

面向对象的照妖镜——UML类图绘制指南
1.前言
感受
在刚接触软件开发工作的时候,每次接到新需求,在分析需求后的第一件事情,就是火急火燎的打开数据库(DBMS),开始进行数据表的创建工作。然而这种方式,总是会让我在编码过程中出现实体类设计疏漏的地方,导致我在写业务代码时,还回头去反复的修改数据表和实体类。为了规避这样的情况,我学习期间发现了UML中关于类图的知识点,它让我知道,作为编码者在分析需求后,做的第一件最基本的事情应该是进行面向对象分析,然后使用UML绘制类图的方式进行面向对象的设计。在类图绘制完之后,使用类图与组员沟通设计思想,分析设计的可行性,在项目组一致达成共识后才进入后面的动手环节。
以上这种,通过面向对象分析和设计来绘制类图的工作习惯,我一直延续至今。因为,它不仅能保证软件构建的稳定性,还能提升我们面向对象的思想和实践能力。在实际中,极少数的情况下,公司会聘用专门的设计人员为你提供设计方案,更多的情况是,程序员要担任设计和编码的综合性工作,所以我认为掌握UML类图,是一名程序员的技能标配。
三个层次
在标准的软件工程建模当中,类图实际上根据三个层次划分为了三种类型的类图,根据使用顺序分别为:概念层类图、说明层类图和实现层类图。概念层用于业务建模阶段,着重于对问题领域的概念化理解;说明层用于概念模型阶段,主要考察类的交互涉及哪些接口;实现层用于设计阶段,主要考虑类在代码技术层面的实现细节。本文主要主要以实现层的类图为主,因为实现层的类图是最常用的,并且它是直接影响到我们实际的编码工作的,下面我会针对它涉及的绘制方式、类之间的关系展开详细讲解。
2.类的识别
UML类图的基本语法是很简单的,可能懂点编程的人在不系统学习的情况下,借助绘图工具都可以绘制出来。但在实际的业务需求中,充斥着各种晦涩的业务概念、事物,要从其中准确无误的提炼出有利于业务系统的类,并非一件简单的事情。
对于类的识别,并没有很具体的步骤、公式进行照搬硬套,往往只能通过自身的经验和面向对象的造诣去识别类。并且识别类往往也不是一蹴而就的,还要结合类与类之间的关系、业务的使用场景,反复推敲,才能逐步得到合适的类型。对此我只能提供一些概念性的经验心得,读者可以选择性的参考,并不作为一个标准。
类的识别很大程度上需要依靠“边界”,这是一个复杂的概念,你可以简单理解它相当于一个范围,设定边界可以让我们知道能做什么事情,和不能做什么事情。并且边界的设定会决定我们看待事物的视角和抽象事物的层次。对于类的识别而言,其边界可参考当前的系统的目标、业务场景等,有了清晰的边界,可以缩小类的识别范围,不在是天马行空,毫无根据。
如果不通过边界确定一个角度,那么对于同一事物,通过不同的角度会提炼出不同的类型。就拿我们自身举例,从职业的角度来看我们则是程序员,从国家的角度来看我们则是中国人,从动物的角度来看我们则是人类。所以我们必须要通过边界来确定一个角度,从而清晰的分析获取有利于业务系统的类型。
例如,你需要在一个网课教育系统中,分析上课的场景中会有哪些类型。如果你不考虑边界(网课教育系统中的上课场景),那么你可能天马行空的分析出:男人、女人这些类型。这样分析出的类型和属性显然对系统毫无意义,也无法为业务提供价值。如果你考虑到了边界(网课教育系统中的上课场景),那么你分析出的类型必然是在这个边界内有利于业务的:老师、学生。
