数据库连接池之c3p0-0.9.1.2,16年的古董,发生连接泄露怎么查(一)
背景
这篇文章是写给有缘人的,为什么这么说呢,因为本篇主要讲讲数据库连接池之c3p0-0.9.1.2版本。
年轻的朋友,可能没怎么听过c3p0了,或者也仅限于听说,这都很正常,因为c3p0算是200几年时比较流行的技术,后来,作者消失了好几年,12年重新开始维护,这时候已经出现了很多第二代线程池了,c3p0已经不占优势,就这样,又维护了几年,直到19年彻底停止更新。
看下其版本历史吧,一开始的maven坐标是这样的:
<!-- https://mvnrepository.com/artifact/c3p0/c3p0 -->
<dependency>
<groupId>c3p0</groupId>
<artifactId>c3p0</artifactId>
</dependency>
07年发了最后一个版本c3p0-0.9.1.2:

再下一个版本是2012年的0.9.2-pre2-RELEASE,来到了2012年,坐标改成了:
<!-- https://mvnrepository.com/artifact/com.mchange/c3p0 -->
<dependency>
<groupId>com.mchange</groupId>
<artifactId>c3p0</artifactId>
</dependency>
后续的更新版本如下:
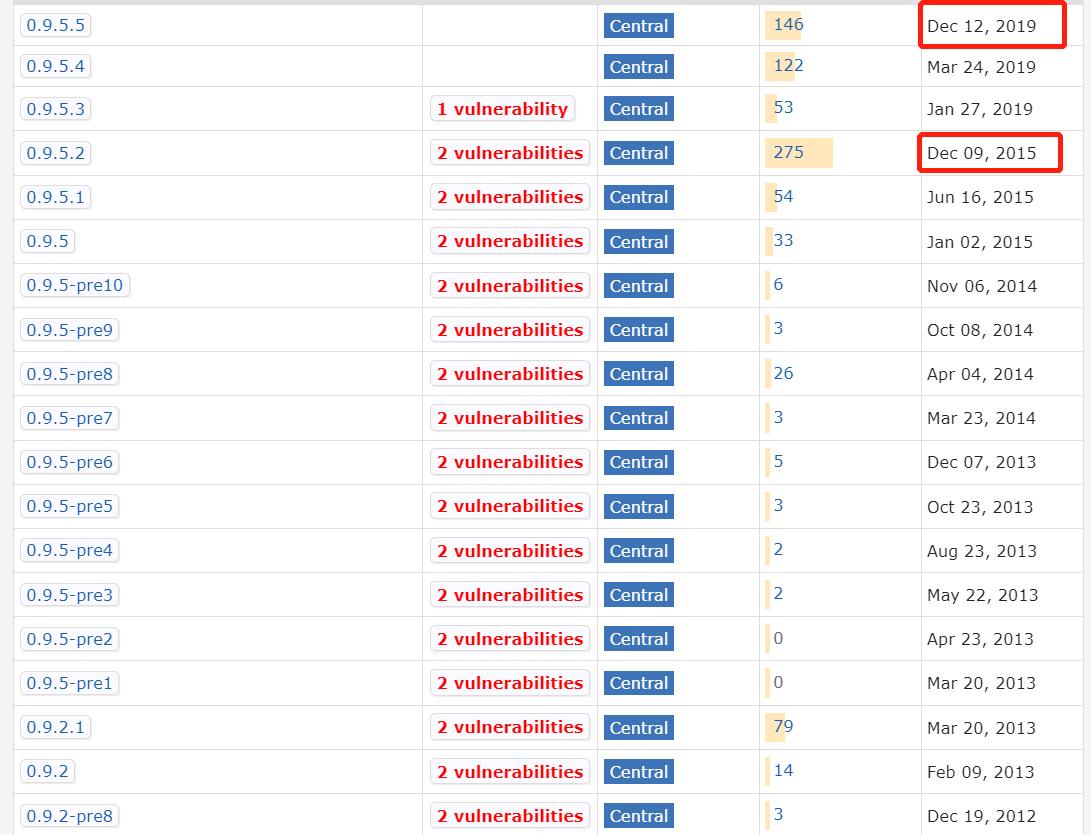
可以看到,维护到15年后,又消失了几年,直到19年又重新维护了一年,然后就再无动静。
所以,为啥我觉得还是可以讲讲c3p0-0.9.1.2这个版本呢,因为据说当年还是比较火的,很多那时候的项目都用了这个版本,然后就一直再没有升级(想升也没得升啊),所以,我估计,如果那些老项目还在维护的话,估计有不少有缘人还在和这个c3p0-0.9.1.2打交道,我,就是其中一个。
在一些求稳的行业,线上能跑的项目,那肯定是没人会去大动的,只会不断地添砖加瓦,而这也导致更难大动,如果没被重构掉的话,就遗留到了现在。
