linux下elasticsearch 安装、配置及示例
简介
开始学es,我习惯边学边记,总结出现的问题和解决方法。本文是在两台linux虚拟机下,安装了三个节点。本次搭建es同时实践了两种模式——单机模式和分布式模式。条件允许的话,可以在多台机器上配置es节点,如果你机器性能有限,那么可以在一台虚拟机上完成多节点的配置。
如图,是本次3个节点的分布。
| hostname | IP | es节点 |
|---|---|---|
| master | 192.168.137.100 | node1、node3 |
| slave | 192.168.137.101 | node2 |
| 注意:先去 /etc/hosts 文件里,将主机名修改为 master、slave,或者在本文用到hostname的地方改为你的主机名。 |
| 2017.8.28 博文更新 | es的主节点是选出来的,它不一定在master 机器上,也就是es主节点不一定非得是node1或node2,也可能是node3. |
一、下载及配置
1.几个基本名词
index: es里的index相当于一个数据库。
type: 相当于数据库里的一个表。
id: 唯一,相当于主键。
node:节点是es实例,一台机器可以运行多个实例,但是同一台机器上的实例在配置文件中要确保http和tcp端口不同(下面有讲)。
cluster:代表一个集群,集群中有多个节点,其中有一个会被选为主节点,这个主节点是可以通过选举产生的,主从节点是对于集群内部来说的。
shards:代表索引分片,es可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上,构成分布式搜索。分片的数量只能在索引创建前指定,并且索引创建后不能更改。
replicas:代表索引副本,es可以设置多个索引的副本,副本的作用一是提高系统的容错性,当个某个节点某个分片损坏或丢失时可以从副本中恢复。二是提高es的查询效率,es会自动对搜索请求进行负载均衡。
2.下载
| 名称 | 版本 | 下载地址 |
|---|---|---|
| elasticsearch | 1.7.3 | elasticsearch-1.7.3.tar.gz |
下载后,放到你的目录下并解压. 因为我们要配置包含三个节点的集群,可以先将其重命名为elasticsearch-node1。比如我的是 /home/zkpk/elasticsearch-node1。
3.修改配置文件
(1) 初步修改
打开/home/zkpk/elasticsearch-node1/config目录下的elasticsearch.yml 文件 ,修改以下属性值并取消该行的注释:
cluster.name: elasticsearch
#这是集群名字,我们 起名为 elasticsearch
#es启动后会将具有相同集群名字的节点放到一个集群下。
node.name: "es-node1"
#节点名字。
discovery.zen.minimum_master_nodes: 2
#指定集群中的节点中有几个有master资格的节点。
#对于大集群可以写3个以上。
discovery.zen.ping.timeout: 40s
#默认是3s,这是设置集群中自动发现其它节点时ping连接超时时间,
#为避免因为网络差而导致启动报错,我设成了40s。
discovery.zen.ping.multicast.enabled: false
#设置是否打开多播发现节点,默认是true。
network.bind_host: 192.168.137.100
#设置绑定的ip地址,这是我的master虚拟机的IP。
network.publish_host: 192.168.137.100
#设置其它节点和该节点交互的ip地址。
network.host: 192.168.137.100
#同时设置bind_host和publish_host上面两个参数。
discovery.zen.ping.unicast.hosts: ["192.168.137.100", "192.168.137.101","192.168.137.100:9301"]
#discovery.zen.ping.unicast.hosts:["节点1的 ip","节点2 的ip","节点3的ip"]
#指明集群中其它可能为master的节点ip,
#以防es启动后发现不了集群中的其他节点。
#第一对引号里是node1,默认端口是9300,
#第二个是 node2 ,在另外一台机器上,
#第三个引号里是node3,因为它和node1在一台机器上,所以指定了9301端口。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
(2) 进一步修改
拷贝 elasticsearch-node1 整个文件夹,两份,一份elasticsearch-node2,一份elasticsearch-node3.
将elasticsearch-node2 文件夹copy到另外一台IP为192.168.137.101的机器上。而在 192.168.137.100 机器上有 node1和node3.