对于分析类中的成员(属性、操作)也可以利用边界来分析。还是以上面的网课教育系统为例,如果不考虑边界,很可能会对老师类和学生类分析出:体重、身高、发量等无意义的属性。只有你充分考虑边界,你就会注重系统的目标、业务的场景,分析出对业务有价值的属性,例如学生类的选修课程、老师类的教龄等。
如果你对边界的概念还是比较模糊,那么你可以在识别类的时候,尝试将当前的系统目标、业务场景看作一个边界,从而选择合适的角度,去提炼出对业务系统有价值的类型。
3.外形
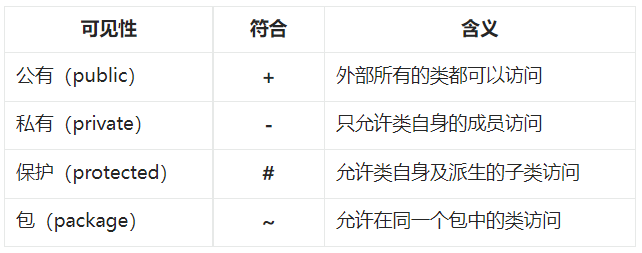
3.1.可见性
可见性主要用于标识类图中的属性和操作,通过设置不同的可见性决定外界对其的访问程度,和编程语言中的访问修饰符同理。UML规范定义了4种可见性,如下表所示。
3.2.类的表现形式
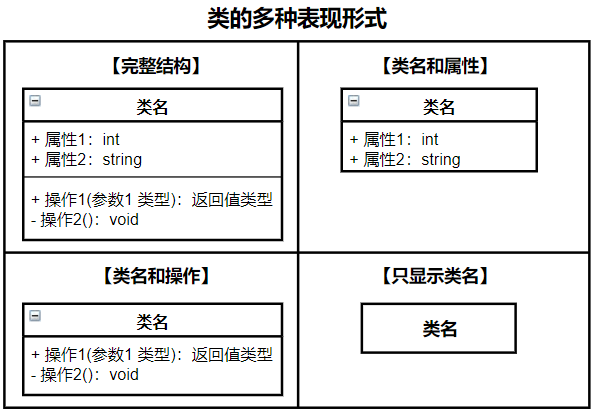
类在UML类图中的形状是一个矩形的方框,在方框中被分为三段区域,上段主要是标识类的名称,中段主要包含类的属性(特征),下段主要是包含类的是操作(行为)。表示一个类时,三段区域的设定并不是必须的,可以只在矩形方框中写一个类名,也可以只写类名和属性,或者是类名和操作。
3.3.代码类型对应类图
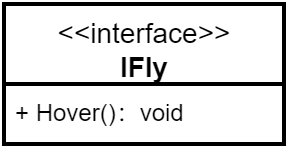
下面将使用C#编程语言编写出:普通类型、抽象类、接口。然后体现出它们在类图中的表现形式。
|
普通类 |
|
|
|
|
|
抽象类(类名和抽象方法名都是斜体) |
|
|
|
|
|
接口(名称上方加<<interface>>) |
|
|
|
|





4.关系
4.1.关联关系
概述
我们以面向对象的思想去分析业务时,其中最基本的是,要弄清楚完成这个业务需要哪些对象。但是往往只分析出对象还远远不够,因为业务对象之间是相互独立的。对象之间必须建立某种链接,促使它们相互协作通信,才能实现业务目标。而这其中用于链接对象的关系,就称之为关联。换句话说,只要两个对象之间存在关联,那么就意味着对象可以与它关联对象进行通信,获取对方的数据进行消息传递。
结构化
关联定义了类之间的一种结构化关系,是一种天然存在的关系。(好比如人出生就有拥有一个国家和一对父母)通常在代码中,关联关系体现为类的属性,如A关联B,那么B的对象会作为A对象的某个属性。在例如在运用ORM框架的代码中,类的关联对象通常定义为一个“导航属性”,可以通过这个导航属性获取到关联对象的数据。在例如数据库中,表的关联对象通常体现为一个“外键”属性,表的某行数据可以通过这个外键属性获取到关联表的数据。不管是导航属性或是外键,它们都是静态的、天然存在的结构。
方向
默认的关联关系是一条不带箭头的直线表示的,这代表着两个关联的类“知道”双方的存在,并可以互相引用。在少数情况下,当两个类之间只需要单方向链接来获取消息时,就需要标识箭头指向被链接的一方。在实际中,我们不必太过于究竟箭头的方向,大多数情况下,关联关系一般不强调关联的方向。
多重性
关联关系最明显的特征就是具有多重性,其意思是一个对象可能通过关联关系链接到多个对象上。例如张三是员工类的对象,那么张三很可能会通过与“工作任务类”之间的关联,链接获取到张三在“工作任务类”中存在的多个工作任务对象(设计XX、开发XX等),这当中对象通过关联链接到数据量的“多少”即为多重性的体现。常见的多重性包括:一对一关联、一对多关联、多对多关联等,也可以是任意数量的多重性关联,如*对*关联(*代表任意数)。
