曹工说Tomcat4:利用 Digester 手撸一个轻量的 Spring IOC容器
一、前言
一共8个类,撸一个IOC容器。当然,我们是很轻量级的,但能够满足基本需求。想想典型的 Spring 项目,是不是就是各种Service/DAO/Controller,大家互相注入,就组装成了我们的业务bean,然后再加上 Spring MVC,再往容器里一放,基本齐活。
我们这篇文章,就是要照着 spring 来撸一个 相当简单的 IOC 容器,这个容器可以完成以下功能:
1、在 xml 配置文件里配置 bean 的扫描路径,语法目前只支持 component-scan,但基本够用了;
2、Bean 用 Component 注解,bean 中属性可以用 Autowired 来进行自动注入。
3、可以解决循环依赖问题。
bean的长相,基本就是下面这样:
@Data
@Component
public class Girl {
private String name = "catalina";
private String height;
private String breast;
private String legLength;
private Boolean isPregnant;
@Autowired
private com.ckl.littlespring.Coder coder;
}
xml,长下面这样:
<?xml version="1.0" encoding="UTF-8"?>
<beans>
<component-scan base-package="com.ckl.littlespring"/>
</beans>
二、思路
1、要解析xml,这个可以用Tomcat Digester 实现,这个是神器,用这个基本解决了读配置文件的问题;
2、读取xml配置的包名下的所有class,这个可以参考Spring,我是在网上找的一个工具类,反正就是利用类加载器获取classpath下的jar、class等,然后根据包名来过滤;
3、从第二步获取的class集合中,过滤出来注解了 @Component 的类,并利用反射读取其name、type、field集合等,其中field集合需要把带有 @Autowired 的过滤出来,用所有这些信息,构造一个 BeanDefinition 对象,放到 BeanDefinition 集合;
4、遍历第三步的BeanDefinition集合,根据 BeanDefinition 生成 Bean,如果该 BeanDefinition 中的field依赖了其他bean,则递归处理,获取到 field 后,反射设置到 bean中。
三、实现
1、代码结构、效果展示
强烈建议大家直接把代码拉下来跑,跑一跑,打个断点,几乎都不用看我写的了。源码路径:
代码结构如下图:
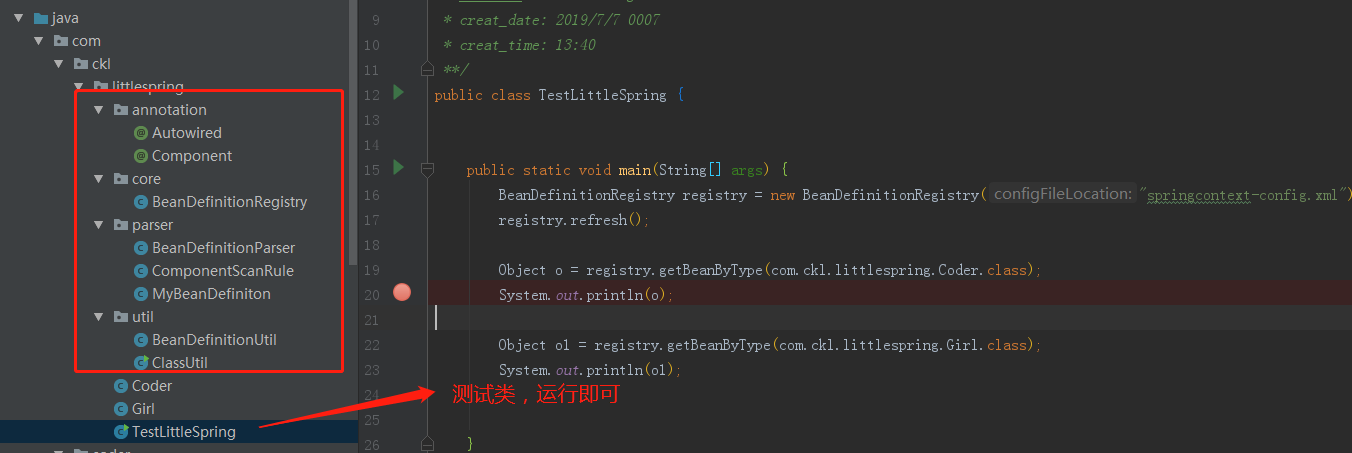
大家看上图,测试类中,主要是 new了 BeanDefinitionRegistry,这个就是我们的 bean 容器,可理解为 Spring 里面的 org.springframework.beans.factory.support.DefaultListableBeanFactory,当然,我们的是玩具而已。该类的构造函数,接收一个参数,就是配置文件的位置,默认会去classpath下查找该文件。bean 容器生成后,我们手动调用 refresh 来初始化容器,并生成 bean。 最后,我们既可以通过 getBeanByType(Class clazz) 来获取想要的 bean了。
在测试代码中,Girl 和 Coder 循环依赖,咱们可以看看实际执行效果:
1 package com.ckl.littlespring;
2
3 import com.ckl.littlespring.annotation.Autowired;
4 import com.ckl.littlespring.annotation.Component;
5 import lombok.Getter;
6 import lombok.Setter;
7
8 @Getter
9 @Setter
10 @Component
11 public class Coder {
12 private String name = "xiaoming";
13
14 private String sex;
15
16 private String love;
17 /**
18 * 女朋友
19 */
20 @Autowired
21 private com.ckl.littlespring.Girl girl;
22
23
24 }
1 package com.ckl.littlespring;
