
简单的线程池(三)
本文中,作者针对 《简单的线程池(一)》 和 《简单的线程池(二)》 介绍的两个线程池分别进行了并发测试。基于收集的测试数据,笔者对结果进行了分析,给出笔者的结论。
◆ 目的
本测试是为了确认非阻塞式线程池与阻塞式线程池的生存性,以及两者在吞吐量上的差异,为改进线程池提供数据支撑。
【注】这里的差异以非阻塞式的吞吐量为基准计算得出的,即 (阻塞式吞吐量 - 非阻塞式吞吐量) ÷ 非阻塞式吞吐量 的百分比。类似并发、压力之类的测试依赖于测试环境,因此笔者认为两者在量级上的差异比绝对数据更有意义。
◆ 环境
考虑到两个线程池的简单程度,为易于显示两者之间的差异,笔者选择了硬件配置偏低的实验环境一。
◆ 用例
针对两个线程池,测试过程模拟出 10 个用户(线程)向线程池提交任务,分别实施如下 15 个测试用例,
| 编号 | 提交周期(分钟) | 思考时间(毫秒) |
|---|---|---|
| 1 | 0.5 | 0 |
| 2 | 0.5 | 0 ~ 8 随机 |
| 3 | 0.5 | 0 ~ 32 随机 |
| 4 | 0.5 | 0 ~ 128 随机 |
| 5 | 0.5 | 0 ~ 1024 随机 |
| 6 | 1 | 0 |
| 7 | 1 | 0 ~ 8 随机 |
| 8 | 1 | 0 ~ 32 随机 |
| 9 | 1 | 0 ~ 128 随机 |
| 10 | 1 | 0 ~ 1024 随机 |
| 11 | 3 | 0 |
| 12 | 3 | 0 ~ 8 随机 |
| 13 | 3 | 0 ~ 32 随机 |
| 14 | 3 | 0 ~ 128 随机 |
| 15 | 3 | 0 ~ 1024 随机 |
收集如下测试数据,
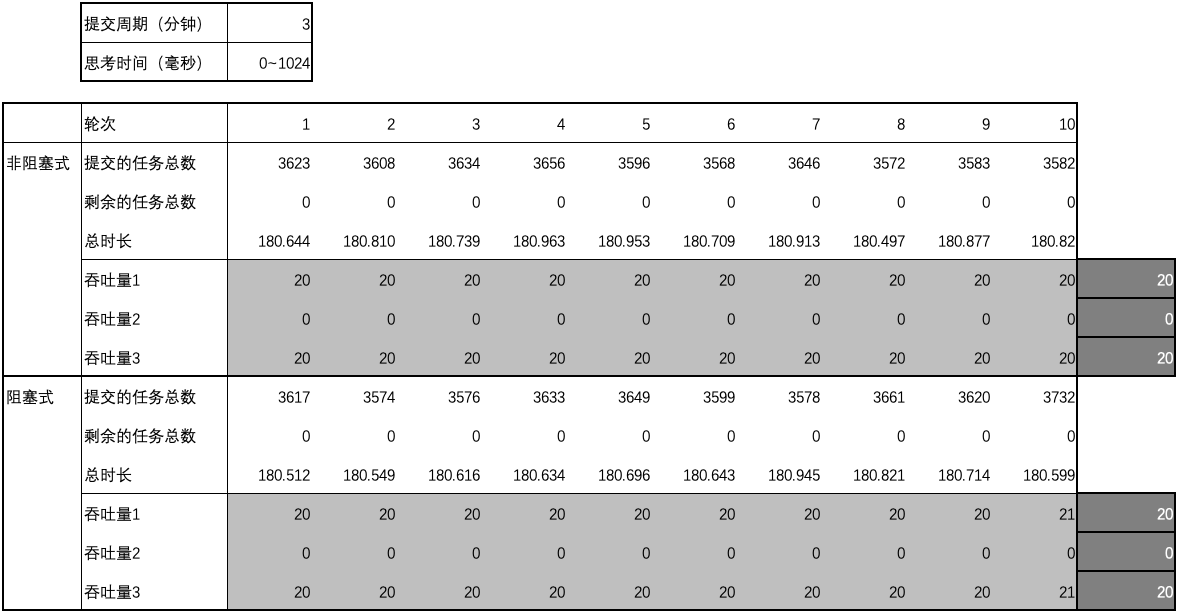
- 提交的任务总数 (A): 在提交周期内,所有用户提交的任务总数;
- 剩余的任务总数 (B): 用户结束提交时,线程池中剩余的任务总数;
- 总时长 (C): 从提交任务开始到处理完所有任务之间的总时间,精确到千分之一秒。
得出 3 个吞吐量指标(任务数 ÷ 秒),
