
AP引擎助力加速生产环境运行

Rapid存储引擎简介
从GreatSQL 8.0.32-25版本开始,新增Rapid存储引擎,该引擎使得GreatSQL能满足联机分析(OLAP)查询请求。
Rapid引擎采用插件(Plugin)方式嵌入GreatSQL中,可以在线动态安装或卸载。
Rapid引擎不会直接面对客户端和应用程序,用户无需修改原有的数据访问方式。它是一个无共享、内存化、混合列式存储的查询处理引擎,其设计目的是为了高性能的处理分析型查询。
并且在TPC-H性能表现优异在32C64G测试机环境下,TPC-H 100G测试中22条SQL总耗时 仅需不到80秒
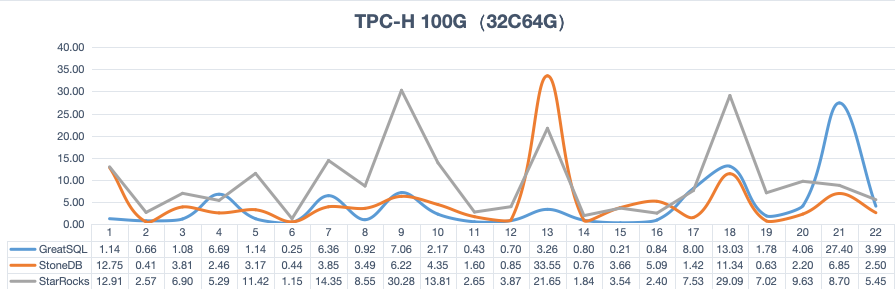
下面是几个不同TPC-H数据量级的压缩率数据:
| TPC-H仓库大小 | InnoDB引擎数据文件大小 | Rapid引擎数据文件大小 | 压缩率 |
|---|---|---|---|
| TPC-H 1GB | 2003026076 | 276574208 | 7.24 |
| TPC-H 100GB | 184570593436 | 28728373248 | 6.42 |
| TPC-H 500GB | 1167795142848 | 146723045376 | 7.96 |
经过GreatSQL社区的测试分析可以看出,相较于InnoDB存储引擎,Rapid存储引擎在存储效率上获得了极大提升。在存放相同的数据集时,Rapid的数据文件所需要的空间仅为InnoDB的6~7分之1,大约 降低了85% 左右。
真实生产案例测试
为了全面验证AP引擎的性能提升,我们成功获取了真实生产环境下的SQL语句、表结构以及经过脱敏处理的数据。在此,特别感谢潲同学和贵司的协助!
测试环境介绍
本次测试采用的环境是 Arch Linux x86_64,机器配置为12C15G
$ uname -a
Linux myarch 6.6.3-arch1-1 #1 SMP PREEMPT_DYNAMIC Wed, 29 Nov 2023 00:37:40 +0000 x86_64 GNU/Linux
$ cat /proc/cpuinfo | grep "processor" | wc -l
12
$ free -h
total
Mem: 15Gi
采用的GreatSQL版本为 GreatSQL 8.0.32-25 版本
$ mysql --version
mysql Ver 8.0.32-25 for Linux on x86_64 (GreatSQL, Release 25, Revision 79f57097e3f)
真实生产SQL
展示即将进行测试的生产SQL(这里不深入讨论该SQL是否存在优化的可能性):
select c.id, c.dept_id, c.user_id, c.type, c.source, c.charge_no, c.amount, c.from_bank, c.to_bank, c.receipt,c.status, c.remark, c.create_by, c.create_time, c.update_by, c.update_time,c.reason,c.fr_no
, d.dept_name, dt.company_name, cp.company_name
from charge c
left join dept d on c.dept_id = d.dept_id
left join user u on c.user_id = u.user_id
left join dept_tax dt on c.dept_id = dt.dept_id
left join dept_info di on c.dept_id = di.dept_id
left join company_bank cb on di.sign_cbid = cb.id
left join company cp on cb.company_id = cp.company_id
limit 3313445,10;
真实生产表结构
生产SQL涉及7张表,我们将逐一展示每张表的表结构。为了保护隐私,我们对部分字段进行了脱敏处理以及一些微调
dept表
CREATE TABLE `dept` (
`dept_id` bigint(20) NOT NULL AUTO_INCREMENT,
`parent_id` bigint(20) DEFAULT '0',
`ancestors` varchar(50) DEFAULT '',
`dept_name` varchar(30) DEFAULT '',
......