2
3 import com.ckl.littlespring.annotation.Autowired;
4 import com.ckl.littlespring.annotation.Component;
5 import com.coder.SaxTest;
6 import lombok.Data;
7
8
9 @Data
10 @Component
11 public class Girl {
12 private String name = "catalina";
13 private String height;
14 private String breast;
15 private String legLength;
16
17 private Boolean isPregnant;
18
19 @Autowired
20 private com.ckl.littlespring.Coder coder;
21
22
23
24 }
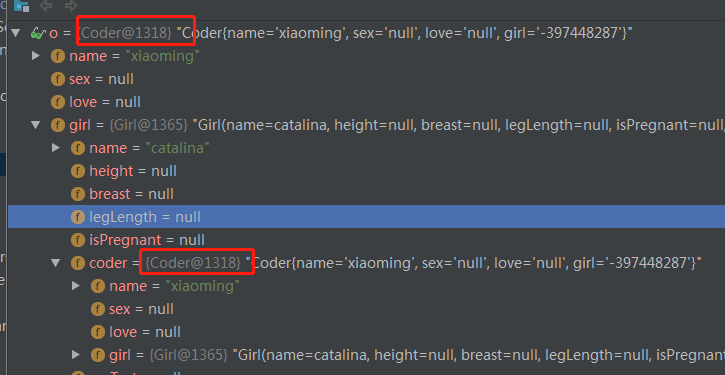
可以看到,没什么问题,好了,接下来,看实现,我们按初始化--》使用的步骤来。
2、BeanDefinitionRegistry 初始化
/**
* bean定义解析器
*/
private BeanDefinitionParser parser;
public BeanDefinitionRegistry(String configFileLocation) {
parser = new BeanDefinitionParser(configFileLocation);
}
该bean容器中,构造函数中,将配置文件直接传给了解析器,解析器 BeanDefinitionParser 会真正负责从 xml 文件内读取 BeanDefinition。
3、 BeanDefinitionParser 初始化
1 @Data
2 public class BeanDefinitionParser {
3 /**
4 * xml 解析器
5 */
6 private Digester digester;
7
8 private String configFileLocation;
9
10
11 private List<MyBeanDefiniton> myBeanDefinitonList = new ArrayList<>();
12
13
14
15 public BeanDefinitionParser(String configFileLocation) {
16 this.configFileLocation = configFileLocation;
17 digester = new Digester();
18 }
19 }
BeanDefinitionParser 中一共三个field,一个为配置文件位置,一个为Tomcat Digester,一个用于存储解析到的 BeanDefinition。Tomcat Digester用于解析 xml,这个一会实际的解析过程我们再说它。构造函数中,主要是给配置文件赋值,以及生成 Digester实例。
4、refresh 方法解析
初始化完成后,调用BeanDefinitionRegistry 的 refresh 解析:
1 public void refresh() {
2 /**
3 * 判断是否已经解析完成bean定义。如果没有完成,则先进行解析
4 */
5 if (!hasBeanDefinitionParseOver) {
6 parser.parse();
7 hasBeanDefinitionParseOver = true;
8 }
9
10 /**
11 * 初始化所有的bean,完成自动注入
12 */
13 for (MyBeanDefiniton beanDefiniton : getBeanDefinitions()) {
14 getBean(beanDefiniton);
15 }
16 }
这里,关注第6行,因为是首次解析,所以要进入BeanDefinitionParser .parse方法。
1 /**
2 * 根据指定规则,解析xml
3 */
4 public void parse() {
5 digester.setValidating(false);
6 digester.setUseContextClassLoader(true);
7
8 // Configure the actions we will be using
9 digester.addRule("beans/component-scan",
10 new ComponentScanRule(this));
