Zebra分库分表原则
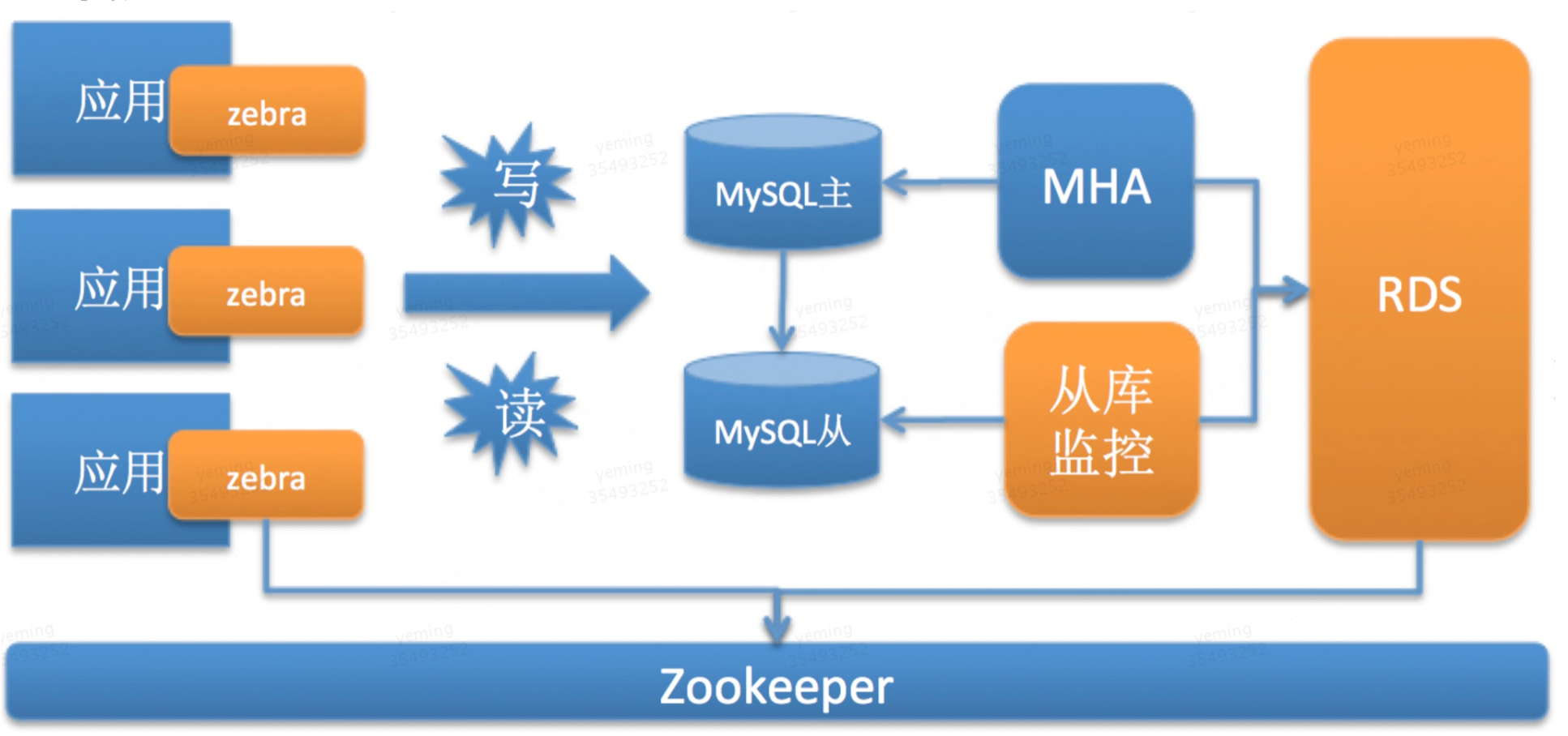
zebra是一个基于JDBC API协议上开发出的高可用、高性能的数据库访问层解决方案。通俗来说就是数据库访问的中间件,在JDBC和数据库连接池之上实现读写分离、分库分布等功能。一般来说Zebra在数据访问架构中位置如下[2]:
-
Zookeeper/OCTO/Nacos:注册中心,存储了数据库的路由信息、用户名密码等信息
-
Zebra:从zookeeper从注册中心拉取数据库信息,然后直连数据库,进行读写分离和分库分表。
-
MHA/ORC/Adha: 数据库高可用服务服务。它的目标是在机房故障,硬件故障、网络抖动、实例故障和流量异常等故障场景下,一旦发生主库故障,MHA会保证切换到某个从库上并把数据库保证一致性。
-
从库监控系统:负责数据库集群中从库的高可用。它的目标是一旦发生从库故障,该服务会把该从库自动摘除。
-
RDS:数据库管理员的管理平台,负责数据库的创建、维护、扩容以及维护zebra的配置信息
-
MySQL:关系型数据库
-
Leaf:分布式ID生成服务。在分库分表后,我们不能再使用mysql的自增主键。因为在插入记录的时候,不同的库生成的记录的自增id可能会出现冲突。在分布式MYSQL中,Leaf能为处在不同分库的相同表生成一个全局的id
1.zebra结构
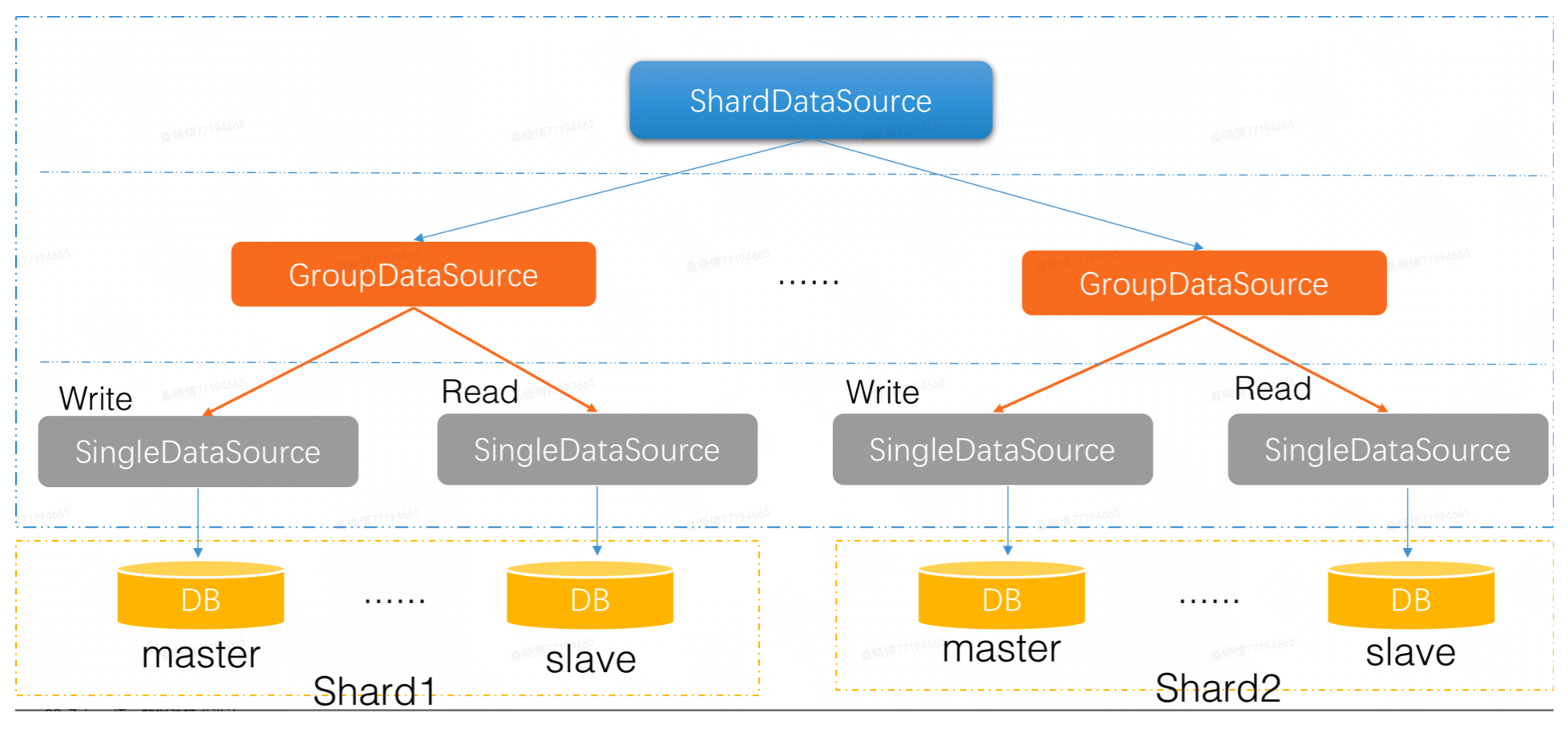
-
ShardDataSource:负责分库分表。
- 它主要判断SQL落在那个分片(数据库集群/GroupDataSource),然后把相应的SQL经过处理后发送给GroupDataSource。
- 它会连接多个数据库集群,因此它会包含若干个GroupDataSource。
-
