SQL Server事务
简介
事务是单个的工作单元,这就意味着单元内有多个操作,事务是多个操作的整合体。如果某个事务执行成功,则涵盖在这个事务里的所有数据操作均会一并执行提交,成为数据库中的永久组成部分。
如果事务因某项操作执行错误,那么事务内所有的操作都将无效,事务实行回滚机制,数据操作都会还原到初始为更改的状态。
为什么需要事务
在银行业务中,有一条记账原则,即有借有贷,借贷相等。为了保证这种原则,每发生一笔银行业务,就必须确保账目上借方和贷方至少个记一笔账,并且这两笔账要么同时成功,要么同时失败。
如果账目上的记录只出现了借方,或者只出现了贷方。那么这就违反了记账的原则,出现记账错误的情况。此业务场景就是事务典型的体现,通过事务处理的处理机制,才可以解决此类业务场景。
示例分析
业务场景:
银行转账往往涉及两个或两个以上的账户,包括转出对象和转入对象两种。在转出的存款金额减少一定金额的同时,转入账户会增加相应金额的存款。接下来以转账的场景为例,用代码演示转账的过程。
数据准备:
--创建表
if exists(select * from sysobjects where name='bank' )
drop table bank
go
create table bank
(
customerName nvarchar(4),
currentMoney money
)
go
--添加约束:账户余额(currentMoney)不能少于1元,否则视为销户
alter table bank
add constraint ck_currentMoney check (currentMoney>=1)
go
--插入测试数据,即转账的两个对象:张三账户余额为1000元,李四账户余额为1元
insert into bank values ('张三',1000),('李四',1);
go
--查看结果
select * from bank go
使用SQL语句模拟转账功能:
逻辑:从张三的账户直接转账1000元到李四的账户,张三账户减少1000元。李四账户增加1000元。
代码如下:
--根据业务逻辑编写SQL语句执行数据操作
--转出
update bank set currentMoney=currentMoney-1000
where customerName='张三'
--转入
update bank set currentMoney=currentMoney+1000
where customerName='李四'
执行结果:
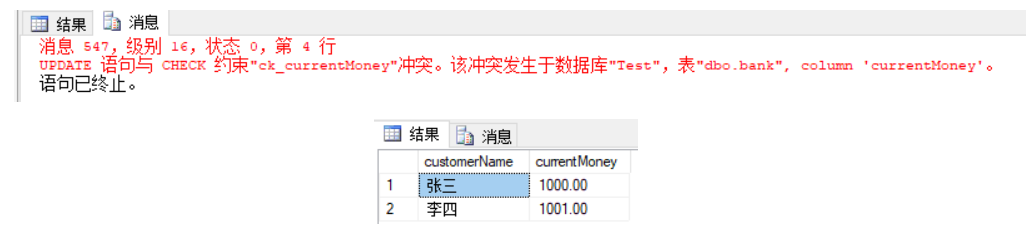
结果分析:
张三转给李四的1000元并没有从账户里扣除,李四的账户却多了1000元,转账后两个账户的余额总和变为1000+1001=2001,存入银行的钱凭空多出1000元。如果此操作发生在生活中,想一想是多么可怕的事情。此操作的原因是因为之前在创建表的时候定义的约束,导致第一个SQL命令无法执行,下一个SQL没有因为中断停止执行。
如果在程序中,可能会用代码逻辑去控制,即等第一个命令执行成功在执行下一个命令,这样虽然可以监控第一个命令的结果做出对应的处理。但是如果第一个命令执行成功,第二个命令执行出错该怎么办,这样还是无法确保一个业务的整体性。
我们可以使用事务机制来解决此问题,转账过程就是一个事务,它需要两条或者更多条SQL语句来完成一系列的操作,不管有多少条命令,它们始终围绕着一个主题就是转账。如果其中某个步骤出错,则整个转账业务也不能成立,应出错要把事务中操作的数据恢复为原来的数据。在开发中如果不使用事务处理机制,我们是很难保证事务中单个操作不出错的。一旦事务中某个操作出错就导致了整体的逻辑性。
事务的概念
事务是一种机制,一个操作序列,它包含了多个操作命令,并且把所有的命令作为一个整体并都围绕着一种业务主题一起向系统提交或撤销操作请求,即这一组命令要么都执行,要么都不执行,通俗的理解就是共同进退。因此事务是一个不可分割的工作逻辑单元,在数据库系统上执行并发操作时,事务是作为最小的控制单元来使用的,它特别适用于多用户同时操作的数据库系统。例如,航空公司的订票系统、银行、保险公司等。