- 从开始提交任务到结束提交任务期间的吞吐量(1): (A - B)÷(并发周期 × 60);
- 从结束提交任务开始到处理完所有任务期间的吞吐量(2): B ÷(总时长 - 并发周期 × 60);
- 从开始提交任务到到处理完所有任务期间的吞吐量(3): A ÷ 总时长。
如果把线程池接受任务的过程称为“吞”,线程池分派任务的过程称为“吐”,则根据前述吞吐量 1 ~ 3 的定义可以看出,吞吐量1 代表的是线程池在有用户提交任务的时间段内的 “吞” + “吐” 的绝对能力;吞吐量2 代表的是线程池在无用户提交任务的时间段内的 “吐” 的绝对能力;吞吐量3 代表的是线程池在 有提交任务 + 没提交任务 的时间段内的 ”吞“ + ”吐“ 的整体能力。
每个测试用例执行 10 次,执行结果的平均值作为某指标的平均吞吐量。为了降低 I/O 对并发能力的影响,程序中任务输出到 stdout 的内容都被重定向到 /dev/null,仅将 stderr 的内容输出到终端。
测试用例执行文件:
- 非阻塞式: lockwise_test.cpp
- 阻塞式: blocking_test.cpp
◆ 测试
-
根据测试用例的要求,修改测试用例文件中的参数,
- 提交周期: 修改 PERIOD 的初始值为 0.5,1 或 3;
- 思考时间: 在用户线程的初始函数中,放开或注释以下内容,
- std::this_thread::yield(),则思考时间为 0;
- std::this_thread::sleep_for(milliseconds(rand()%RAND_LIMIT)),则思考时间为 0 ~ RAND_LIMIT 毫秒随机(须同时修改 RAND_LIMIT 的初始值为 8,32,128 或 1024)。
-
编译测试用例执行文件
- 非阻塞式:
g++ -std=c++11 -lpthread lockwise_test.cpp - 阻塞式:
g++ -std=c++11 -lpthread blocking_test.cpp
- 非阻塞式:
-
执行
./a.out 1>/dev/null