GroupDataSource: 负责读写分离。
- 它判断SQL是读还是写,然后把SQL发送给相应的SingleDataSource。
- 它的范围是一个主从数据库集群,因此它会包含若干个SingleDataSource。
-
SingleDataSource:负责抽象底层使用的连接池类型(c3p0,druid,tomcat-jdbc等),然后直连每一个数据库实例。每一个Master或者Slave,都对应一个SingleDataSource。
2. ShardDataSource:分库分表
ShardDataSource负责分库分表的连接池,它主要判断SQL的落到哪个分片上,然后把相应的SQL经过处理后发送给GroupDataSource。
2.1 分库分表
读写分离,主要是为了数据库读能力的水平扩展。而分库分表则是为了写能力的水平扩展。
一旦业务表中的数据量大了,从维护和性能角度来看,无论是任何的 CRUD 操作,对于数据库而言都是一件极其耗费资源的事情。即便设置了索引, 仍然无法掩盖因为数据量过大从而导致的数据库性能下降的事实 ,这个时候就该对数据库进行水平分区 (sharding,即分库分表 ),将原本一张表维护的海量数据分配给 N 个子表进行存储和维护。
优点:
- 降低单台机器的负载压力,提升写入性能
- 提高了DB的并发量。除了提高写的效率
- 更重要的是提高读的效率,提高查询的性能。
- 还有诸如写操作的锁操作等,都会带来很多显然的好处。
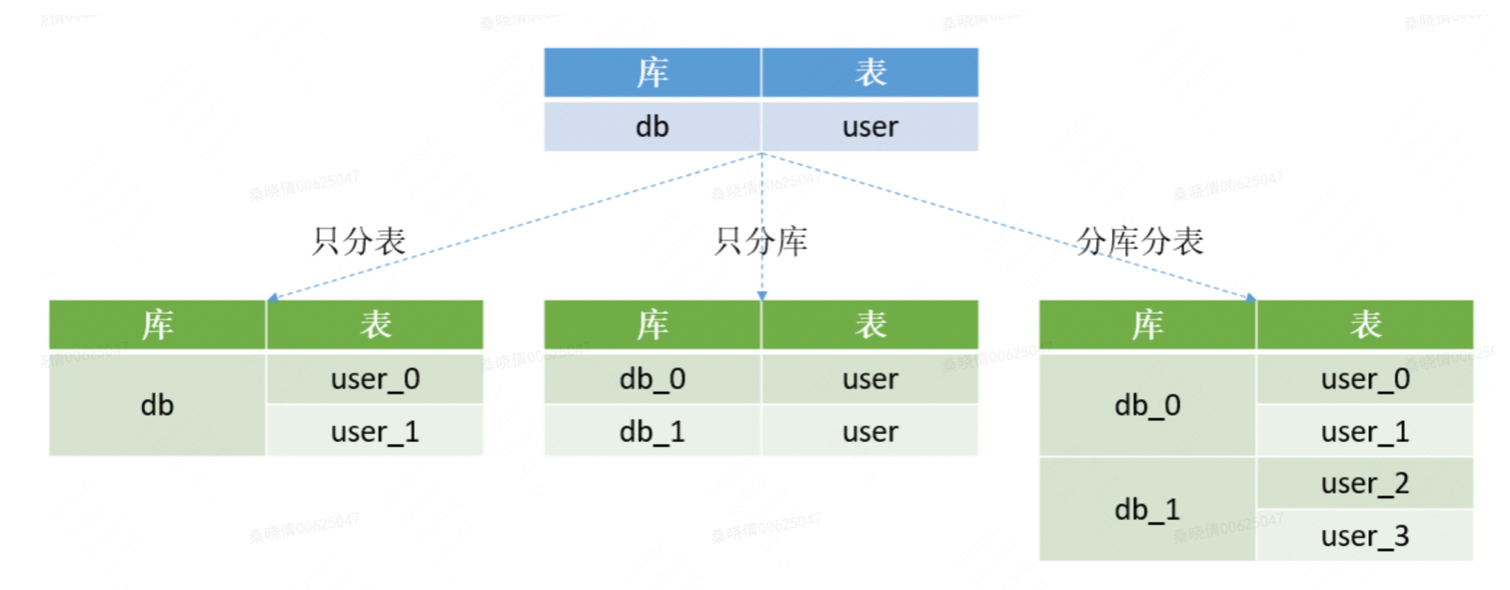
1. 分库分表的3种形式
- 只分库:将db库拆分为db_0和db_1两个库,同时在db_0和db_1库中各自新建一个user表,db_0.user表和db_1.user表中各自只存原来的db.user表中的部分数据。
