文件下载文件名包含中文时,乱码的处理方法(url编解码)
utf-8/gbk编码
"中“这个汉子的utf-8编码为:E4B8AD
gbk编码为:D6D0
urlencode
经过urlencode编码后,
%E4%B8%AD
%D6%D0
服务端这样编写代码时的网络报文解析
String name = "中文bc_rule"
+ "_export_"
+ DateUtils.formatDateToStr(new Date(), "yyyy_MM_dd HH_mm_ss") + ".xls";
String encode = URLEncoder.encode(name, "UTF-8");
httpServletResponse.setHeader("filename", encode);
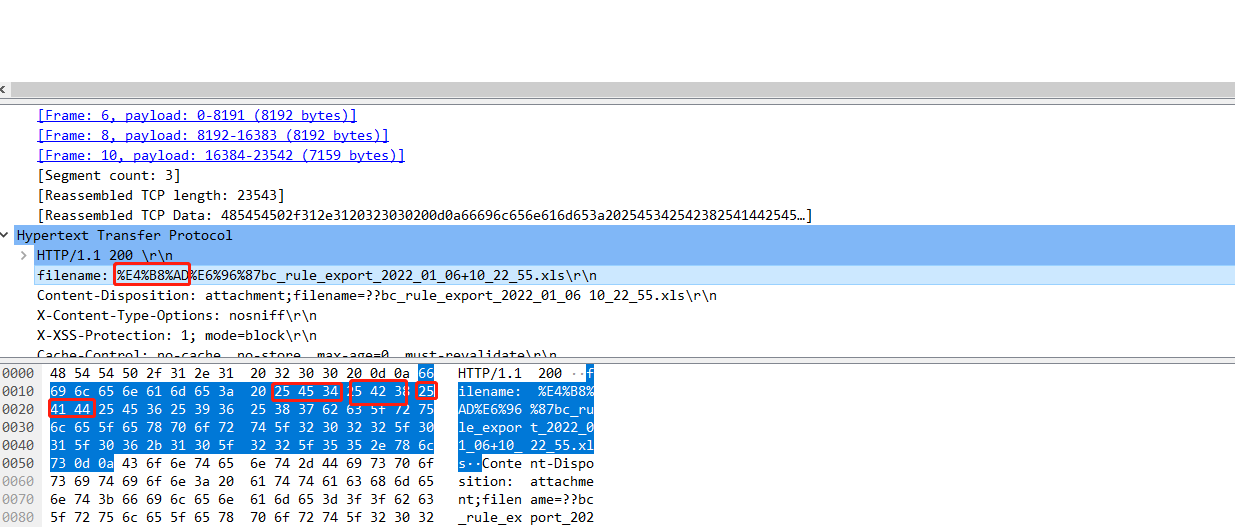
网络抓包可以看到,就是把中字的urlencode编码传下去了:
"%E4%B8%AD",看来默认就是UTF-8编码。
客户端是js,如下方式进行解码:
const filename = res.headers.get("filename");
console.log(`origin name:${ filename}`)
const filename2 = decodeURIComponent(filename);
console.log(`filename:${filename2}`);
console打印的结果:
origin name:%E4%B8%AD%E6%96%87bc_rule_export_2022_01_06+10_22_55.xls
filename:中文bc_rule_export_2022_01_06+10_22_55.xls
可以看到,客户端也是默认用了UTF-8去解码,否则应该是解码不出来的。
客户端代码没变的情况下,遇到下图中用gbk编码的字符串,报错了:
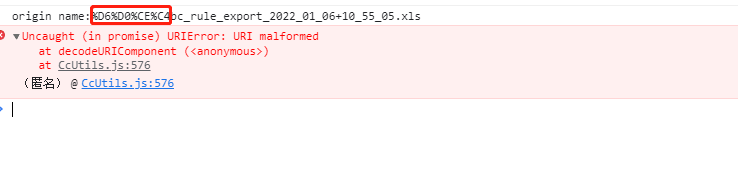
下图直接在console实验,确实会报错:
decodeURIComponent("%D6%D0")
VM671:1 Uncaught URIError: URI malformed
at decodeURIComponent (<anonymous>)
at <anonymous>:1:1
https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/decodeURI

 浙公网安备 33010602011771号
浙公网安备 33010602011771号