`create_time` datetime DEFAULT NULL,
`update_by` varchar(64) DEFAULT '',
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`dept_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='部门表'
user表
CREATE TABLE `user` (
`user_id` bigint(20) NOT NULL AUTO_INCREMENT,
`dept_id` bigint(20) DEFAULT NULL,
`fans_id` bigint(20) DEFAULT NULL,
`login_name` varchar(30) NOT NULL,
`user_name` varchar(30) NOT NULL,
`alias` varchar(100) DEFAULT NULL,
`user_type` varchar(2) DEFAULT '00',
`email` varchar(50) DEFAULT '',
`phonenumber` varchar(11) DEFAULT '',
`sex` char(1) DEFAULT '0',
......
`create_by` varchar(64) DEFAULT '',
`create_time` datetime DEFAULT NULL,
`update_by` varchar(64) DEFAULT '',
`update_time` datetime DEFAULT NULL,
`remark` varchar(500) DEFAULT NULL,
PRIMARY KEY (`user_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='用户表'
dept_tax表
CREATE TABLE `dept_tax` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`dept_id` bigint(20) NOT NULL,
`company_name` varchar(50) NOT NULL,
`tax_no` varchar(50) DEFAULT NULL,
`tax_type` varchar(30) DEFAULT NULL,
......
`create_by` varchar(50) DEFAULT '',
`create_time` datetime DEFAULT NULL,
`update_by` varchar(50) DEFAULT '',
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='信息表'
dept_info表
CREATE TABLE `dept_info` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`dept_id` bigint(20) NOT NULL,
`customer_id` bigint(20) DEFAULT NULL,
`dept_type` char(1) DEFAULT '1',
`industry_type` char(1) DEFAULT '0',
`dept_flag` char(1) DEFAULT '1',
`dept_kind` char(1) DEFAULT '0',
`bus_scope` varchar(10) DEFAULT '1',
`channel_id` bigint(20) DEFAULT NULL,
......
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='信息表'
company_bank表
CREATE TABLE `company_bank` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`company_id` bigint(20) DEFAULT NULL,
`bank_name` varchar(50) DEFAULT NULL,
`bank_card` varchar(30) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
company表
CREATE TABLE `company` (
`company_id` bigint(20) NOT NULL AUTO_INCREMENT,
`company_name` varchar(100) DEFAULT NULL,
PRIMARY KEY (`company_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
charge表
CREATE TABLE `charge` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`dept_id` bigint(20) NOT NULL,
`user_id` bigint(20) DEFAULT NULL,
`type` char(1) DEFAULT NULL,
......
`create_time` datetime DEFAULT NULL,
`update_by` varchar(50) DEFAULT '',
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