11
12 InputSource inputSource = null;
13 InputStream inputStream = null;
14 try {
15 inputStream = Thread.currentThread().getContextClassLoader().getResourceAsStream(configFileLocation);
16 inputSource = new InputSource(inputStream);
17 inputSource.setByteStream(inputStream);
18 Object o = digester.parse(inputSource);
19 System.out.println(o);
20 } catch (Exception e) {
21 e.printStackTrace();
22 }
23 }
先关注第9、10行,配置解析规则,在解析xml时,遇到 beans元素下的component-scan时,则回调 ComponentScanRule 的规则。第18行,真正开始解析xml。
我们看看 ComponentScanRule 的实现:
1 package com.ckl.littlespring.parser;
2
3 import org.apache.commons.digester3.Rule;
4 import org.xml.sax.Attributes;
5
13 public class ComponentScanRule extends Rule {
14
15 private String basePackage;
16
17 private BeanDefinitionParser beanDefinitionParser;
18
19 public ComponentScanRule(BeanDefinitionParser beanDefinitionParser) {
20 this.beanDefinitionParser = beanDefinitionParser;
21 }
22
23 @Override
24 public void begin(String namespace, String name, Attributes attributes) throws Exception {
25 basePackage = attributes.getValue("base-package");
26 beanDefinitionParser.doScanBasePackage(basePackage);
27 }
28
29 @Override
30 public void end(String namespace, String name) throws Exception {
31
32 }
33 }
关注25/26行,这里从xml中获取属性 base-package,然后再调用 com.ckl.littlespring.parser.BeanDefinitionParser#doScanBasePackage 来进行处理。
1 /**
2 * 当遇到component-scan元素时,该函数被回调,解析指定包下面的bean 定义,并加入bean 定义集合
3 * @param basePackage
4 */
5 public void doScanBasePackage(String basePackage) {
6 Set<Class<?>> classSet = ClassUtil.getClasses(basePackage);
7
8 if (classSet == null) {
9 return;
10 }
11
12 //过滤出带有Component注解的类,并将其转换为beanDefinition
13 List<Class<?>> list = classSet.stream().filter(clazz -> clazz.getAnnotation(Component.class) != null).collect(Collectors.toList());
14
15 for (Class<?> clazz : list) {
16 MyBeanDefiniton myBeanDefiniton = BeanDefinitionUtil.convert2BeanDefinition(clazz);
17 myBeanDefinitonList.add(myBeanDefiniton);
18 }
19
20 }
以上方法执行结束时,basePackage下的被 Component 注解的 class就收集完毕。具体怎么实现的?