◆ 结果
-
用例 1 的结果
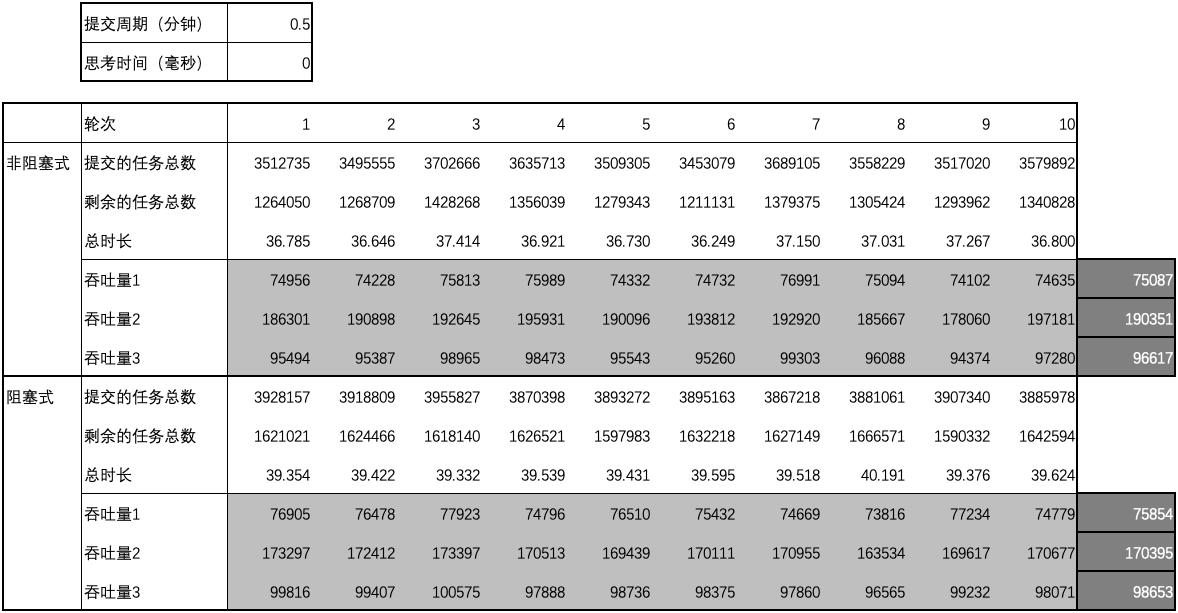
-
用例 2 的结果
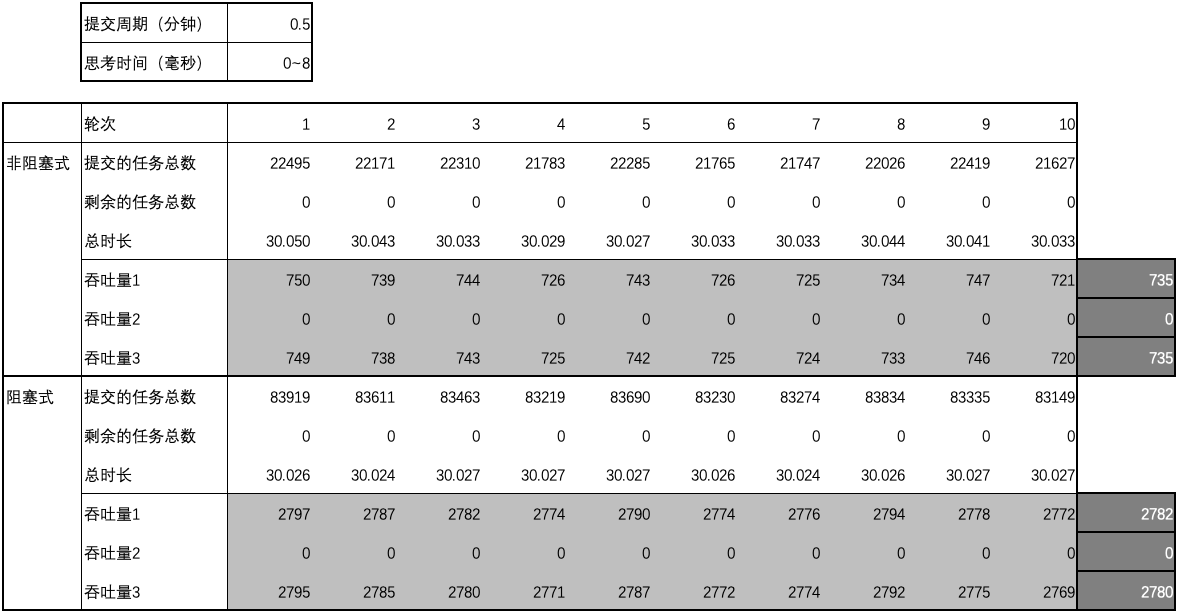
-
用例 3 的结果

-
用例 4 的结果

-
用例 5 的结果

-
用例 6 的结果
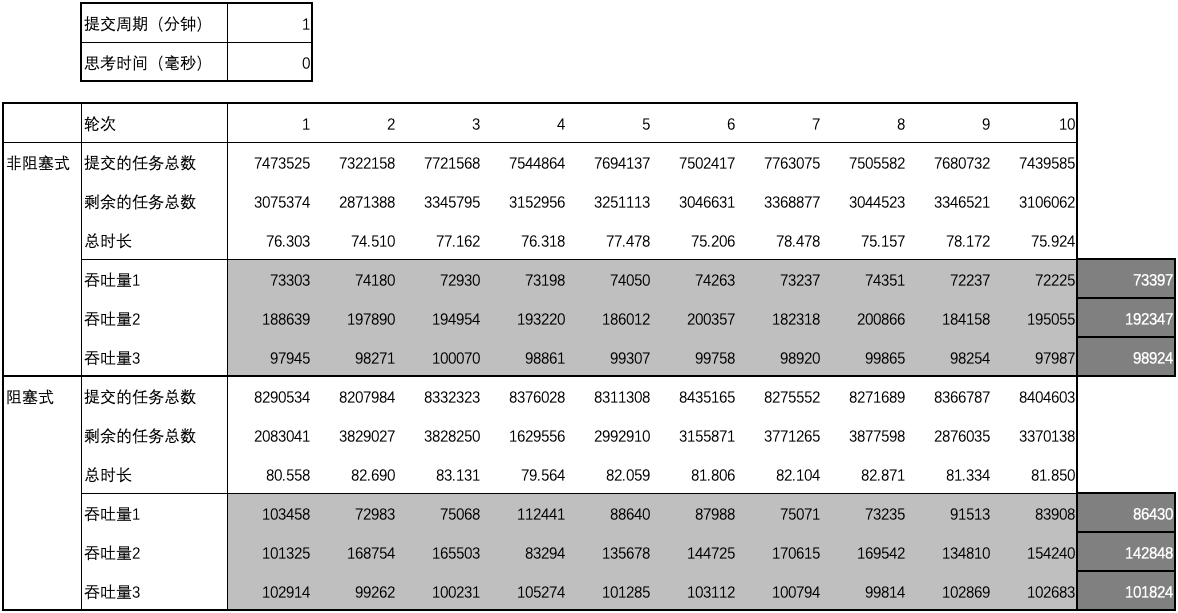
-
用例 7 的结果
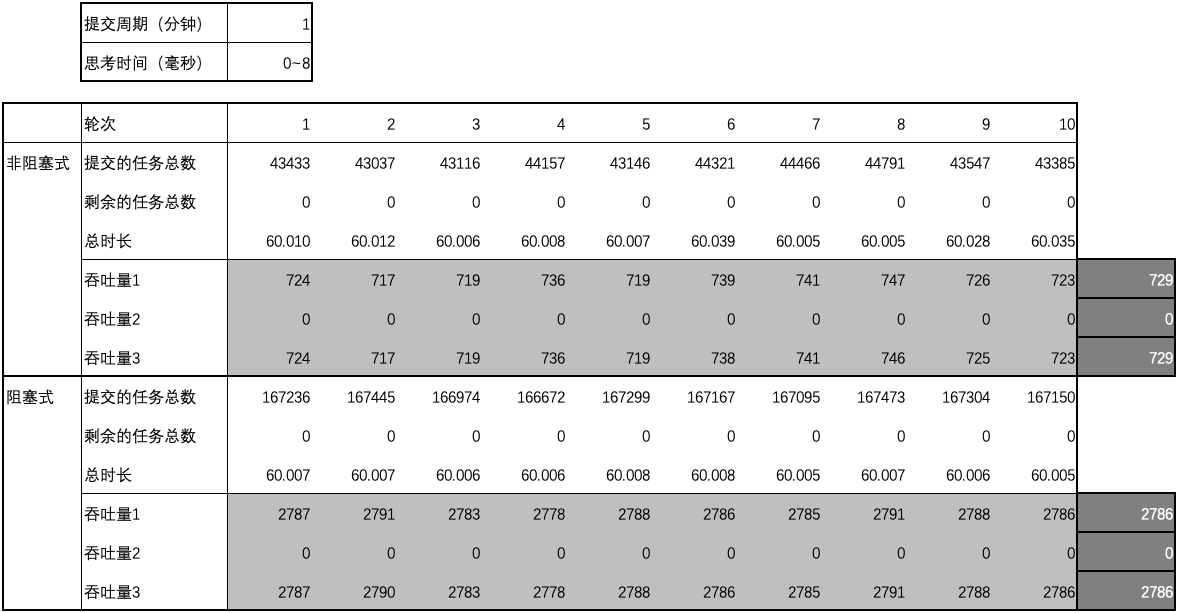
-
用例 8 的结果
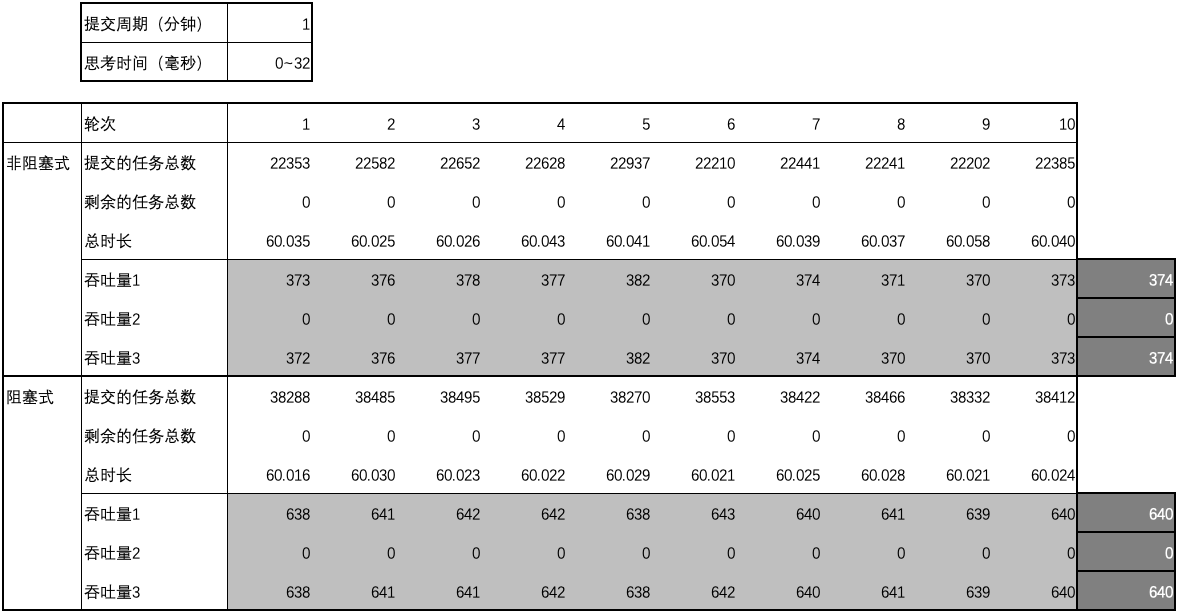
-
用例 9 的结果
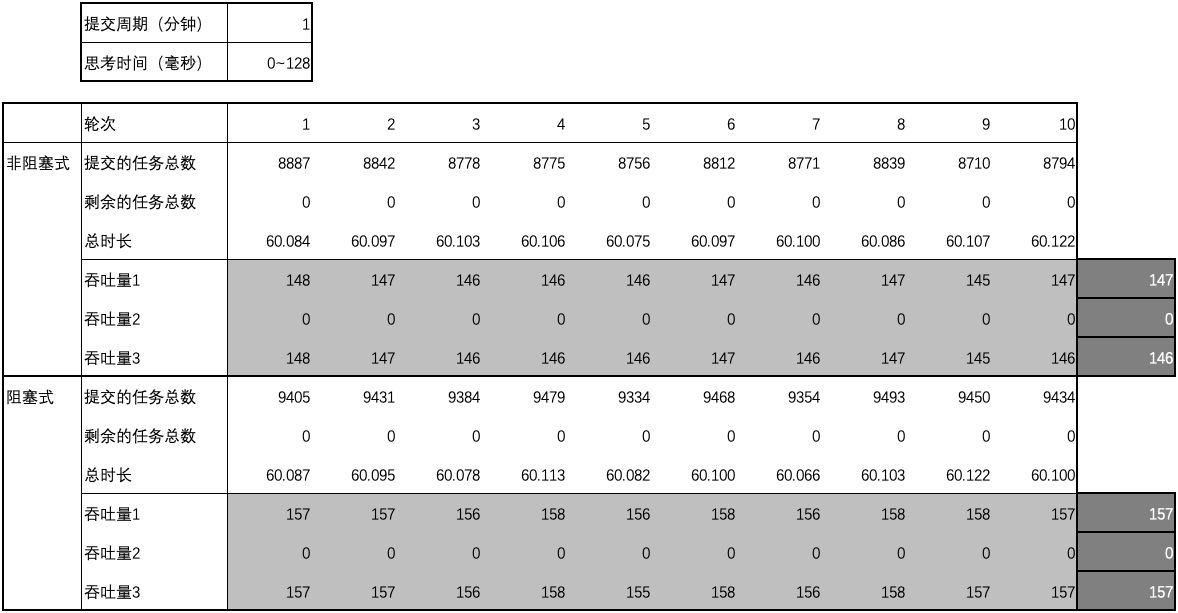
-
用例 10 的结果
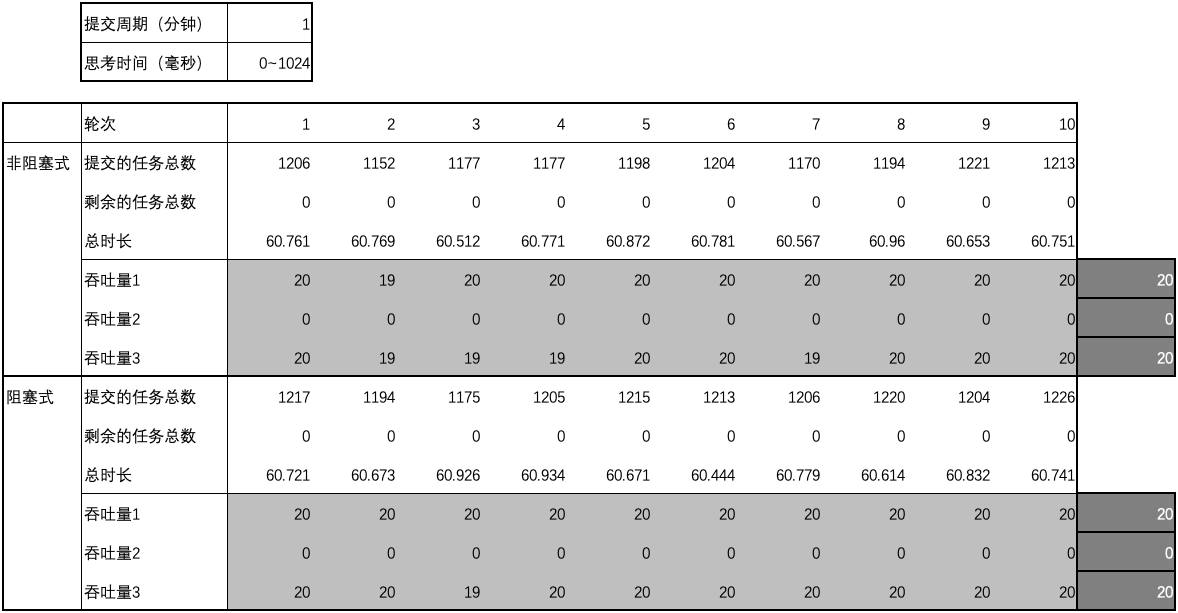
-
用例 11 的结果

程序要求的内存容量超过了操作系统可分配的物理内存,抛出了 std::bad_alloc 异常。 -
