缓存使用问题
一. 缓存穿透
当热点数据为空时,将会有大量请求到缓存,一旦数据库承受不了用户请求,查询就会变慢,大量的请求也会阻塞在数据库查询上,造成应用服务器的连接和线程资源被占满,最终导致系统崩溃,这样称为缓存穿透。
通常解决方案:
- 返回空值
我们从数据库中查询到空值或者发生异常时,我们可以向缓存中回种一个空值。但是因为空值并不是准确的业务数据,并且会占用缓存的空间,所以我们会给这个空值加一个比较短的过期时间,让空值在短时间之内能够快速过期淘汰。
Object nullValue = new Object();
try {
Object valueFromDB = getFromDB(uid); //从数据库中查询数据
if (valueFromDB == null) {
cache.set(uid, nullValue, 10); //如果从数据库中查询到空值,就把空值写入缓存,设置较短的超时时间
} else {
cache.set(uid, valueFromDB, 1000);
}
} catch(Exception e) {
cache.set(uid, nullValue, 10);
}
-
使用布隆过滤器
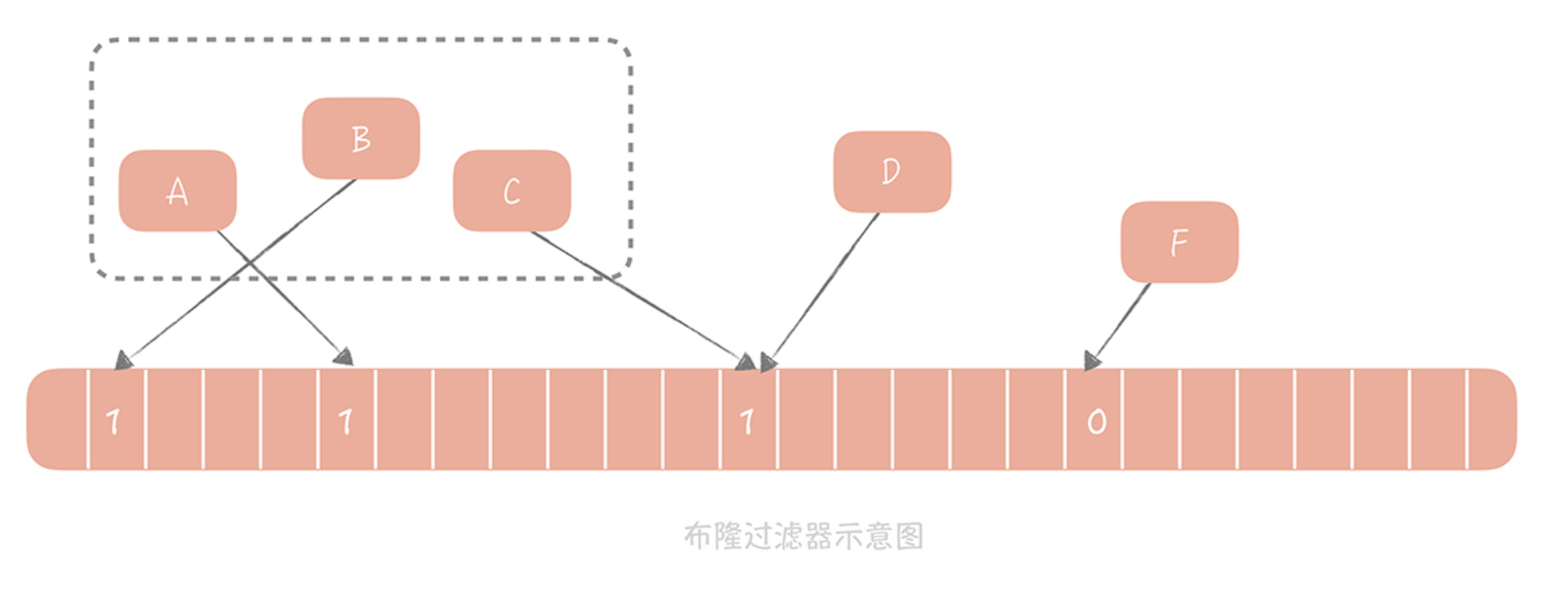
在请求之前,先使用二进制Hash数组用来判断一个元素是否在一个集合中,如果不存在就直接返回空值,而不需要继续查询数据库和缓存,这样就可以极大地减少异常查询带来的缓存穿透。
把每个值按照提供的Hash算法算出对应的Hash值,然后将Hash值对数组长度取模后得到需要计入数组的索引值,存在值为1,不存在值为0。
缺点:
- 因为Hash冲突,所以存在错误几率。
- 不支持删除元素,因为同一个位置可能有多个值。
- 使用分布式锁
分布式锁的方式也比较简单,比方说ID为1的用户是一个热点用户,当他的用户信息缓存失效后,我们需要从数据库中重新加载数据时,先写入一个Key为"lock.1"的缓存项,然后去数据库里面加载数据,当数据加载完成后再把这个Key删掉。这时,如果另外一个线程也要请求这个用户的数据,它发现缓存中有Key为“lock.1”的缓存,就认为目前已经有线程在加载数据库中的值到缓存中了,它就可以重新去缓存中查询数据,不再穿透数据库了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号