- 只分表:将db库中的user表拆分为2个分表,user_0和user_1,这两个表还位于同一个库中。
- 分库分表:将db库拆分为db_0和db_1两个库,db_0中包含user_0、user_1两个分表,db_1中包含user_2、user_3两个分表。
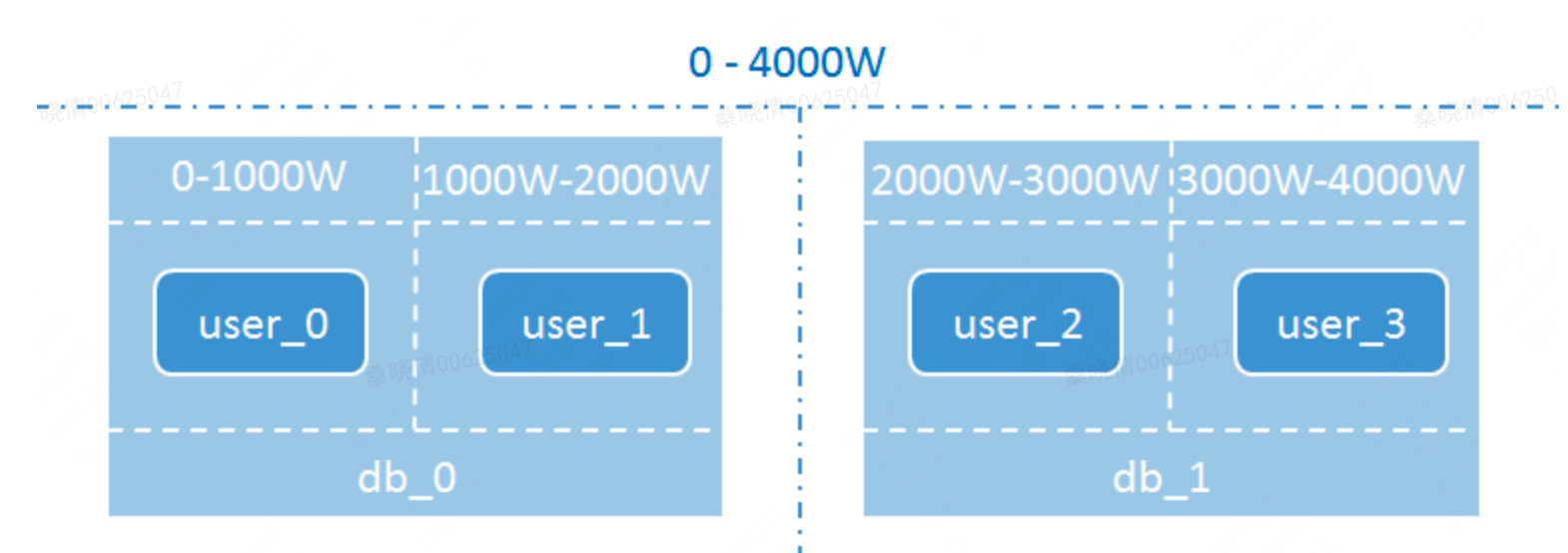
分库分表示例:假设db库的user表中原来有4000W条数据,现在将db库拆分为2个分库db_0和db_1,user表拆分为user_0、user_1、user_2、user_3四个分表,每个分表存储1000W条数据。
2.2 配置信息
- ruleName:分表分表规则,集中式配置在配置中心上面
- routerFactory:本地分表规则,先获取本地分库分表规则,如果没有配置,则从配置中心上获取ruleName分库分表规则
- dataSourcePool:配置若干个GroupDataSource或者SingleDataSource
- parallelCorePoolSize:线程池线程数
- parallelMaxPoolSize:线程池最大线程数
- parallelWorkQueueSize:等待队列
- parallelExecuteTimeOut:SQL在线程池中的超时时间
<!-- GroupDataSource或SingleDataSource的配置这里不再详细说明,请参考zebra接入指南 -->
<bean id="zebraDs0" class="com.dianping.zebra.single.jdbc.SingleDataSource" init-method="init" destroy-method="close">
<property name="jdbcUrl" value="jdbc:mysql:"/>
......
