Linux学习笔记_Lv
1,linux快捷键
2,shell常用通配符
3,Linux 的目录结构 FHS 标准:
FHS 定义了两层规范,第一层是, / 下面的各个目录应该要放什么文件数据,例如 /etc应该放置设置文件,/bin 与 /sbin 则应该放置可执行文件等等。
第二层则是针对 /usr 及 /var 这两个目录的子目录来定义。例如 /var/log 放置系统日志文件,/usr/share 放置共享数据等等。
使用 cd 命令可以切换目录,在 Linux 里面使用 . 表示当前目录,.. 表示上一级目录(注意,我们上一节介绍过的,以 . 开头的文件都是隐藏文件,所以这两个目录必然也是隐藏的,你可以使用 ls -a 命令查看隐藏文件),
- 表示上一次所在目录,~ 通常表示当前用户的 home 目录。使用 pwd 命令可以获取当前所在路径(绝对路径)
4,zip打包文件夹
zip -r -q -o shiyanlou.zip /home/shiyanlou
设置压缩级别为 9 和 1(9 最大,1 最小),重新打包:
$ zip -r -9 -q -o shiyanlou_9.zip /home/shiyanlou -x ~/*.zip
$ zip -r -1 -q -o shiyanlou_1.zip /home/shiyanlou -x ~/*.zip
用 du 命令分别查看默认压缩级别、最低、最高压缩级别及未压缩的文件的大小:
$ du -h -d 0 *.zip ~ | sort
h, --human-readable(方便人阅读,大小按照M单位)
d, --max-depth(所查看文件的深度,指目录层数)/粘贴
使用安静模式,将文件解压到指定目录:
创建加密 zip 包
使用 -e 参数可以创建加密压缩包:
$ zip -r -e -o shiyanlou_encryption.zip /home/shiyanlou
注意: 关于 zip 命令,因为 Windows 系统与 Linux/Unix 在文本文件格式上的一些兼容问题,比如换行符(为不可见字符),在 Windows 为 CR+LF(Carriage-Return+Line-Feed:回车加换行),
而在 Linux/Unix 上为 LF(换行),所以如果在不加处理的情况下,在 Linux 上编辑的文本,在 Windows 系统上打开可能看起来是没有换行的。如果你想让你在 Linux 创建的 zip 压缩文件在 Windows 上解压后没有任何问题,那么你还需要对命令做一些修改:
$ zip -r -l -o shiyanlou.zip /home/shiyanlou
5,解压zip文件
unzip命令
将 shiyanlou.zip 解压到当前目录:
$ unzip shiyanlou.zip
使用安静模式,将文件解压到指定目录:
$ unzip -q shiyanlou.zip -d ziptest
如果你不想解压只想查看压缩包的内容你可以使用 -l 参数:
$ unzip -l shiyanlou.zip
注意: 使用 unzip 解压文件时我们同样应该注意兼容问题,(中文编码的问题),通常 Windows 系统上面创建的压缩文件,如果有有包含中文的文档或以中文作为文件名的文件时默认会采用 GBK 或其它编码,
而 Linux 上面默认使用的是 UTF-8 编码,如果不加任何处理,直接解压的话可能会出现中文乱码的问题(有时候它会自动帮你处理),为了解决这个问题,我们可以在解压时指定编码类型。
使用 -O(英文字母,大写 o)参数指定编码类型:
unzip -O GBK 中文压缩文件.zip
6,tar 打包
tar 命令一些基本的使用方式,即不进行压缩只是进行打包(创建归档文件)和解包的操作。
创建一个 tar 包:
$ tar -cf shiyanlou.tar ~
上面命令中,-c 表示创建一个 tar 包文件,-f 用于指定创建的文件名,注意文件名必须紧跟在 -f参数之后,比如不能写成 tar -fc shiyanlou.tar,可以写成 tar -f shiyanlou.tar -c ~。
你还可以加上 -v 参数以可视的的方式输出打包的文件。上面会自动去掉表示绝对路径的 /,你也可以使用 -P 保留绝对路径符。
解包一个文件(-x 参数)到指定路径的已存在目录(-C 参数):
$ mkdir tardir $ tar -xf shiyanlou.tar -C tardir
只查看不解包文件 -t 参数:
$ tar -tf shiyanlou.tar
保留文件属性和跟随链接(符号链接或软链接),有时候我们使用 tar 备份文件当你在其他主机还原时希望保留文件的属性(-p 参数)和备份链接指向的源文件而不是链接本身(-h 参数):
$ tar -cphf etc.tar /etc
对于创建不同的压缩格式的文件,对于 tar 来说是相当简单的,需要的只是换一个参数,这里我们就以使用 gzip 工具创建 *.tar.gz 文件为例来说明。
我们只需要在创建 tar 文件的基础上添加 -z 参数,使用 gzip 来压缩文件:
$ tar -czf shiyanlou.tar.gz ~
解压 *.tar.gz 文件:
$ tar -xzf shiyanlou.tar.gz
