GreatSQL 构建高效 HTAP 服务架构指南(MGR)
GreatSQL 构建高效 HTAP 服务架构指南(MGR)
引言
全文约定:
$为命令提示符、greatsql>为 GreatSQL 数据库提示符。在后续阅读中,依据此约定进行理解与操作
上一篇已经介绍了如何在主从复制架构中,搭建一个专属 HTAP 服务。本篇将在 MGR 架构中部署一个专属 HTAP 服务。
整体方案架构图
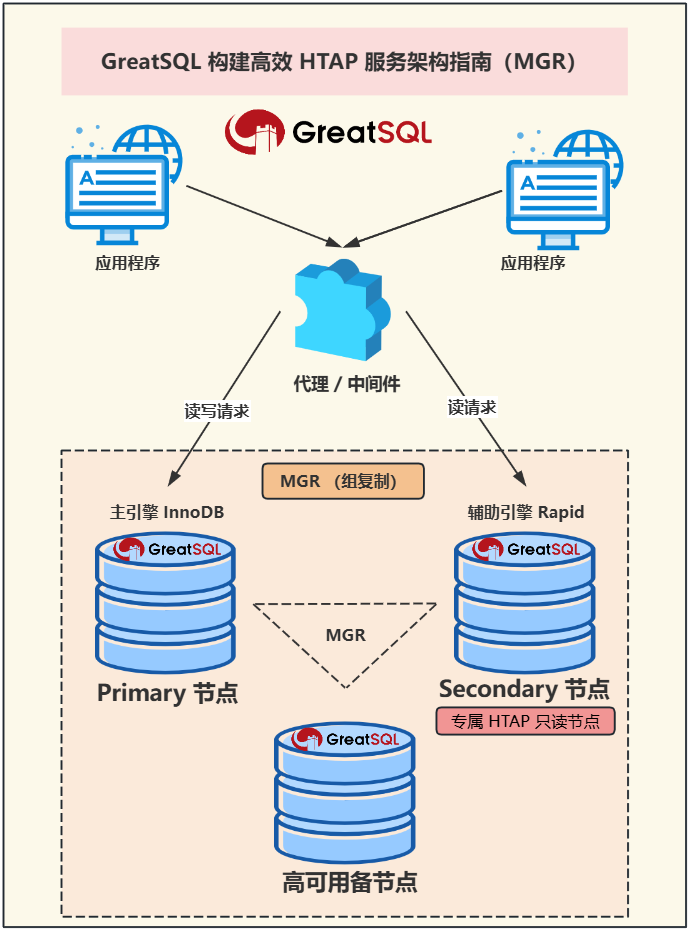
本服务架构采用 GreatSQL MGR 架构,在 MGR 架构中部署一个专属 HTAP 服务节点。Primary 节点采用默认 InnoDB 引擎,Secondary 节点使用辅助引擎 Rapid 加速查询构建专属 HTAP 只读节点。加上 MySQL Router 等之类的代理/中间件负责读写分离来完成 HTAP 服务架构。
- 高查询效率:
- Rapid引擎的引入使得从节点能够加速查询处理,特别适用于 OLAP(联机分析处理)场景。
- 读写分离及读负载均衡:
- 利用代理/中间件实现读写分离,确保主节点(写操作)和从节点(读操作)的读写负载得到有效均衡。
- 高可用:
- GreatSQL 针对 MGR 做了大量的改进和提升工作,进一步提升 MGR 的高可靠等级,例如:地理标签、读写节点VIP、仲裁节点等。
- 详见:[GreatSQL 高可用] https://greatsql.cn/docs/8.0.32-25/5-enhance/5-2-ha.html
- 高灵活和扩展:
- GreatSQL 的可插拔存储引擎架构使得系统可以根据需要选择适合的存储引擎。Rapid引擎作为辅助引擎,可以动态安装或卸载,为用户提供了极大的灵活性和可扩展性。
部署 MGR 架构
环境准备及版本介绍
服务器配置
$ uname -a
Linux gip 3.10.0-957.el7.x86_64 #1 SMP Thu Nov 8 23:39:32 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux
$ cat /etc/centos-release
CentOS Linux release 7.6.1810 (Core)
组件配置
| IP | 角色 | 版本 | 备注 |
|---|---|---|---|
| 192.168.6.215:3306 | Primary 节点 | GreatSQL 8.0.32-25 | |
| 192.168.6.214:3306 | Secondary 节点 | GreatSQL 8.0.32-25 | 专属 HTAP 只读节点 |
| 192.168.6.54:3306 | Secondary 节点 | GreatSQL 8.0.32-25 | 高可用备节点 |
| 192.168.6.215:3306 | MySQL Router | 8.4.0 TLS | 代理/中间件。可根据需求灵活替换 |
安装 GreatSQL
GreatSQL 安装版本为 8.0.32-25 版本,并分别安装三个实例 GreatSQL
安装步骤详见:https://greatsql.cn/docs/8.0.32-25/4-install-guide/0-install-guide.html
部署 MGR 架构
MGR 部署方案在 GreatSQL 用户手册中有详细介绍,可以使用 MySQL Shell for GreatSQL 或手动部署详见:https://greatsql.cn/docs/8.0.32-25/6-mgr/1-deploy-mgr.html 这里就不在过多赘述了。
部署成功后,在MGR架构中,可以查看MGR状态
greatsql> SELECT * FROM performance_schema.replication_group_members;
+---------------------------+--------------------------------------+----------------+-------------+--------------+-------------+----------------+----------------------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE | MEMBER_ROLE | MEMBER_VERSION | MEMBER_COMMUNICATION_STACK |
+---------------------------+--------------------------------------+----------------+-------------+--------------+-------------+----------------+----------------------------+
| group_replication_applier | 4c78e67d-338a-11ef-995c-00163edb666e | 192.168.6.56 | 3306 | ONLINE | SECONDARY | 8.0.32 | XCom |
| group_replication_applier | d7ebbeef-3384-11ef-8022-00163e832e1f | 192.168.6.214 | 3306 | ONLINE | SECONDARY | 8.0.32 | XCom |
| group_replication_applier | e3fb309c-3389-11ef-8b02-00163e8e122e | 192.168.6.215 | 3306 | ONLINE | PRIMARY | 8.0.32 | XCom |