</bean>
<bean id="zebraDs1" class="com.dianping.zebra.group.jdbc.GroupDataSource" init-method="init" destroy-method="close">
<property name="jdbcRef" value="tuangou2010" />
......
</bean>
<bean id="zebraDs2" class="com.dianping.zebra.single.jdbc.SingleDataSource" init-method="init" destroy-method="close">
......
</bean>
<bean id="zebraDs3" class="com.dianping.zebra.single.jdbc.SingleDataSource" init-method="init" destroy-method="close">
......
</bean>
<!-- ShardDatasource接入配置 -->
<bean id="zebraDS" class="com.dianping.zebra.shard.jdbc.ShardDataSource" init-method="init">
<property name="dataSourcePool">
<map>
<entry key="id0" value-ref="zebraDs0"/>
<entry key="id1" value-ref="zebraDs1"/>
<entry key="id2" value-ref="zebraDs2"/>
<entry key="id3" value-ref="zebraDs3"/>
</map>
</property>
<!--ruleName是分库分表的规则名,集中式配置在配置中心-->
<property name="ruleName" value="welife"/>
<!--routerFactory:本地分表规则,先获取本地分库分表规则,如果没有配置,则从配置中心上获取ruleName分库分表规则-->
<property name="routerFactory">
<bean class="com.dianping.zebra.shard.router.builder.XmlResourceRouterBuilder">
<constructor-arg value="spring/shard/router-local-rule.xml"/>
</bean>
</property>
<!--线程池相关的配置,用户可根据实际需要自行调整-->
<property name="parallelCorePoolSize" value="16" />
<property name="parallelMaxPoolSize" value="32" />
<property name="parallelWorkQueueSize" value="500" />
<property name="parallelExecuteTimeOut" value="3000" />
<!-- 连接池相关的配置,可以参考GroupDatasource配置,属性相同 -->
<property name="poolType" value="druid" />
<property name="minPoolSize" value="5" />
</bean>
分表规则配置(spring/shard/router-local-rule.xml)
<?xml version="1.0" encoding="UTF-8"?>
<router-rule>
<table-shard-rule table="Feed" generatedPK="id">
<shard-dimension dbRule="#id#%4" dbIndexes="dbname[0-3]" tbRule="#id#.intdiv(4)%2" tbSuffix="alldb:[0,7]" isMaster="true">
</shard-dimension>
</table-shard-rule>
</router-rule>
2.3 分库分表挑战
- 分库分表的增删改功能
分库分表之后,希望能向单库单表那样去操作数据库。
