
线上问题排查--进程重启失败,最后发现是忘了cd
背景
我前面写了几篇文章,讲c3p0数据库连接池发生了连接泄露,但是随机出现,难以确定根因,最终呢,为了快速解决问题,我是先写了个shell脚本,脚本主要是检测服务的接口访问日志,看看过去的30s内是不是接口几乎都超时了,如果是的话,咱们就重启服务。然后把这个shell加入到了crontab里,每30s调度一次。

crontab如下(cron最小调度时间为分钟,所以搞了两条,以支持30s执行一次):
* * * * * /bin/sh /xxx/xxx/check_service_block_gbk.sh
* * * * * sleep 30; /xxx/xxx/check_service_block_gbk.sh
脚本的内容大概如下,:
计算过去n秒内异常请求的次数
...
如果异常请求超过某个阈值,重启服务
if [ "${error_req_count_sum}" -gt ${THRESHOLD_FOR_ERROR_REQ_IN_LAST_N_SECONDS} ];then
log "trigger restart, start restart"
"${SERVICE_ROOT_PATH}"/run.sh stopall
"${SERVICE_ROOT_PATH}"/run.sh startall
log "finish restart,finish current check"
else
log "no need restart,finish current check"
fi
这个脚本上线有半个多月了,这期间问题一直没复现,结果,昨天下午,运维同事和我说,用户反馈app出问题了,也就是问题复现了,但是,我那个脚本吧,好像有问题,现象就是,异常进程是结束了,但是,却没有启动起来,导致这期间服务完全宕了,最后还是他手动启动起来的。
现场排查
由于事情是事后他和我说的,我过去后也就是一起看了下日志,发现服务的访问日志确实是中断了2分钟(就是服务被脚本干掉后,没启动起来的真空期)。而shell脚本呢,在如下几行中:
function log()
{
now=$(date "+%Y-%m-%d %H:%M:%S")
echo -e "$now : $*"
echo "$now : $*" >> "${SERVICE_ROOT_PATH}"/check_service_block_gbk.log
}
log "trigger restart, start restart"
"${SERVICE_ROOT_PATH}"/run.sh stopall
"${SERVICE_ROOT_PATH}"/run.sh startall
log "finish restart,finish current check"
当时脚本写得不算很完备,只有log的那两行有日志,真正执行停止服务和启动服务的run.sh的执行,日志都打到console去了,日志文件里完全没有:
"trigger restart, start restart"
"finish restart,finish current check"
所以啊,毕竟还是不够专业,应该把脚本的标准输出重定向到日志文件的。
另外,根据脚本和现象,确定是执行了/run.sh stopall的,毕竟服务都没了嘛。
我们这个服务的框架很老,但也还比较稳定,框架自带的脚本就是上面看到的那个run.sh,这个run.sh呢,执行run.sh startall,会启动3个服务。
- 一个是服务本身