用例 12 的结果

-
用例 13 的结果
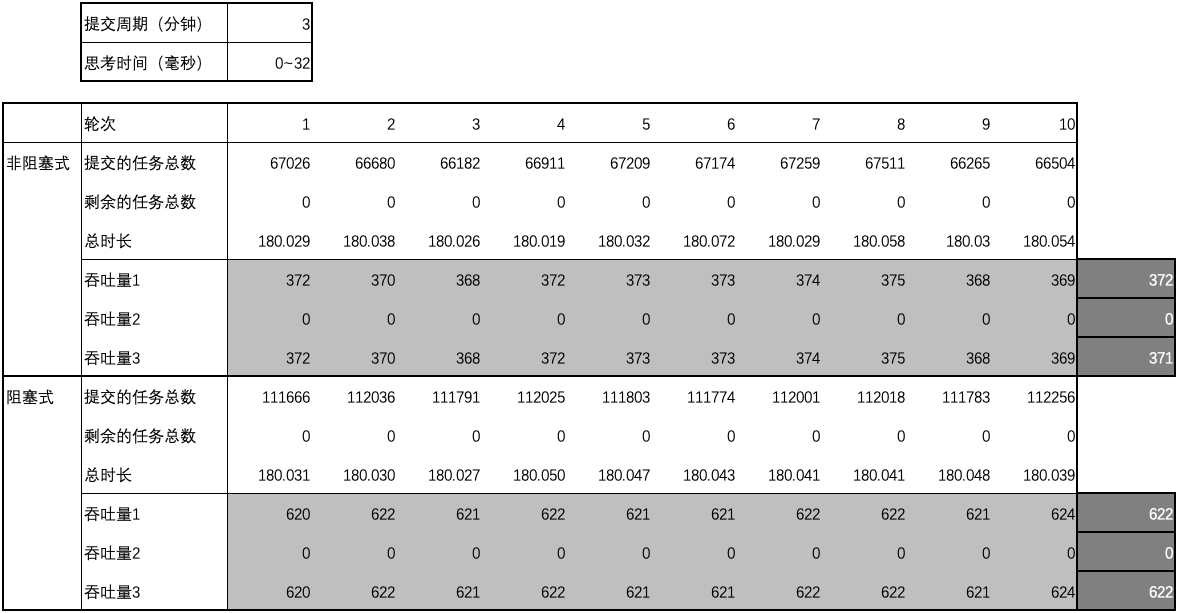
-
用例 14 的结果
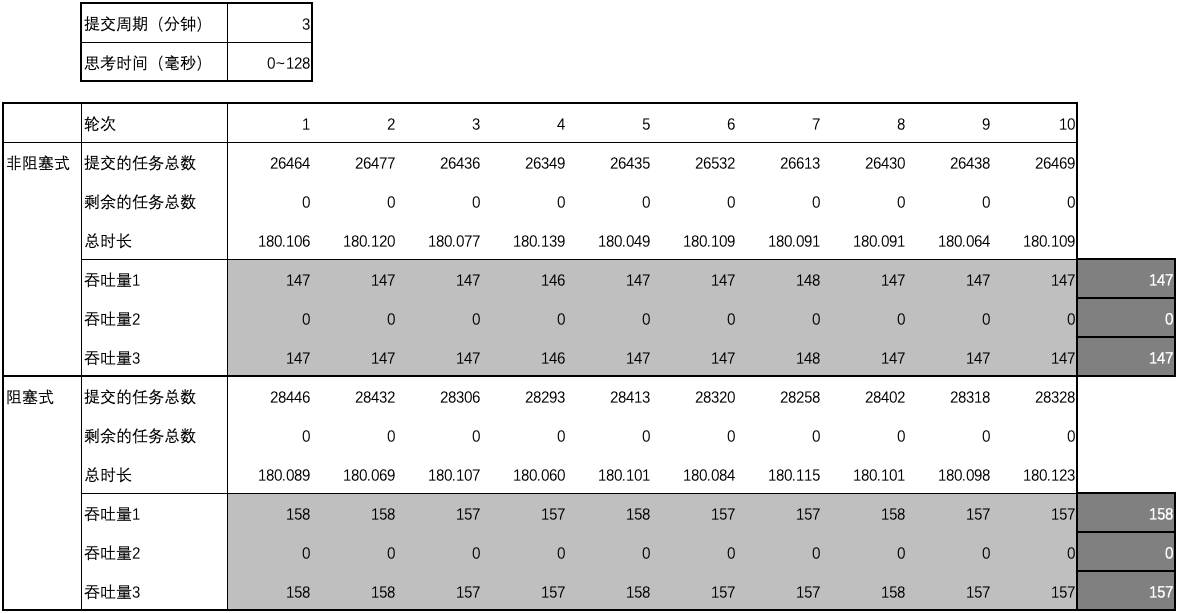
-
用例 15 的结果
◆ 分析
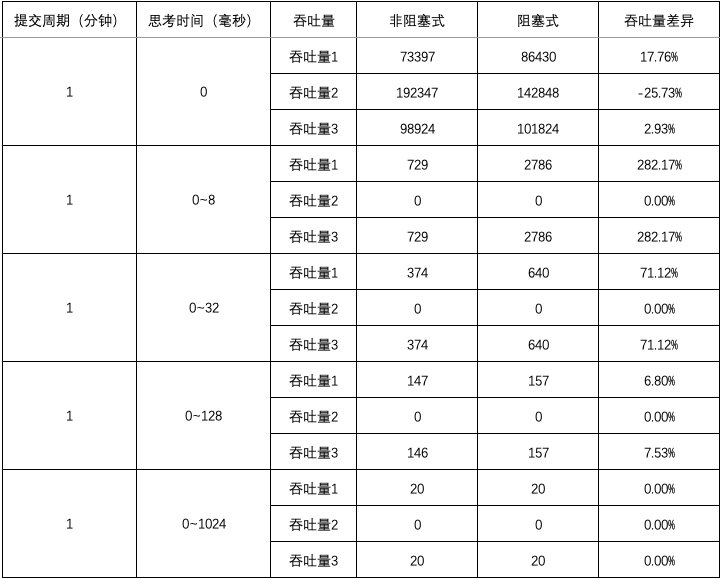
图1 ~ 图3 汇总了测试用例 1 ~ 15 的结果中平均吞吐量数据和差异,
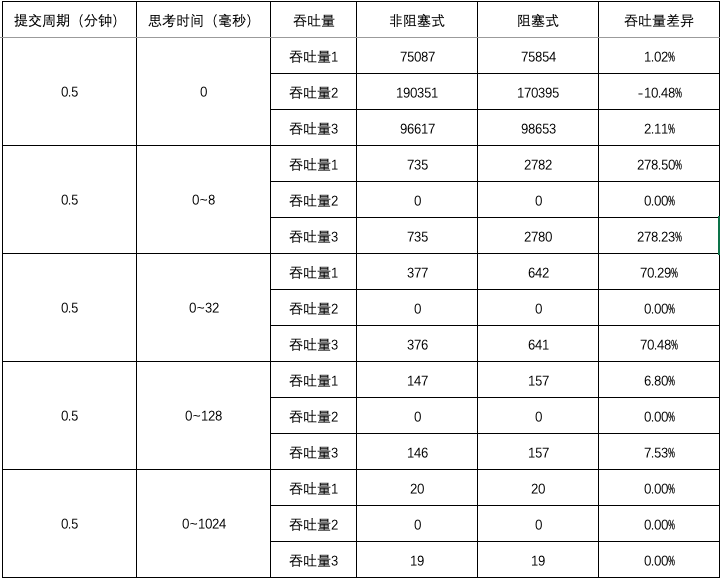
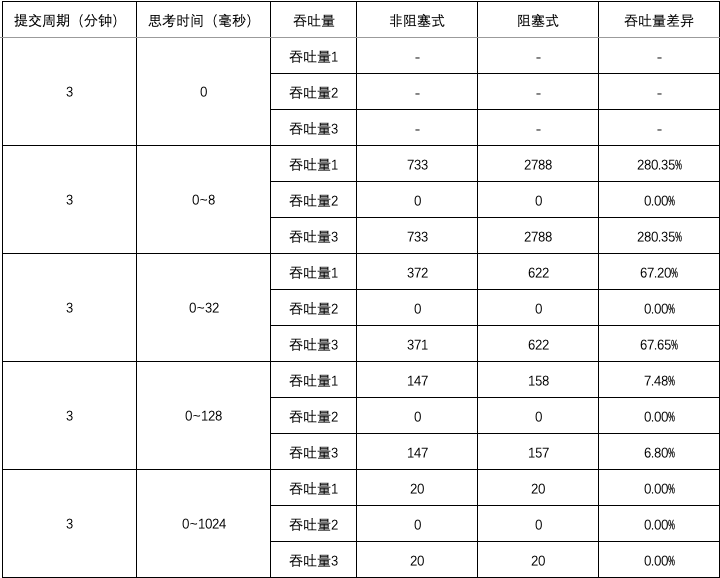

- 当思考时间为 0 时,阻塞式的吞吐量略微优于非阻塞式的吞吐量;延长提交周期后,阻塞式的吞吐量明显优于非阻塞式的吞吐量;
- 当思考时间不为 0 时,阻塞式的吞吐量大幅优于非阻塞式的吞吐量,但差异不会因提交周期的延长而大幅变化;随着思考时间的增加,阻塞式的吞吐量与非阻塞式的吞吐量之间的差异逐渐消失。
