曹工说Redis源码(3)-- redis server 启动过程完整解析(中)
文章导航
Redis源码系列的初衷,是帮助我们更好地理解Redis,更懂Redis,而怎么才能懂,光看是不够的,建议跟着下面的这一篇,把环境搭建起来,后续可以自己阅读源码,或者跟着我这边一起阅读。由于我用c也是好几年以前了,些许错误在所难免,希望读者能不吝指出。
曹工说Redis源码(1)-- redis debug环境搭建,使用clion,达到和调试java一样的效果
曹工说Redis源码(2)-- redis server 启动过程解析及简单c语言基础知识补充
本讲主题
首先,会再补充一点c语言中,指针的相关知识;接下来,开始接着昨天的那篇,讲redis的启动过程,由大到小来讲,避免迅速陷入到细节中。
关于指针的理解
指针,其实就是指向一个内存地址,在知道这个地址前后存储的内容的前提下,这个指针可以被你任意解释。我举个例子:
typedef struct Test_Struct{
int a;
int b;
}Test_Struct;
int main() {
// 1
void *pVoid = malloc(4);
// 2
memset(pVoid,0x01,4);
// 3
int *pInt = pVoid;
// 4
char *pChar = pVoid;
// 5
short *pShort = pVoid;
// 6
Test_Struct *pTestStruct = pVoid;
// 7
printf("address:%p, point to %d\n", pChar, *pChar);
printf("address:%p, point to %d\n", pShort, *pShort);
printf("address:%p, point to %d\n", pInt, *pInt);
printf("address:%p, point to %d\n", pTestStruct, pTestStruct->a);
}
-
1处,分配一片内存,4个字节,32位;返回一个指针,指向这片内存区域,准确地说,指向第一个字节,因为分配的内存是连续的,你可以理解为数组。
The malloc() function allocates size bytes and returns a pointer to the allocated memory.
-
2处,调用memset,将这个pVoid 指向的内存开始的4个字节,设置为0x01,其实就是把每个字节设置为00000001。
这个memset的注释如下:
NAME memset - fill memory with a constant byte SYNOPSIS #include <string.h> void *memset(void *s, int c, size_t n); DESCRIPTION The memset() function fills the first n bytes of the memory area pointed to by s with the constant byte c.参考资料: https://www.cnblogs.com/yhlboke-1992/p/9292877.html
这里我们把每个字节,设为0x01,最终的二进制,其实就是如下这样:

-
3处,定义int类型的指针,将pVoid赋值给它,int占4字节
-
4处,定义char类型的指针,将pVoid赋值给它,char占1字节
-
5处,定义short类型的指针,将pVoid赋值给它,short占2字节
-
6处,定义Test_Struct类型的指针,这是个结构体,类似于高级语言的类,这个结构体的结构如下:
typedef struct Test_Struct{ int a; int b; }Test_Struct;同样,我们将pVoid赋值给它。
-
7处,分别打印各类指针的地址,和对其解引用后的值。
输出如下:

257的二进制就是:0000 0001 0000 0001
16843009的二进制就是:0000 0001 0000 0001 0000 0001 0000 0001
结构体那个,也好理解,因为这个结构体,第一个属性a,就是int类型的,占4个字节。
另外,大家要注意,上面输出的指针地址都是一模一样的。
如果大家能理解这个demo,再看看这个链接,相信会更加理解指针:
redis server大致的启动过程
int main(int argc, char **argv) {
struct timeval tv;
/**
* 1 设置时区等等
*/
setlocale(LC_COLLATE,"");
...
// 2 检查服务器是否以 Sentinel 模式启动
server.sentinel_mode = checkForSentinelMode(argc,argv);
// 3 初始化服务器配置
initServerConfig();
// 4
if (server.sentinel_mode) {
initSentinelConfig();
initSentinel();
}
// 5 检查用户是否指定了配置文件,或者配置选项
if (argc >= 2) {
...