注意,常用命令
- zip:
- 打包 :zip something.zip something (目录请加 -r 参数)
- 解包:unzip something.zip
- 指定路径:-d 参数
- tar:
- 打包:tar -zcvf something.tar something
- 解包:tar -zxvf something.tar
- 指定路径:-C 参数
7,磁盘管理
df 命令查看磁盘的容量 $ df
使用 du 命令查看目录的容量
这个命令前面其实已经用了很多次了:
# 默认同样以 blocks 的大小展示
$ du
# 加上`-h`参数,以更易读的方式展示
$ du -h
-d参数指定查看目录的深度
# 只查看1级目录的信息
$ du -h -d 0 ~
# 查看2级
$ du -h -d 1 ~
常用参数
du -h #同--human-readable 以K,M,G为单位,提高信息的可读性。
du -a #同--all 显示目录中所有文件的大小。
du -s #同--summarize 仅显示总计,只列出最后加总的值。
8,linux下的帮助命令
我们可以使用 type 命令来区分命令是内建的还是外部的
(1)#得到这样的结果说明是内建命令,正如上文所说内建命令都是在 bash 源码中的 builtins 的.def中
xxx is a shell builtin
(2)#得到这样的结果说明是外部命令,正如上文所说,外部命令在/usr/bin or /usr/sbin等等中
xxx is /usr/sbin/xxx
(3)#若是得到alias的结果,说明该指令为命令别名所设定的名称;
xxx is an alias for xx --xxx
help
help 命令是用于显示 shell 内建命令的简要帮助信息。帮助信息中显示有该命令的简要说明以及一些参数的使用以及说明,
一定记住 help 命令只能用于显示内建命令的帮助信息,不然就会得到你刚刚得到的结果。 exit,cd 便是内建命令,可以
显示详细信息,而ls非内建命令,无法显示。
若是外部命令使用:ls --help
其他信息: man info
9,linux备份日志
题目
小明是一个服务器管理员,他需要每天备份论坛数据(这里我们用日志替代),备份当天的日志并删除之前的日志。而且备份之后文件名是年-月-日的格式。alternatives.log在/var/log/下面。
目标
1. 为shiyanlou用户添加计划任务
2. 每天凌晨3点的时候定时备份alternatives.log到/home/shiyanlou/tmp/目录
3. 命名格式为年-月-日,比如今天是2017年4月1日,那么文件名为2017-04-01
解答步骤:
1. 启动日志服务器 $ sudo service rsyslog start
2. 启动crontab服务 $ sudo cron -f &
3. 进入crontab文件 $ crontab -e
选择vim编辑器 “1”或者“2”
最后一行添加任务并保存: 0 3 * * * cp /var/log/alternatives.log /home/shiyanlou/tmp/$(date+ \%Y\%m\%d)
4, 启动cron 的守护进程 1,ps aux | grep cron 2, pgrep cron
任务添加解析:
① crontab时间格式内容
* * * * * command
M H D m d command
第1列表示分钟1~59 每分钟用*或者 */1表示
第2列表示小时1~23(0表示0点)
第3列表示日期1~31
第4列表示月份1~12
第5列标识号星期0~6(0表示星期天)
第6列要运行的命令或脚本内容
② 举例:关于crontab文件中时间定义,crontab文件的注释写的很清楚
# For example, you can run a backup of all your user accounts
# at 5 a.m. every week with:
# 0 5 * * 1 tar -zcf /var/backups/home.tgz /home/
#
# For more information see the manual pages of crontab(5) and cron(8)
#
# m h dom(day of month) mon(month) dow(day of week) command
10,命令顺序执行控制
有选择的执行命令
$ which cowsay>/dev/null && cowsay -f head-in ohch~
上面的&&就是用来实现选择性执行的,它表示如果前面的命令执行结果(不是表示终端输出的内容,而是表示命令执行状态的结果)返回0则执行后面的,
否则不执行,你可以从$?环境变量获取上一次命令的返回结果:
$ which cowsay>/dev/null || echo "cowsay has not been install, please run 'sudo apt-get install cowsay' to install"
||在这里就是与&&相反的控制效果,当上一条命令执行结果为≠0($?≠0)时则执行它后面的命令:
我们还可以结合着&&和||来实现一些操作,比如:
$ which cowsay>/dev/null && echo "exist" || echo "not exist"
流程示意图:

11,管道
管道是一种通信机制,通常用于进程间的通信(也可通过socket进行网络通信),它表现出来的形式就是将前面每一个进程的输出(stdout)直接作为下一个进程的输入(stdin)。
管道又分为匿名管道和具名管道。我们在使用一些过滤程序时经常会用到的就是匿名管道,在命令行中由|分隔符表示。
具名管道简单的说就是有名字的管道,通常只会在源程序中用到具名管道。
查看/etc目录下有哪些文件和目录,使用ls命令来查看:
$ ls -al /etc
有太多内容,屏幕不能完全显示,这时候可以使用滚动条或快捷键滚动窗口来查看。不过这时候可以使用管道:
$ ls -al /etc | less
通过管道将前一个命令(ls)的输出作为下一个命令(less)的输入,然后就可以一行一行地看。
cut命令,打印每一行的某一字段
打印/etc/passwd文件中以:为分隔符的第1个字段和第6个字段分别表示用户名和其家目录:
$ cut /etc/passwd -d ':' -f 1,6
打印/etc/passwd文件中每一行的前N个字符:
# 前五个(包含第五个)
$ cut /etc/passwd -c -5
# 前五个之后的(包含第五个)
$ cut /etc/passwd -c 5-
# 第五个
$ cut /etc/passwd -c 5
# 2到5之间的(包含第五个)
$ cut /etc/passwd -c 2-5
wc命令: 计数工具
wc 命令用于统计并输出一个文件中行、单词和字节的数目,比如输出/etc/passwd文件的统计信息:
$ wc /etc/passwd
分别只输出行数、单词数、字节数、字符数和输入文本中最长一行的字节数:
# 行数 $ wc -l /etc/passwd
# 单词数 $ wc -w /etc/passwd
# 字节数 $ wc -c /etc/passwd
# 字符数 $ wc -m /etc/passwd
# 最长行字节数 $ wc -L /etc/passwd
统计 /etc 下面所有目录数:
$ ls -dl /etc/*/ | wc -l
sort排序命令
支持的排序有按字典排序,数字排序,按月份排序,随机排序,反转排序,指定特定字段进行排序等等。
默认为字典排序:
$ cat /etc/passswd | sort
反转排序:
$ cat /etc/passwd | sort -r
按特定字段排序:
$ cat /etc/passwd | sort -t':' -k 3
上面的-t参数用于指定字段的分隔符,这里是以":"作为分隔符;-k 字段号用于指定对哪一个字段进行排序。
这里/etc/passwd文件的第三个字段为数字,默认情况下是uniq命令可以用于过滤或者输出重复行。以字典序排序的,如果要按照数字排序就要加上-n参数:
$ cat /etc/passwd | sort -t':' -k 3 -n
uniq去重命令
uniq命令可以用于过滤或者输出重复行。
(1)过滤重复行
使用history命令查看最近执行过的命令(实际为读取${SHELL}_history文件,如我们环境中的~/.zsh_history文件),
只查看使用了哪个命令而不需要知道具体干了什么,去掉命令后面的参数,去掉重复的命令:
$ history | cut -c 8- | cut -d ' ' -f 1 | uniq
经过层层过滤,你会发现确是只输出了执行的命令那一列,不过去重效果好像不明显,之所以不明显是因为uniq命令只能去连续重复的行,不是全文去重,所以要达到预期效果,我们先排序:
$ history | cut -c 8- | cut -d ' ' -f 1 | sort | uniq # 或者$ history | cut -c 8- | cut -d ' ' -f 1 | sort -u
(2)输出重复行
# 输出重复过的行(重复的只输出一个)及重复次数
$ history | cut -c 8- | cut -d ' ' -f 1 | sort | uniq -dc
# 输出所有重复的行
$ history | cut -c 8- | cut -d ' ' -f 1 | sort | uniq -D
12,简单的文本处理
tr命令 : tr 命令可以用来删除一段文本信息中的某些文字。或者将其进行转换。
-d : 删除和set1匹配的字符,注意不是全词匹配也不是按字符顺序匹配
-s : 去除set1指定的在输入文本中连续并重复的字符
举例:
删除 "hello shiyanlou" 中所有的'o','l','h'
$ echo 'hello shiyanlou' | tr -d 'olh'
# 将"hello" 中的ll,去重为一个l
$ echo 'hello' | tr -s 'l'
# 将输入文本,全部转换为大写或小写输出
$ echo 'input some text here' | tr ''[a-z]' '[A-Z]''
col 命令:可以将Tab换成对等数量的空格键,或反转这个操作。
