简单的线程池(二)
笔者在 《简单的线程池(一)》 中采用了非阻塞的(nonblocking)线程同步方式,在此文中笔者将采用阻塞的(blocking)线程同步方式实现相同特性的线程池。
本文中不再赘述与 《简单的线程池(一)》 相同的内容。如有不明之处,请参考该博客。
◆ 实现
以下代码给出了此线程池的实现,(blocking_shared_pool.h)
class Thread_Pool {
private:
struct Task_Wrapper { ...
};
atomic<bool> _done_;
Blocking_Queue<Task_Wrapper> _queue_; // #1
unsigned _workersize_;
thread* _workers_;
void work() {
Task_Wrapper task;
while (!_done_.load(memory_order_acquire)) {
_queue_.pop(task); // #3
task();
}
}
void stop() {
size_t remaining = _queue_.size();
while (!_queue_.empty()) // #2
std::this_thread::yield();
std::fprintf(stderr, "\n%zu tasks remain before destructing pool.\n", remaining);
for (unsigned i = 0; i < _workersize_; ++i) // #5
_queue_.push([] {});
for (unsigned i = 0; i < _workersize_; ++i) {
if (_workers_[i].joinable())
_workers_[i].join(); // #4
}
delete[] _workers_;
}
public:
Thread_Pool() : _done_(false) {
try {
_workersize_ = thread::hardware_concurrency();
_workers_ = new thread[_workersize_];
for (unsigned i = 0; i < _workersize_; ++i) {
_workers_[i] = thread(&Thread_Pool::work, this);
}
} catch (...) {
stop();
throw;
}
}
~Thread_Pool() {
stop();
}
template<class Callable>
future<typename std::result_of<Callable()>::type> submit(Callable c) {
typedef typename std::result_of<Callable()>::type R;
packaged_task<R()> task(c);
future<R> r = task.get_future();
_queue_.push(std::move(task));
return r;
}
};
Task_Wrapper 具体化了线程安全的任务队列 Blocking_Queue<>(#1)。稍后对 Blocking_Queue<> 做说明。
终止线程池时,任务队列中的剩余任务被执行(#2)完后,任务队列处于被清空的状态。在 _done_ 还未被置为 true 之前,工作线程可能会因为 _queue_.pop(task) 而进入循环等待的阻塞状态(#3)。如果此时主线程先调用工作线程的 join() 函数(#4),将导致死锁(deadlock)状态。即,工作线程正在等待有任务入队,而主线程又要等待工作线程的结束。为了打破循环等待条件,在主线程调用工作线程的 join() 函数之前,向队列中放入 _workersize_ 个假任务(#5)。其目的,是确保在任务队列上等待的所有工作线程退出循环等待(#3)。
阻塞式的队列 Blocking_Queue<> 如下,(blocking_queue.h)
template<class T>
class Blocking_Queue {
private:
mutex mutable _m_; // #1
condition_variable _cv_;
queue<T> _q_;
public:
void push(T&& element) {
lock_guard<mutex> lk(_m_);
_q_.push(std::move(element));
_cv_.notify_one(); // #3
}
void pop(T& element) {
unique_lock<mutex> lk(_m_);
_cv_.wait(lk, [this]{ return !_q_.empty(); }); // #2
element = std::move(_q_.front());
_q_.pop();
}
bool empty() const {
lock_guard<mutex> lk(_m_);
return _q_.empty();
}
size_t size() const {
lock_guard<mutex> lk(_m_);
return _q_.size();
}
};
队列采用了 std::mutex 和 std::condition_variable 控制工作线程对任务队列的并发访问(#1)。如果没有可出队的任务,当前线程就会在 _cv_ 上循环等待(#2);任务入队后,由 _cv_ 通知在其上等待的线程(#3)。
◆ 逻辑
以下类图展现了此线程池的代码主要逻辑结构。

[注] 图中用构造型(stereotype)标识出工作线程的初始函数,并在注解中加以说明调用关系。
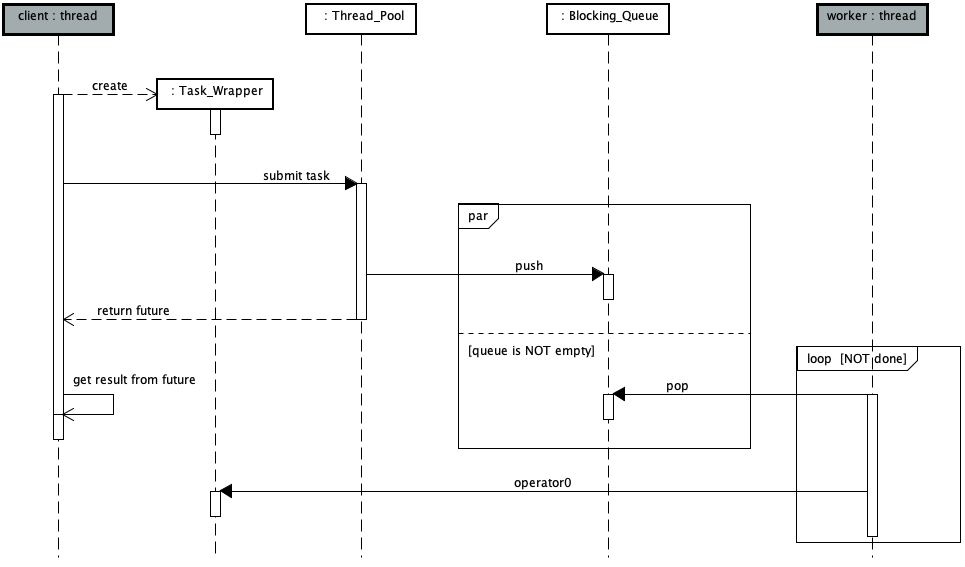
以下顺序图展现了线程池用户提交任务与工作线程执行任务的并发过程。
◆ 验证
验证所使用的的测试用例及结果,与 《简单的线程池(一)》 的保持一致。
◆ 最后
完整的代码请参考 [gitee] cnblogs/15607633 。
写作过程中,笔者参考了《C++并发编程实战》一书中的部分设计思路。致 Anthony Williams、周全等译者。
受限于作者的水平,读者如发现有任何错误或有疑问之处,请追加评论或发邮件联系 green-pi@qq.com。作者将在收到意见后的第一时间里予以回复。 本文来自博客园,作者:green-cnblogs,转载请注明原文链接:https://www.cnblogs.com/green-cnblogs/p/15607633.html 谢谢!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号