简单的线程池(七)
本文中,笔者为 《简单的线程池(四)》 提及的非阻塞独占式线程池增加了一项功能:当某个工作线程的任务队列中无工作任务时,此工作线程可以去其他工作线程的任务队列中获取任务。笔者称之为非阻塞互助式线程池。
笔者对比了测试结果与 《简单的线程池(六)》 的数据,得出了添加功能前后的差异。
本文不再赘诉与 《简单的线程池(四)》 相同的内容。如有不明之处,请参考该博客。
◆ 实现
以下代码给出了此线程池的实现,(lockwise_mutual_pool.h)
class Thread_Pool {
private:
struct Task_Wrapper { ...
};
atomic<bool> _suspend_;
atomic<bool> _done_;
unsigned _workersize_;
thread* _workers_;
Lockwise_Queue<Task_Wrapper>* _workerqueues_;
void work(unsigned index) {
Task_Wrapper task;
while (!_done_.load(memory_order_acquire)) {
if (_workerqueues_[index].pop(task))
task();
else // # 1
for (unsigned i = 0; i < _workersize_; ++i)
if (_workerqueues_[(index + i + 1) % _workersize_].pop(task)) { // #2
task();
break;
}
while (_suspend_.load(memory_order_acquire))
std::this_thread::yield();
}
}
void stop() { ...
}
public:
Thread_Pool() : _suspend_(false), _done_(false) { ....