我现在手里的维护的一个项目,就是用的这个框架,而且,它很容易有bug,不信的话,搜索看看:
本文,就打算来讲讲我遇到的问题和这个框架的0.9.1.2版本的大概的源码逻辑。
我遇到的线上问题
我目前手里这套服务的代码框架应该是0几年诞生的,不是市面上曾经流行的框架,如struts、spring mvc那些,而是c++开发的类比netty、servlet容器的东西,在监听端口收到客户端请求后,能根据请求中的功能id来反向调用对应的java代码,还是有点东西的。而java代码里也是一套框架,框架源码还失传了,框架里代码定死了用c3p0这个来创建数据库连接池,导致我想换也不好换,比较费劲。
业务层呢,托了jdbc规范的福,就是只和jdbc的api打交道,比如找datasource拿connection,这个拿,一般也就是从连接池里面取,用完了,再调用connection.close(内部会把连接再还回连接池)。
所以,我们线上到底有啥问题呢?具体表现就是,业务会突然在某个时刻,调用datasource.getConnection的时候,取不到连接,直接超时,而且是全部的业务请求都出这个问题,这时候,服务基本就hang死了,前端一直转圈。
这个是完全随机的,不定时地炸,每次炸了后,就要靠运维同事重启服务,重启后,服务就好了。
下面来说说定位的过程吧,现在其实也没找到根本原因,只是有了解决的办法和一些猜测,可以等下次再出现的时候,验证一下。
定位初始
刚开始的时候,线上服务只有日志,而且只有error日志,那基本看不出个啥,就是大片大片的等待从连接池获取连接,最后直到超时都获取不到的报错。
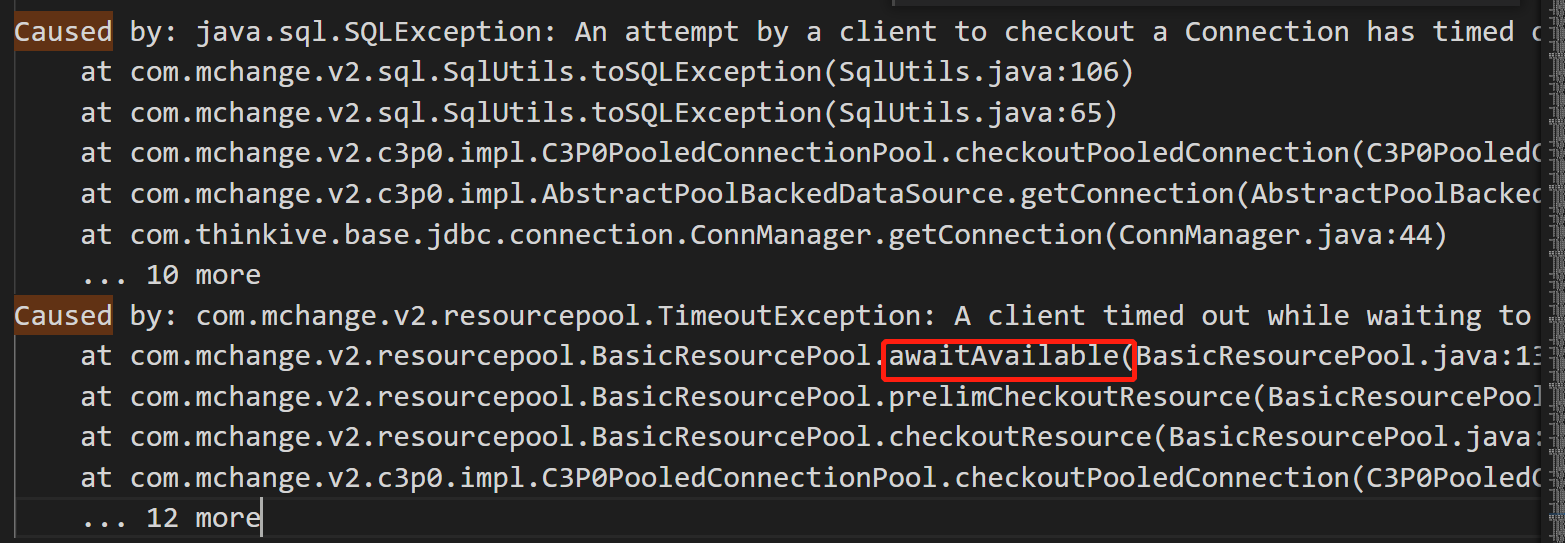
当时苦于没有其他手段,又是偶现,也看不出个啥,找dba了也看过db,dba表示运行稳定,当然,dba说的也不一定准,反正是没收获。
后来,2月份的时候,搞了个脚本,服务出现问题的时候,先执行下脚本,打印下jstack、jmap、netstat、top等一些东西,而一开始的时候,运维经常忘记执行,直接就重启了,于是只能等下次,直到2月底的某一天吧,总算是执行了下脚本,拿到了jmap等信息。