不深入探讨SQL和表结构是否存在优化的可能性,只验证AP引擎提升查询测试。
加载数据
鉴于原始数据较为有限,为了更明显地进行测试,我们为每张表生成了一些新数据,来看下各表数据和表空间大小是多少:
| 表名 | 数据量 | 表空间大小 |
|---|---|---|
| dept | 11000 | 10M |
| user | 100000 | 31M |
| dept_tax | 10000 | 88M |
| charge | 1000000 | 184M |
| company | 1000 | 160K |
| dept_info | 10000 | 11M |
| company_bank | 1000 | 176K |
未改造测试
待测试的SQL语句:
select c.id, c.dept_id, c.user_id, c.type, c.source, c.charge_no, c.amount, c.from_bank, c.to_bank, c.receipt,c.status, c.remark, c.create_by, c.create_time, c.update_by, c.update_time,c.reason,c.fr_no
, d.dept_name, dt.company_name, cp.company_name
from _charge c
left join dept d on c.dept_id = d.dept_id
left join user u on c.user_id = u.user_id
left join dept_tax dt on c.dept_id = dt.dept_id
left join dept_info di on c.dept_id = di.dept_id
left join company_bank cb on di.sign_cbid = cb.id
left join company cp on cb.company_id = cp.company_id
limit 3313445,10;
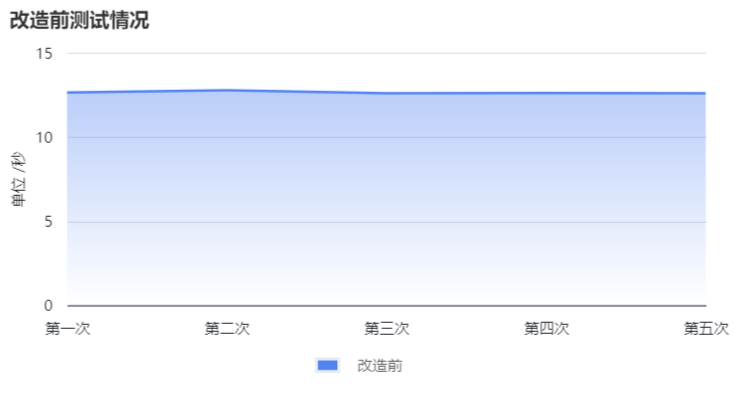
先不使用AP引擎测试查询五次:
| 测试次数 | 耗时 |
|---|---|
| 第一次 | 10 rows in set (12.64 sec) |
| 第二次 | 10 rows in set (12.77 sec) |
| 第三次 | 10 rows in set (12.60 sec) |
| 第四次 | 10 rows in set (12.61 sec) |
| 第五次 | 10 rows in set (12.59 sec) |
可以看到五次测试结果都是稳定在12秒左右,平均耗时12.64/s:
使用Rapid引擎测试
启用Rapid引擎
greatsql> INSTALL PLUGIN Rapid SONAME 'ha_rapid.so';
greatsql> SHOW PLUGINS;
+----------------------------------+----------+--------------------+----------------------+---------+
| Name | Status | Type | Library | License |
+----------------------------------+----------+--------------------+----------------------+---------+
| binlog | ACTIVE | STORAGE ENGINE | NULL | GPL |
...
| Rapid | ACTIVE | STORAGE ENGINE | ha_rapid.so | GPL |
+----------------------------------+----------+--------------------+----------------------+---------+
55 rows in set (0.00 sec)
加上Rapid辅助引擎
greatsql> ALTER TABLE dept SECONDARY_ENGINE = rapid;
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
greatsql> ALTER TABLE user SECONDARY_ENGINE = rapid;
greatsql> ALTER TABLE charge SECONDARY_ENGINE = rapid;
greatsql> ALTER TABLE company SECONDARY_ENGINE = rapid;
greatsql> ALTER TABLE company_bank SECONDARY_ENGINE = rapid;
greatsql> ALTER TABLE dept_info SECONDARY_ENGINE = rapid;
greatsql> ALTER TABLE dept_tax SECONDARY_ENGINE = rapid;
查看建表DDL,发现增加了 SECONDARY_ENGINE=rapid
greatsql> SHOW CREATE TABLE _company\G
*************************** 1. row ***************************
Table: company
Create Table: CREATE TABLE `company` (