对于node3: node3和node1在一台机器上,node1的配置文件里端口默认分别是9300和9200,所以要改一下node3配置文件里的端口,elasticsearch.yml 文件修改如下:
node.name: "es-node3"
transport.tcp.port: 9301
http.port: 9201- 1
- 2
- 3
对于node2: 对 elasticsearch.yml 修改如下
node.name: "es-node2"
network.bind_host: 192.168.137.101
network.publish_host: 192.168.137.101
network.host: 192.168.137.101- 1
- 2
- 3
- 4
注意:
1.对于单机多节点的es集群,一定要注意修改 transport.tcp.port 和http.port 的默认值保证节点间不冲突。
2. 出现找不到同一集群中的其他节点的情况,检查下
discovery.zen.ping.unicast.hosts 是否已设置。
二、运行 & 关闭 elasticsearch
1.运行elasticsearch :
编辑 /home/zkpk/elasticsearch-1.7.3/bin/elasticsearch.in.sh, 设置 ES_MIN_MEM和ES_MAX_MEM,确保二者数值一致,或者可以在启动es时指定,
[zkpk@master ~]$ cd ~/elasticsearch-node1/bin
[zkpk@master bin]$ ./elasticsearch -Xms512m -Xmx512m- 1
- 2
若想让es后台运行,则
[zkpk@master bin]$ ./elasticsearch -d -Xms512m -Xmx512m- 1
2.关闭elasticsearch:
前台运行:可以通过”CTRL+C”组合键来停止运行
后台运行,可以通过”kill -9 进程号”停止.也可以通过REST API接口:
curl -XPOST http://主机IP:9200/_cluster/nodes/_shutdown- 1
来关闭整个集群,通过:
curl -XPOST http://主机IP:9200/_cluster/nodes/节点标示符(如es-node1)/_shutdown- 1
来关闭单个节点.
三、插件及其安装
BigDesk Plugin : 对集群中es状态进行监控。
Elasticsearch Head Plugin: 对ES进行各种操作,如查询、删除、浏览索引等。
1.安装head插件
进入到节点elasticsearch-node1/bin路径,并安装插件。
[zkpk@master bin]$ ./plugin -install mobz/elasticsearch-head- 1
