

常见的排序算法——归并排序
本文记述了自顶向下归并排序的基本思想和一份参考实现代码,并在说明了算法的性能后用随机数据进行了验证。
◆ 思想
使用自顶向下的分治思想进行排序。将待排序元素分为两个待排序子范围,用递归的方式对两个子范围分别排序。然后将排序结果归并起来,即得到整体排序的结果。归并两个已排序的子范围时,需要借助临时的存储空间。如要得到逆序的结果,则仅需改变比较的方向即可。
◆ 实现
排序代码采用《算法(第4版)》的“排序算法类模板”实现。(代码中涉及的基础类,如 Array,请参考算法文章中涉及的若干基础类的主要API)
// merge.hxx
...
class Merge
{
...
template
<
class _T,
class = typename std::enable_if<std::is_base_of<Comparable<_T>, _T>::value>::type
>
static
void
sort(Array<_T> & a)
{
Array<_T> aux = Array<_T>(a.size()); // #1
__sort__(a, 0, a.size()-1, aux);
}
...
template
<
class _T,
class = typename std::enable_if<std::is_base_of<Comparable<_T>, _T>::value>::type
>
static
void
__sort__(Array<_T> & a, int lo, int hi, Array<_T> & aux)
{
if (hi <= lo) return;
int mi = lo + (hi - lo) / 2; // #2
__sort__(a, lo, mi, aux); // #3
__sort__(a, mi+1, hi, aux);
__merge__(a, lo, mi, hi, aux); // #4
}
...
template
<
class _T,
class = typename std::enable_if<std::is_base_of<Comparable<_T>, _T>::value>::type
>
static
void
__merge__(Array<_T> & a, int lo, int mi, int hi, Array<_T> & aux)
{
int i = lo, j = mi+1;
for (int k = lo; k <= hi; ++k) // #1
aux[k] = a[k];
for (int k = lo; k <= hi; ++k) // #5
if (i > mi) a[k] = aux[j++];
else if (j > hi) a[k] = aux[i++];
else if (__less__(aux[j], aux[i])) a[k] = aux[j++];
else a[k] = aux[i++];
}
...
template
<
class _T,
class = typename std::enable_if<std::is_base_of<Comparable<_T>, _T>::value>::type
>
static
bool
__less__(_T const& v, _T const& w)
{
return v.compare_to(w) < 0; // #6
}
...
归并过程需要借助临时的存储空间(#1),其作为参数被传递给递归的 __sort__() 函数。将待排序范围分成两半(#2),用递归的方式对两个子范围分别排序(#3),然后将排序结果归并起来(#4)。通过一一比较,将各自排序的结果归并起来(#5)。将 '<' 改为 '>',即得到逆序的结果(#6)。
◆ 性能
| 时间复杂度 | 空间复杂度 | 是否稳定 |
|---|---|---|
| N*log(N) | N | 是 |
◆ 验证
测试代码采用《算法(第4版)》的倍率实验方案,用随机数据验证其正确性并获取时间复杂度数据。
// test.cpp
...
time_trial(int N)
{
Array<Double> a(N);
for (int i = 0; i < N; ++i) a[i] = Std_Random::random(); // #1
Stopwatch timer;
Merge::sort(a); // #2
double time = timer.elapsed_time();
assert(Merge::is_sorted(a)); // #3
return time;
}
...
test(char * argv[])
{
int T = std::stoi(argv[1]); // #4
double prev = time_trial(512);
Std_Out::printf("%10s%10s%7s\n", "N", "Time", "Ratio");
for (int i = 0, N = 1024; i < T; ++i, N += N) { // #5
double time = time_trial(N);
Std_Out::printf("%10d%10.3f%7.2f\n", N, time, time/prev); // #6
prev = time;
}
}
...