// 载入配置文件, options 是前面分析出的给定选项
loadServerConfig(configfile,options);
sdsfree(options);
}
// 6 将服务器设置为守护进程
if (server.daemonize) daemonize();
// 7 创建并初始化服务器数据结构
initServer();
// 8 如果服务器是守护进程,那么创建 PID 文件
if (server.daemonize) createPidFile();
// 9 为服务器进程设置名字
redisSetProcTitle(argv[0]);
// 10 打印 ASCII LOGO
redisAsciiArt();
// 11 如果服务器不是运行在 SENTINEL 模式,那么执行以下代码
if (!server.sentinel_mode) {
// 从 AOF 文件或者 RDB 文件中载入数据
loadDataFromDisk();
// 启动集群
if (server.cluster_enabled) {
if (verifyClusterConfigWithData() == REDIS_ERR) {
redisLog(REDIS_WARNING,
"You can't have keys in a DB different than DB 0 when in "
"Cluster mode. Exiting.");
exit(1);
}
}
// 打印 TCP 端口
if (server.ipfd_count > 0)
redisLog(REDIS_NOTICE,"The server is now ready to accept connections on port %d", server.port);
} else {
sentinelIsRunning();
}
// 12 运行事件处理器,一直到服务器关闭为止
aeSetBeforeSleepProc(server.el,beforeSleep);
aeMain(server.el);
// 13 服务器关闭,停止事件循环
aeDeleteEventLoop(server.el);
return 0;
}
-
1,2,3处,在前面那篇中已经讲过,主要是初始化各种配置参数,比如socket相关的;redis.conf中涉及的,aof,rdb,replication,sentinel等;redis server自己内部的数据结构等,如runid,配置文件地址,服务器的相关信息(32位还是64位,因为redis直接运行在操作系统上,而不是像高级语言有虚拟机,32位和64位下,不同数据的长度是不同的),日志级别,最大客户端数量,客户端最大idle时间等等
-
4处,因为sentinel和普通的redis server其实是共用同一份代码,所以这里启动时,要看是启动sentinel,还是启动普通的redis server,如果是启动sentinel,则进行sentinel相关配置
-
5处,检查启动时的命令行参数中,是否指定了配置文件,如果指定了,要使用配置文件的配置为准
-
6处,设置为守护进程
-
7处,根据前面的配置,初始化redis server
-
8处,创建pid文件,一般默认路径:/var/run/redis.pid,这个可以在redis.conf进行配置,如:
pidfile "/var/run/redis_6379.pid" -
9处,为服务器进程设置名字
-
10处,打印logo
-
11处,如果不是sentinel模式启动的话,加载aof或rdb文件
-
12处,跳入死循环,开始等待接收连接,处理客户端的请求;同时,周期执行后台任务,比如删除过期key等
-
13处,服务器关闭,一般来说,走不到这里,一般都是陷入在12处的死循环中;只有在某些场景下,将一个全局变量stop修改为true后,程序会从12处跳出死循环,然后走到这里。
初始化redis server的过程
这一节,主要是细化前面的第7步操作,即初始化redis server。这一个函数,位于redis.c中,名为initServer,做的事情很多,接下来会顺序讲解。
设置全局的信号处理函数
// 设置信号处理函数
signal(SIGHUP, SIG_IGN);
signal(SIGPIPE, SIG_IGN);
setupSignalHandlers();
最重要的是最后一行:
void setupSignalHandlers(void) {
// 1
struct sigaction act;
/* When the SA_SIGINFO flag is set in sa_flags then sa_sigaction is used.
* Otherwise, sa_handler is used. */
sigemptyset(&act.sa_mask);
act.sa_flags = 0;
// 2
act.sa_handler = sigtermHandler;
// 3
sigaction(SIGTERM, &act, NULL);
return;
}
3处,设置了:接收到SIGTERM信号时,使用act来处理信号,act在1处定义,是一个局部变量,它有一个字段,在2处被赋值,这是一个函数指针。函数指针类似于java中的一个static方法的引用,为什么是static,因为执行这类方法不需要new一个对象;在c语言中,所有的方法都是最顶级的,调用时,不需要new一个对象;所以,从这点来说,c语言的函数指针类似java中的static方法的引用。
我们可以看看2处,
act.sa_handler = sigtermHandler;
这个sigtermHandler,应该就是一个全局函数了,看看其怎么被定义的:
// SIGTERM 信号的处理器
