

简单的线程池(八)
笔者根据 Anthony Williams 在《C++并发编程实战》中所述,
某个工作线程在任务队列的头部操作,而其它工作线程在任务队列的尾部操作。这实际上意味着这个队列对于拥有线程来说是一个后进先出的栈。最近被放到队列中的任务会最先被取出来执行。从缓存的角度来说这可以提高性能,因为对比之前被放入队列中的任务,被取出的任务的数据更加有可能在缓存中。
尝试调整了 《简单的线程池(七)》 中提及的非阻塞互助式线程池的实现方案,用 std::deque 替换 std::queue 作为存储工作任务的底层数据结构,并新定义非阻塞线程安全的双端队列 Lockwise_Deque<>。
工作任务始终被添加至双端队列的尾部。为了验证从缓存的角度是否可以提高性能,笔者用四种方式实现工作任务的获取,
- 当前工作线程从自己的任务队列的头部获取任务,如无工作任务则从其他任务队列的头部获取任务(A);
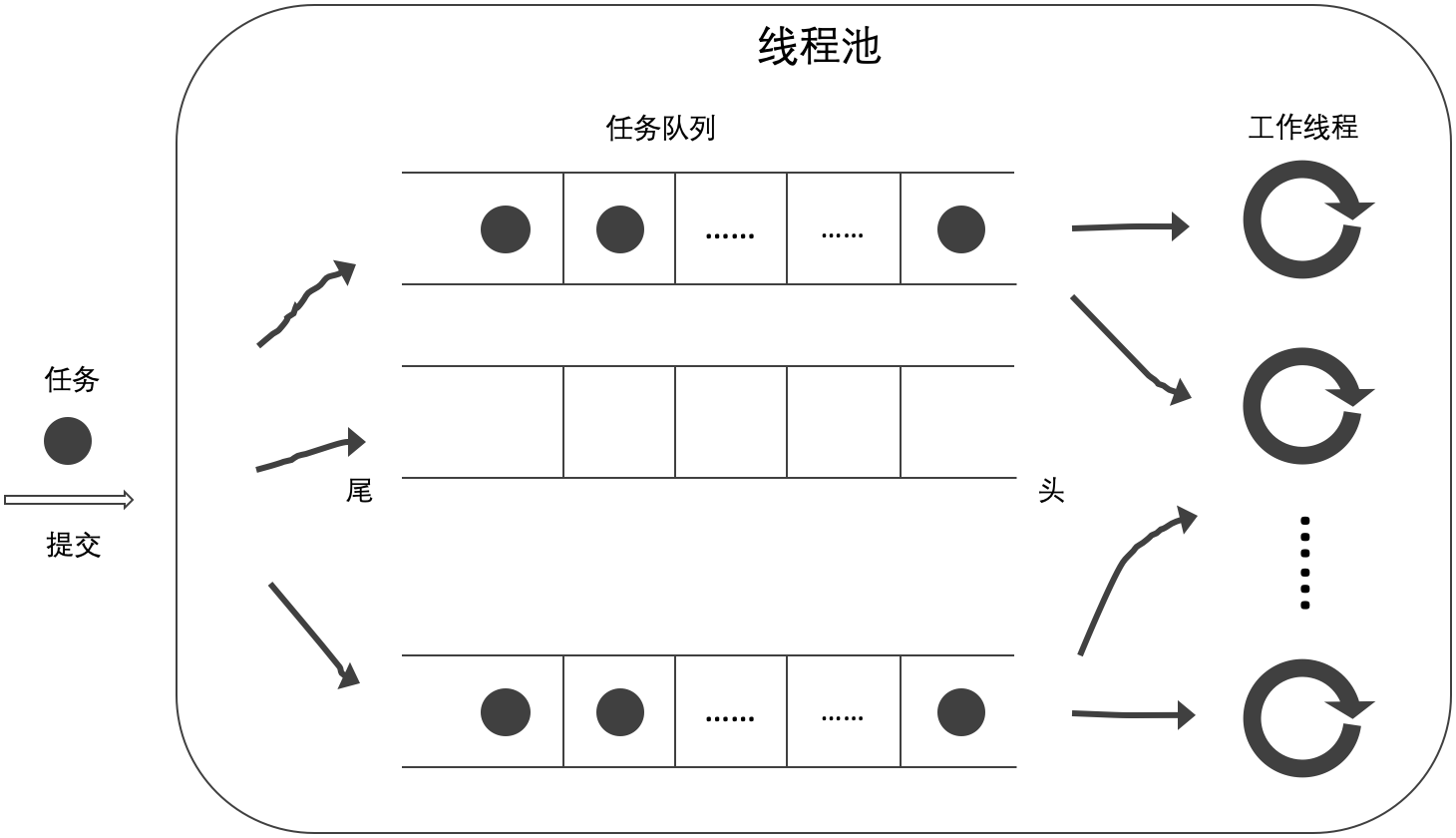
- 当前工作线程从自己的任务队列的尾部获取任务,如无工作任务则从其他任务队列的头部获取任务(B);
