杂烩 headless 无界面浏览器
普通的静态网页不需要用浏览器渲染,直接伪装好请求头开爬就是了。但有时我们还会遇到一些需要“动态加载”才能显示相应内容的网页——也就是说,我们需要爬的网络元素并不会直接出现在HTML节点里,而是必须通过AJAX等技术与网站后台服务器交换数据之后才能显示出来。
 AJAX介绍(来自我们小组做的PPT)
AJAX介绍(来自我们小组做的PPT)
例如新浪网“社会新闻心情排行榜”里面的新闻标题链接(对应于图中的<a href=…>里面的“data[i].url”),就是一种需要通过JavaScript访问后台数据之后才能加载出来的动态元素。
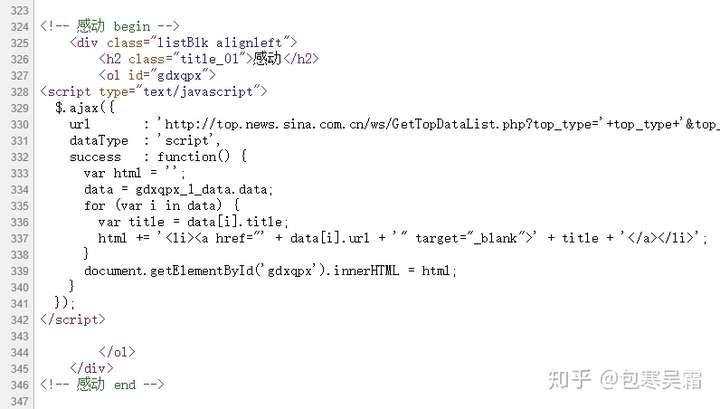 view-source:http://news.sina.com.cn/society/moodrank/20150101.shtml
view-source:http://news.sina.com.cn/society/moodrank/20150101.shtml
面对这样的动态网页,我们就需要借助PhantomJS等无头浏览器(图中的红圈),从而模拟人类“打开浏览器、进入网址、等待加载动态网络元素”等一系列动作,然后就可以根据此时的HTML节点来爬数据啦。
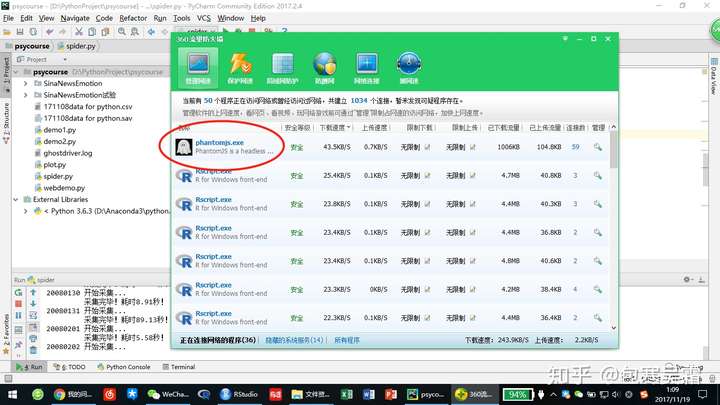 Python调用“无头浏览器”PhantomJS
Python调用“无头浏览器”PhantomJS
PhantomJS是真正的啥窗口都没有的无头浏览器,所以它的名字也很恰当——幽灵(Phantom)。
当然,Chrome、火狐等也都有对应的无头浏览器,在运行时可以选择让它们弹出窗口,这样有利于我们监控爬虫的运行状况。
SlimerJS:基于Gecko的无头浏览器,SlimerJS和PhantomJS基本兼容,就是一个内核换成了Gecko的PhantomJS
HtmlUnit:纯java开发的无头浏览器,完全java开发,javascript引擎使用的是Rhnio,由于不是基于Webkit、Gecko等主流内核开发,兼容性不好
CasperJS是一个开源的导航脚本处理和测试工具,基于PhantomJS(前端自动化测试工具)编写。CasperJS简化了完整的导航场景的过程定义,提供了用于完成常见任务的实用的高级函数、方法和语法
Headless简介
下面是wiki上面的说法
https://en.wikipedia.org/wiki/Headless_browser
A headless browser is a web browser without a graphical user interface.
无界面浏览器是没有图形用户界面的Web浏览器。
Headless browsers provide automated control of a web page in an environment similar to popular web browsers, but they are executed via a command-line interface or using network communication. They are particularly useful for testing web pages as they are able to render and understand HTML the same way a browser would, including styling elements such as page layout, colour, font selection and execution of JavaScript and Ajax which are usually not available when using other testing methods.
无界面浏览器在类似于流行网络浏览器的环境中提供了对网页的自动控制,但是它们是通过命令行界面或使用网络通信来执行的。 它们对于测试网页特别有用,因为它们能够以与浏览器相同的方式呈现和理解HTML,包括样式元素,例如页面布局,颜色,字体选择以及JavaScript和Ajax的执行,而使用其他元素时通常不可用 测试方法。
那么一般都用它来做什么呢?