|
多重性 |
例子 |
图例 |
|
一对一 |
在某个教室中,一个学生只会指定一个座位,一个座位也只会安排一个学生。因此学生和座位之间是一对一的关联关系。 |
|
|
一对多 |
在现实生活中,一个人可以选择购买合法上牌的多辆汽车,而一辆合法上牌的车只属于一个人。在这个场景中,人和车辆之间就属于一对多的关联关系。 |
|
|
多对多 |
在学校中,一名学生会学校多门课程(语数外),而一门课程(语文)会有多名学生学习。在这个场景中,学生和课程之间属于多对多的关联关系。 |
|


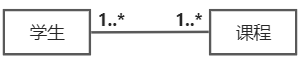
读图检查
在分析关联关系的多重性是否合理时,可以通过“读图检查法”来进行关联关系的准确性判断。你可以分别从左到右、从右到左来读图,看看有没有不合理的地方。我们使用上面多重性表格中人和车的关系为例,从左到右读:一个人对应零到多个车。从右到左读:一辆车对应一个人,而不能读成:多辆车对应一个人。注意由“多”的一边往另外一边读时,仍然是一个什么对应多少个什么,无论你从哪边开始读起,都是以“一个.....”开头。
4.2.聚合关系
在分析出两个类的关联关系之后,两个关联的类中可能还存在一种整体和部分的含义,即存在整体包含部分的现象。对于这种,存在整体和部分含义的关联关系可以进一步细化,表示成聚合关系。聚合关系可以看作,是在普通关联的基础上细化的一种特殊关联关系。除了拥有关联关系所有的基本特征外,其中一个类描述了一个较大的事物(整体),另一个类代表较小的事物(部分),较小的事物可以构成一个较大的事物。
对于聚合关系的识别,可以在已有的关联关系基础上,通过分析两个类之间是否存在:“整体由部分构成”、“部分是整体的一部分”等整体和部分的语义来完成。例如对于一个OA办公系统来说,其中部门和员工之间的关联关系就存在着整体和部分的含义。员工是部门的一部分,部门由员工构成。聚合关系是用一条带空心菱形箭头的直线表示,空心菱形箭头指向的一端表示“整体”,反方向是“部分”。示例的聚合关系如下图所示。

4.3.组合关系
组合关系是在聚合关系基础之上延申的一种关联关系,还可以将它看作是聚合关系的变体,或者是对聚合关系的进一步强调。因此组合关系具有关联、聚合的所有特征。在分析出聚合关系之后,还可以对针对整体和部分做进一步的分析:两者之间除了整体拥有部分的语义之外,两者之间是否属于“强依赖”;并且整体和部分的生命周期是一致的。如果存在以上的特点,那么可以将其表示为组合关系。
“强依赖”和一致的生命周期意味着:整体拥有部分的同时,部分不能脱离整体而存在;当整体不存在时,部分也没有存在的意义。对于组合关系中的整体和部分之间的关系特点,我们可以用一则成语来形象的描述:“皮之不存,毛将焉附”。在这种特点上,它和聚合关系恰恰相反,聚合关系即使整体不存在了,部分也依然存在。如果你认为聚合和组合比较容易混淆,那么你可以将聚合看成“弱包含关系”,组合可以看成“强包含关系”,以此来区分两者之间的差异。
基于组合关系中整体和部分的“强依赖”现象,因此在图中表示该关系的箭头,是由一条实心菱形箭头的直线表示,实心菱形箭头指向的一端表示“整体”,反方向是“部分”。示例的组合关系如下图所示。
![]()
4.4.依赖关系
概述