static void sigtermHandler(int sig) {
REDIS_NOTUSED(sig);
redisLogFromHandler(REDIS_WARNING,"Received SIGTERM, scheduling shutdown...");
// 打开关闭标识
server.shutdown_asap = 1;
}
这个函数就是打开server这个全局变量的shutdown_asap。这个字段在以下地方被使用:
serverCron in redis.c
/* We received a SIGTERM, shutting down here in a safe way, as it is
* not ok doing so inside the signal handler. */
// 服务器进程收到 SIGTERM 信号,关闭服务器
if (server.shutdown_asap) {
// 尝试关闭服务器
if (prepareForShutdown(0) == REDIS_OK) exit(0);
// 如果关闭失败,那么打印 LOG ,并移除关闭标识
redisLog(REDIS_WARNING,"SIGTERM received but errors trying to shut down the server, check the logs for more information");
server.shutdown_asap = 0;
}
以上这段代码的第一行,标识了这段代码所处的位置,为redis.c中的serverCron函数,这个函数,就是redis server的周期执行函数,类似于java中的ScheduledThreadPoolExecutor,当这个周期任务,检测到server.shutdown_asap打开后,就会去关闭服务器。
那,上面这个接收到信号,要执行的动作说完了,那么,什么是信号,信号其实是linux下进程间通讯的一种手段,比如kill -9 ,就会给对应的pid,发送一个SIGKILL 命令;在redis前台运行时,你按下ctrl + c,其实也是发送了一个信号,信号为SIGINT,值为2。大家可以看下图:
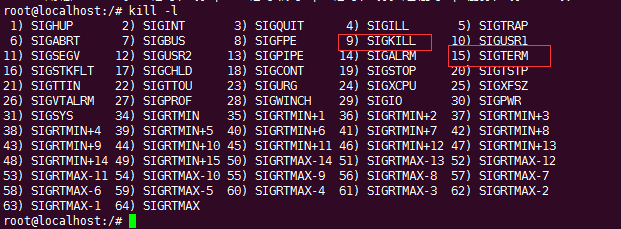
那么,前面我们注册的信号是哪个呢,是:SIGTERM,15。也就是我们按下kill -15时,会触发这个信号。
关于kill 9 和kill 15的差别,可以看这篇博客:
开启syslog
// 设置 syslog
if (server.syslog_enabled) {
openlog(server.syslog_ident, LOG_PID | LOG_NDELAY | LOG_NOWAIT,
server.syslog_facility);
}
这个就是发送日志到linux系统的syslog,可以看看openlog函数的说明:
send messages to the system logger
这个感觉用得不多,可以查阅:
初始化当前redisServer的部分属性
// 初始化并创建数据结构
server.current_client = NULL;
// 1
server.clients = listCreate();
server.clients_to_close = listCreate();
server.slaves = listCreate();
server.monitors = listCreate();
server.slaveseldb = -1; /* Force to emit the first SELECT command. */
server.unblocked_clients = listCreate();
server.ready_keys = listCreate();
server.clients_waiting_acks = listCreate();
server.get_ack_from_slaves = 0;
server.clients_paused = 0;
这个其实没啥说的,大家看到,比如1处,这个server.clients,server是一个全局变量,维护当前redis server的各种状态,clients呢,是用来保存当前连接到redis server的客户端,类型为链表:
// 一个链表,保存了所有客户端状态结构
list *clients; /* List of active clients */
所以,这里其实就是调用listCreate(),创建了一个空链表,然后赋值给clients。
其他属性,类似。
创建常量字符串池,供复用
大家知道,redis在返回响应的时候,通常就是一句:"+OK"之类的。这个字符串,如果每次响应的时候,再去new一个,也太浪费了,所以,干脆,redis自己把这些常用的字符串,缓存了起来。
void createSharedObjects(void) {
int j;
// 常用回复
shared.crlf = createObject(REDIS_STRING,sdsnew("\r\n"));
shared.ok = createObject(REDIS_STRING,sdsnew("+OK\r\n"));
shared.err = createObject(REDIS_STRING,sdsnew("-ERR\r\n"));
...
// 常用错误回复
shared.wrongtypeerr = createObject(REDIS_STRING,sdsnew(
"-WRONGTYPE Operation against a key holding the wrong kind of value\r\n"));
...