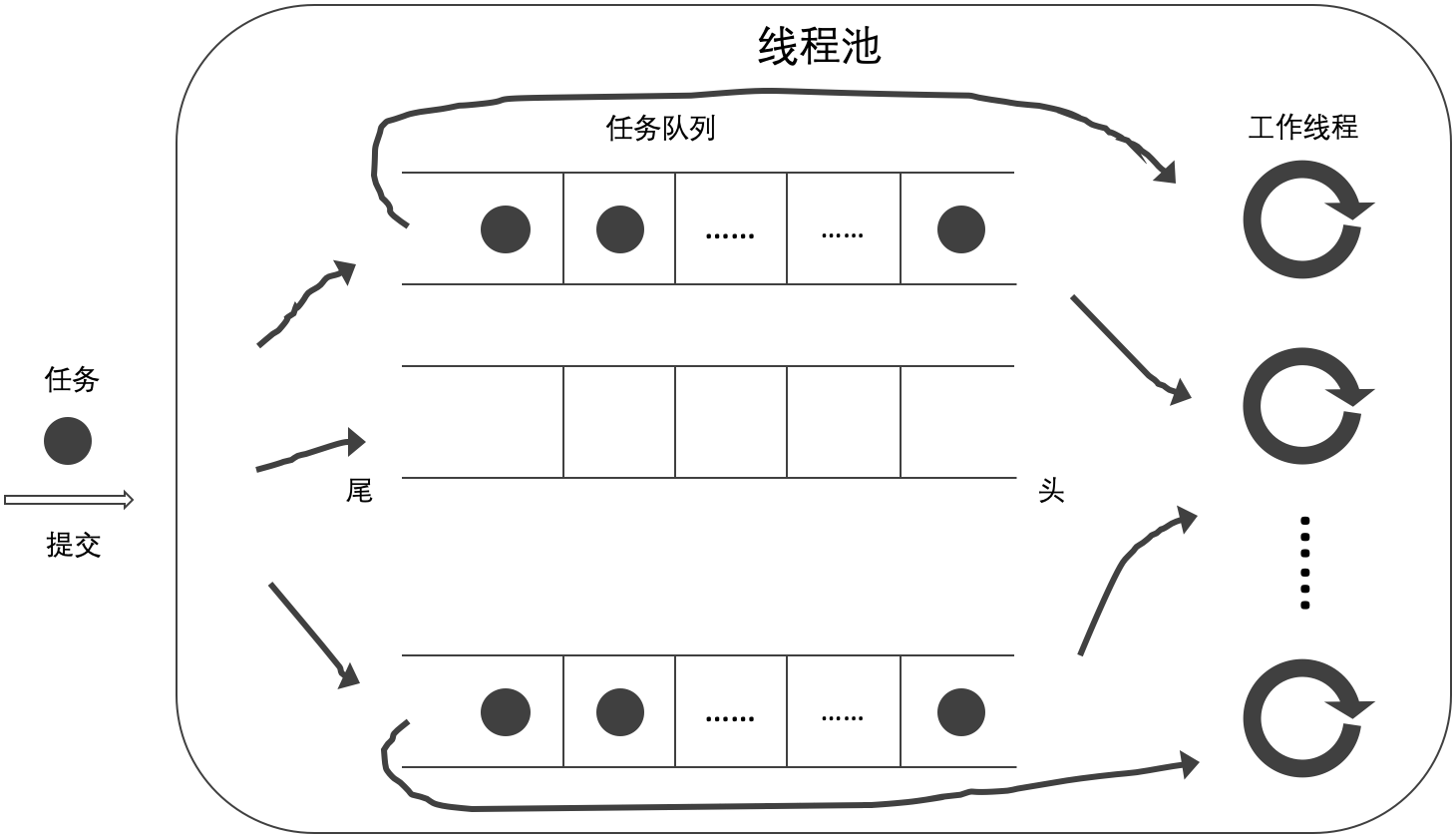
- 当前工作线程从自己的任务队列的头部获取任务,如无工作任务则从其他任务队列的尾部获取任务(C);
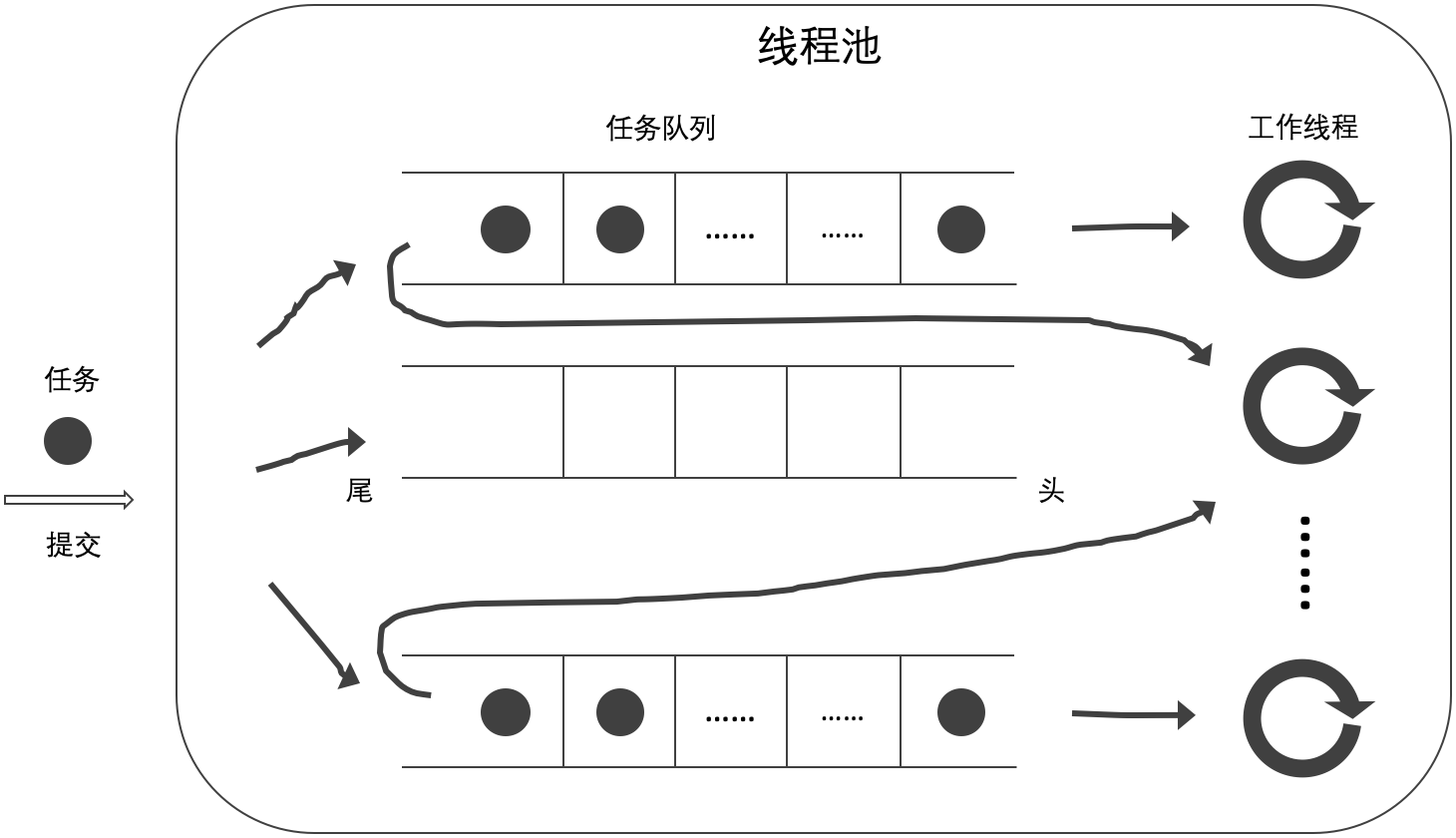
- 当前工作线程从自己的任务队列的尾部获取任务,如无工作任务则从其他任务队列的尾部获取任务(D)。
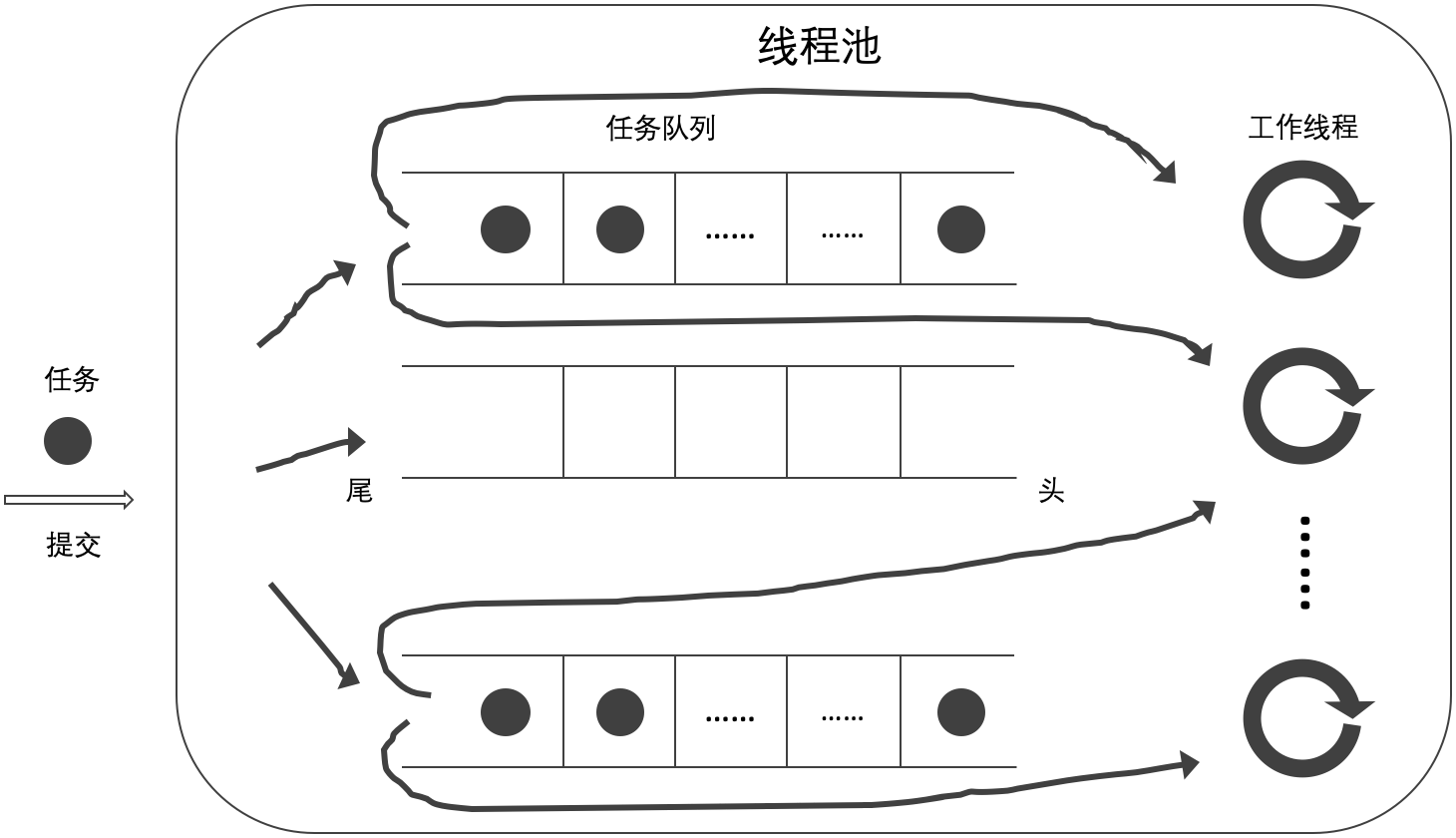
A 方式即为最初的非阻塞互助式,差别在于底层数据结构由 std::queue 更改为 std::deque;B 方式即按照 Anthony 所述的实现;C 和 D 是笔者为了全面确认缓存对性能的影响而增加的方式。
本文不再赘诉与 《简单的线程池(七)》 相同的内容。如有不明之处,请参考该博客。
◆ 实现
以下代码给出了非阻塞线程安全双端队列的实现,(lockwise_deque.h)
template<class T>
class Lockwise_Deque {
private:
struct Spinlock_Mutex { ...