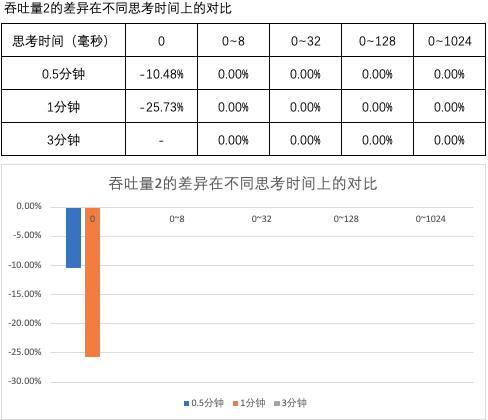
- 当思考时间为 0 时,阻塞式的吞吐量劣于非阻塞式的吞吐量;延长提交周期后,阻塞式的吞吐量明显劣于非阻塞式的吞吐量;
- 当思考时间不为 0 时,因阻塞式的吞吐量和非阻塞式的吞吐量均为 0,它们间没有差异。
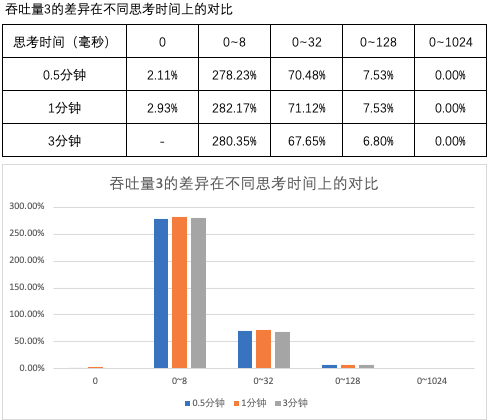
- 当思考时间为 0 时,阻塞式的吞吐量略微优于非阻塞式的吞吐量;延长提交周期后,阻塞式的吞吐量优于非阻塞式的吞吐量;
- 当思考时间不为 0 时,阻塞式的吞吐量大幅优于非阻塞式的吞吐量,但差异不会因提交周期的延长而大幅变化;随着思考时间的增加,阻塞式的吞吐量与非阻塞式的吞吐量之间的差异逐渐消失。
◆ 结论
考虑到现实中的思考时间为 0 的情况相当少见,基于上述的分析,笔者认为,
- 在需要应对高频并发的场合,采用阻塞式线程池的吞吐量指标会优于非阻塞式线程池的吞吐量指标;
- 在需要应对低频并发的场合,采用阻塞式线程池的吞吐量指标相当于非阻塞式线程池的吞吐量指标;
- 在仅为分派并发任务的场合,采用阻塞式线程池的吞吐量指标会劣于非阻塞式线程池的吞吐量指标。
◆ 最后
完整的代码及测试数据请参考 [gitee] cnblogs/15622669 。
写作过程中,笔者参考了《软件性能测试过程详解与案例剖析》一书中的部分概念及思路。致段念。
受限于作者的水平,读者如发现有任何错误或有疑问之处,请追加评论或发邮件联系 green-pi@qq.com。作者将在收到意见后的第一时间里予以回复。 本文来自博客园,作者:green-cnblogs,转载请注明原文链接:https://www.cnblogs.com/green-cnblogs/p/15622669.html 谢谢!

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,携手博客园推出1Panel与Halo联合会员
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步