}
这个和java中,把字符串字面量缓存起来,是一样的,都是为了提高性能;java里,不是还把128以内的整数也缓存了吗,对吧。
调整进程可以打开的最大文件数
服务器一般在真实线上环境,如果是需要应对高并发的话,可能会有几十上百万的客户端,和服务器上的某个进程,建立tcp连接,而这时候,一般就需要调整进程可以打开的最大文件数(socket也是文件)。
在阅读redis源码之前,我知道的,修改进程可以打开的最大文件数的方式是通过ulimit,具体的,大家可以看下面这两个链接:
但是,在这个源码中,发现了另外一种方式:
- 获取当前的指定资源的限制值的api
#define RLIMIT_NOFILE 5 /* max number of open files */
struct rlimit {
rlim_t rlim_cur;
rlim_t rlim_max;
};
struct rlimit limit;
getrlimit(RLIMIT_NOFILE,&limit)
上面这个代码,获取当前系统中,NOFILE(进程最大文件数)这个值的资源限制大小。
通过man getrlimit(需要先安装,安装方式:yum install man-pages.noarch),可以看到:

-
setrlimit则可以设置资源的相关限制
limit.rlim_cur = f; limit.rlim_max = f; setrlimit(RLIMIT_NOFILE,&limit)
创建事件循环相关数据结构
事件循环器的结构如下:
/*
* State of an event based program
*
* 事件处理器的状态
*/
typedef struct aeEventLoop {
// 目前已注册的最大描述符
int maxfd; /* highest file descriptor currently registered */
// 目前已追踪的最大描述符
int setsize; /* max number of file descriptors tracked */
// 用于生成时间事件 id
long long timeEventNextId;
// 最后一次执行时间事件的时间
time_t lastTime; /* Used to detect system clock skew */
// 已注册的文件事件
aeFileEvent *events; /* Registered events */
// 已就绪的文件事件
aeFiredEvent *fired; /* Fired events */
// 时间事件
aeTimeEvent *timeEventHead;
// 事件处理器的开关
int stop;
// 多路复用库的私有数据
void *apidata; /* This is used for polling API specific data */
// 在处理事件前要执行的函数
aeBeforeSleepProc *beforesleep;
} aeEventLoop;
初始化上面这个数据结构的代码在:aeCreateEventLoop in redis.c
上面这个结构中,主要就是:
-
apidata中,主要用于存储多路复用库的相关数据,每次调用多路复用库,去进行select时,如果发现有就绪的io事件发生,就会存放到 fired 属性中。
比如,select就是linux下,老版本的linux内核中,多路复用的一种实现,redis中,其代码如下:
static int aeApiPoll(aeEventLoop *eventLoop, struct timeval *tvp) { ... // 1 retval = select(eventLoop->maxfd+1, &state->_rfds,&state->_wfds,NULL,tvp); if (retval > 0) { for (j = 0; j <= eventLoop->maxfd; j++) { ... // 2 eventLoop->fired[numevents].fd = j; eventLoop->fired[numevents].mask = mask; numevents++; } } return numevents; }省略了部分代码,其中,1处,进行select,这一步类似于java中nio的select操作;2处,将select返回的,已就绪的文件描述符,填充到fired 属性。
-
另外,我们提到过,redis有一些后台任务,比如清理过期key,这个不是一蹴而就的;每次周期运行后台任务时,就会去清理一部分,而这里的后台任务,其实就是上面这个数据结构中的时间事件。
// 时间事件 aeTimeEvent *timeEventHead;
分配16个数据库的内存空间
server.db = zmalloc(sizeof(redisDb) * server.dbnum);
打开listen端口,监听请求
/* Open the TCP listening socket for the user commands. */
// 打开 TCP 监听端口,用于等待客户端的命令请求
listenToPort(server.port, server.ipfd, &server.ipfd_count)
这里就是打开平时的6379端口的地方。
初始化16个数据库对应的数据结构
/* Create the Redis databases, and initialize other internal state. */
// 创建并初始化数据库结构
for (j = 0; j < server.dbnum; j++) {
server.db[j].dict = dictCreate(&dbDictType, NULL);
server.db[j].expires = dictCreate(&keyptrDictType, NULL);
server.db[j].blocking_keys = dictCreate(&keylistDictType, NULL);
server.db[j].ready_keys = dictCreate(&setDictType, NULL);
server.db[j].watched_keys = dictCreate(&keylistDictType, NULL);
server.db[j].eviction_pool = evictionPoolAlloc();
server.db[j].id = j;
server.db[j].avg_ttl = 0;
}
db的数据结构如下:
typedef struct redisDb {
// 数据库键空间,保存着数据库中的所有键值对
dict *dict; /* The keyspace for this DB */
// 键的过期时间,字典的键为键,字典的值为过期事件 UNIX 时间戳
dict *expires; /* Timeout of keys with a timeout set */
// 正处于阻塞状态的键