-x : 将Tab转换为空格
-h : 将空格转换为Tab
流重定向
join命令:将两个文件中包含相同内容的那一行合并在一起。
-t :指定分隔符,默认为空格
-i :忽略大写的差异
-1 :指明第一个文件要用哪个字段来对比,默认对比第一个字段
-2 :指明第二个文件要用哪个字段来对比,默认对比第一个字段
举例:
# 创建两个文件
$ echo '1 hello' > file1 $ echo '1 shiyanlou' > file2
$ join file1 file2 # 将/etc/passwd与/etc/shadow
两个文件合并,指定以':'作为分隔符
$ sudo join -t':' /etc/passwd /etc/shadow
# 将/etc/passwd与/etc/group两个文件合并,指定以':'作为分隔符, 分别比对第4和第3个字段
$ sudo join -t':' -1 4 /etc/passwd -2 3 /etc/group
paste命令:这个命令与join 命令类似,它是在不对比数据的情况下,简单地将多个文件合并一起,以Tab隔开。
-d :指定合并的分隔符,默认为Tab
-s :不合并到一行,每个文件为一行
举例:
$ echo hello > file1
$ echo shiyanlou > file2
$ echo www.shiyanlou.com > file3
$ paste -d ':' file1 file2 file3
$ paste -s file1 file2 file3 或者 paste -s file*
13,数据流重定向
重定向概念:>或>>操作,他们分别是将标准输出导向一个文件或追加到一个文件中。这其实就是重定向。
将原本输出到标准输出的数据重定向到一个文件中,因为标准输出(/dev/stdout)本身也是一个文件,
我们将命令输出导向另一个文件自然也是没有任何问题的。
重定向举例: >表示是从左到右,<右到左
$ echo 'hello shiyanlou' > redirect
$ echo 'www.shiyanlou.com' >> redirect
$ cat redirect
管道默认是连接前一个命令的输出到下一个命令的输入,而重定向通常是需要一个文件来建立两个命令的连接。
tee命令:同时重定向到多个文件
举例:重定向到文件并打印到终端
$ echo 'hello shiyanlou' | tee hello
exec命令:永久重定向 使用exec命令实现“永久”重定向。
exec命令的作用是使用指定的命令替换当前的 Shell,即使用一个进程替换当前进程,或者指定新的重定向:
举例:
# 先开启一个子 Shell $ zsh # 使用exec替换当前进程的重定向,将标准输出重定向到一个文件
$ exec 1>somefile
# 后面你执行的命令的输出都将被重定向到文件中,直到你退出当前子shell,或取消exec的重定向(后面将告诉你怎么做)
$ ls $ exit $ cat somefile(即此操作将ls命令的结果输出到文件中)
创建输出文件描述符
查看当前shell进程中打开的文件描述符,使用exec命令可以创建新的文件描述符号
$ cd /dev/fd/;ls -Al
关闭文件描述符
$ exec 3>&-
$ cd /dev/fd;ls -Al;cd -
/dev/null:完全屏蔽命令的输出
/dev/null,或称空设备,是一个特殊的设备文件,它通常被用于丢弃不需要的输出流,或作为用于输入流的空文件,
这些操作通常由重定向完成。读取它则会立即得到一个EOF
xargs:分隔参数列表
UNIX 和类 UNIX 操作系统的常用命令。将参数列表转换成小块分段传递给其他命令,以避免参数列表过长的问题。
$ cut -d: -f1 < /etc/passwd | sort | xargs echo正则表达式
上面这个命令用于将/etc/passwd文件按:分割取第一个字段排序后,使用echo命令生成一个列表。
总结:
错误指令修改:
while read filename; do
rm -iv $filename
done < <(ls)
从外观上看,这是想把 ls 命令的输出也就是当前目录的文件列表逐行读取出来,然后使用 rm -iv 在获得你许可的情况下,优雅地删除他们。运行这个程序后会发现,虽然 rm 命令显示了询问是否删除的信息,但是 rm 完全没有关心你的回答。并且整个程序也没有删除一个文件。
答案是 rm -iv 偷了 read 的数据!因为 rm -iv 期待用户从标准输入给出一个 y 或 n 的答案以确认是否删除,但标准输入被 < <(ls) 重定向了。于是 rm -iv 开始在 < <(ls) 里寻找答案。如果找不到 y 或者 n 就一直寻找下去,直到把 < <(ls) 的内容消耗完。这时在下一轮的循环中由于数据没有了, read 读不出数据,程序也就退出了。
修改方法:我们先把标准输入复制一份出来,然后让 rm -iv 使用复制出来的标准输入。再把原来的标准输入重定向给
< <(ls) 。修改后的程序:
exec 3<&0
while read filename; do
rm -iv $filename <&3
done < <(ls)