} mutable _m_;
deque<T> _q_;
public:
void push(T&& element) {
lock_guard<Spinlock_Mutex> lk(_m_);
_q_.push_back(std::move(element)); // #1
}
bool pop(T& element) {
lock_guard<Spinlock_Mutex> lk(_m_);
if (_q_.empty())
return false;
element = std::move(_q_.front()); // #2
_q_.pop_front();
return true;
}
bool pull(T& element) {
lock_guard<Spinlock_Mutex> lk(_m_);
if (_q_.empty())
return false;
element = std::move(_q_.back()); // #3
_q_.pop_back();
return true;
}
...
};
push(T&&) 函数实现从双端队列尾部添加任务(#1),pop(T&) 函数实现从双端队列头部获取任务(#2),pull(T&) 函数实现从双端队列尾部获取任务(#3)。
以下代码给出 A 方式的实现,(lockwise_mutual_2a_pool.h)
class Thread_Pool {
...
void work(unsigned index) {
Task_Wrapper task;
while (!_done_.load(memory_order_acquire)) {
if (_workerqueues_[index].pop(task)) // #1
task();
else
for (unsigned i = 0; i < _workersize_; ++i)
if (_workerqueues_[(index + i + 1) % _workersize_].pop(task)) { // #2
task();
break;
}
while (_suspend_.load(memory_order_acquire))
std::this_thread::yield();
}
}
...