`company_id` bigint NOT NULL AUTO_INCREMENT COMMENT '序号ID',
`company_name` varchar(100) DEFAULT NULL COMMENT '签约主体',
PRIMARY KEY (`company_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1001 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci SECONDARY_ENGINE=rapid
1 row in set (0.00 sec)
数据全量导入Rapid引擎中
greatsql> ALTER TABLE dept SECONDARY_LOAD;
greatsql> ALTER TABLE user SECONDARY_LOAD;
greatsql> ALTER TABLE charge SECONDARY_LOAD;
greatsql> ALTER TABLE company SECONDARY_LOAD;
greatsql> ALTER TABLE company_bank SECONDARY_LOAD;
greatsql> ALTER TABLE dept_info SECONDARY_LOAD;
greatsql> ALTER TABLE dept_tax SECONDARY_LOAD;
开始测试Rapid引擎
有两种方式启用Rapid引擎
方式一
-- 设置use_secondary_engine=ON的时候,为保证查询语句能够使用rapid,
-- 通常需要设置secondary_engine_cost_threshold = 0,或一个较小的阈值
SET use_secondary_engine = ON;
SET secondary_engine_cost_threshold = 0;
方式二(不建议)
-- 修改会话变量,设置强制使用Rapid引擎
SET use_secondary_engine = FORCED;
-- 或执行SQL查询时指定HINT
SELECT /*+ SET_VAR(use_secondary_engine=forced) */ ...省略 FROM from charge c;
先使用方案二,执行SQL查询时指定HINT测试五次看看表现如何
待测试的SQL语句:
select /*+ SET_VAR(use_secondary_engine=forced) */ c.id, c.dept_id, c.user_id, c.type, c.source, c.charge_no, c.amount, c.from_bank, c.to_bank, c.receipt,c.status, c.remark, c.create_by, c.create_time, c.update_by, c.update_time,c.reason,c.fr_no
, d.dept_name, dt.company_name, cp.company_name
from _charge c
left join dept d on c.dept_id = d.dept_id
left join user u on c.user_id = u.user_id
left join dept_tax dt on c.dept_id = dt.dept_id
left join dept_info di on c.dept_id = di.dept_id
left join company_bank cb on di.sign_cbid = cb.id
left join company cp on cb.company_id = cp.company_id
limit 3313445,10;
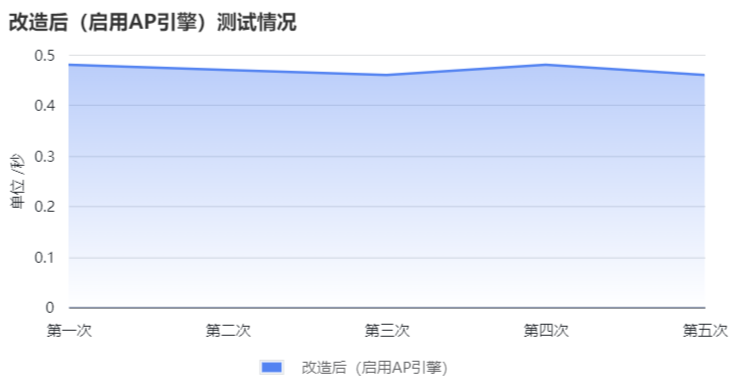
同样测试查询五次:
| 测试次数 | 耗时 |
|---|---|
| 第一次 | 10 rows in set (0.48 sec) |
| 第二次 | 10 rows in set (0.47 sec) |
| 第三次 | 10 rows in set (0.46 sec) |
| 第四次 | 10 rows in set (0.48 sec) |
| 第五次 | 10 rows in set (0.46 sec) |
可以看到Rapid引擎出手即是秒杀,平均耗时0.47/s:
改造前(平均耗时12.64/s)和改造后(平均耗时0.47/s)对比测试结果:
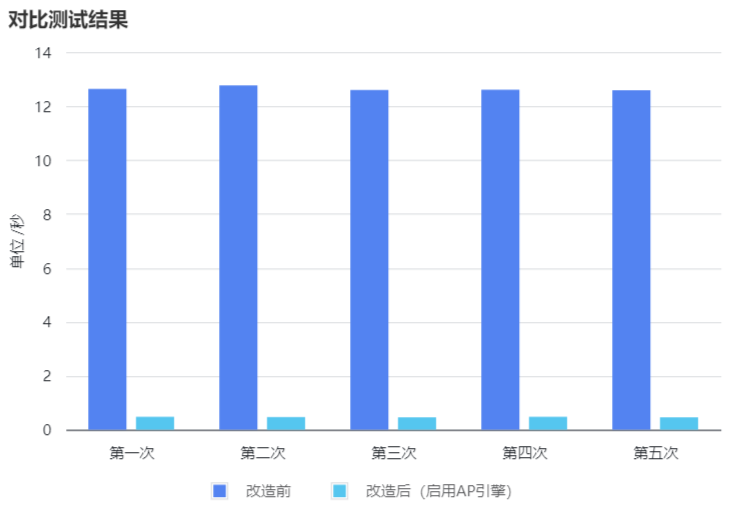
总体来说改造后约提升了26.9倍:

如果我们选择使用HINT进行改造,就需要对原SQL语句进行相应修改。因此,我们将采用方案一来进行试验
greatsql> SET use_secondary_engine = ON;
greatsql> secondary_engine_cost_threshold = 0;