+---------------------------+--------------------------------------+----------------+-------------+--------------+-------------+----------------+----------------------------+
3 rows in set (0.00 sec)
生成测试数据
主库写入数据
-- 创建测试数据库
CREATE DATABASE IF NOT EXISTS htap_test_db;
USE htap_test_db;
-- 创建接近生产环境的表
CREATE TABLE `orders` (
`order_id` int NOT NULL AUTO_INCREMENT,
`customer_id` int NOT NULL,
`product_id` int NOT NULL,
`order_date` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
`order_status` char(10) NOT NULL DEFAULT 'pending',
`quantity` int NOT NULL,
`order_amount` decimal(10,2) NOT NULL,
`shipping_address` varchar(255) NOT NULL,
`billing_address` varchar(255) NOT NULL,
`order_notes` varchar(255) DEFAULT NULL,
PRIMARY KEY (`order_id`),
KEY `idx_customer_id` (`customer_id`),
KEY `idx_product_id` (`product_id`),
KEY `idx_order_date` (`order_date`),
KEY `idx_order_status` (`order_status`)
) ENGINE=InnoDB AUTO_INCREMENT=100001 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
在 Primary 节点往该表插入十万行数据
greatsql> SELECT COUNT(*) FROM htap_test_db.orders;
+----------+
| COUNT(*) |
+----------+
| 100000 |
+----------+
1 row in set (0.01 sec)
如果在 Secondary 节点进行一个复杂 SQL 查询,需要用时 2~3 秒左右
SELECT
order_id,customer_id,product_id,order_date,order_status,
quantity,order_amount,shipping_address,billing_address,
order_notes,
SUM( order_amount ) OVER ( PARTITION BY customer_id ) AS total_spent_by_customer,
COUNT( order_id ) OVER ( PARTITION BY customer_id ) AS total_orders_by_customer,
AVG( order_amount ) OVER ( PARTITION BY customer_id ) AS average_order_amount_per_customer
FROM
orders
WHERE
order_status IN ( 'completed', 'shipped', 'cancelled' )
AND quantity > 1
ORDER BY
order_date DESC,
order_amount DESC
LIMIT 100;
运行三次结果平均值为 3.09 秒
# 第一次
100 rows in set (2.90 sec)
# 第二次
100 rows in set (3.14 sec)
# 第三次
100 rows in set (3.23 sec)
构建专属 HTAP 只读节点
以下所有操作都在 GreatSQL 192.168.6.214:3306 Secondary 节点中进行
使用 Rapid 引擎
进入 Secondary 节点,先关闭 super_read_only 并加载 Rapid 引擎
greatsql> SET GLOBAL super_read_only =off;
greatsql> INSTALL PLUGIN Rapid SONAME 'ha_rapid.so';
为InnoDB表加上Rapid辅助引擎
greatsql> ALTER TABLE htap_test_db.orders SECONDARY_ENGINE = rapid;
将表数据一次性全量导入到 Rapid 引擎中
greatsql> ALTER TABLE htap_test_db.orders SECONDARY_LOAD;
Query OK, 0 rows affected (1.72 sec)
检查导入情况,注意关键词 SECONDARY_ENGINE="rapid" SECONDARY_LOAD="1"
greatsql> SHOW TABLE STATUS like 'orders'\G
*************************** 1. row ***************************
Name: orders
Engine: InnoDB
Version: 10
Row_format: Dynamic
Rows: 93611
Avg_row_length: 140
Data_length: 13123584
Max_data_length: 0
Index_length: 9502720
Data_free: 4194304
Auto_increment: 200001