- 再一个是一个定时重启脚本,脚本里是一个死循环,每次循环就是检测是否到指定时间了,如果到了,就重启服务;没到,就sleep 1s;
- 另一个也是一个watchdog脚本,脚本里是一个死循环,每次循环就是检测服务还在不在,不在了就把服务拉起来
这几个服务一启动后,就会在当前目录下,生成几个pid文件:
- 服务本身,不生成pid文件,停止时就靠服务名去ps -ef|grep来查找
- 定时重启脚本,生成pid到reset.pid这个文件
- watchdog脚本,生成pid到watchdog.pid这个文件
而停止的时候run.sh stopall,就会根据上面的几种方法去找到对应的pid来kill。然后这几个服务的框架是支持kill -9这种暴力杀服务的,所以,几个服务被stop了,日志里是一点信息没有;然后呢,既然你说服务没启动起来,难道启动日志也没有嘛?问题是,还真的没有,空空如也,正常的话,自然是有的。但是我们可能就是执行run.sh startall时,报错可能都写到标准输出了,自然就没记录到日志里。
当时看到的东西,差不多就是这些。
本地复现
有的人会说,感觉这脚本没测试,直接就上线了,我可以这么说,测试,肯定是测了的,本地运行shell,都能把服务重启起来;但是,把脚本放到crontab里面后,倒是没有测试过这个分支。
这两个脚本是在同一目录下:
[root@xxxx]# ll check_service_block_gbk.sh run.sh
-rwxr-xr-x 1 root root 3498 Aug 1 08:50 check_service_block_gbk.sh
-rwxr-xr-x 1 root root 11425 Aug 1 10:51 run.sh
我当时测试的时候,在本地测是通过如下命令,一点问题没有:
./check_service_block_gbk.sh
结果这次上线又出了这个,我就想着在本地复现下,弄到cron里去触发,没想到,还真的和线上一样,服务被stop了,但是并没有重启起来。
我先是crontab -e加了日志,把脚本的标准输出重定向到文件/root/cron.log:
* * * * * /bin/sh -x /foo/bar/check_service_block_gbk.sh >> /root/cron.log 2>&1
然后触发了一次后,去查看shell执行日志/root/cron.log,发现,在执行startall时,nohup启动服务的地方,看着有点怪:
+ nohup /foo/bar/TBAServer
这个TBAServer是个二进制,就是我们的后台服务。我当时,为啥感觉有点怪呢,因为run.sh中,nohup那一行如下:
nohup $SERVER_PATH >> ${SERVER_DIR}/stdout.txt 2>&1 &
我们脚本里,后面还有>> xxx/stdout.txt 2>&1 &这些,为啥在shell -x的执行log里没有呢?
当时以为找到了问题,结果后来,我正常在shell中如下执行:
sh -x check_service_block_gbk.sh
发现执行日志也是一样的,看起来不是这个的问题。
然后左查右查,搞了好久,反正昨晚没弄出来,然后早上上班的时候,在互联网上关键字找了下,好像也没有类似的问题,只看到说,在cron执行的话,环境变量和在shell中执行不一样,不过我还没来得及测试环境变量这块,就有了新发现。
换机测试,柳暗花明