}
~Thread_Pool() { ...
}
template<class Callable>
future<typename std::result_of<Callable()>::type> submit(Callable c) { ...
}
};
此线程池的代码与 非阻塞独占式线程池 相比,仅在工作线程的初始函数 Thread_Pool::work(unsigned) 上有区别。当某个工作线程的任务队列中无工作任务时(#1),此工作线程会去其他工作线程的任务队列中获取任务。这里涉及到的“选择其他工作线程的任务队列的算法”(#2),来自于本文最后的参考书籍。
◆ 逻辑
此线程池的结构和与 《简单的线程池(四)》 中的一致,此处略。
此线程池用户提交任务与工作线程执行任务的并发过程与 《简单的线程池(一)》 中的一致,此处略。
◆ 验证
验证过程采用了 《简单的线程池(三)》 中定义的的测试用例。笔者对比了测试结果与 《简单的线程池(六)》 的数据,结果如下,
图1 列举了 吞吐量1的差异 在 0.5 分钟、1 分钟和 3 分钟的提交周期内不同思考时间上的对比。
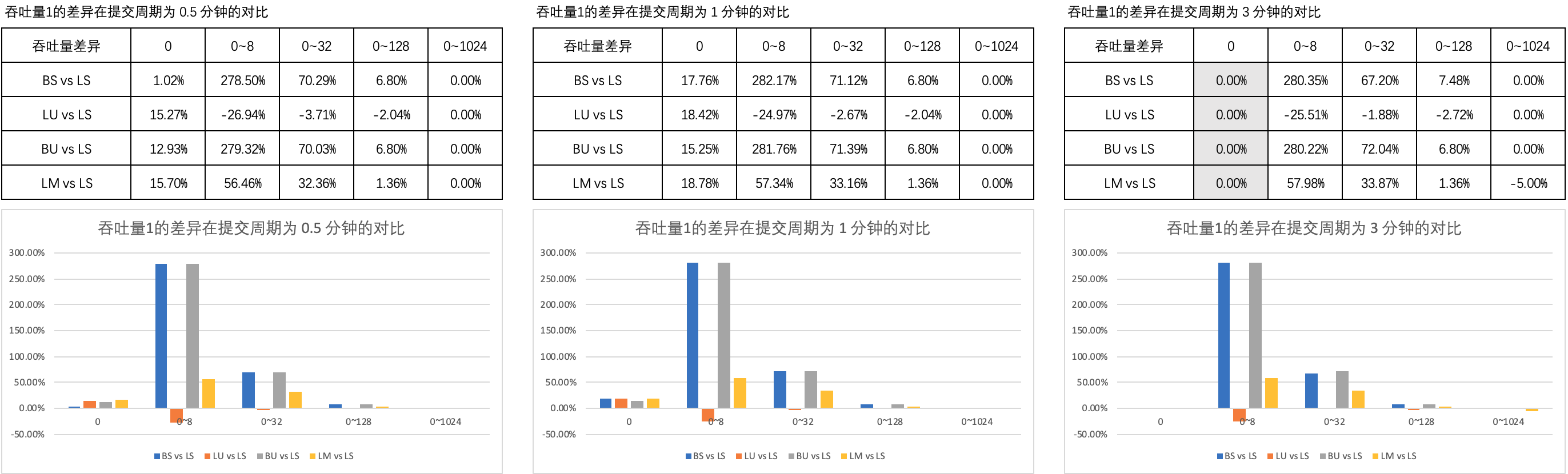
【注】非阻塞互助式 略称为 LM ,下同。
可以看到,
- 当思考时间为 0 时,LM 的吞吐量优于 LS、BS 的吞吐量,相当于 LU、BU 的吞吐量;延长提交周期后,LM 和 LS、BS、LU、BU 的吞吐量差异没有发生明显变化;
- 当思考时间不为 0 时,LM 的吞吐量大幅优于 LS、LU 的吞吐量,大幅劣于 BS、BU 的吞吐量,但差异不会因提交周期的延长而大幅变化;随着思考时间的增加,LM 的吞吐量与 LS、BS、LU、BU 的吞吐量差异逐渐消失。
图2 列举了 吞吐量2的差异 在 0.5 分钟、1 分钟和 3 分钟的提交周期内不同思考时间上的对比。