}
当前工作线程从自己的任务队列的头部获取工作任务(#1),如无工作任务则从其他任务队列的头部获取任务(#2)。
以下代码给出 B 方式的实现,(lockwise_mutual_2b_pool.h)
class Thread_Pool {
...
void work(unsigned index) {
Task_Wrapper task;
while (!_done_.load(memory_order_acquire)) {
if (_workerqueues_[index].pull(task)) // #1
task();
else
for (unsigned i = 0; i < _workersize_; ++i)
if (_workerqueues_[(index + i + 1) % _workersize_].pop(task)) { // #2
task();
break;
}
while (_suspend_.load(memory_order_acquire))
std::this_thread::yield();
}
}
...
}
当前工作线程从自己的任务队列的尾部获取工作任务(#1),如无工作任务则从其他任务队列的头部获取任务(#2)。
以下代码给出 C 方式的实现,(lockwise_mutual_2c_pool.h)
class Thread_Pool {
...
void work(unsigned index) {
Task_Wrapper task;
while (!_done_.load(memory_order_acquire)) {
if (_workerqueues_[index].pop(task)) // #1
task();
else
for (unsigned i = 0; i < _workersize_; ++i)
if (_workerqueues_[(index + i + 1) % _workersize_].pull(task)) { // #2
task();
break;
}
while (_suspend_.load(memory_order_acquire))
std::this_thread::yield();
}
}
...
}
当前工作线程从自己的任务队列的头部获取工作任务(#1),如无工作任务则从其他任务队列的尾部获取任务(#2)。
以下代码给出 D 方式的实现,(lockwise_mutual_2d_pool.h)
class Thread_Pool {
...
void work(unsigned index) {
Task_Wrapper task;
while (!_done_.load(memory_order_acquire)) {
if (_workerqueues_[index].pull(task)) // #1