例如我们要批量插入四条用户记录,并且希望根据用户的id字段,确定这条记录插入哪个库的哪张表。例如1号记录插入user_1表,2号记录插入user_2表,3号记录插入user_3表,4号记录插入user_0表。sql如下:
insert into user(id,name) values (1,”tianshouzhi”),(2,”huhuamin”), (3,”wanghanao”),(4,”luyang”)
分库分表的具体流程可以用下图进行描述:
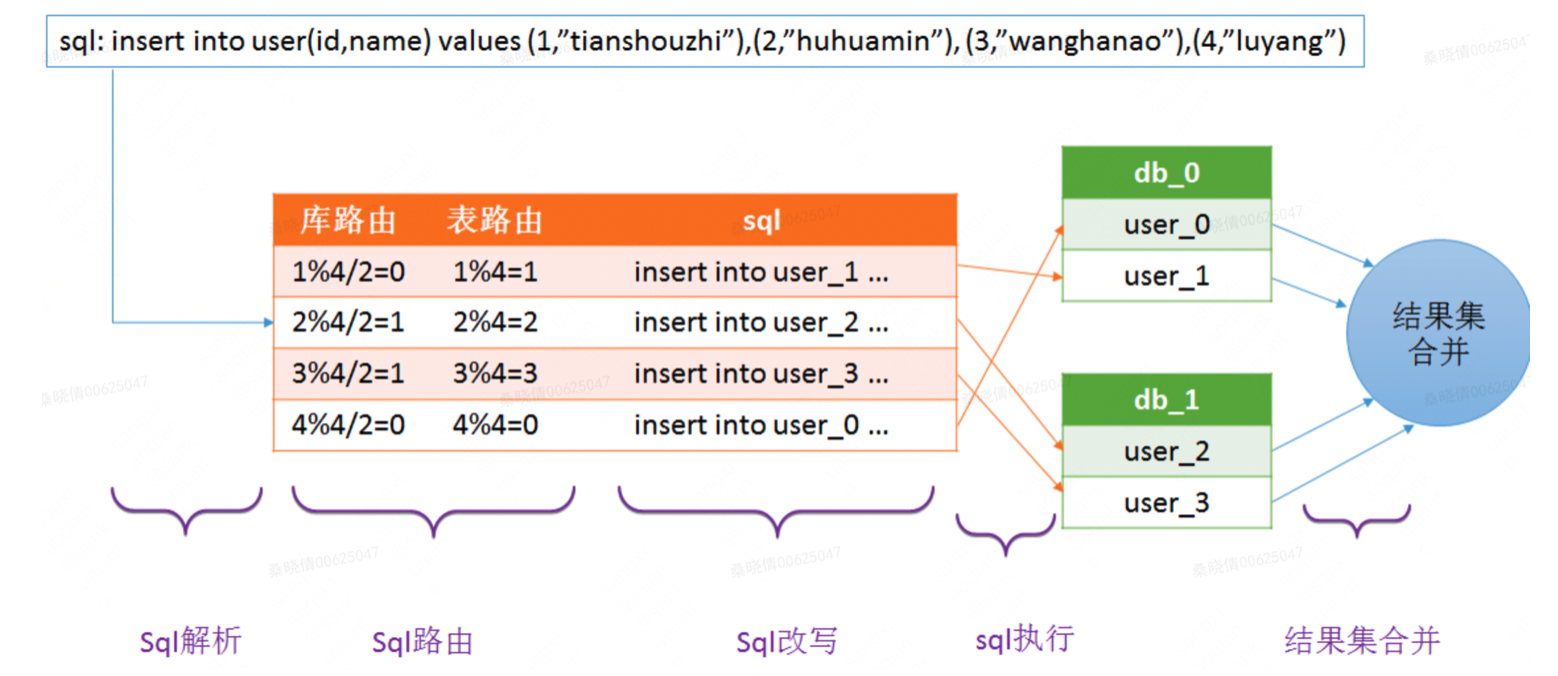
- sql解析:首先对sql进行解析,得到需要插入的四条记录的id字段的值分别为1,2,3,4
- sql路由:sql路由包括库路由和表路由。库路由用于确定这条记录应该插入哪个库,表路由用于确定这条记录应该插入哪个表。
- sql改写:上述批量插入的语法将会在 每个库中都插入四条记录,明显是不合适的,因此需要对sql进行改写,拆分成每个库对应的sql,即每个库只插入一条记录。
insert into user_1(id,name) values (1,”tianshouzhi”)
insert into user_2(id,name) values (2,”huhuamin”)
insert into user_3(id,name) values (3,”wanghanao”)
insert into user_0(id,name) values (4,”luyang”)
- sql执行:一条sql经过改写后变成了多条sql,为了提升效率应该并发的到不同的库上并发执行,而不是按照顺序逐一执行
- 结果集合并:每个sql执行之后,都会有一个执行结果,我们需要对分库分表的结果集进行合并,从而得到一个完整的结果。
- 分布式id
在分库分表后,我们不能再使用mysql的自增主键。因为在插入记录的时候,不同的库生成的记录的自增id可能会出现冲突。因此需要有一个全局的id生成器。关于分布式id的生成,可以使用组件
- 分布式事物
分布式事物是指同时操作多个数据库。例如上面的批量插入记录到四个不同的库,如何保证要么同时成功,要么同时失败。
zebra目前并不支持分布式事务功能,柔性事务是目前比较主流的方案,柔性事务包括:最大努力通知型、可靠消息最终一致性方案以及TCC两阶段提交。mysql支持XA事务,但是效率较低。但是无论XA事务还是柔性事务,实现起来都是非常复杂的。
- 动态扩容
动态扩容指的是增加分库分表的数量。它要保证经过动态扩容之后,数据可以被正确访问到。
例如原来的user表拆分到2个库的四张表上。现在我们希望将分库的数量变为4个,分表的数量变为8个。这种情况下一般要伴随着数据迁移。例如在4张表的情况下,id为7的记录,7%4=3,因此这条记录位于user_3这张表上。但是现在分表的数量变为了8个,而7%8=7,而user_7这张表上根本就没有id=7的这条记录,因此如果不进行数据迁移的话,就会出现记录找不到的情况。
3. GroupDataSource
负责读写分离的连接池,它主要负责判断SQL的读写操作,然后把相应的SQL发送给SingleDataSource。它负责连接一个数据库集群,因此它会包含若干个SingleDataSource。
3.1 读写分离
面对大数据的sql请求, 在单台mysql实例的情况下,所有的读写操作都集中在这一个实例上。当读压力太大,单台mysql实例扛不住时,此时DBA一般会将数据库配置成集群,一个master(主库),多个slave(从库)。
主从数据同步:master将数据通过binlog的方式同步给slave,可以将slave节点的数据理解为master节点数据的全量备份。
从应用的角度来说,如果是写操作(insert、update、delete等),就走主库,主库会将数据同步给从库;之后有读操作(select、show、explain等),就走从库,从多个slave中选择一个,查询数据。
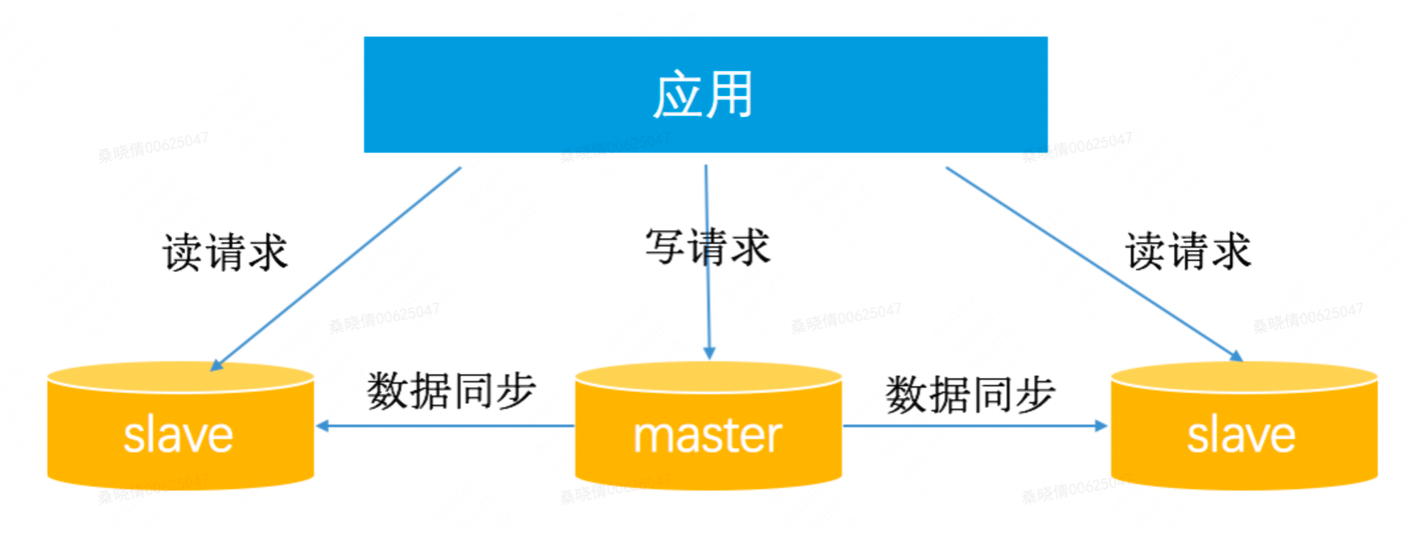
读写分离优点:
- 避免单点故障。
- 负载均衡,读能力水平扩展。
3.2 配置信息
-
jdbcRef:读写分离的jdbc。
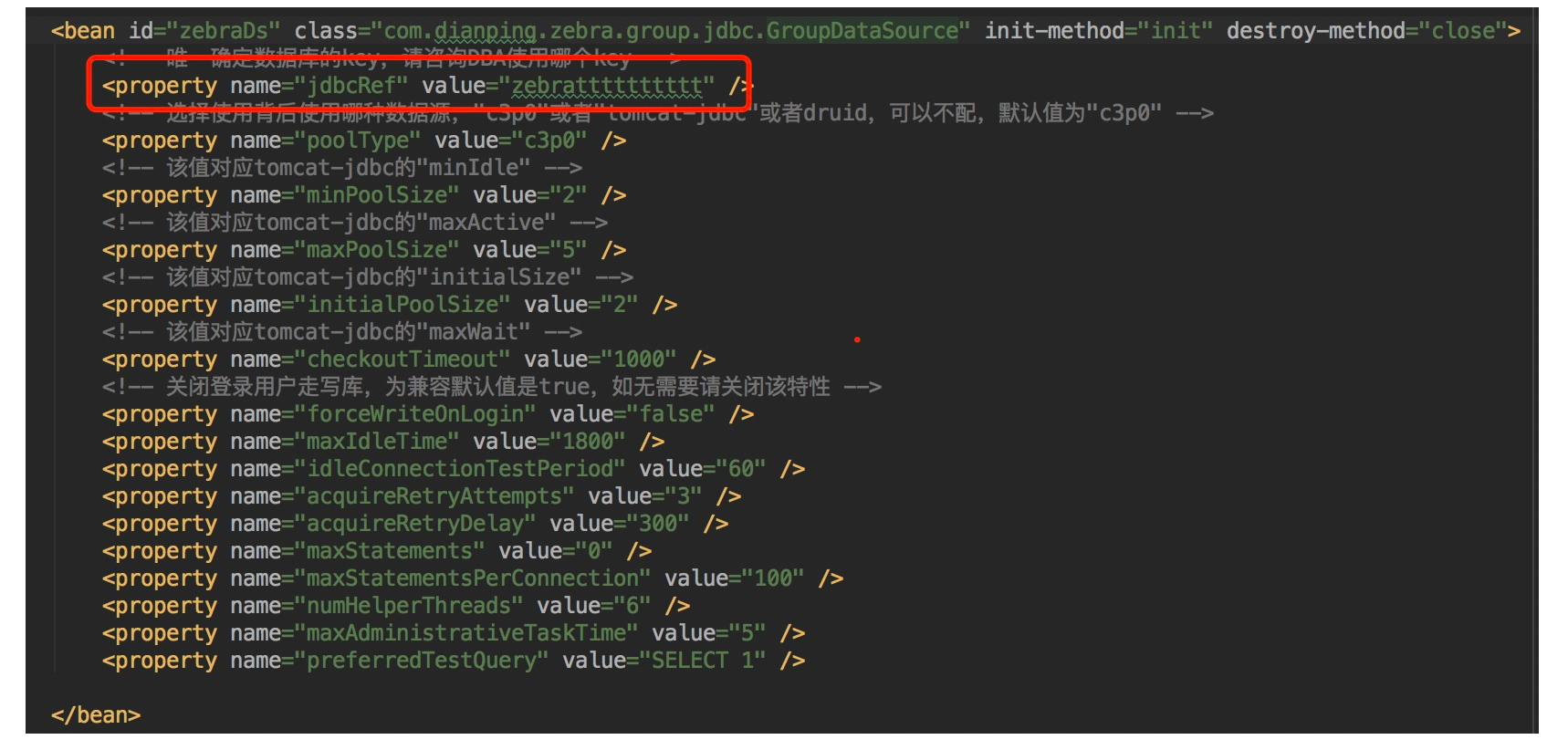