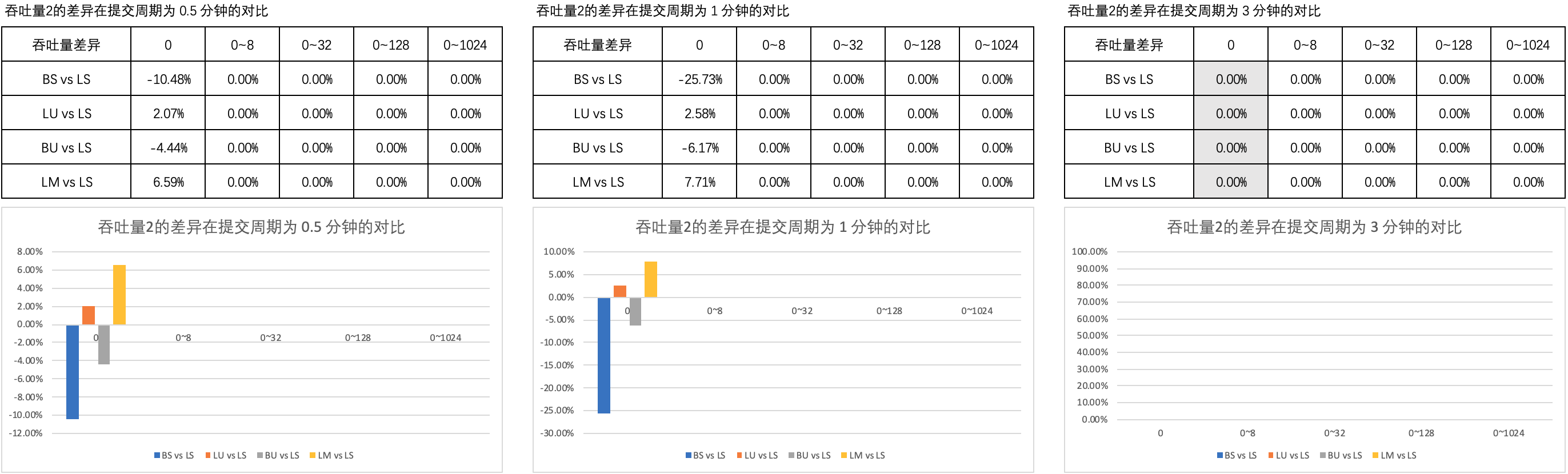
可以看到,
- 当思考时间为 0 时,LM 的吞吐量优于 LS、BS、LU、BU 的吞吐量;延长提交周期后,LM 和 LS、BS、LU、BU 的吞吐量差异没有发生明显变化;
- 当思考时间不为 0 时,因 LM 和 LS、BS、LU、BU 的吞吐量均为 0,它们间没有差异。
图3 列举了 吞吐量3的差异 在 0.5 分钟、1 分钟和 3 分钟的提交周期内不同思考时间上的对比。
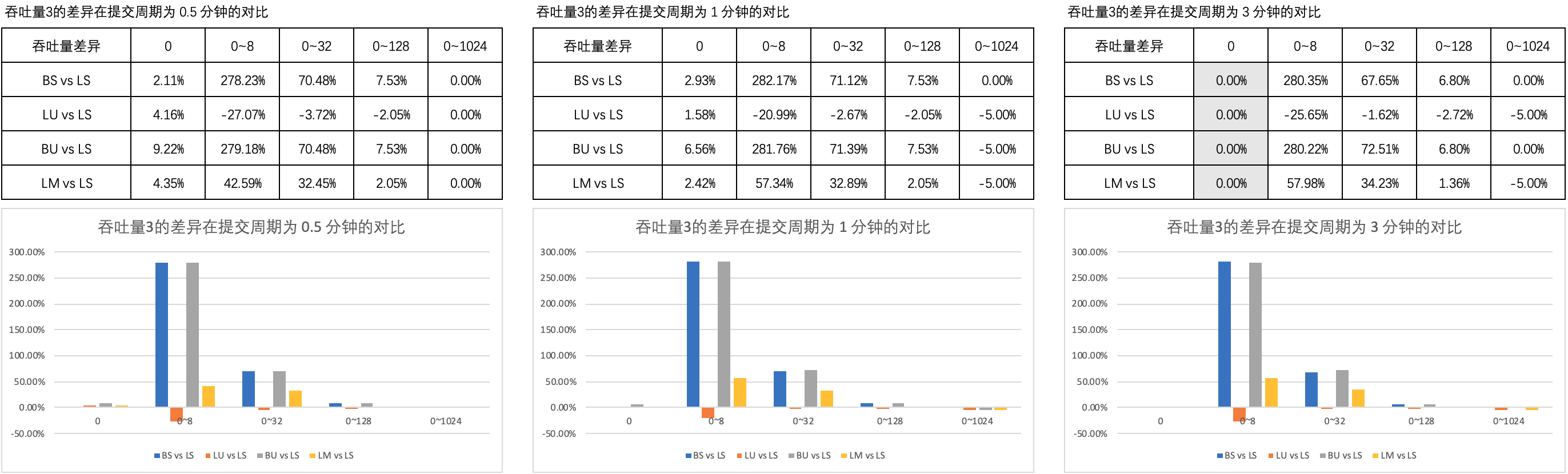
可以看到,
- 当思考时间为 0 时,LM 的吞吐量相当于 LS、BS、LU 的吞吐量,略劣于 BU 的吞吐量;延长提交周期后,LM 和 LS、BS、LU、BU 的吞吐量差异没有发生明显变化;
- 当思考时间不为 0 时,LM 的吞吐量大幅优于 LS、LU 的吞吐量,大幅劣于 BS、BU 的吞吐量,但差异不会因提交周期的延长而大幅变化;随着思考时间的增加,LM 的吞吐量与 LS、BS、LU、BU 的吞吐量差异逐渐消失。
基于以上的对比分析,笔者认为,在非阻塞式线程池中,
- 互助式的吞吐量指标优于共享式、独占式的吞吐量指标。
◆ 最后
完整的代码和测试结果请参考 [gitee] cnblogs/15710614 。
关于“选择其他工作线程的任务队列的算法”,笔者参考了《C++并发编程实战》一书。致 Anthony Williams、周全等译者。
受限于作者的水平,读者如发现有任何错误或有疑问之处,请追加评论或发邮件联系 green-pi@qq.com。作者将在收到意见后的第一时间里予以回复。 本文来自博客园,作者:green-cnblogs,转载请注明原文链接:https://www.cnblogs.com/green-cnblogs/p/15710614.html 谢谢!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号