练习:
在一个记录命令的文件中,从里面找出出现频率次数前3的命令并保存在/home/shiyanlou/result。
目标
将结果写入result,结果包含次数和命令,如“100 ls”
答案:
cat data1|cut -c 8-|sort|uniq -dc|sort -k 1 -n -r|head -3 > /home/shiyanlou/result
解析:
1,文件第8位开始为命令,用cut截取含8位及以后命令
2,第一次使用sort将重复命令连续排列,及所有重复命令排在一起
3,uniq -dc 输出重复行及次数,格式为: 次数 + 命令
4,第二次使用sort -k 1对第一个字段进行排序,-n对数字进行排序,-r反转排序即倒序
14,正则表达式(掌握基本命令:sed ,grep ,awk的用法)被称为模式:pattern
概念:正则表达式(Regular Expression,在代码中常简写为 regex、regexp 或 RE)正则表达式使用单个字符串来描述、匹配一系列符合某个句法规则的字符串。
在很多文本编辑器里,正则表达式通常被用来检索、替换那些符合某个模式的文本。许多程序设计语言都支持利用正则表达式进行字符串操作。
例如,在 Perl 中就内建了一个功能强大的正则表达式引擎。正则表达式通常缩写成“regex”,单数有 regexp、regex,复数有 regexps、regexes、regexen。
用来描述或者匹配一系列符合某个句法规则的字符串。
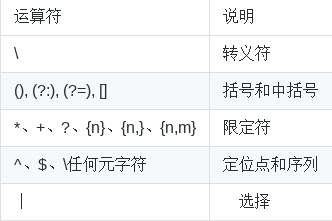
(1)数量限定( 如果在一个模式中不加数量限定符则表示出现一次且仅出现一次)
+ 表示前面的字符必须出现至少一次(1次或多次),例如,"goo+gle",可以匹配"gooogle","goooogle"等;
? 表示前面的字符最多出现一次(0次或1次),例如,"colou?r",可以匹配"color"或者"colour";
* 星号代表前面的字符可以不出现,也可以出现一次或者多次(0次、或1次、或多次),例如,“0*42”可以匹配42、042、0042、00042等。
(2)范围和优先级
()圆括号可以用来定义模式字符串的范围和优先级,这可以简单的理解为是否将括号内的模式串作为一个整体。
例如,"gr(a|e)y"等价于"gray|grey",(这里体现了优先级,竖直分隔符用于选择a或者e而不是gra和ey),
"(grand)?father"匹配father和grandfather(这里体验了范围,?将圆括号内容作为一个整体匹配)。
(3)语法(部分)

优先级为从上到下从左到右,依次降低:
grep模式匹配命令:grep命令用于打印输出文本中匹配的模式串,它使用正则表达式作为模式匹配的条件。grep支持三种正则表达式引擎,分别用三个参数指定:

基本正则表达式:BRE扩展正则表达式,ERE
(1)位置
查找/etc/group文件中以"shiyanlou"为开头的行
$ grep 'shiyanlou' /etc/group $ grep '^shiyanlou' /etc/group
(2)数量
# 将匹配以'z'开头以'o'结尾的所有字符串
$ echo 'zero\nzo\nzoo' | grep 'z.*o'
# 将匹配以'z'开头以'o'结尾,中间包含一个任意字符的字符串
$ echo 'zero\nzo\nzoo' | grep 'z.o'
# 将匹配以'z'开头,以任意多个'o'结尾的字符串
$ echo 'zero\nzo\nzoo' | grep 'zo*'
注意:其中\n为换行符
(3)选择
# grep默认是区分大小写的,这里将匹配所有的小写字母
$ echo '1234\nabcd' | grep '[a-z]'
# 将匹配所有的数字
$ echo '1234\nabcd' | grep '[0-9]'
# 将匹配所有的数字
$ echo '1234\nabcd' | grep '[[:digit:]]'
# 将匹配所有的小写字母
$ echo '1234\nabcd' | grep '[[:lower:]]'
# 将匹配所有的大写字母
$ echo '1234\nabcd' | grep '[[:upper:]]'
# 将匹配所有的字母和数字,包括0-9,a-z,A-Z
$ echo '1234\nabcd' | grep '[[:alnum:]]'
# 将匹配所有的字母
$ echo '1234\nabcd' | grep '[[:alpha:]]'
(4)特殊符号及说明
select me
# 排除字符
$ echo 'geek\ngood' | grep '[^o]'
注意:当^放到中括号内为排除字符,否则表示行首。
扩展正则表达式:ERE
要通过grep使用扩展正则表达式需要加上-E参数,或使用egrep。
(1)数量
# 只匹配"zo"
$ echo 'zero\nzo\nzoo' | grep -E 'zo{1}'
# 匹配以"zo"开头的所有单词
$ echo 'zero\nzo\nzoo' | grep -E 'zo{1,}'
(2)grep -E 匹配包含
grep -Ev 匹配不包含
注意:因为.号有特殊含义,所以需要转义。(\ .)