如果要使用读写分离功能,需要在我们管理平台RDS上申请一组读写数据库,比如DB-1-WRITE,DB-1-REDAD,DB-2-READ,这里DB-1负责所有写请求,DB-1和DB-2共同负责读请求(流量可以配置)。以上2个数据库会关联一个jdbcRef保存在注册中心上面,所以上述xml里面直接配置了jdbcRef,启动时候从注册中心获取对应的主从结构。
<bean id="dataSource" class="com.dianping.zebra.group.jdbc.GroupDataSource" init-method="init" destroy-method="close">
<!-- 必配。指定唯一确定数据库的key-->
<property name="jdbcRef" value="jdbcref" />
<!-- 选配。指定底层使用的连接池类型,支持"c3p0","tomcat-jdbc","druid","hikaricp","dbcp2"和"dbcp",推荐使用"druid"或者"dbcp2",版本2.10.3之后默认值为"druid",之前版本默认值为"c3p0" -->
<property name="poolType" value="druid" />
<!-- 连接池配置 -->
<!-- 选配。指定连接池的最小连接数,默认值是5。 -->
<property name="minPoolSize" value="5" />
<!-- 选配。指定连接池的最大连接数,默认值是20。 -->
<property name="maxPoolSize" value="20" />
<!-- 选配。指定连接池的初始化连接数,默认值是5。 -->
<property name="initialPoolSize" value="5" />
<!-- 选配。指定连接池的获取连接的超时时间,默认值是1000。 -->
<property name="checkoutTimeout" value="1000" />
</bean>
通用配置:
| 属性 | 默认值 | 含义 | 最佳实践 |
|---|---|---|---|
| jdbcref | 空 | 用户获取数据库连接信息的key。连接信息包括:ip、port、username、password、以及一些连接池参数默认。 | 最简单的情况下,业务方可以只配置一个jdbcref属性,就可以使用GroupDataSource,这种情况下使用的都是默认的配置,可能并没有满足业务需求。强烈建议,显式的定义以下核心参数:poolType、lazyInit、initialPoolSize、minPoolSize、maxPoolSize、checkoutTime。 |
| poolType | version < 2.10.2,默认为c3p0version>=2.10.2,默认为druid | 底层使用的连接池类型。支持类型列表:"c3p0" , "tomcat-jdbc" , "druid" , "dbcp" , "dbcp2" ,**"hikaricp" | 建议使用dbcp2或者druidtomcat-jdbc由于存在将死链接放回到连接池中的问题,不建议使用,参考:[SocketTimeout与No operations allowed after connection closed]c3p0、dbcp由于性能相对较低,目前也不建议使用。参考:[多种数据源连接池性能压测结果]hikaricp性能较高,但是缺少大规模应用实践,业务同学自行考虑是否使用。 |
| lazyInit | true | 启动时立即初始化连接池。立即初始化连接池有助于提高前几个sql的执行速度,减少连接获取时间。为true时,表示第一次接收到查询请求时,才会初始化链接。为false,启动时立即初始化连接数为initialPoolSize。 | 如果应用启动时会出现连接获取超时的异常 建议设置为false。否则设置为true。tips:对于应用和DB多地域部署场景,都是同地域就近访问(正常不会出现北京机器访问上海DB),因此如果设置lazyInit后初始化跨地域的连接池会导致初始化大量无用连接,所以LazyInit=false不会初始化跨地域的连接池 |
| initialPoolSize | 5 | 初始连接数 | 针对这几个参数,在设置时,应该考虑一下GroupDataSource底层维护了多少个SingleDataSource。每个参数都会应用到底层所有SingleDataSource。例如initialPoolSize设置为5,但是底层有3个SingleDataSource,实际上会初始化15个连接。过小,连接不够用,获取链接时间较长,甚至超时。过大浪费数据库连接。 |