想象一下每次在发版前,测试人员都需要测试系统的功能,重复且乏味。于是你决定让程序自动测试界面上的功能。你不需要浏览器有GUI界面,想通过编程的方法来驱动浏览器进行各种操作,并且希望能在服务器端运行,这样每次发版前就可以自动测试相关功能,提高测试效率。
以上只是一个应用场景,Headless浏览器可以理解为没有GUI界面的浏览器程序。由于没有界面,所以在速度上比普通浏览器稍快,它可以在自动化测试、性能检查、获取元数据(例如爬虫)和网页截图等方面发挥用途。
对比
在Chrome浏览器还没有原生支持Headless之前,早期浏览器可以通过Xvfb服务处理图形显示从而实现Headless模式,近期火狐也在积极研发原生支持Headless模式,预计在Firefox 56版本中实现。还有一种方案是通过封装浏览器内核来实现Headless。比较知名的比如PhantomJS(目前仅维护)封装了QtWebKit内核,SlimerJS封装了Gecko内核,TrifleJS封装了IE内核。
而使用这些框架的时候,可能会出现很多奇怪的问题。这些程序是运行在封闭环境中的,所以会导致和外部通信很繁琐,并且由于采用的内核比较老,从而很多新特性,新语法不支持,并非真实的用户环境。所以提倡用Headless模式替代这些框架,从而获得更好的效果。
使用
Chrome Beta 59开始在Liunx、Mac、Window(Chrome 60)上支持Headless模式。下载并安装好相应版本的浏览器后,可以有多种方式来启动Chrome Headless模式。
通过命令行参数—headless来启动:
$ /Applications/Google\ Chrome\ Canary.app/Contents/MacOS/Google\ Chrome\ Canary --headless —remote-debugging-port=9222
另外也可以采用封装好的Chrome启动库来达到多个平台兼容启动,如Lighthouse用Node.js实现的chrome-launcher库,自动寻找系统中Chrome程序的安装位置,然后通过child_process模块来启动Chrome浏览器。
同时Headless也支持被嵌入到C++程序中,从而可以更加底层地控制浏览器。
当启动完Headless浏览器后,Mac上会出现Chrome的图标,但是并不能打开看到界面。然后我们可以通过浏览器访问相应的远程调试端口来参看相应的调试界面。除了客户端能通过远程接口访问外,还可以通过编程实现DevTools协议来和浏览器进行相关的通信,从而实现对页面的控制。
架构
图1为Headless Chrome架构图。 Headless Chrome主要实现了两个功能,一个是实现了Headless API的Headless shell应用程序,通过命令行参数启动Headless模式,即启动Headless shell。一个是Headless library,它实现了嵌入式应用程序能控制浏览器并与网页交互的功能。

图1 Headless Chrome架构图
如果你是通过C++程序嵌入的话,就可以用Headless library来和浏览器进行通信。浏览器和外界通信有一套协议称为DevTools。Client API是基于Chrome DevTools协议实现的一套可以和浏览器交互的库。除了上面说的,还有许多库实现DevTools,如官方推荐采用Node.js实现的chromeremote-interface库,或者采用Python实现的chromote库等。
DevTools协议
Chrome DevTools是一套可以用来和Chrome浏览器通信的协议,平常我们开发调试Chrome程序用的开发者工具即是基于该协议实现的一个网页程序。Chrome开发者工具通过Socket和Chrome进行通信,浏览器中的一个Tab页面即对应一个Socket通道。然后互相进行数据交换,从而实现对网页的检查、调试和监控等功能。
我们可以用命令行参数在客户端来远程调试页面。在命令行中加入参数“—remote-debuggingport=9222”启动Chrome后,在浏览器进入“localhost:9222”即可看到调试界面。其中我们可以通过网络面板中的WebSocket连接来查看调试程序和Chrome进行的数据收发。我们可以把该协议当成浏览器的API,想实现什么功能,需要发送固定格式的信息过去,浏览器接收后会返回相应的数据。
Headless应用
在自动化测试和网络爬虫等领域会经常用到该项新特性。
自动化测试
自动化测试有许多的框架,比较好用的比如Nightmare,这是一款基于Electron的自动化测试库,语法漂亮好用。最近这个库也计划从Electron迁移到Headless Chrome。我们也可以结合Karma来实现UI的自动化测试,这样可以保证代码在真实环境中运行。
网络爬虫
网络爬虫应用在以前的方案中,会有较多问题,比如数据抓取不全。现在很多的网站都做成了单页应用,采用AJAX交互,传统爬虫能拿到的数据有限,如果不执行前端代码,就拿不到有用的信息。此时,我们可以用Headless Chrome来执行相关的代码,将页面执行完成后,在对相应的页面进行分析。这比其他方案能有更好的稳定性,不过由于目前这方面的库还不是很成熟,导致需要自己去写一些底层的实现,在开发效率上会比较慢。
自动截图
自动截图也可以被应用到Headless中。在前端代码报错后,如果希望能把当前错误页面的截图并发给监控程序,目前的纯前端做法可以采用html2canvas。但用过这个库后,你会发现有的截图效果很不理想,和原来的界面差距较大。那可以换个角度,采用后端截图的方法。由于页面展示本质是HTML和CSS。我们可以在服务器端部署Chrome Headless服务器,里面加载对应网站的资源,等前端报错后,只需将前端整个页面的Dom数据发送给服务器,服务器把相应内容的Dom替换后,由于CSS一般是提取出来的,所以客户端和服务端样式表一致,Dom结构一致,数据一致,即可以将服务器端截图并发送给监控程序。