sed流编辑器:sed工具在 man 手册里面的全名为"sed - stream editor for filtering and transforming text ",用于过滤和转换文本的流编辑器。它是一个非交互式的编辑器
sed 命令基本格式:
sed [参数]... [执行命令] [输入文件]... # 形如:
$ sed -i '1s/sad/happy/' test
# 表示将test文件中第一行的"sad"替换为"happy"
参数:
-n : 安静模式,只打印受影响的行,默认打印输入数据的全部内容
-e : 用于在脚本中添加多个执行命令一次执行,在命令行中多个命令通常不需要加该参数
-f filename : 指定执行filename文件中的命令
-r :使用扩展正则表达式,默认为标准正则表达式
-i : 将直接修改输入文件内容,而不是打印到标准输出设备
sed执行命令格式:
[n1][,n2]command [n1][~step]command # 其中一些命令可以在后面加上作用范围,形如:
$ sed -i 's/sad/happy/g' test # g表示全局范围
$ sed -i 's/sad/happy/4' test # 4表示指定行中的第四个匹配字符串
其中n1,n2表示输入内容的行号,它们之间为,逗号则表示从n1到n2行,如果为~波浪号则表示从n1开始以step为步进的所有行;command为执行动作,下面为一些常用动作指令:
s :行内替换
c :整行替换
a :插入到指定行的后面
i :插入到指定行的前面
p :打印指定行,通常与-n参数配合使用
d :删除指定行
打印指定行
# 打印2-5行
$ nl passwd | sed -n '2,5p'
# 打印奇数行
$ nl passwd | sed -n '1~2p'
(passwd为测试文件,p为动作指令)
行内替换
# 将输入文本中"shiyanlou" 全局替换为"hehe",并只打印替换的那一行,注意这里不能省略最后的"p"命令
$ sed -n 's/shiyanlou/hehe/gp' passwd
每个字段排列显示
行间替换
$ nl passwd | grep "shiyanlou"
# 删除第21行
$ sed -n '21c\www.shiyanlou.com' passwd
(这里只把要删的行打印出来了,并没有真正的删除,如果要删除的话,请使用-i参数)
awk文本处理语言:AWK是一种用于处理文本的编程语言工具。Linux及Unix环境中现有的功能最强大的数据处理引擎之一,它允许创建简短的程序,
这些程序读取输入文件、为数据排序、处理数据、对输入执行计算以及生成报表,还有无数其他的功能。
awk所有的操作都是基于pattern(模式)—action(动作)对来完成的,如下面的形式:
$ pattern {action}
其中pattern通常是表示用于匹配输入的文本的“关系式”或“正则表达式”,action则是表示匹配后将执行的动作。在一个完整awk操作中,这两者可以只有其中一个,
如果没有pattern则默认匹配输入的全部文本,如果没有action则默认为打印匹配内容到屏幕。
awk处理文本的方式,是将文本分割成一些“字段”,然后再对这些字段进行处理,默认情况下,awk以空格作为一个字段的分割符。
awk命令基本格式:
awk [-F fs] [-v var=value] [-f prog-file | 'program text'] [file...]
其中-F参数用于预先指定前面提到的字段分隔符(还有其他指定字段的方式) ,-v用于预先为awk程序指定变量,
-f参数用于指定awk命令要执行的程序文件,或者在不加-f参数的情况下直接将程序语句放在这里,最后为awk需要处理的文本输入,且可以同时输入多个文本文件。
awk实例:
$ vim test包含如下内容:
I like linux www.shiyanlou.com
(1)将test的第一行的每个字段单独显示为一行

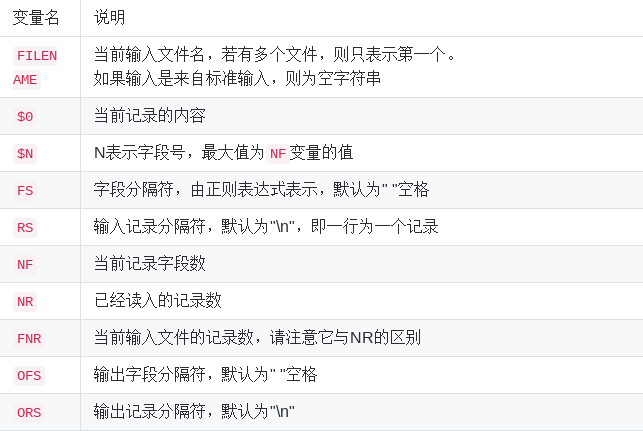
解析 :NR与OFS,这两个是awk内建的变量,NR表示当前读入的记录数,可以简单的理解为当前处理的行数,OFS表示输出时的字段分隔符,默认为" "空格,