| minPoolSize | 5 | 最小连接数 | |
| maxPoolSize | 30 | 最大连接数 | |
| checkoutTimeout | 1000 | 获取链接超时时间2.10.1之前的版本,只能设置小于等于1000的值2.10.2支持设置大于1000的值 | 如果遇到获取链接超时异常,可将此值调大,但是这可能会导致接口响应变慢,此时应该增大maxPoolSize。 |
| routerStrategy | WeightRouter | 支持IdcAwareRouter(同机房优先),WeightRouter(同中心优先),RegionAwareRouter(同区域优先)。 | 建议不要本地进行覆盖,在管理平台上进行配置,可以动态进行切换。本地覆盖后,则不支持进行动态切换。 |
| routerType | master-slave | 支持master-slave(默认)slave-only(只走从库)master-only只走主库)。 | 如果应用只需要走从库(例如统计需求)可以配置为slave-only,只需要走主库,可以配置为master-only。 |
| connectionInitSql | 空 | 连接池创建物理连接时会首先执行改sql,一般用于设置一些数据库的session。 | |
| extraJdbcUrlParams | 空 | 用来在本地设置一些自定义的jdbcurl参数 | jdbcdriver 5.1.36及以上版本需要在jdbcurl设置 "useSSL=false" 参数, 可以通过此方式设置如果需要额外的参数比如allowMultiQueries=true、zeroDateTimeBehavior=convertToNull或者其他参数,可以通过以下方式设置或者覆盖。如果有大事务或者大查询会超过60s的,请也覆盖掉socketTimeout=60000这个参数。connectTimeout=xxx,这个参数可以设置创建连接时的超时时间,可以在数据库hang住是快速失败。更多参数,见官方文档: https://dev.mysql.com/doc/connector-j/5.1/en/connector-j-reference-configuration-properties.html |
| preferredTestQuery | 当poolType不是C3P0时,默认值为SELECT 1;当poolType是C3P0时,默认为null | 用于检测连接有效性的测试所执行的测试语句 | 由于不同的poolType默认值是不同的,因此建议显式的进行配置为SELECT 1。 |
| isJdbcrefGroup(2.10.2) | true | 主要用于SET化配置,指定为false后,在SET环境下,也可以直接访问一个jdbcref。 | 对于非SET化应用,不需要配置此项。对于SET化的应用,如果需要直接访问某个jdbcref,可以配置为false |
| useDistType (3.1.0) | false | 用与开启分布式sql引擎的开关 | 使用分布式sql引擎可开启(不推荐使用) |
非c3p0参数
| 属性 | 默认值 | 含义 | 最佳实践 |
|---|---|---|---|
| timeBetweenEvictionRunsMillis | 30000 | 每30秒运行一次空闲连接回收器 | 可以适当调大,例如300000,即5min |
| minEvictableIdleTimeMillis | 1800000 | 池中的连接空闲30分钟后被回收 | 根据业务情况选配,为了避免业务流量突然变大,可以适当的调大。 |
| validationQueryTimeout | 0(hikari连接池默认5000) | preferredTestQuery执行超时时间,默认0秒,表示不超时 | 使用默认的0即可。因为zebra默认添加了socketTimeout=60000,因此校验SQL执行不会超过60s |
| removeAbandonedTimeout | 300 | 连接泄漏回收参数,泄露的连接可以被删除的超时值 | 如果有大事务执行超过300s,可以适当调大 |
| numTestsPerEvictionRun | 6 | 在每次空闲连接回收器线程(如果有)运行时检查的连接数量 默认6 | 使用默认配置即可 |