用 [0,1) 之间的实数初始化待排序数组(#1),打开计时器后执行排序(#2),确保得到正确的排序结果(#3)。整个测试过程要执行 T 次排序(#4)。每次执行排序的数据规模都会翻倍(#5),并以上一次排序的时间为基础计算倍率(#6),
此测试在实验环境一中完成,
$ g++ -std=c++11 test.cpp std_out.cpp std_random.cpp stopwatch.cpp type_wrappers.cpp
$ ./a.out 15
N Time Ratio
1024 0.007 2.33
2048 0.017 2.43
4096 0.037 2.18
8192 0.082 2.22
16384 0.177 2.16
32768 0.380 2.15
65536 0.811 2.13
131072 1.727 2.13
262144 3.660 2.12
524288 7.733 2.11
1048576 16.294 2.11
2097152 34.246 2.10
4194304 71.784 2.10
8388608 150.179 2.09
16777216 313.591 2.09
可以看出,随着数据规模的成倍增长,排序所花费的时间将是上一次规模的 2.1? 倍,且在不断变小。将数据反映到以 2 为底数的对数坐标系中,可以得到如下图像,
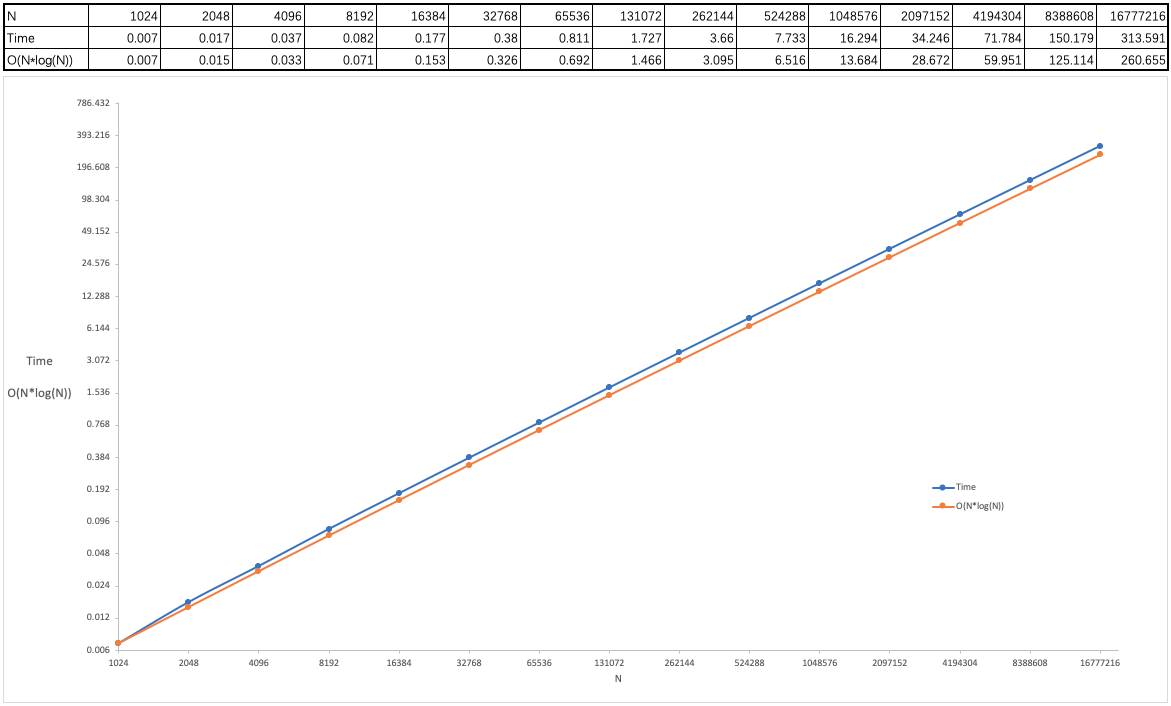
O(N*log(N)) 代表了线性对数级别复杂度下的理论排序时间,该行中的数据是以 Time 行的第一个数据为基数逐一乘 2 + 2/log(N) 后得到的结果(因为做的是倍率实验,所以乘 (2*N*log(2*N)) / (N*log(N)),化简得到 2 + 2/log(N),即乘 2+2/log(1024),2+2/log(2048),2+2/log(4096),... 2+2/log(16777216);因为是二分归并,所以 log 的底数为 2)。
◆ 最后
完整的代码请参考 [gitee] cnblogs/18150209 。
查看性能对比,了解此算法与其它排序算法的相似性和差异性。
写作过程中,笔者参考了《算法(第4版)》的归并排序、“排序算法类模板”和倍率实验。致作者 Sedgwick,Wayne 及译者谢路云。
受限于作者的水平,读者如发现有任何错误或有疑问之处,请追加评论或发邮件联系 green-pi@qq.com。作者将在收到意见后的第一时间里予以回复。 本文来自博客园,作者:green-cnblogs,转载请注明原文链接:https://www.cnblogs.com/green-cnblogs/p/18150209 谢谢!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 25岁的心里话
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器