Create_time: 2024-06-27 11:00:46
Update_time: NULL
Check_time: NULL
Collation: utf8mb4_0900_ai_ci
Checksum: NULL
Create_options: SECONDARY_ENGINE="rapid" SECONDARY_LOAD="1"
Comment:
1 row in set (0.01 sec)
打开 Rapid 引擎的总控制开关,并把优化器阈值调小
greatsql> SET use_secondary_engine = ON;
greatsql> SET secondary_engine_cost_threshold = 0;
secondary_engine_cost_threshold的默认值是100000,可根据实际情况设置
查看该 SQL 的执行计划,注意关键词 Using secondary engine RAPID 表示使用了 Rapid 引擎
greatsql> EXPLAIN SELECT ... 省略 ... ORDER BY order_date DESC,order_amount DESC LIMIT 100;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: orders
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 93611
filtered: 33.33
Extra: Using where; Using filesort; Using secondary engine RAPID
1 row in set, 2 warnings (0.00 sec)
执行三次结果平均值为 0.086 秒,比之前提升近 36 倍!
# 第一次
100 rows in set (0.10 sec)
# 第二次
100 rows in set (0.08 sec)
# 第三次
100 rows in set (0.08 sec)
启动增量导入任务
因为在生产环境中数据是无时不刻在产生,所以需要启用增量导入,此时才可保证数据始终导入在 Rapid 引擎内
启动增量导入任务
greatsql> SELECT START_SECONDARY_ENGINE_INCREMENT_LOAD_TASK('htap_test_db', 'orders');
+----------------------------------------------------------------------+
| START_SECONDARY_ENGINE_INCREMENT_LOAD_TASK('htap_test_db', 'orders') |
+----------------------------------------------------------------------+
| success |
+----------------------------------------------------------------------+
查看增量导入任务状态
greatsql> SELECT * FROM information_schema.SECONDARY_ENGINE_INCREMENT_LOAD_TASK\G
*************************** 1. row ***************************
DB_NAME: htap_test_db
TABLE_NAME: orders
START_TIME: 2024-06-27 11:26:37
START_GTID: aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaa1:1-100011,
e3fb309c-3389-11ef-8b02-00163e8e122e:1
COMMITTED_GTID_SET: aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaa1:1-100011,
e3fb309c-3389-11ef-8b02-00163e8e122e:1
READ_GTID:
READ_BINLOG_FILE: ./binlog.000013
READ_BINLOG_POS: 1710
DELAY: 0
STATUS: RUNNING
END_TIME:
INFO:
1 row in set (0.01 sec)
在给主库插入 1 万条数据,确认主从复制和 Rapid 引擎的增量导入没有问题,产生的新数据也可以使用 Rapid 引擎加速查询。
请注意,Rapid 引擎在增量导入数据时可能存在短暂延迟。大量 Insert、Delete 数据,可能无法立即通过 Rapid 引擎查询到这些最新变动的数据。等增量任务导入完成后 Rapid 引擎才能查询到最新变动的数据。
# Secondary 节点查看数据是 110000 条和 Primary 节点一致
greatsql> SELECT COUNT(*) FROM htap_test_db.orders;
+----------+
| COUNT(*) |
+----------+
| 110000 |
+----------+
1 row in set (0.02 sec)
greatsql> EXPLAIN SELECT COUNT(*) FROM htap_test_db.orders\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: orders
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 103611
filtered: 100.00
Extra: Using secondary engine RAPID
1 row in set, 1 warning (0.00 sec)