C3P0连接池参数
| 属性 | 默认值 | 含义 | 最佳实践 |
|---|---|---|---|
| maxIdleTime | 0 | 连接池内连接最大空闲时间 单位s。若为0则永不丢弃。 | 建议显式的设置一个大于0的值,如3600 |
| idleConnectionTestPeriod | 0 | 每隔指定时间,检测连接池内的空闲链接,单位:秒。只有值大于0的情况下,才会进行检测。 | 通常需要显式的指定一个大于0的值,建议不小于300s,即5min。过小检测太频繁,可能到连接池中获取链接时,链接正在被检测概率较大,导致获取连接时间变长。过大的话,可能会出现有失败的链接,但是没有被及时的检测到。 |
| acquireRetryAttempts | 30 | 定义在从数据库获取新连接失败后重复尝试的次数 | 建议不要指定这2个参数,直接通过通用参数中checkoutTimeout属性指定即可。原因参考:[关于c3p0 CannotAcquireResourceException] |
| acquireRetryDelay | 300 | 重新获取连接中间隔时间,单位毫秒。与acquireRetryAttempts联合使用,也就是默认获取连接失败最多重试30次,每次等待300ms。 | |
| maxStatements | 0 | JDBC的标准参数,用以控制数据源内加载的PreparedStatements数量。但由于预缓存的statements 属于单个connection而不是整个连接池。所以设置这个参数需要考虑到多方面的因素。 如果maxStatements与maxStatementsPerConnection均为0,则缓存被关闭。 | 关于这两个参数,建议使用默认值0即可,不需要配置。原因在于:statement缓存对于支持游标的数据库,如oralce,可能有较大的性能提升。对于使用mysql的情况,可以关闭。 曾遇到业务方使用了statement缓存的情况下,创建一个statement花费了几百毫秒,这是因为一旦开启了缓存,每次获取statment之前,必须获取一个全局的锁,在高并发的情况下,对于锁的竞争会非常激烈。因此不建议使用。 |
| maxStatementsPerConnection | 0 | 定义了连接池内单个连接所拥有的最大缓存statements数 | |
| numHelperThreads | 3 | c3p0是异步操作的,缓慢的JDBC操作通过帮助进程完成。扩展这些操作可以有效的提升性能 通过多线程实现多个操作同时被执行。 | 使用默认的配置即可。 |
| maxAdministrativeTaskTime | 0 | 可能对那些面临无限挂起的任务或者出现明显的死锁信息的用户有帮助 | 基本没用,使用默认的0即可。 |
3.3 读写分离挑战
-
主从数据同步延迟问题。因为数据是从master节点通过网络同步给多个slave节点,因此必然存在延迟。因此有可能出现我们在master节点中已经插入了数据,但是从slave节点却读取不到的问题。
对于一些强一致性的业务场景,要求插入后必须能读取到,因此对于这种情况,我们需要提供一种方式,让读请求也可以走主库,而主库上的数据必然是最新的。
-
事务问题。如果一个事务中同时包含了读请求(如select)和写请求(如insert),如果读请求走从库,写请求走主库,由于跨了多个库,那么jdbc本地事务已经无法控制,属于分布式事务的范畴。而分布式事务非常复杂且效率较低。因此对于读写分离,目前主流的做法是,事务中的所有sql统一都走主库,由于只涉及到一个库,jdbc本地事务就可以搞定。
-
高可用问题。主要包括:
- 新增slave节点:如果新增slave节点,应用应该感知到,可以将读请求转发到新的slave节点上。
- slave宕机或下线:如果其中某个slave节点挂了/或者下线了,应该对其进行隔离,那么之后的读请求,应用将其转发到正常工作的slave节点上。
- master宕机:需要进行主从切换,将其中某个slave提升为master,应用之后将写操作转到新的master节点上。
4. SingleDataSource
SingleDataSource负责连接数据库,配置数据库的基本信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号