依赖关系是一种侧重于“行为”的使用关系,表示某个对象在某个场景下产生的行为,需要使用另外一个对象提供的服务来完成。这也意味着,被使用对象的变化可能会影响到使用对象。依赖关系的分析要结合特定的场景和相应的行为,这一点可表面它属于一种临时性的关系,它通常在行为运行期产生,并且随着运行场景的不同,依赖的对象也会发生变化。
临时性
例如人和汽车这两个对象,如果运行场景是让汽车运行在马路上,那么汽车的运行则需要依赖于人的驾驶;如果场景变为人乘坐汽车去上班,那就变成人上班通勤依赖于汽车的送达。可见,它并不像关联关系那样是一种天然的结构化关系,依赖关系是短暂的,它会随着不同场景的变化而变化的,并且依赖关系是基于场景下的行为所产生的,使用场景结束后,依赖关系也会暂时消失。如人和菜刀这两个对象,静态时它们没有关系,但在厨房切菜的场景里,人切菜的行为就依赖于菜刀;脱离了这个切菜的场景,人就暂时不需要菜刀了。
运用
依赖关系的引用通常在代码里体现为:类构造方法的参数、方法的参数。在分析时,如果发现A对象需要保存B对象的实例,但A对象的类中对B对象没有操作,B发生修改后,A不会发生变化,仅仅是A“知道”B对象,那么可以将其定义为关联关系。在分析时,如果发现A对象需要在某个业务场景的方法中,使用入参对象B的属性或方法,那么可以将其定义为依赖关系,这同时也意味着,B的修改会导致A发生修改(A依赖于B)。依赖关系在图中用一条带箭头的虚线表示,箭头指向被依赖的对象。

4.4.泛化关系
泛化关系表明,一个类可以共享另外一个或多个类的结构和行为。为了实现泛化关系,我们引入了继承机制,一个子类可以继承一个或多个父类,子类会继承父类的属性、操作和关系,因此我们通常也将泛化称为继承。此外,子类还可以根据自己的需要添加额外的属性、操作或关系,还可以对父类已有的操作进行重新定义。其中,继承一个父类为单一继承,继承多个父类为多重继承。在实际的系统应用中,我们大多数采用单一继承,因为多重继承会存在一些隐患问题,并且主流的编程语言(Java、C#)都不支持多重继承。
泛化关系除了实现复用性,更深层次的目的是达到父类替代子类的可替换性,从而实现多态处理。另外,在分析出泛化关系后,可以通过描述类之间是否存在[is a 关系]或者[kind of 关系]的语义来验证。具体来说,就是“子类是父类”(猫是动物),或“子类是父类的一种”(猫是动物的一种)。
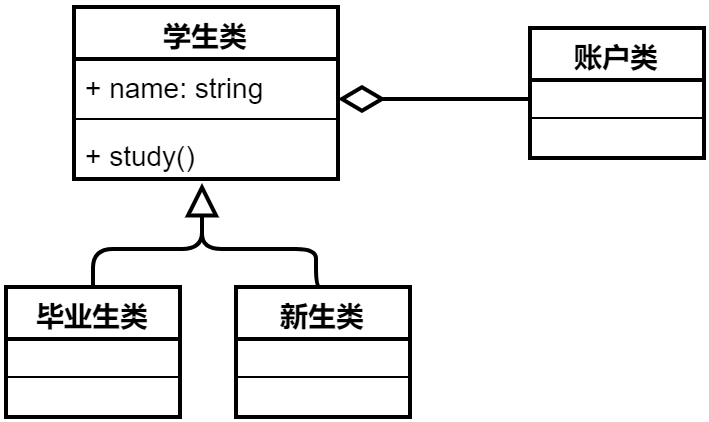
泛化关系是用一条带空心箭头的直线表示。如下图展示了学生管理系统的一种泛化关系,其中代表子类(毕业生类和新生类)都从父类(学生类)继承,它们继承了父类全部属性和操作。此外,子类也会继承父类中的关系,因此毕业生类和新生类于账户类也有聚合关系。
结语
UML类图的学习并不是一蹴而就的,也不能指望看了几篇教程就认为自己会了。在学习初期阶段先要保证自己能够读懂类图,然后可以根据已有的业务分析结果“照葫芦画瓢”的绘制出来,最后关键的还是要在于通过实践,根据具体业务发散出面向对象思想,并能将这个思想通过适当的方式在类图中简单明了的体现出来。


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 清华大学推出第四讲使用 DeepSeek + DeepResearch 让科研像聊天一样简单!
· 推荐几款开源且免费的 .NET MAUI 组件库
· 实操Deepseek接入个人知识库
· 易语言 —— 开山篇
· Trae初体验