task();
else
for (unsigned i = 0; i < _workersize_; ++i)
if (_workerqueues_[(index + i + 1) % _workersize_].pull(task)) { // #2
task();
break;
}
while (_suspend_.load(memory_order_acquire))
std::this_thread::yield();
}
}
...
}
当前工作线程从自己的任务队列的尾部获取工作任务(#1),如无工作任务则从其他任务队列的尾部获取任务(#2)。
◆ 逻辑
以下类图展现了此线程池的代码主要逻辑结构。
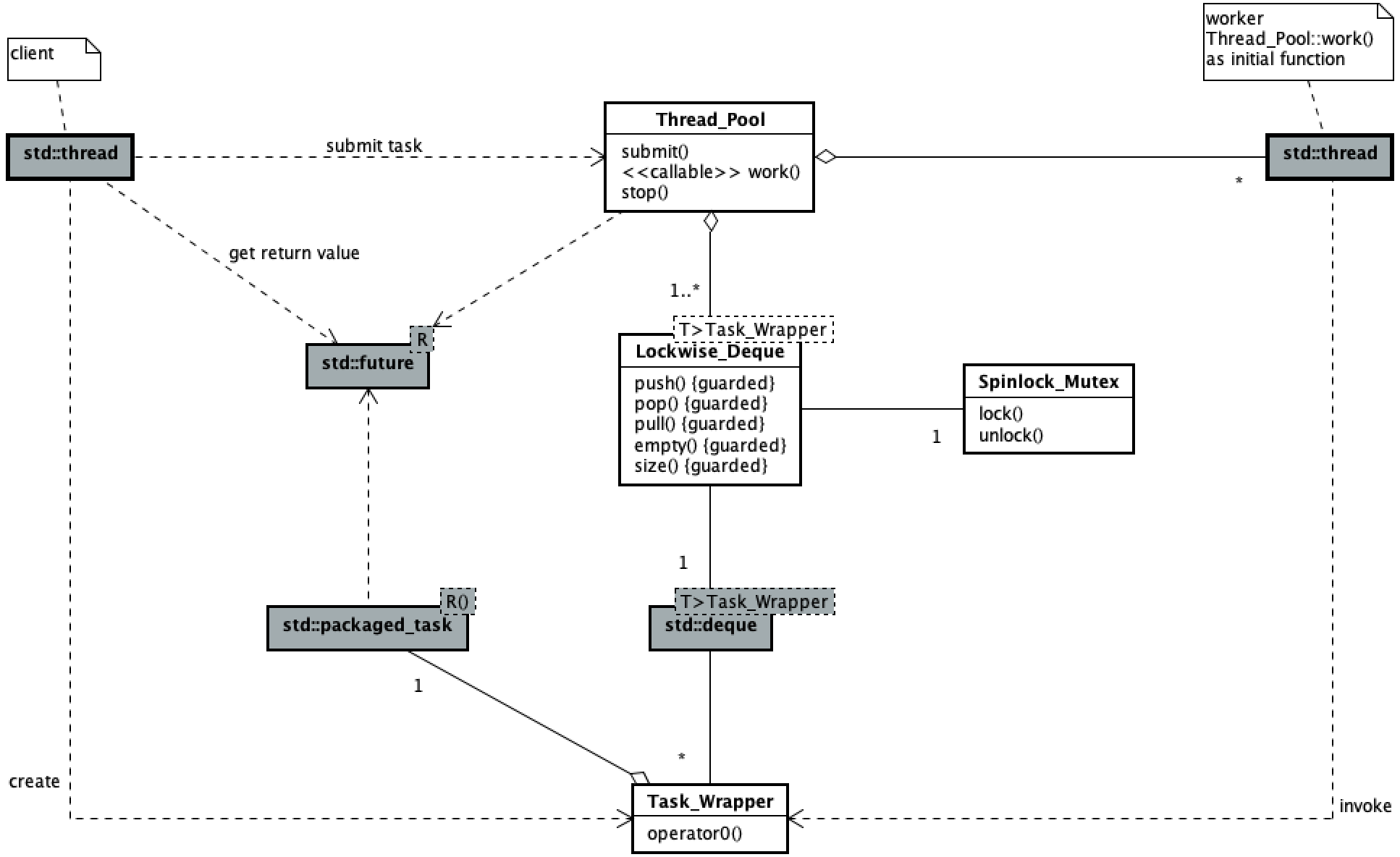
线程池用户提交任务与工作线程执行任务的并发过程与 《简单的线程池(一)》 中的一致,此处略。
◆ 验证
验证过程采用了 《简单的线程池(三)》 中定义的的测试用例。笔者对比了测试结果与 《简单的线程池(七)》 的数据,结果如下,
图1 列举了 吞吐量1的差异 在 0.5 分钟、1 分钟和 3 分钟的提交周期内不同思考时间上的对比。
【注】四种非阻塞线程安全的双端队列略称为 LM2A、LM2B、LM2C 和 LM2D,下同。
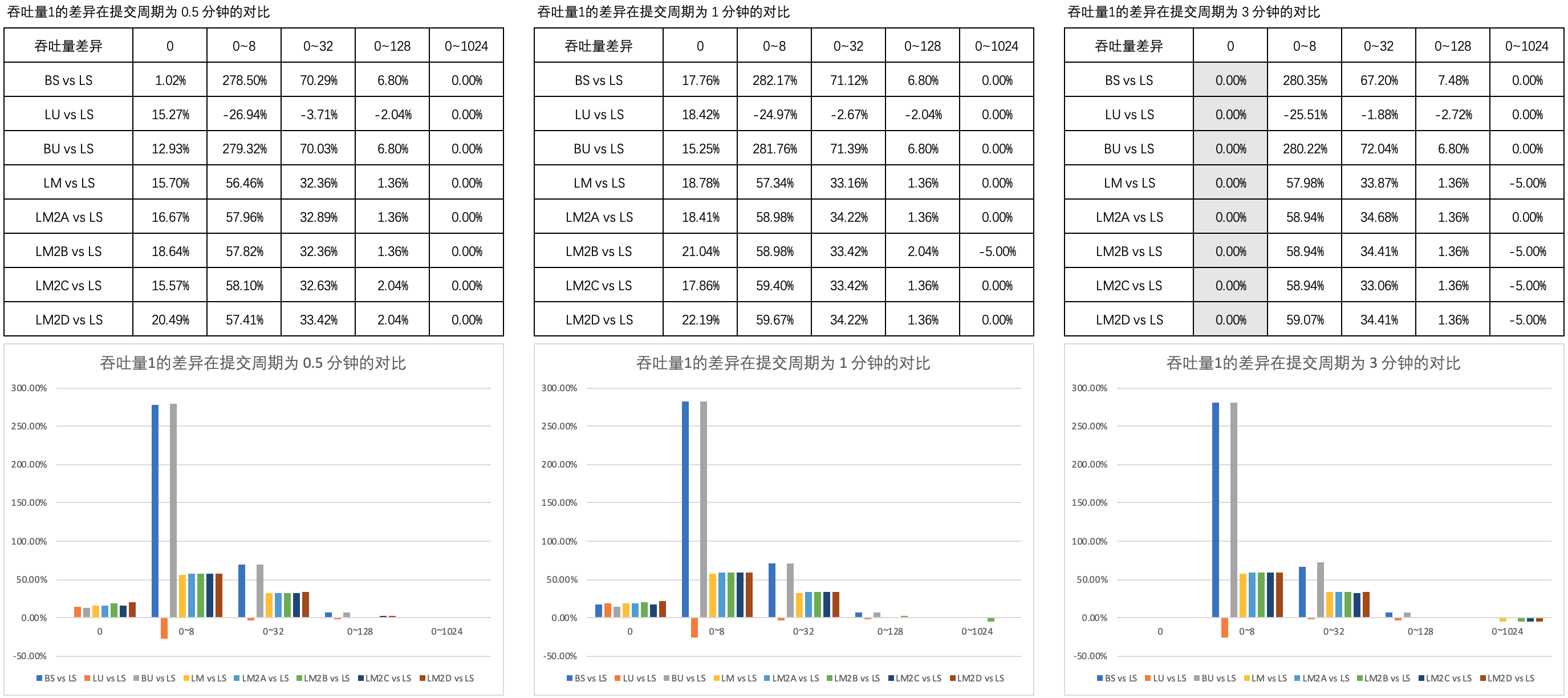