# 查看下执行计划
greatsql> explain select c.id, c.dept_id, c.user_id, c.type, c.source, c.charge_no, c.amount, c.from_bank, c.to_bank, c.receipt,c.status, c.remark, c.create_by, c.create_time, c.update_by, c.update_time,c.reason,c.fr_no , d.dept_name, dt.company_name, cp.company_name from charge c left join dept d on c.dept_id = d.dept_id left join user u on c.user_id = u.user_id left join dept_tax dt on c.dept_id = dt.dept_id left join dept_info di on c.dept_id = di.dept_id left join company_bank cb on di.sign_cbid = cb.id left join company cp on cb.company_id = cp.company_id limit 3313445,10\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: c
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 905486
filtered: 100.00
Extra: Using secondary engine RAPID # 证明用到RAPID引擎
# 下方省略,证明有用到RAPID引擎即可
可以看到默认的使用了RAPID引擎
数据导入
在上方我们执行过ALTER TABLE xxx SECONDARY_LOAD这个操作,会将InnoDB主引擎中的数据全量加载到Rapid引擎中,这个过程称为全量导入。全量导入成功后,Rapid引擎中的数据是静态的,当向主引擎表中继续插入、删除、修改数据时,并不会导入到Rapid引擎中。
那数据会更新会修改要怎么办呢?总不能每次都全量导入吧?
所以此时可以利用binlog特性,可以在全量导入成功后,启动增量导入任务。增量任务会读取自全量导入成功之后的binlog数据,将binlog解析并应用到rapid引擎中,这个过程称为增量导入。
不同于全量导入,增量导入会启动一个常驻的后台线程,实时读取和应用增量binlog数据。
增量导入数据的限制和需求
在手册上有介绍到增量导入数据的限制和需求,如下:
- 需要设置表名大小写不敏感,即设置
lower_case_table_names = 1。 - 需要开启GTID模式,即设置
gtid_mode = ON和enforce_gtid_consistency = ON。 - 需要采用row格式的binlog event,不支持statement格式,即设置
binlog_format = ROW。增量任务运行过程中,检测到statement的DML event,可能会报错退出。 - 需要关闭GIPKs特性,即设置
sql_generate_invisible_primary_key = OFF。用户表不能有 invisible primary key,如果表包含隐式不可见的主键,在全量导入过程中会报错;同时也不支持用户表中存在任何不可见列(invisible column)。 - 需要先对表执行过一次全量导入后,才能启动增量导入任务,否则任务启动会报错。
- 不支持 PARTIAL_UPDATE_ROWS_EVENT 类型的binlog,即不要设置
binlog_row_value_options = PARTIAL_JSON。 - 不支持
CREATE TABLE SELECT语句,增量任务运行过程中,检测到该语句产生的binlog event时可能会报错退出。 - 不支持XA事务,运行过程中检查到XA事务会报错退出。
开启增量导入
增量导入有两个系统函数分别是
START_SECONDARY_ENGINE_INCREMENT_LOAD_TASK():启动任务STOP_SECONDARY_ENGINE_INCREMENT_LOAD_TASK():停止任务
执行SQL命令 SELECT START_SECONDARY_ENGINE_INCREMENT_LOAD_TASK() 即可启动增量任务,根据函数返回信息可以确认是否任务启动成功。如果启动失败,可以从错误日志中查看具体失败的原因。
该函数包含3个参数:
- db_name,必选项,指定增量导入任务对应的数据库名。
- table_name,必选项,指定增量导入任务对应的数据表名。
- gtid,可选项,指定开始增量导入任务的起始gtid_set值。默认不需要指定,任务会自动根据
ALTER TABLE ... SECONDARY_LOAD全量导入时刻的gtid_executed进行计算和判断。
-- 对user表启动增量导入任务
greatsql> SELECT START_SECONDARY_ENGINE_INCREMENT_LOAD_TASK('aptest', 'user');
+------------------------------------------------------------------+
| START_SECONDARY_ENGINE_INCREMENT_LOAD_TASK('aptest', 'user') |
+------------------------------------------------------------------+
| success |
+------------------------------------------------------------------+
1 row in set (0.00 sec)
-- 查看增量导入任务状态
greatsql> SELECT * FROM information_schema.SECONDARY_ENGINE_INCREMENT_LOAD_TASK\G