事务是作为单个逻辑工作单元执行的一系列操作。一个逻辑工作单元必须有四个属性,即原子性、一致性、隔离性、持久性,这些特性简称为ACID。
1.原子性(一个事务只围绕一个业务主题,事务中每个操作只针对一个表进行)
事务是一个完整的操作。事务的各个元素是不可分的(原子的)。事务中的所有元素必须作为一个整体提交或回滚。如果事务中任何元素执行失败,则整个事务就视为失败。
以银行转账事务为例,如果该事务提交了,则转出和转入两个账户的数据都将会更新数据。如果由于某种原因,事务中某一项操作失败,则事务不会提交,两个账户的数据都不会更新,并且会撤销对任何账户余额的修改,这主要说明的是事务中的操作不能部分执行。
2.一致性(数据存储合乎业务逻辑)
当事务完成时,数据必须处于一致状态。也就是是说,在事务开始之前,数据库中存储的数据处于一致状态。在正在进行的事务中,数据可能处于不一致的状态,如数据可能有部分修改。然而,当事务成功完成时,数据必须再次回到已知的一致状态。通过事务对数据所做的修改不能损坏数据的逻辑性,或者说事务不能使数据处于混乱不合法性。如,一个订单系统下了一笔订单后,数据库中存在下单后的订单数据,订单中的商品库存却没有因采购订单的商品的购买而减少。
以银行转账事务为例。在事务开始之前,所有账户的余额处于一致状态。在事务进行的过程中,一个账户余额减少,而另一个账户余额尚未修改。因此,所有账户余额处于不一致状态(数据不合乎业务逻辑)。
3.隔离性(事务本身就可以很好处理并发操作)
对数据进行修改的所有并发事务是彼此隔离的,这表明事务必须是独立的,它不应以任何方式依赖于或影响其他事务。修改数据的事务可以在另一个使用相同数据的事务开始之前访问这些数据,或者在另一个使用相同数据的事务的结束之后访问这些数据。另外,当事务修改数据时,如果任何其他进程正在同时使用相同的数据,则会等到事务提交之后,对数据的修改才能生效。可以通俗的理解,在对数据库数据修改的通道上,只允许单个事务通过执行,待当前通道事务执行成功才会执行下一个事务。如转账事务,张三和李四之间的转账与王五和赵二之间的转账,永远是相互独立的。
4.持久性(事务可以预防系统的突发状况)
事务的持久性指不管系统是否发生了故障,事务处理的结果都是永久的。
一个事务完成之后,它对于数据库的改变是永久性的,即使系统出现故障也是如此。就是说,一旦事务被提交,事务的效果会被永久地保留在数据库中。(这有点像纹身)
如果系统SQL Server数据库或者某些组件发生了故障,则数据库会在系统重新启动的时候自动恢复。SQL Server使用事务日志保存受到故障影响的事务并重新运行未提交的事务。
SQL Server事务中的关键代码
1.开始事务
BEGIN TRANSACTION
这个语句显示地标记一个事务的起始点。
2.提交事务
COMMIT TRANSACTION
这个语句标志一个事务成功结束。自事务开始至提交语句之间(BEGIN TRANSACTION ~ COMMIT TRANSACTION)执行的所有数据操作将将永久地保存在数据库数据文件中,并释放连接时占用的资源。
3.回滚(撤销)事务
ROLLBACK TRANSACTION
清除自事务起始点至该语句之间,所做的所有数据操作,将数据状态回滚到事务开始之前,并释放由事务控制的资源。
SQL Server执行事务的逻辑:
BENGIN TRANSACTION语句后面的SQL语句对数据库的操作都将记录在事务日志中,只到遇到ROLLBACK TRANSACTION语句或COMMIT TRANSACTION语句。如果事务中某一项操作失败且执行了ROLLBACK TRANSACTION语句,
那么在BEGIN TRANSACTION语句之后所有更新的数据都能回滚到事务之前的状态。如果事务中的所有操作全部正确完成,并且使用了COMMIT TRANSACTION语句,那么所有数据操作都将提交到数据库。
事务分类