dict *blocking_keys; /* Keys with clients waiting for data (BLPOP) */
// 可以解除阻塞的键
dict *ready_keys; /* Blocked keys that received a PUSH */
// 正在被 WATCH 命令监视的键
dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */
struct evictionPoolEntry *eviction_pool; /* Eviction pool of keys */
// 数据库号码
int id; /* Database ID */
// 数据库的键的平均 TTL ,统计信息
long long avg_ttl; /* Average TTL, just for stats */
} redisDb;
这里可以看到,设置了过期时间的key,除了会在 dict 属性存储,还会新增一条记录到 expires 字典。
expires字典的key:执行键的指针;value:过期时间。
创建pub/sub相关数据结构并初始化
// 创建 PUBSUB 相关结构
server.pubsub_channels = dictCreate(&keylistDictType, NULL);
server.pubsub_patterns = listCreate();
初始化部分统计属性
// serverCron() 函数的运行次数计数器
server.cronloops = 0;
// 负责执行 BGSAVE 的子进程的 ID
server.rdb_child_pid = -1;
// 负责进行 AOF 重写的子进程 ID
server.aof_child_pid = -1;
aofRewriteBufferReset();
// AOF 缓冲区
server.aof_buf = sdsempty();
// 最后一次完成 SAVE 的时间
server.lastsave = time(NULL); /* At startup we consider the DB saved. */
// 最后一次尝试执行 BGSAVE 的时间
server.lastbgsave_try = 0; /* At startup we never tried to BGSAVE. */
server.rdb_save_time_last = -1;
server.rdb_save_time_start = -1;
server.dirty = 0;
resetServerStats();
/* A few stats we don't want to reset: server startup time, and peak mem. */
// 服务器启动时间
server.stat_starttime = time(NULL);
// 已使用内存峰值
server.stat_peak_memory = 0;
server.resident_set_size = 0;
// 最后一次执行 SAVE 的状态
server.lastbgsave_status = REDIS_OK;
server.aof_last_write_status = REDIS_OK;
server.aof_last_write_errno = 0;
server.repl_good_slaves_count = 0;
updateCachedTime();
设置时间事件对应的函数指针
/* Create the serverCron() time event, that's our main way to process
* background operations. */
// 为 serverCron() 创建时间事件
if (aeCreateTimeEvent(server.el, 1, serverCron, NULL, NULL) == AE_ERR) {
redisPanic("Can't create the serverCron time event.");
exit(1);
}
这里的serverCron就是一个函数,后续每次周期触发时间事件时,就会运行这个serverCron。
可以看这里的英文注释,作者也提到,这是主要的处理后台任务的方式。
这块以后也会重点分析。
设置connect事件对应的连接处理器
aeCreateFileEvent(server.el, server.ipfd[j], AE_READABLE, acceptTcpHandler, NULL)
这里的acceptTcpHandler就是处理新连接的函数:
void acceptTcpHandler(aeEventLoop *el, int fd, void *privdata, int mask) {
int cport, cfd, max = MAX_ACCEPTS_PER_CALL;
char cip[REDIS_IP_STR_LEN];
REDIS_NOTUSED(el);
REDIS_NOTUSED(mask);
REDIS_NOTUSED(privdata);
while (max--) {
// accept 客户端连接
cfd = anetTcpAccept(server.neterr, fd, cip, sizeof(cip), &cport);
if (cfd == ANET_ERR) {
if (errno != EWOULDBLOCK)
redisLog(REDIS_WARNING,
"Accepting client connection: %s", server.neterr);
return;
}
// 为客户端创建客户端状态(redisClient)
acceptCommonHandler(cfd, 0);
}
}
创建aof文件
如果aof打开了,就需要创建aof文件。
if (server.aof_state == REDIS_AOF_ON) {
server.aof_fd = open(server.aof_filename,
O_WRONLY | O_APPEND | O_CREAT, 0644);
}
剩下的几个,暂时不涉及的任务
// 如果服务器以 cluster 模式打开,那么初始化 cluster
if (server.cluster_enabled) clusterInit();
// 初始化复制功能有关的脚本缓存
replicationScriptCacheInit();
// 初始化脚本系统
scriptingInit();
// 初始化慢查询功能
slowlogInit();
// 初始化 BIO 系统
bioInit();
上面的几个,我们暂时还讲解不到,先看看就行。
到此,初始化redis server,就基本结束了。
总结
本讲内容较多,主要是redis启动过程中,要做的事,也太多了。希望我已经大致讲清楚了,其中,连接处理器那些都只是大致讲了,后面会继续。谢谢大家。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号