1、调用 ClassUtil.getClasses(basePackage); 来获取指定包下面的全部class
2、从第一步的集合中,过滤出带有 Component 注解的class
3、利用 工具类 BeanDefinitionUtil.convert2BeanDefinition,从class 中提取 bean 定义的各类属性。
先看看 BeanDefinition 的定义:
1 package com.ckl.littlespring.parser;
2
3 import lombok.Data;
4
5 import java.lang.reflect.Field;
6 import java.util.List;
7
8
9 @Data
10 public class MyBeanDefiniton {
11
12 /**
13 * bean的名字,默认使用类名,将首字母变成小写
14 */
15 private String beanName;
16
17 /**
18 * bean的类型
19 */
20 private String beanType;
21
22 /**
23 * bean的class
24 */
25 private Class<?> beanClazz;
26
27 /**
28 * field依赖的bean
29 */
30 private List<Field> dependencysByField;
31
32
33 }
就几个属性,相当简单,下面看 BeanDefinitionUtil.convert2BeanDefinition:
1 public static MyBeanDefiniton convert2BeanDefinition(Class<?> clazz){
2 MyBeanDefiniton definiton = new MyBeanDefiniton();
3 String name = clazz.getName();
4 definiton.setBeanName(name.substring(0,1).toLowerCase() + name.substring(1));
5 definiton.setBeanType(clazz.getCanonicalName());
6 definiton.setBeanClazz(clazz);
7
8 Field[] fields = clazz.getDeclaredFields();
9 if (fields == null || fields.length == 0){
10 return definiton;
11 }
12
13 ArrayList<Field> list = new ArrayList<>();
14 list.addAll(Arrays.asList(fields));
15 List<Field> dependencysField = list.stream().filter(field -> field.getAnnotation(Autowired.class) != null).collect(Collectors.toList());
16 definiton.setDependencysByField(dependencysField);
17
18 return definiton;
19 }
最重要的就是第 15/16行,从所有的 field 中获取 带有 autowired 注解的field。这些 field 都是需要进行自动注入的。
执行完以上这些后,com.ckl.littlespring.parser.BeanDefinitionParser#myBeanDefinitonList 就持有了所有的 BeanDefinition。 下面就开始进行自动注入了,let's go!
5、bean初始化,完成自动注入
我们接下来,再看一下 BeanDefinitionRegistry 中的refresh,上面我们完成了 parser.parse 方法,此时,BeanDefinitionParser#myBeanDefinitonList 已经准备就绪了。
1 public void refresh() {
2 /**
3 * 判断是否已经解析完成bean定义。如果没有完成,则先进行解析
4 */
5 if (!hasBeanDefinitionParseOver) {
6 parser.parse();
7 hasBeanDefinitionParseOver = true;
8 }
9
10 /**
11 * 初始化所有的bean,完成自动注入
12 */
13 for (MyBeanDefiniton beanDefiniton : getBeanDefinitions()) {
14 getBean(beanDefiniton);
15 }
16 }
我们要关注的是,第13行,getBeanDefinitions()主要是从 parser 中获取 BeanDefinition 集合。因为是内部使用,我们定义为private。
1 private List<MyBeanDefiniton> getBeanDefinitions() {
2 return parser.getBeanDefinitions();
3 }
然后,我们关注第14行,getBean 会真正完成 bean 的创建,如果有依赖的field,则会进行注入。
1 /**
2 * 根据bean 定义获取bean
3 * 1、先查bean容器,查到则返回
4 * 2、生成bean,放进容器(此时,依赖还没注入,主要是解决循环依赖问题)
5 * 3、注入依赖
6 *
7 * @param beanDefiniton
8 * @return
9 */
10 private Object getBean(MyBeanDefiniton beanDefiniton) {
11 Class<?> beanClazz = beanDefiniton.getBeanClazz();
12 Object bean = beanMapByClass.get(beanClazz);
13 if (bean != null) {
14 return bean;
15 }
16
17 //没查到的话,说明还没有,需要去生成bean,然后放进去
18 try {
19 bean = beanClazz.newInstance();