*************************** 1. row ***************************
DB_NAME: aptest
TABLE_NAME: user
START_TIME: 2024-02-21 09:33:55
START_GTID: 9548406d-8ff1-11ee-97ec-ec5c6826bca3:1-3808
COMMITTED_GTID_SET: 9548406d-8ff1-11ee-97ec-ec5c6826bca3:1-3821
READ_GTID: 9548406d-8ff1-11ee-97ec-ec5c6826bca3:3821
READ_BINLOG_FILE: ./binlog.000023
READ_BINLOG_POS: 596312770
DELAY: 0
STATUS: RUNNING
END_TIME:
INFO:
1 row in set (0.00 sec)
当然如果想停止也可以使用以下操作停止增量同步
greatsql> SELECT STOP_SECONDARY_ENGINE_INCREMENT_LOAD_TASK('aptest', 'user');
greatsql> SELECT STOP_SECONDARY_ENGINE_INCREMENT_LOAD_TASK('aptest', 'user');
+-----------------------------------------------------------------+
| STOP_SECONDARY_ENGINE_INCREMENT_LOAD_TASK('aptest', 'user') |
+-----------------------------------------------------------------+
| success |
+-----------------------------------------------------------------+
1 row in set (0.21 sec)
greatsql> SELECT * FROM information_schema.SECONDARY_ENGINE_INCREMENT_LOAD_TASK\G
*************************** 1. row ***************************
DB_NAME: aptest
TABLE_NAME: user
START_TIME: 2024-02-21 09:33:55
START_GTID: 9548406d-8ff1-11ee-97ec-ec5c6826bca3:1-3808
COMMITTED_GTID_SET: 9548406d-8ff1-11ee-97ec-ec5c6826bca3:1-3821
READ_GTID: 9548406d-8ff1-11ee-97ec-ec5c6826bca3:3821
READ_BINLOG_FILE: ./binlog.000023
READ_BINLOG_POS: 596312770
DELAY: 60
STATUS: NOT RUNNING
END_TIME: 2024-02-21 09:35:46
INFO: NORMAL EXIT
1 row in set (0.00 sec)
更多Rapid存储引擎介绍请前往GreatSQL用户手册上查看 Rapid引擎(Rapid Engine)https://greatsql.cn/docs/8032-25/user-manual/5-enhance/5-1-highperf-rapid-engine.html
总结
对于在不改造SQL的前提下,查询速度提升了 26.9倍 的这一结果,潲同学表示非常惊讶。然而,令人遗憾的是,他们尚未迁移到GreatSQL数据库。因此,他目前正紧锣密鼓地向总监提议,争取尽快完成迁移并采用GreatSQL数据库:)
目前Rapid存储引擎已经开放测试了,欢迎各位来体验测试~
GreatSQL手册:https://greatsql.cn/docs/8032-25/
GreatSQL下载地址:https://gitee.com/GreatSQL/GreatSQL/releases/tag/GreatSQL-8.0.32-25
Enjoy GreatSQL 😃
关于GreatSQL
GreatSQL数据库是一款开源免费数据库,可在普通硬件上满足金融级应用场景,具有高可用、高性能、高兼容、高安全等特性,可作为MySQL或Percona Server for MySQL的理想可选替换。
相关链接
技术交流群
微信:添加GreatSQL社区助手好友,微信号wanlidbc发送验证信息加群
QQ群:533341697
Enjoy GreatSQL 😃
关于 GreatSQL
GreatSQL是适用于金融级应用的国内自主开源数据库,具备高性能、高可靠、高易用性、高安全等多个核心特性,可以作为MySQL或Percona Server的可选替换,用于线上生产环境,且完全免费并兼容MySQL或Percona Server。
相关链接: GreatSQL社区 Gitee GitHub Bilibili
GreatSQL社区:
社区博客有奖征稿详情:https://greatsql.cn/thread-100-1-1.html

技术交流群:
微信:扫码添加
GreatSQL社区助手微信好友,发送验证信息加群。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号