图2 列举了 吞吐量2的差异 在 0.5 分钟、1 分钟和 3 分钟的提交周期内不同思考时间上的对比。
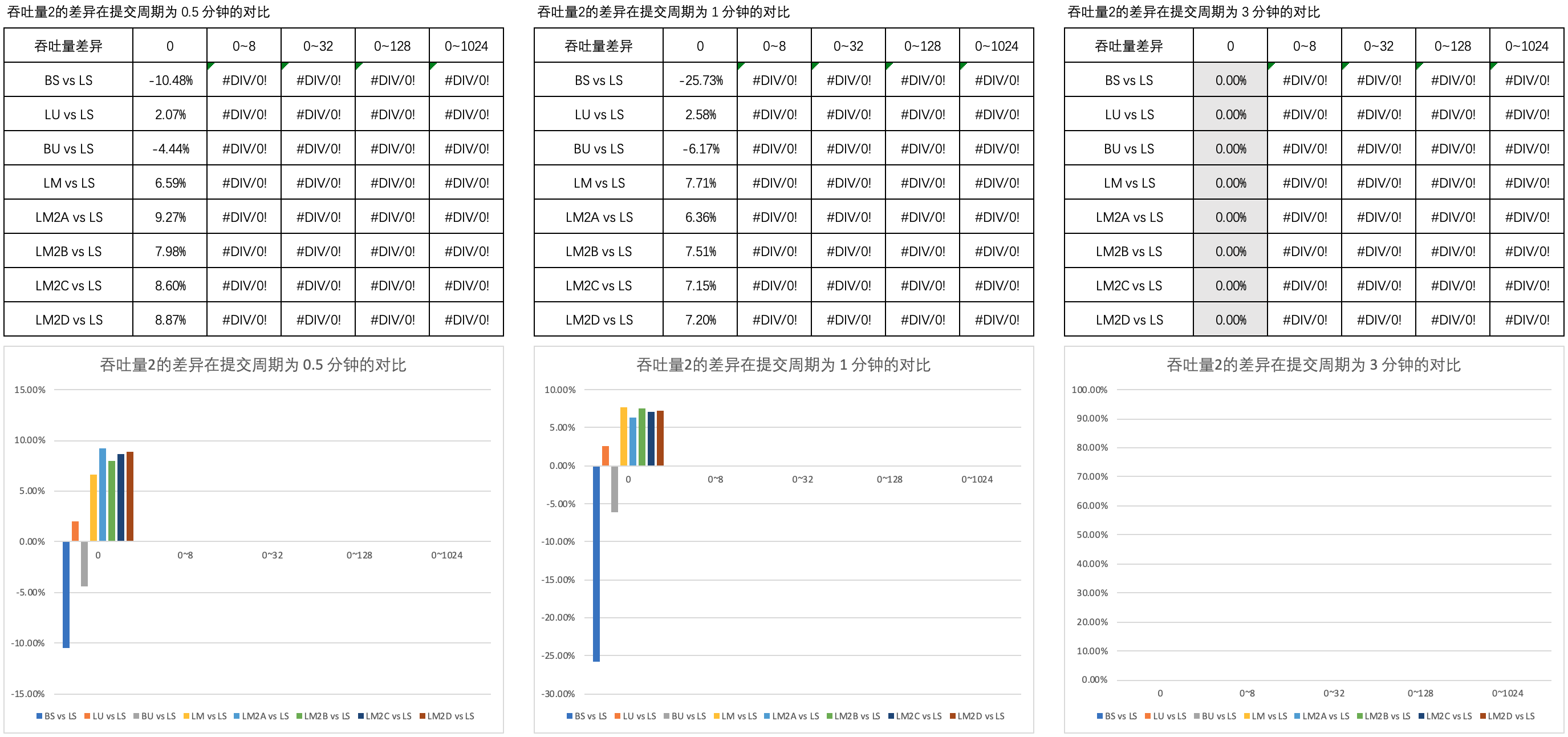
图3 列举了 吞吐量3的差异 在 0.5 分钟、1 分钟和 3 分钟的提交周期内不同思考时间上的对比。
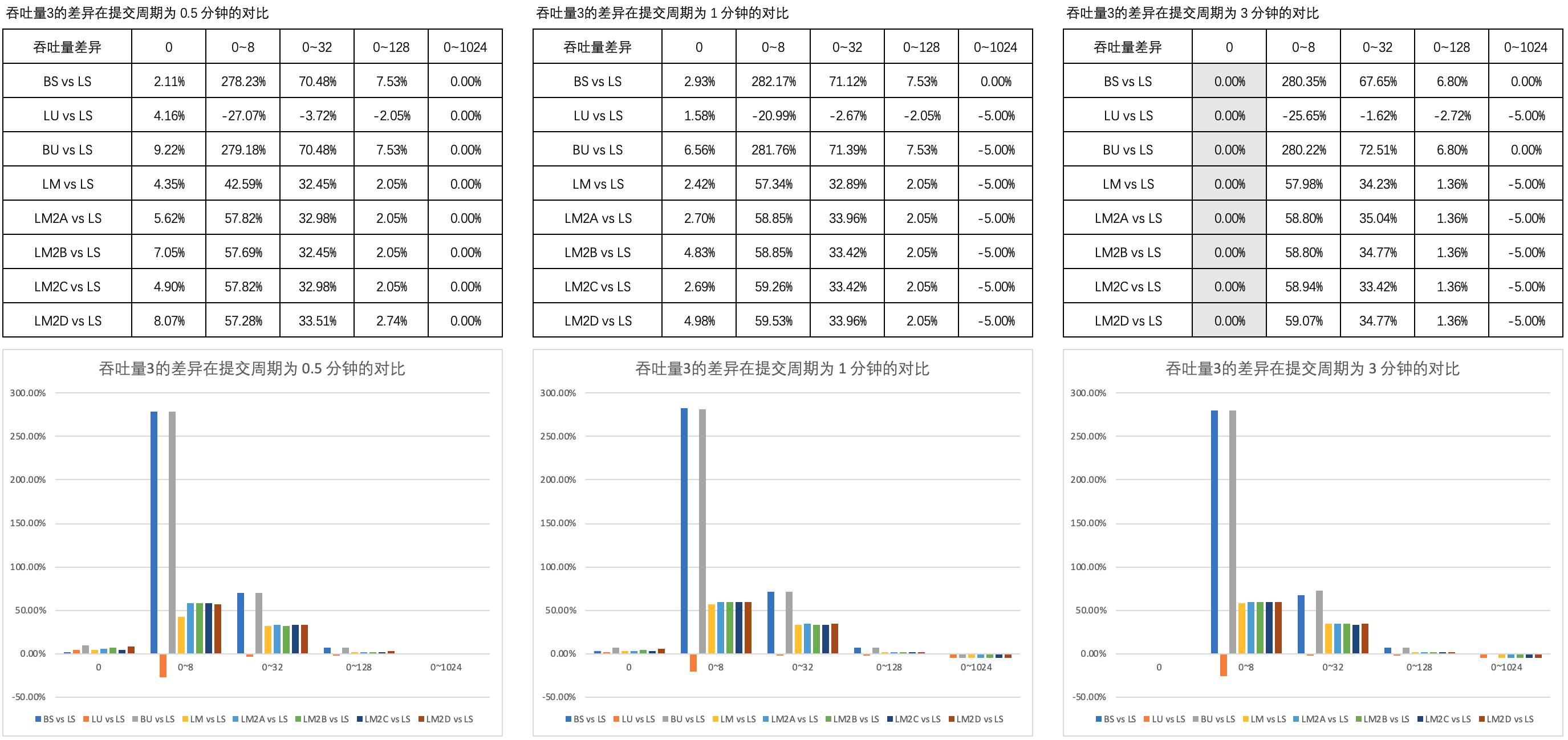
可以看到,B 方式的非阻塞互助式线程池与 A、C、D 方式的以及普通队列的非阻塞互助式在吞吐量上的表现近乎一致。
基于以上的对比分析,笔者认为,在非阻塞式线程池中采用双端队列,
从缓存的角度来说这可以提高性能
这样的论述是值得讨论的。
◆ 最后
完整的代码和测试数据请参考 [gitee] cnblogs/15723078 。
作者参考了《C++并发编程实战》一书中的部分设计思路。致 Anthony Williams、周全等译者。
受限于作者的水平,读者如发现有任何错误或有疑问之处,请追加评论或发邮件联系 green-pi@qq.com。作者将在收到意见后的第一时间里予以回复。 本文来自博客园,作者:green-cnblogs,转载请注明原文链接:https://www.cnblogs.com/green-cnblogs/p/15723078.html 谢谢!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!