jmap确认直接原因
查看资源池现状
分析jmap,个人习惯用MAT。MAT支持object query language语言进行堆对象查询,具体语法可以自己学一学。
我就如下图所示,查询连接池的情况,我这边有多数据源,所以有多个连接池,其中有问题的那个连接池,池子里维护的连接有40个:
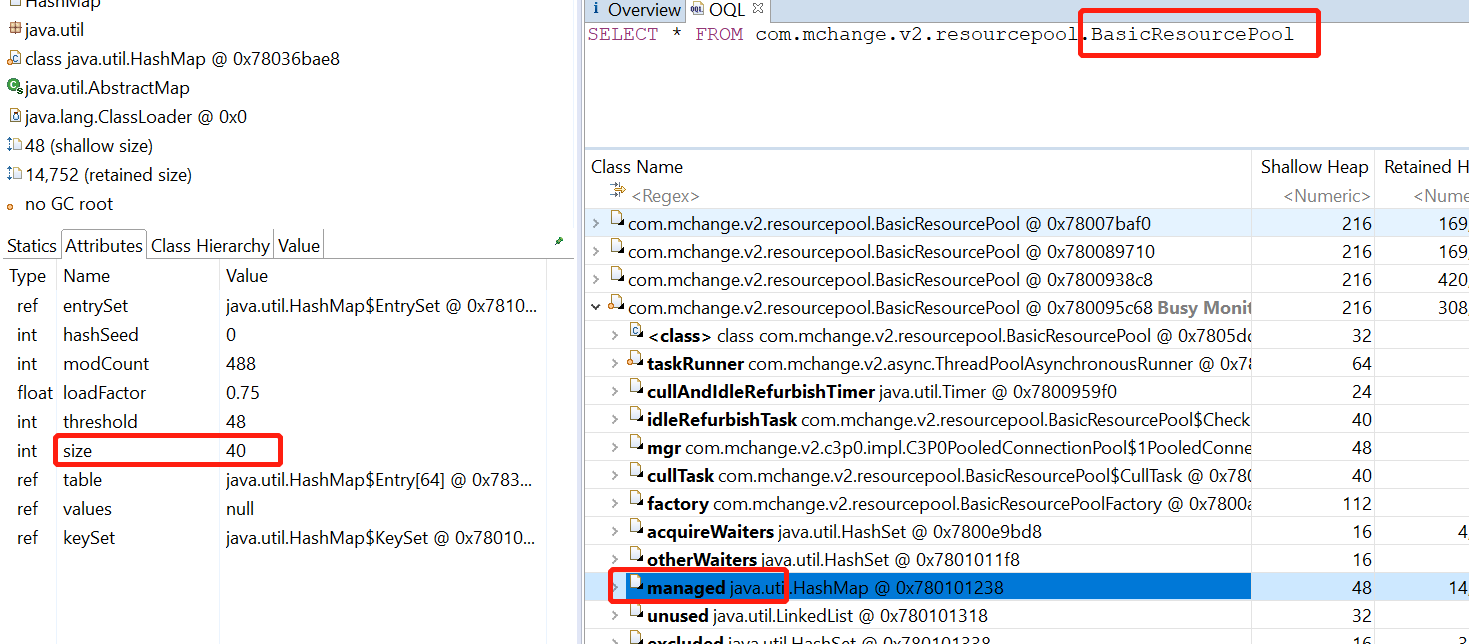
这里有必要说一下,这个managed:
/* keys are all valid, managed resources, value is a PunchCard */
HashMap managed = new HashMap();
这个hashmap,就是连接池。
初始化连接池--维护managed、unused
那么,它是怎么初始化的呢,以下面的参数举例:
<property name="minPoolSize">10</property>
<property name="maxPoolSize">50</property>
在BasicResourcePool的构造函数中,就会调用如下方法:
//start acquiring our initial resources
ensureStartResources();
private void ensureStartResources()
{ recheckResizePool(); }
具体就会调用:
private void expandPool(int count)
{
for (int i = 0; i < count; ++i)
taskRunner.postRunnable( new AcquireTask() );
}
c3p0会计算出,需要建10个连接出来,上面的count就是10,那么会new 10个runnable,提交给线程池执行,在每个线程执行时:
private void doAcquire() throws Exception
{
// 1 交给具体的manager去获取底层连接
Object resc = mgr.acquireResource();
...