由于昨晚那台本地拿来复现的机器,白天用的人较多,为了不影响别人,我就换了台机器,没想到,换到新机器后测试时,在shell的执行日志中看到了关键日志:
+ nohup /foo/bar/TBAServer
...
启动路径不是进程所在路径,系统无法正常运行
看到这个,我大概就知道是啥原因了,为啥这个关键日志,在昨晚的机器没有呢,是因为二进制文件的版本不同,我今天这台机器上的二进制,版本更新。
看到这个错误,我大概猜测是进程的current working directory的问题,于是我修改了下run.sh,打印pwd。
echo cwd: "$PWD" ---增加的一行
nohup $SERVER_PATH >> ${SERVER_DIR}/stdout.txt 2>&1 &
然后,分别测试在shell下正常运行和通过crontab运行:
-
crontab时,
cwd: /root
-
shell正常运行时:
cwd: /foo/bar
虽然已基本确认问题,我还是进一步检验了一下,为啥二进制文件里会报那个错误,我用IDA对那个二进制反编译了一下,(只能看懂一点,非常勉强)。
问题根源
里面有如下代码:
if ( !IsStartFromPFPath() )
{
OUT(byte_4AB1C0);
exit(1);
}
这里调用了一个函数,大意是是否从xxx路径启动,不是的话,就会输出一个信息,然后exit。
这个输出的信息,我找了下,确实就是日志里那句。

接下来,我们进函数一览,现在看c++已经非常吃力了,只能看个大概:
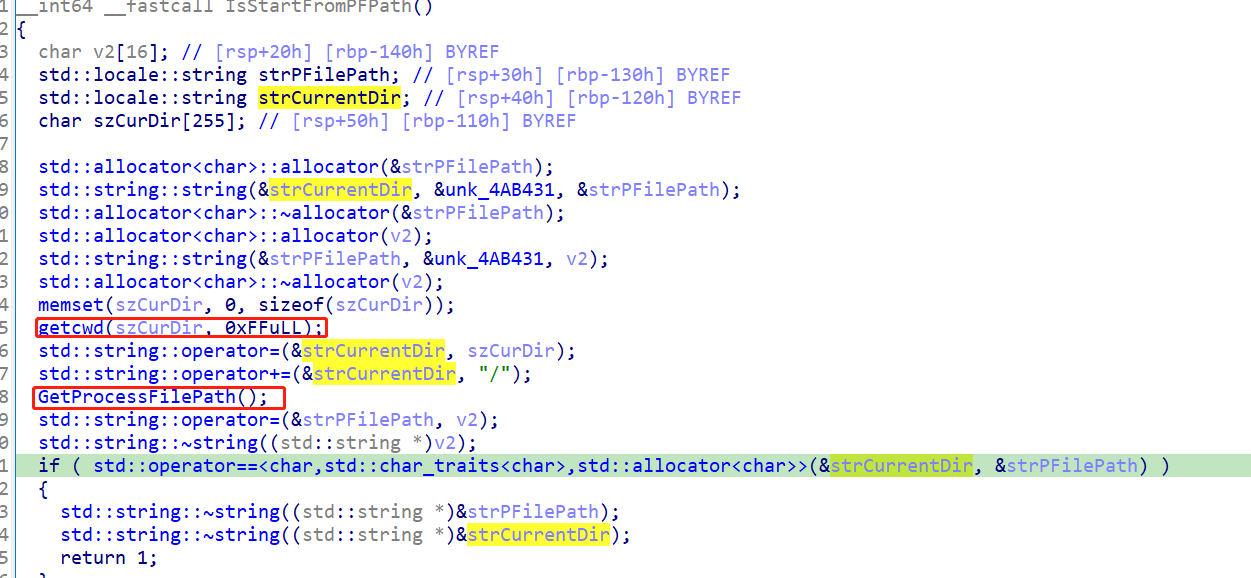
这里面调用了另外两个函数,一个是获取进程的cwd(当前工作目录),一个是获取进程文件的路径,然后做比较,看看是否一致。
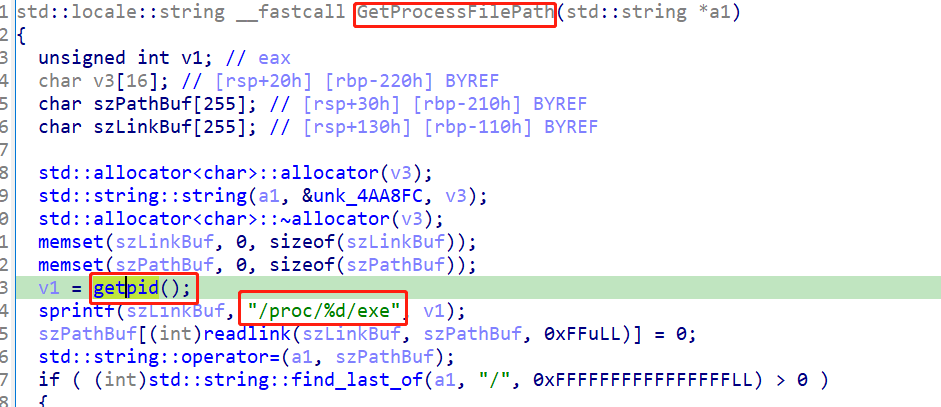
这个获取进程文件路径的函数,如上,我们结合猜测,应该就是获取二进制文件TBAServer的位置。
而,我们在cron执行时,cwd为/root,而TBAServer的位置为/foo/bar/TBAServer,这两个路径,明显不一致,所以,最终报了那个错误,导致启动失败。
为了进一步确认以上猜想,我准备使用strace命令,来看看启动这个TBAServer时,到底进行了哪些系统调用?
我改了run.sh,如下:
echo cwd: "$PWD"
nohup strace -q -f -s 200 $SERVER_PATH 2>&1 & >> ${SERVER_DIR}/stdout.txt
strace命令的强大毋庸置疑,可以跟踪系统调用,很多难题都能迎刃而解。下图也确认了我们的代码分析的结论。

问题解决
知道是cwd的问题了,那就解决吧,解决的办法就是要将工作目录切换到正确的目录,我采用的方法是直接在crontab这里修改。
* * * * * cd /foo/bar; /bin/sh -x /foo/bar/check_service_block_gbk.sh
有一个小问题是,这里我就没再将执行日志重定向了,也就是去掉了下面这部分。因为我发现服务运行时的日志也会打印进去,到时候日志就打了两份了。暂时还没去想怎么解决。
>> /root/cron.log 2>&1
下午的时候,到运维同事那边试了试,运行很平稳,检测到异常就可以自动重启了,终于可以了了这个事了。
参考文章
关于cron环境变量问题的文章:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号