实战预渲染
Prerender和Server-side render(SSR) 两种技术都是解决首屏渲染问题,以此来提高用户体验的方案。Prerender方案不需要后端是Node.js。其实本质上,Prerender只提供一个假的静态首页预先给客户看到样式,不具备应用的功能。
在目前的SPA网站中,首屏大多会有一个id为app的元素。等框架资源加载完成后,框架会动态替换app元素为真正的应用样子。而在资源尤其是打包后的JavaScript文件没加载完成之前,页面基本处于白屏的状态。而Prerender正是希望用一个固定的样式来代替这个白屏的状态。
目前实现预渲染的简单方案可以采用几张图片,来给用户直观的应用布局样式,从而增加用户等待的时长。复杂一点可以采用webpack将预先写好的样式组件打包后内联写入首屏页面,包括写入JavaScript脚本,写入HTML和CSS等。让用户可以快速了解应用的名字,整体颜色布局信息。具体做成什么样,需要由应用本身来决定。但不希望在首页中有过多的内嵌代码,否则拖慢初始加载速度导致后续资源加载变慢的话,预渲染效果也会不理想。
我们可以用Headless来实现预渲染,有两种预渲染方案。
一种是在服务器端,当请求过来后,把请求动态挂在Headless Chrome里,然后把Chrome里面的Dom拿到后返回给客户端,这个也可以做成SPA应用程序通用的SEO优化方案。
另一种是在代码发布阶段将静态样式内嵌写入网站首页。在打包阶段开启静态服务器,然后用Headless Chrome来访问对应的网站,并得到网站的Dom。和骨架图不同的是,这时候的Dom应该是网站真实渲染后的Dom。
在实际应用中,会碰到渲染出页面结构含有开发时脏数据问题。如果把开发时的数据去掉,会影响整体页面的布局,因为有的布局是靠内容撑起来的。所以我们采用了字符替换的方法,把文字数据替换为 ,这样既保留了占位,又去掉了脏数据。对于图片的处理需要把图片的href更换为默认URL图片,有的icon如果是内联数据,需要去掉。总之一个原则,让页面初始加载骨架看起来和真实结构一致。可以采用在编码的时候,在元素的属性上设置标志符,来表明文字或者图片是否需要被替换。处理完后,需要有效果,其前提是把CSS文件在打包的时候单独提取出来,这样在初始加载时才会有效果。然后通过webpack打包把处理后的Dom数据内嵌到首页中。当用户首次访问的时候,首页就已内嵌有了对应的Dom结构,让用户对网站布局有个大概的感知,减少用户等待时间。
示例代码请见下。
const chromeLauncher = require(‘chrome-launcher');
const CDP = require('chrome-remote-interface');
function delay(time) {
time = time || 0;
return new Promise((resolve, reject) => {
setTimeout(function() {
resolve();
}, time);
})
}
async function preRender() {
// open chrome
const chrome = await chromeLauncher.launch({
port: 9222,
});
const { Page, DOM } = await CDP();
await Promise.all([
Page.enable(),
DOM.enable(),
]);
await Page.navigate({ url: 'https://h5.ele.me/market/#/home' });
await Page.loadEventFired();
// wait for loading data
await delay(3000);
const rootNode = await DOM.getDocument();
const appNode = await DOM.querySelector({ nodeId: rootNode.root.nodeId,selector: '#app' });
// replace product data to clear data
const needReplaceFlag = '#app [shell-replace]';
const defaultImage = 'http://defaultImage.com';
const replaceNode = await DOM.querySelectorAll({ nodeId:
rootNode.root.nodeId, selector: needReplaceFlag });
replaceNode.nodeIds.length && await new Promise((resolve, reject) => {
const tasks = [];
replaceNode.nodeIds.forEach(nodeId => {
try {
const task = DOM.getOuterHTML({ nodeId }).then(html => {
const nodeName = html.outerHTML.split('>')[0].slice(1).split(' ')[0];
if (nodeName === 'img') {
return DOM