如上图所见,我们将字段分隔符设置为\n换行符,所以第一行原本以空格为字段分隔的内容就分别输出到单独一行了。然后是$N其中N为相应的字段号,
也是awk的内建变量,表示引用相应的字段,因为第一行只有三个字段,所以只引用到了$3。除此之外另一个这里没有出现的$0,它表示引用当前记录(当前行)的全部内容。
(2)将test的第二行的以点为分段的字段换成以空格为分隔

解析:这里的-F参数,是用来预先指定待处理记录的字段分隔符。除了指定OFS我们还可以在print 语句中直接打印特殊符号如这里的\t,print打印的非变量内容都需要用""一对引号包围起来。
另一个版本,展示了实现预先指定变量分隔符的另一种方式,即使用BEGIN,就这个表达式指示了,其后的动作将在所有动作之前执行,这里是FS赋值了新的"."点号代替默认的" "空格
awk常用内置变量:
挑战:数据提取
题目:
1,在文件data中匹配数字开头的行,结果写入/home/shiyanlou/num文件
2,在文件data中匹配出正确格式的邮箱,结果写入一个名为/home/shiyanlou/mail的文件
答案:
1,grep '^[0-9]' data2 > /home/shiyanlou/num
2,grep -E '@{1}' data2 > /home/shiyanlou/mail
15,Linux下软件安装
Linux 上的软件安装主要有四种方式:
- 在线安装
- 从磁盘安装deb软件包
- 从二进制软件包安装
- 从源代码编译安装
apt-get 是用于处理 apt包的公用程序集,我们可以用它来在线安装、卸载和升级软件包等
apt-get install 软件

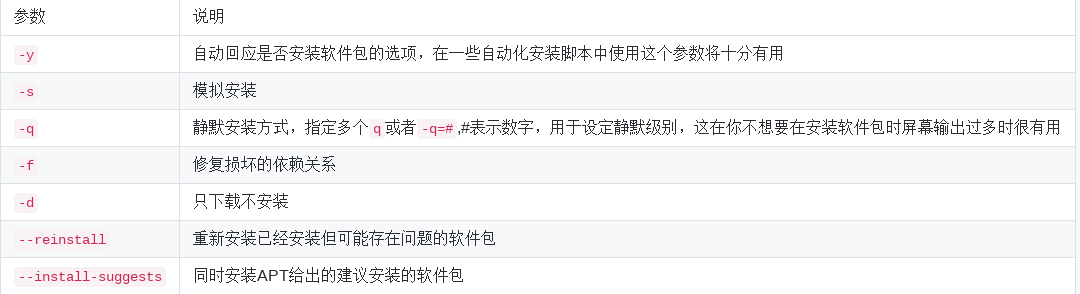
重新安装:
$ sudo apt-get --reinstall install w3m
软件升级:
# 更新软件源
$ sudo apt-get update
# 升级没有依赖问题的软件包
$ sudo apt-get upgrade
# 升级并解决依赖关系
$ sudo apt-get dist-upgrade
卸载软件:
sudo apt-get remove w3m
# 不保留配置文件的移除
$ sudo apt-get purge w3m
# 或者
sudo apt-get --purge remove
# 移除不再需要的被依赖的软件包
$ sudo apt-get autoremove
软件搜索:
sudo apt-cache search softname1 softname2 softname3……
dpkg:使用 dpkg 从本地磁盘安装 deb 软件包(底层工具)
常用参数:

使用dpkg安装
$ sudo dpkg -i emacs24_24.3+1-2ubuntu1_amd64.deb
查看已安装目录:
使用dpkg -L查看deb包目录信息
$ sudo dpkg -L emacs24
从二进制包安装:将从网络上下载的二进制包解压后放到合适的目录,然后将包含可执行的主程序文件的目录添加进PATH环境变量即可
16,Linux进程概念
程序和进程:程序是为了完成某种任务而设计的软件,进程就是运行中的程序。
程序只是一些列指令的集合,是一个静止的实体,而进程不同,进程有以下的特性:
- 动态性:进程的实质是一次程序执行的过程,有创建、撤销等状态的变化。而程序是一个静态的实体。
- 并发性:进程可以做到在一个时间段内,有多个程序在运行中。程序只是静态的实体,所以不存在并发性。
- 独立性:进程可以独立分配资源,独立接受调度,独立地运行。
- 异步性:进程以不可预知的速度向前推进。
- 结构性:进程拥有代码段、数据段、PCB(进程控制块,进程存在的唯一标志)。也正是因为有结构性,进程才可以做到独立地运行。
并发与并行:并发:在一个时间段内,宏观来看有多个程序都在活动,有条不紊的执行(每一瞬间只有一个在执行,只是在一段时间有多个程序都执行过)
并行:在每一个瞬间,都有多个程序都在同时执行,这个必须有多个 CPU 才行
线程(thread)是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。
一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。因为线程中几乎不包含系统资源,所以执行更快、更有效率。