// 2 拿到连接后,维护到池子里
assimilateResource(resc);
}
这里的mgr,负责具体去创建数据库连接,由于涉及到多种数据库,因此mgr就负责具体脏活累活,连接池这边就不和这些脏话累活打交道,就是类似于我们代码分层架构中的,用来操作redis、es、第三方服务等的一个层,相当于把一些通用的业务逻辑下沉。
而上面2处的代码,就负责池子维护:
private void assimilateResource( Object resc ) throws Exception
{
// 1
managed.put(resc, new PunchCard());
// 2
unused.add(0, resc);
// 3
this.notifyAll();
}
这里的1处,就会往managed里面存放连接,key就是创建的连接,那么value是啥呢?
final static class PunchCard
{
long acquisition_time;// 创建时间
long last_checkin_time; //上次归还到连接池的时间
long checkout_time; // 从连接池借出的时间,未借出时,值为-1
Exception checkoutStackTraceException; // 被借出时,该借出线程的堆栈
PunchCard()
{
this.acquisition_time = System.currentTimeMillis();
this.last_checkin_time = acquisition_time;
this.checkout_time = -1;
this.checkoutStackTraceException = null;
}
}
Punchcard这个词,翻译的意思是:穿孔卡(旧时把信息打成一排排的小孔,用以将指令输入计算机等),我这边就理解成这个数据库连接的一些记录出借/归还信息的卡片。
里面有个checkout_time字段,初始化的值是 -1,表示未被出借。
另外,还有个重要字段,unused,这个主要是存放可供出借的连接。
/* all valid, managed resources currently available for checkout */
LinkedList unused = new LinkedList();
上面的2处,就会把新的连接往这里面放,放完后,用notify通知其他消费者线程。
综上所述,刚开始的时候,
<property name="minPoolSize">10</property>
<property name="maxPoolSize">50</property>
managed的size是10,unused也是10
连接池出借连接的逻辑
检查unused是否有空闲连接
private synchronized Object prelimCheckoutResource( long timeout ){
int available = unused.size();
if (available == 0){
// 检查是否可以扩容,可以的话,触发扩容后开始等待。扩容也是异步的,扩容成功的话,unused的size就大于0
...
}
Object resc = unused.get(0);
// 检查连接是否过期了,如果过期了,这个连接不能要,得销毁
if ( shouldExpire( resc ) )
{
removeResource( resc );
ensureMinResources();
return prelimCheckoutResource( timeout );
}
else
{ // 连接可用,那就从unused中摘除本连接并返回
unused.remove(0);
return resc;
}
}
检查连接是否真实有效
boolean refurb = attemptRefurbishResourceOnCheckout( resc );