此处启用了 Rapid 引擎所以COUNT(*)速度会很快,若没启用 Rapid 引擎则可能耗时较长
查看执行计划,从 rows 列可以看到,扫描的行数增加了,表示新数据已经增量导入到 Rapid 引擎中
greatsql> EXPLAIN SELECT ... 省略 ... ORDER BY order_date DESC,order_amount DESC LIMIT 100;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: orders
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 103611
filtered: 33.33
Extra: Using where; Using filesort; Using secondary engine RAPID
1 row in set, 2 warnings (0.00 sec)
操作完成后,记得把 super_read_only 打开,避免误写入数据,打开 super_read_only=ON 后,Rapid 引擎增量任务可正常运行
greatsql> SET GLOBAL super_read_only =on;
此方案真正上线后,还需增添额外的高可用切换逻辑处理,例如:
至此,MGR架构下和构建 HTAP 专属只读节点完成,接下来是使用中间件实现读写分离
实现读写分离
这里使用的是 MySQL Router 中间件实现的读写分离,MySQL Router 对 MGR 兼容度高,契合度好。
使用 MySQL Router 需要用 MySQL Shell 纳管 MGR 集群,否则 MySQL Router 会报错:
Error: Error executing MySQL query "SELECT * FROM mysql_innodb_cluster_metadata.schema_version": SELECT command denied to user 'repl'@'192.168.6.215' for table 'schema_version' (1142)
若使用 MySQL Shell 构建的 MGR 集群则不需要再次纳管,若手动构建的 MGR 集群请参阅文章进行纳管
安装 MySQL Router
下载过程省略,可自行到 MySQL 网站上下载
这里选择的是最新的长期支持版 MySQL Router 8.4.0 版本
解压安装包,并进入 MySQL Router 的 bin 目录
$ tar -xvJf mysql-router-8.4.0-linux-glibc2.17-x86_64.tar.xz
可以做一个环境变量
$ echo 'export PATH=/usr/local/mysql-router-8.4.0-linux-glibc2.17-x86_64/bin:$PATH' >> ~/.bash_profile
$ source ~/.bash_profile
创建一个 MySQL Router 用户
$ /sbin/groupadd mysqlrouter
$ /sbin/useradd -g mysqlrouter mysqlrouter -d /dev/null -s /sbin/nologin
初始化 MySQL Router
$ mysqlrouter --bootstrap repl@192.168.6.215:3306 --user=root
# 输出结果如下
...部分省略
After this MySQL Router has been started with the generated configuration
$ /etc/init.d/mysqlrouter restart
or
$ systemctl start mysqlrouter
or
$ mysqlrouter -c /usr/local/mysql-router-8.4.0-linux-glibc2.17-x86_64/mysqlrouter.conf
...部分省略
- Read/Write Connections: localhost:6446
- Read/Only Connections: localhost:6447
- Read/Write Split Connections: localhost:6450
## MySQL X protocol
- Read/Write Connections: localhost:6448
- Read/Only Connections: localhost:6449
可以看到在 6446、6447 端口的基础上有一个 6450 端口,这个端口可以作为读写分离端口
这就初始化完毕了,按照上面的提示,直接启动 mysqlrouter 服务即可,检查下是否正常启动
mysqlrouter -c /usr/local/mysql-router-8.4.0-linux-glibc2.17-x86_64/mysqlrouter.conf &
$ ps -ef | grep -v grep | grep mysqlrouter
root 29153 4815 1 16:10 pts/0 00:00:03 mysqlrouter -c /usr/local/mysql-router-8.4.0-linux-glibc2.17-x86_64/mysqlrouter.conf
$ netstat -lntp | grep mysqlrouter
tcp 0 0 0.0.0.0:6446 0.0.0.0:* LISTEN 29153/mysqlrouter
tcp 0 0 0.0.0.0:6447 0.0.0.0:* LISTEN 29153/mysqlrouter
tcp 0 0 0.0.0.0:6448 0.0.0.0:* LISTEN 29153/mysqlrouter