一个程序至少有一个进程,一个进程至少有一个线程。线程的划分尺度小于进程,使得多线程程序的并发性高。另外,进程在执行过程中拥有独立的内存单元,而多个线程共享内存,从而极大地提高了程序的运行效率。
进程的分类:以进程的功能与服务对象:用户进程:通过执行用户程序、应用程序或称之为内核之外的系统程序而产生的进程,此类进程可以在用户的控制下运行或关闭。
系统进程:通过执行系统内核程序而产生的进程,如可以执行内存资源分配和进程切换等相对底层的工作;且该进程的运行不受用户的干预,包括root用户
以应用程序的服务类型: 交互进程 :由一个 shell 终端启动的进程,在执行过程中,需要与用户进行交互操作,可以运行于前台,也可以运行在后台。
批处理进程:该进程是一个进程集合,负责按顺序启动其他的进程。
守护进程 :守护进程是一直运行的一种进程,在 Linux 系统启动时启动,在系统关闭时终止。它们独立于控制终端并且周期性的执行某种任务或等待处理某些发生的事件。
父进程与子进程 :系统调用 fork() 与 exec()
子进程就是父进程通过系统调用 fork() 而产生的复制品,fork() 就是把父进程的 PCB 等进程的数据结构信息直接复制过来,只是修改了 PID,只有在执行 exec() 之后才会不同,早先的 fork() 比较消耗资源,进化成 vfork(),效率提高
fork() :系统调用(system call),它的主要作用就是为当前的进程创建一个新的进程,这个新的进程就是它的子进程,这个子进程除了父进程的返回值和 PID 以外其他的都一模一样,
如进程的执行代码段,内存信息,文件描述,寄存器状态等等
exec() :也是系统调用,作用是切换子进程中的执行程序也就是替换其从父进程复制过来的代码段与数据段。
前台(foreground)就是在终端中运行,能与你有交互的
后台(background)就是在终端中运行,但是你并不能与其任何的交互,也不会显示其执行的过程
17,Linux进程管理
进程查看: top 实时的查看进程的状态,以及系统的一些信息(如 CPU、内存信息等), ps来静态查看当前的进程信息, pstree 来查看当前活跃进程的树形结构。
#查看物理CPU的个数
#cat /proc/cpuinfo |grep "physical id"|sort |uniq|wc -l
#每个cpu的核心数
cat /proc/cpuinfo |grep "physical id"|grep "0"|wc -l
ps:ps aux 罗列所有进程信息 ps axjf 进程树状显示 ps -afxo user,ppid,pid,pgid,command 每个字段排列显示 kill 杀死进程
进程执行顺序,nice控制优先级
#打开一个程序放在后台,或者用图形界面打开
nice -n -5 vim &
#用 ps 查看其优先级
ps -afxo user,ppid,pid,stat,pri,ni,time,command | grep vim
用 renice 来修改已经存在的进程的优先级
renice -5 pid
18,Linux日志系统
系统日志,应用日志
系统日志:
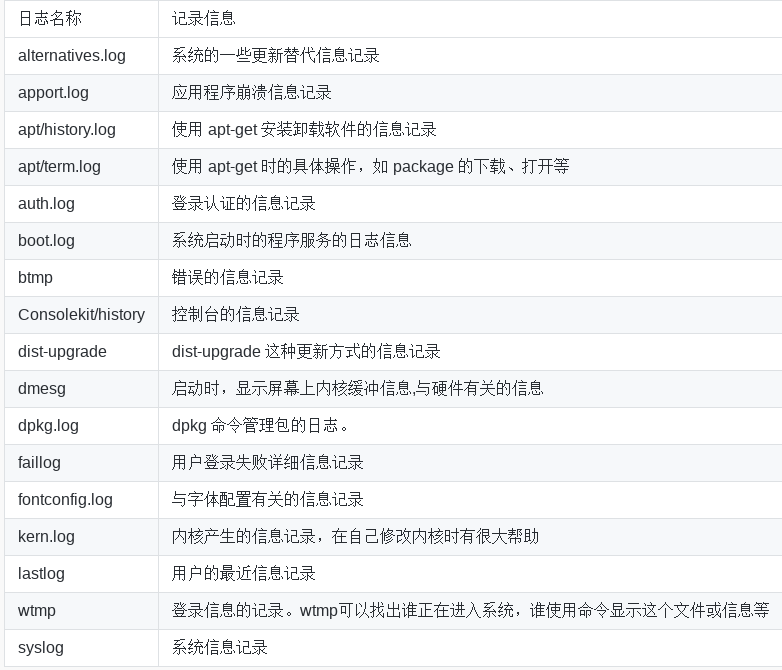
rsyslog的全称是 rocket-fast system for log,它提供了高性能,高安全功能和模块化设计,系统日志记录程序。
logrotate 程序是一个日志文件管理工具。用来把旧的日志文件删除,并创建新的日志文件。可以根据日志文件的大小,也可以根据其天数来切割日志、管理日志,这个过程又叫做“转储”。
logger 是一个 shell 命令接口,可以通过该接口使用 Syslog 的系统日志模块,还可以从命令行直接向系统日志文件写入信息。
#首先将syslog启动起来
sudo service rsyslog start
#向 syslog 写入数据
ping 127.0.0.1 | logger -it logger_test -p local3.notice &
#查看是否有数据写入
sudo tail -f /var/log/syslog

 浙公网安备 33010602011771号
浙公网安备 33010602011771号