在SQL Server中事务有以下3种类型:
1.显示事务:
使用SQL Server事务中的关键代码明确指定事务的阶段(BEGIN TRANSACTION、COMMIT TRANSACTION、ROLLBACK TRANSACTION)。
2.隐式事务:
通过设置SET IMPLICIT_TRANSACTION ON语句,将隐式事务模式打开。当以隐式事务操作时,SQL Server将在提交或回滚事务后自动启动新事务。不需要描述每个事务的开始,只要提交或回滚每个事务即可。
3.自动提交事务:
这是SQL Server的默认模式,它将每条单独的T-SQL语句视为一个事务。如果成功执行,则自动提交。如果错误,则自动回滚。
在实际开发中最常用的就是显示事务,当前文章介绍的也是显示事务,它明确地指定事务的每个阶段。
SQL Server事务运用
接着<为什么需要事务>段落中的银行转账示例继续介绍怎么在代码中实现事务。
结合@@ERROR的运用:
在事务处理的过程中,如何通过代码判断T-SQL语句执行是否有误,从而顺利实现提交事务或回滚事务操作呢?可以在事务的每个操作之后,使用@@ERROR全局变量,以检查判断当前T-SQL语句执行是否有误,如果有错误则返回非零值。
实现代码:
set nocount on
go
print '查看转账事务前的账户余额'
select * from bank
go
--开始事务(指定事务从此开始,后续的SQL语句是一个整体)
begin transaction
--定义变量,用于累计事务执行过程中的错误
declare @errorSum int
set @errorSum=0 --初始化为0,即默认代表无错误
--事务逻辑-转账:张三的账户减少1000元,李四的账户增加1000元
update bank set currentMoney=currentMoney-1000 where customerName='张三'
set @errorSum=@@ERROR+@errorSum --累计是否有误
update bank set currentMoney=currentMoney+1000 where customerName='李四'
set @errorSum=@@ERROR+@errorSum --累计是否有误
print '查看转账事务过程中的余额'
select * from bank
--根据错误变量的值,判断语句在执行过程是否出错,以确定事务进行提交或回滚
if @errorSum<>0 --非零
begin
print '交易失败,回滚事务'
rollback transaction
end
else
begin
print '交易成功,提交事务,数据录入至数据库'
commit transaction
end
go
print '查看转账事务后的余额'
select * from bank
go
语句执行结果:

示例中事务在执行过程中因某条操作中断,张三是转账转出对象,转出1000元后张三账户为0,违反了约束而出错。事务此时保证了转账逻辑的合法性。下面将张三转账金额改为800,运行结果如下:

事务了执行提交,转账事务完整成功执行。
编写事务时要遵守的原则
事务尽可能简短:
事务启动至结束后再数据库管理系统中保留大量资源,以保证事务的原子性、一致性,隔离性和持久性。如果在多用户系统中,较大的事务将会占用系统的大量资源,是系统不堪重负,会影响软件的性能,甚至导致系统崩溃。
事务中访问的数据量尽量最少:
当并发执行事务处理时,事务操作的数据量越少,事务之间对操作数据的争夺就越少。
查询数据时尽量不要使用事务:
对数据进行浏览查询操作并不会更新数据库的数据,因此尽量不使用事务查询数据,避免占用过量的系统资源。
在事务处理过程中尽量不要出现等待用户输入的操作:
在处理事务的过程中,如果需要等待用户输入数据,那么事务会长时间地占用资源,有可能造成系统阻塞。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号