2. 安装bigdesk
[zkpk@master bin]$ ./plugin -install lukas-vlcek/bigdesk
让我们看下es页面吧~~
打开head浏览,浏览器输入http://192.168.137.100:9200/_plugin/head/ ,如图,
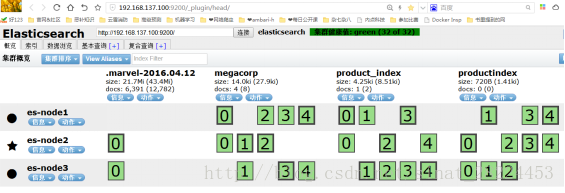
图1
每个小方块就是索引分片,可以看到每个索引被分成几个分片,每个分片还有它的备份分片,然后存储在三个节点上。粗框的是主分片,细框的是备份分片。
四、添加索引
现在我们来添加一个索引记录吧~
1.可以在命令窗口通过命令来添加
curl -XPUT 'http://主机IP:9200/dept/employee/32' -d '{ "empname": "emp32"}'- 1
见 http://www.oschina.net/translate/elasticsearch-getting-started?cmp
2.我们可以在页面上通过JSON添加
(1)点击 复合查询[+] ,我们可以在 megacorp 索引 (相当于数据库名)的 employee 类型(相当于表名)下新增一个id为2的人的信息。
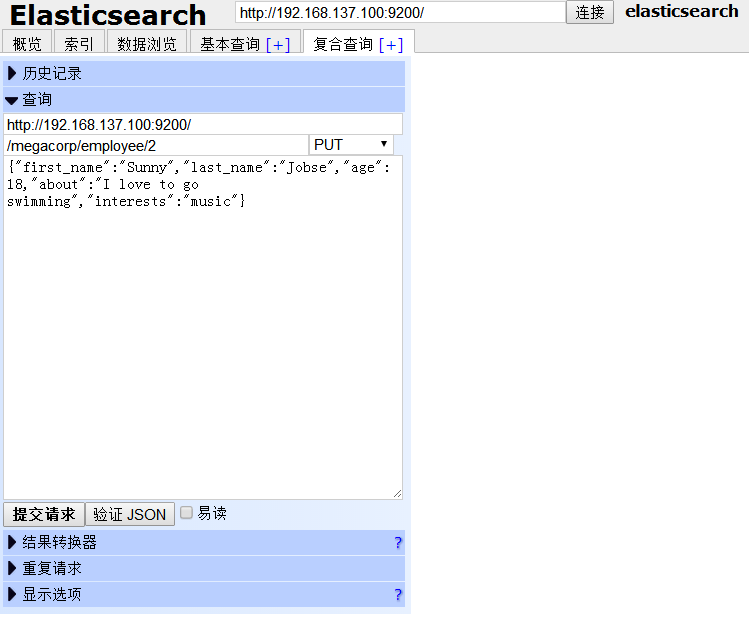
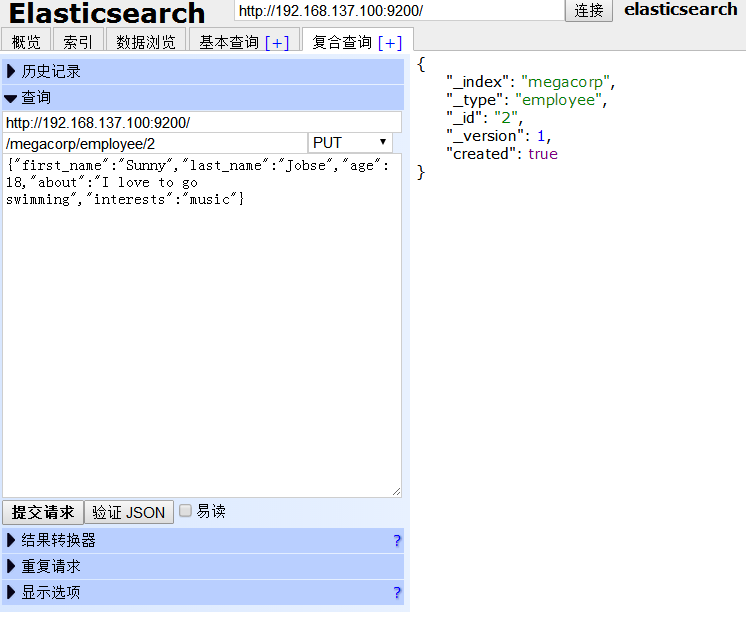
点击下方的 提交请求 按钮,页面右方有回馈信息,“created”代表是否为新建。添加成功。
点击 浏览数据 ,在左侧 索引 下选择 megacorp,如图,
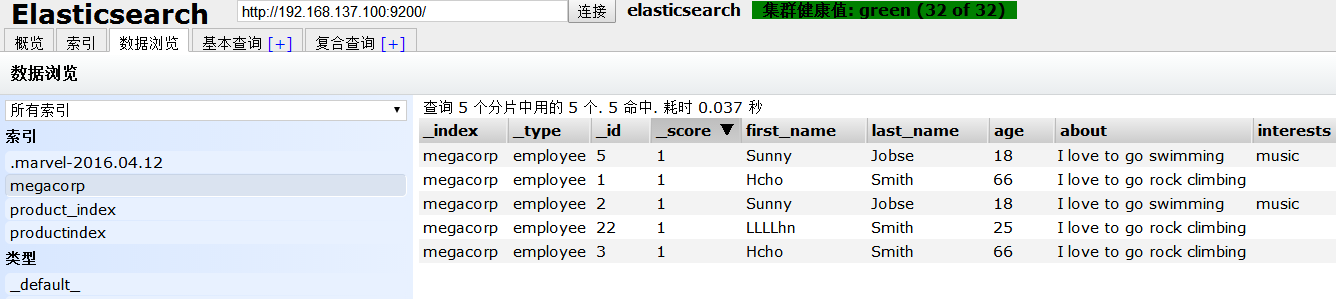
可以看到,一条id为2的记录被添加了。
(2)下面我们修改id为2 的人的年龄为15,把about 信息去掉,并且加一项兴趣。
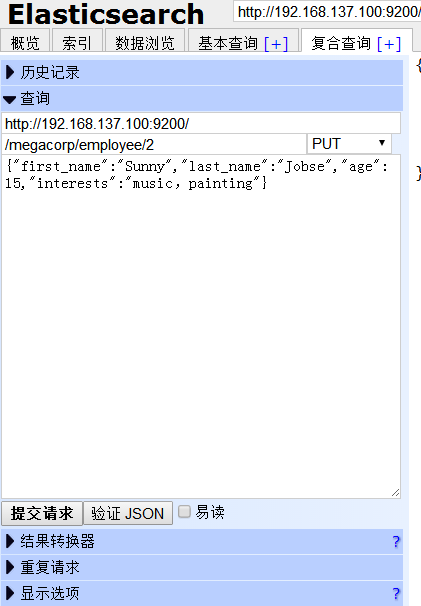
提交后,右侧有反馈信息,“created”为 false,因为我们这次不是新建而是修改。
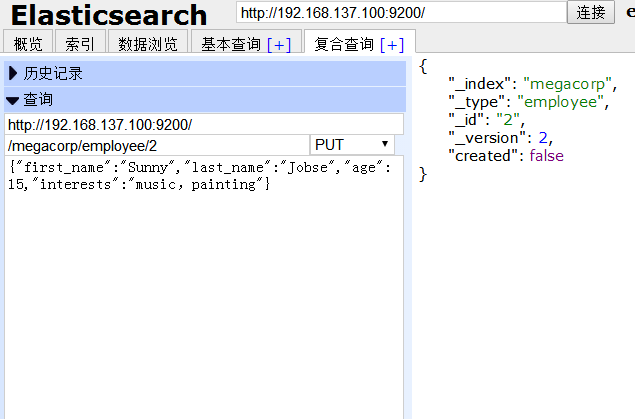
返回浏览数据,id为2 的记录,年龄、兴趣等均已发生变化。

参考:
http://www.cnblogs.com/huangfox/p/3543351.html
http://www.linuxidc.com/Linux/2015-02/114243.htm
http://my.oschina.net/u/579033/blog/394845?fromerr=Kt60ej6x
文档总结不易,希望能帮到各位,和各位一起进步,另,转载请标明出处。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号