tcp 0 0 0.0.0.0:6449 0.0.0.0:* LISTEN 29153/mysqlrouter
tcp 0 0 0.0.0.0:6450 0.0.0.0:* LISTEN 29153/mysqlrouter
tcp 0 0 0.0.0.0:8443 0.0.0.0:* LISTEN 29153/mysqlrouter
现在需要更改下 MySQL ROUTER 中的 [routing:bootstrap_ro] 配置使其读操作优先在专属 HTAP 节点上读
[routing:bootstrap_ro]
bind_address=0.0.0.0
bind_port=6447
# 更改后
destinations=192.168.6.214:3306,192.168.6.215:3306,192.168.6.56:3306
routing_strategy=first-available
# 更改前
#destinations=metadata-cache://mgr/?role=SECONDARY
#routing_strategy=round-robin-with-fallback
protocol=classic
测试读写分离效果
在启动 rouyter 测试读写分离效果,先测试写节点是否指向 PRIMARY 节点
$ for ((i=0;i<=2;i++));do mysql -h192.168.6.215 -urepl -p'GreatSQL@2024' -P6446 -e"select @@server_id;";done;
+-------------+
| @@server_id |
+-------------+
| 3306 |
+-------------+
+-------------+
| @@server_id |
+-------------+
| 3306 |
+-------------+
+-------------+
| @@server_id |
+-------------+
| 3306 |
+-------------+
在测试读节点是否指向 SECONDARY 节点
$ for ((i=0;i<=2;i++));do mysql -h192.168.6.215 -urepl -p'GreatSQL@2024' -P6447 -e"select @@server_id;";done;
+-------------+
| @@server_id |
+-------------+
| 3307 |
+-------------+
+-------------+
| @@server_id |
+-------------+
| 3307 |
+-------------+
+-------------+
| @@server_id |
+-------------+
| 3307 |
+-------------+
最后测试读写分离端口 6450 是否会将读写操作分别指向 PRIMARY 节点和 SECONDARY 节点
$ for ((i=0;i<=2;i++));do mysql -h192.168.6.215 -urepl -p'GreatSQL@2024' -P6450 -e"select @@server_id;";done;
+-------------+
| @@server_id |
+-------------+
| 3308 |
+-------------+
+-------------+
| @@server_id |
+-------------+
| 3307 |
+-------------+
+-------------+
| @@server_id |
+-------------+
| 3308 |
+-------------+
# 因为其余两个 SECONDARY 节点设置 super_read_only=OFF,若能写入必定指向 PRIMARY 节点
$ mysql -h192.168.6.215 -uroot -p'GreatSQL@2024' -P6450 -e "INSERT INTO htap_test_db.orders (customer_id, product_id, order_status, quantity, order_amount, shipping_address, billing_address, order_notes) VALUES (274, 467, 'processing', 6, 17.70, 'Shipping Address 2', 'Billing Address 2', 'Order note for order 2');"
由于 3308 节点与 3307 节点皆为 SECONDARY 节点,故而在进行读操作时,会对这两个节点轮询分配,因此 6450 读写分离端口无法指定专门使用专属的 HTAP 节点。倘若有需求,将 3308 节点启用 Rapid 引擎即可。
当 PRIMARY 节点发生宕机状况后,若 3308 这个高可用节点成为新的 PRIMARY 节点,那么 3308 节点所设置的 Rapid 引擎并不会对所有的读写操作产生影响。
自此构建高效 HTAP 服务器架构(MGR)完成!
Enjoy GreatSQL 😃
关于 GreatSQL
GreatSQL是适用于金融级应用的国内自主开源数据库,具备高性能、高可靠、高易用性、高安全等多个核心特性,可以作为MySQL或Percona Server的可选替换,用于线上生产环境,且完全免费并兼容MySQL或Percona Server。
相关链接: GreatSQL社区 Gitee GitHub Bilibili
GreatSQL社区:
社区博客有奖征稿详情:https://greatsql.cn/thread-100-1-1.html

技术交流群:
微信:扫码添加
GreatSQL社区助手微信好友,发送验证信息加群。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号