20 } catch (InstantiationException | IllegalAccessException e) {
21 e.printStackTrace();
22 return null;
23 }
24
25 // 先行暴露,解决循环依赖问题
26 beanMapByClass.put(beanClazz, bean);
27
28 //注入依赖,如果没有依赖的field,直接返回
29 List<Field> dependencysByField = beanDefiniton.getDependencysByField();
30 if (dependencysByField == null) {
31 return bean;
32 }
33
34 for (Field field : dependencysByField) {
35 try {
36 autowireField(beanClazz, bean, field);
37 } catch (Exception e) {
38 throw new RuntimeException(beanClazz.getName() + " 创建失败",e);
39 }
40 }
41
42 return bean;
43 }
在这个方法里,我们主要就是,创建了 bean,并且放到了 容器中(一个hashmap,key是class,value就是对应的bean实例)。我们关注第36行,这里会进行field 的注入:
1 private void autowireField(Class<?> beanClazz, Object bean, Field field) {
2 Class<?> fieldType = field.getType();
3 List<MyBeanDefiniton> beanDefinitons = getBeanDefinitions();
4 if (beanDefinitons == null) {
5 return;
6 }
7
8 // 根据类型去所有beanDefinition看,哪个类型是该类型的子类;把满足的都找出来
9 List<MyBeanDefiniton> candidates = beanDefinitons.stream().filter(myBeanDefiniton -> {
10 return fieldType.isAssignableFrom(myBeanDefiniton.getBeanClazz());
11 }).collect(Collectors.toList());
12
13 if (candidates == null || candidates.size() == 0) {
14 throw new RuntimeException(beanClazz.getName() + "根据类型自动注入失败。field:" + field.getName() + " 无法注入,没有候选bean");
15 }
16 if (candidates.size() > 1) {
17 throw new RuntimeException(beanClazz.getName() + "根据类型自动注入失败。field:" + field.getName() + " 无法注入,有多个候选bean" + candidates);
18 }
19
20 MyBeanDefiniton candidate = candidates.get(0);
21 Object fieldBean;
22 try {
23 // 递归调用
24 fieldBean = getBean(candidate);
25 field.setAccessible(true);
26 field.set(bean, fieldBean);
27 } catch (Exception e) {
28 throw new RuntimeException("注入属性失败:" + beanClazz.getName() + "##" + field.getName(), e);
29 }
30
31
32 }
这里,我们先看第10行,我们要根据field 的 类型,看看当前的bean 容器中有没有 field 类型的bean,比如我们的 field 的类型是个接口,那我们就会去看有没有实现类。
这里有两个异常可能会抛出,如果一个都没找到,无法注入;如果找到了多个,我们也判断为无法注入。(基础版本,暂没考虑 spring 中的 qualifier 注解)
最后,我们在第24行,根据找到的 beanDefinition 查找 bean,这里是个递归调用。 找到之后,会设置到 对应的 field 中。
注意的是,该递归的终结条件就是,该 bean 没有依赖需要注入。 完成所有这些步骤后,我们的 bean 都注册到了 BeanDefinitionRegistry#beanMapByClass 中。
1 /**
2 * map:存储 bean的class-》bean实例
3 */
4 private Map<Class, Object> beanMapByClass = new ConcurrentHashMap<>();
后续,只需要根据class来查找对应的bean即可。
1 /**
2 * 根据类型获取bean对象
3 *
4 * @param clazz
5 * @return
6 */
7 public Object getBeanByType(Class clazz) {
8 return beanMapByClass.get(clazz);
9 }
四、总结
一个简易的ioc,大概就是这样子了。后边有时间,再把 aop 的功能加进去。当然,加进去了依然是玩具,我们造轮子的意义在哪里呢?大概就是让你更懂我们现在在用的轮子,知道它的核心代码大概是什么样子的。我们虽然大部分时候都是api 调用者,写点胶水,但是真正出问题的时候,当框架不满足的时候,我们还是得有搞定问题和扩展框架的能力。
个人水平也很有限,大家可以批评指正,欢迎加入下发二维码的 Java 交流群一起沟通学习。
源码在github,链接在上文发过了哈。
参考的工具类链接:https://www.cnblogs.com/Leechg/p/10058763.html 其中有可以优化的空间,不过用着还是不错。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号