if (!refurb)
{
removeResource( resc );
ensureMinResources();
resc = null;
}
这个步骤类似于在连接上执行一个select 1,检查连接到底能不能用。不能用的话,销毁连接。
借到连接后,维护出借卡片
PunchCard card = (PunchCard) managed.get( resc );
card.checkout_time = System.currentTimeMillis();
if (debug_store_checkout_exceptions)
card.checkoutStackTraceException = new Exception("DEBUG ONLY: Overdue resource check-out stack trace.");
这里就是,获取到这个连接的punchCard信息卡,然后登记出借的时间为当前时间,那么,是谁借了呢,这里是通过new一个异常的方式,通过这个异常,就能知道当前线程的堆栈。
用完后,归还连接给连接池
if (managed.keySet().contains(resc))
doCheckinManaged( resc );
这个归还呢,如下,也不是直接归还,竟然也是new一个runnable去归还,个人觉得,这个有巨大的隐患,因为线程池是可能会堵的,而这个就极有可能导致还不进去。
private void doCheckinManaged( final Object resc ){
Runnable doMe = new RefurbishCheckinResourceTask();
taskRunner.postRunnable( doMe );
}
class RefurbishCheckinResourceTask implements Runnable
{
public void run()
{
// 1 归还前试着测试下连接是否能用,比如select 1
boolean resc_okay = attemptRefurbishResourceOnCheckin( resc );
// 2 获取卡片并更新卡片
PunchCard card = (PunchCard) managed.get( resc );
if ( resc_okay && card != null)
{
// 3
unused.add(0, resc );
card.last_checkin_time = System.currentTimeMillis();
card.checkout_time = -1;
}
BasicResourcePool.this.notifyAll();
}
}
这里主要就是,归还前先测试下连接是不是好的,免得还个坏的进去;再就是,拿到之前的出借卡,更新归还时间为当前时间、借出时间改为-1;再把连接放回到unused空闲链表。
现状反映出的问题
问题如下,空闲链表为空,连接池被出借一空:
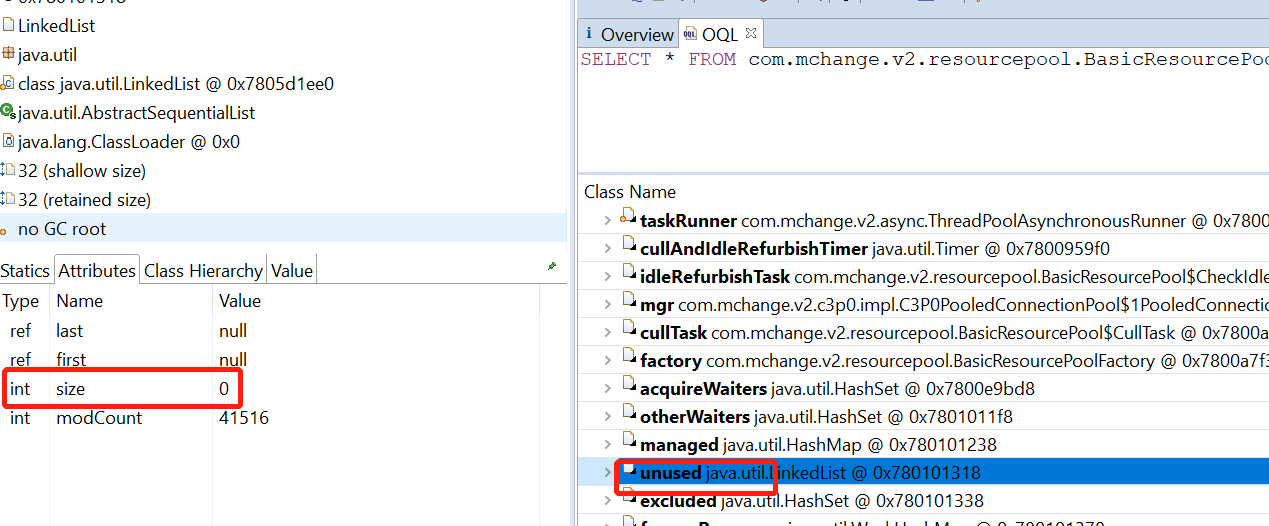
随便找了个连接看出借时间:
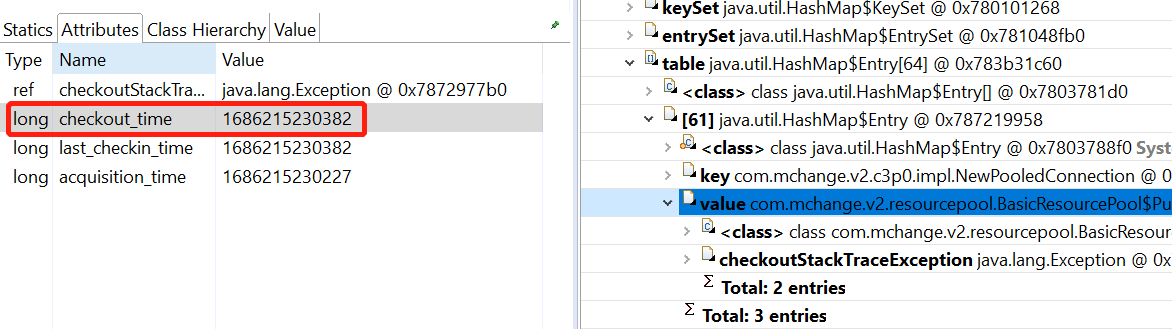

这个时间,距离执行jmap的时候,已经过去了一分钟了,而大部分的punchCard都是这样,这说明了什么,说明了这些连接被借出去一分钟了,都还没有归还到unused空闲链表,导致空闲链表size为0,后续的请求在unused上死等也等不到连接(因为managed已经达到池子的最大值了,也没法扩容),于是超时。
问题根因如何找
现在看起来,直接原因是找到了,就是有连接泄露,但是具体是哪里有泄露呢?是不是真的有泄露呢?感觉长路仍漫漫,继续努力吧。
留到下篇继续吧,天也晚了,现在早上上班早,晚上不早点睡真是扛不住。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号