实现一个简单的Database11(译文)
- GreatSQL社区原创内容未经授权不得随意使用,转载请联系小编并注明来源。
- GreatSQL是MySQL的国产分支版本,使用上与MySQL一致。
- 作者: 花家舍
- 文章来源:GreatSQL社区原创
前文回顾
译注:cstack在github维护了一个简单的、类似sqlite的数据库实现,通过这个简单的项目,可以很好的理解数据库是如何运行的。本文是第十一篇,主要是实现递归搜索B-Tree
Part 11 递归搜索B-Tree
上次我们在插入第15行数据报错的时候结束:
db > insert 15 user15 person15@example.com
Need to implement searching an internal node
首先,使用一个新的函数调用替换埋桩的代码。
if (get_node_type(root_node) == NODE_LEAF) {
return leaf_node_find(table, root_page_num, key);
} else {
- printf("Need to implement searching an internal node\n");
- exit(EXIT_FAILURE);
+ return internal_node_find(table, root_page_num, key);
}
}
这个函数会执行二叉搜索来查找子节点是否会包含给定的 Key。请记住,这些指向右子节点的 Key 都是他们指向的子节点中包含的最大 Key 。
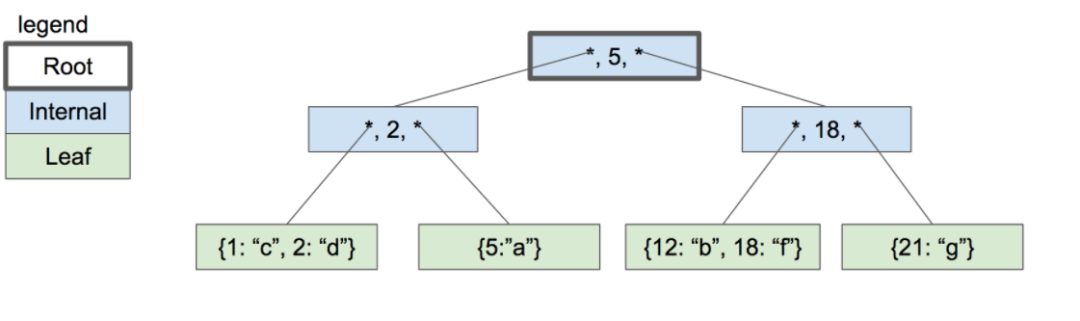
three-level btree
所以我们的二叉搜索比较查找的 Key 和指向右边子节点的的指针。
+Cursor* internal_node_find(Table* table, uint32_t page_num, uint32_t key) {
+ void* node = get_page(table->pager, page_num);
+ uint32_t num_keys = *internal_node_num_keys(node);
+
+ /* Binary search to find index of child to search */
+ uint32_t min_index = 0;
+ uint32_t max_index = num_keys; /* there is one more child than key */
+
+ while (min_index != max_index) {
+ uint32_t index = (min_index + max_index) / 2;
+ uint32_t key_to_right = *internal_node_key(node, index);
+ if (key_to_right >= key) {
+ max_index = index;
+ } else {
+ min_index = index + 1;
+ }
+ }
另请记住,内部节点的子节点可以是叶节点,也可以是内部节点。在我们查找到正确的子节点后,会在节点上调用适合的搜索函数:
+ uint32_t child_num = *internal_node_child(node, min_index);
+ void* child = get_page(table->pager, child_num);
+ switch (get_node_type(child)) {
+ case NODE_LEAF:
+ return leaf_node_find(table, child_num, key);
+ case NODE_INTERNAL:
+ return internal_node_find(table, child_num, key);
+ }
+}
测试
现在向一个多节点btree插入 key 不再会导致报错结果。所以我们可以更新我们的测例:
" - 12",
" - 13",
" - 14",
- "db > Need to implement searching an internal node",
+ "db > Executed.",
+ "db > ",
])
end
我觉得现在是反思一下我们的另一个测试的时候了。也就是尝试插入1400行数据。仍然会报错,但是报错信息变成新的其他报错。现在,当程序 crash 的时候,我们的测试不能很好的处理这种报错。如果发生这种报错情况,到目前为止我们只使用获得的输出。
raw_output = nil
IO.popen("./db test.db", "r+") do |pipe|
commands.each do |command|
- pipe.puts command
+ begin
+ pipe.puts command
+ rescue Errno::EPIPE
+ break
+ end
end
pipe.close_write
下面显示出了我们在测试插入1400行时输出的报错:
end
script << ".exit"
result = run_script(script)
- expect(result[-2]).to eq('db > Error: Table full.')
+ expect(result.last(2)).to match_array([
+ "db > Executed.",
+ "db > Need to implement updating parent after split",
+ ])
end
看起来这是我们待办事项列表中的下一个!
Enjoy GreatSQL 😃
关于 GreatSQL
GreatSQL是由万里数据库维护的MySQL分支,专注于提升MGR可靠性及性能,支持InnoDB并行查询特性,是适用于金融级应用的MySQL分支版本。
相关链接: GreatSQL社区 Gitee GitHub Bilibili
GreatSQL社区:
社区博客有奖征稿详情:https://greatsql.cn/thread-100-1-1.html

技术交流群:
微信:扫码添加
GreatSQL社区助手微信好友,发送验证信息加群。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号