
实现一个简单Database8(译文)
前文回顾
译注:cstack在github维护了一个简单的、类似sqlite的数据库实现,通过这个简单的项目,可以很好的理解数据库是如何运行的。本文是第八篇,主要是对B-tree的叶子节点格式的实现
Part 8 B-Tree叶子节点格式
我们准备把表的格式从非排序的数组格式行(rows)改成B-Tree。这是一个相当大变化,需要多个篇幅才能实现。在本文结束时,我们将定义叶子节点的布局,支持插入键值对儿到单节点的B-Tree。但是首先,来回顾一下把数据结构(从数组array)切换到B-Tree的原因。
替换表格式
根据现在的格式(数组组织的行数据格式),每个page存储的只有行数据(没有元数据),所以空间使用上很有效率,非常节省空间。插入操作也很快,因为它只是追加到表的结尾而已。然而,查询一个特定的行数据只能遍历整张表的数据才能搞定。并且如果想删除一行数据的话,我们就只能移动这条数据后面的所有数据才能填补因为删除数据产生的空洞。
如果把表数据按照数组的方式存储,但是保持行按 id 排序,我们就可以使用二分查找方式来查找一个特定的 id 。然而,插入操作会变得很慢,因为我们不得不移动大量行(rows)才能腾出空间插入数据。
相反,我们采用树的结构。每个在树中的节点能够包含的行数量可变,所以我们不得不在节点中存储一些额外信息来追踪节点中包含了多少行数据。此外,所有内部节点还有存储开销,因为这些节点不存储任何行数据(只存储目录项用来做路由查找)。作为对维护一整个大文件方案的替换,(使用树的结构来组织行数据)我们可以快速执行插入、删除和查找。
| 非排序数组行数据 | 排序数组行数据 | Tree of nodes | |
|---|---|---|---|
| 页内包含 | 只有数据 | 只有数据 | 元数据, 主键, 数据 |
| 每页行数 | more | more | fewer |
| 插入 | O(1) | O(n) | O(log(n)) |
| 删除 | O(n) | O(n) | O(log(n)) |
| id查找 | O(n) | O(log(n)) | O(log(n)) |
节点头的格式(Node Header Format)
叶子节点和内部节点有不同的布局格式。这里创建一个enum类型用来追踪节点的类型(node type):
+typedef enum { NODE_INTERNAL, NODE_LEAF } NodeType;
每个节点对应一个page。内部节点通过存储子节点的 page numbrer 来指向其子节点。btree 向 pager 请求特定的 page number ,然后将获取到的指针放到 page cache。数据页(page)是按照 page number 的顺序一个接一个存储在数据库文件中的。
节点需要在它的头部(header,page的开头位置)存放一些元数据。每个节点存储它自己的节点类型,也就是它是不是根节点,还有一个指向父节点的指针(这个指针用来通过父节点来查找同一层级的其他节点,即兄弟节点)。我为每个节点的头部(node header)的字段(field)的大小和偏移位置定义了一些常量:
+/*
+ * Common Node Header Layout
+ */
+const uint32_t NODE_TYPE_SIZE = sizeof(uint8_t);
+const uint32_t NODE_TYPE_OFFSET = 0;
+const uint32_t IS_ROOT_SIZE = sizeof(uint8_t);
+const uint32_t IS_ROOT_OFFSET = NODE_TYPE_SIZE;
+const uint32_t PARENT_POINTER_SIZE = sizeof(uint32_t);
+const uint32_t PARENT_POINTER_OFFSET = IS_ROOT_OFFSET + IS_ROOT_SIZE;
+const uint8_t COMMON_NODE_HEADER_SIZE =
+ NODE_TYPE_SIZE + IS_ROOT_SIZE + PARENT_POINTER_SIZE;
叶子节点格式(Leaf Node Format)
除了这些常见头部字段(header fields),叶子节点需要存储它包含有多少单元格(cells)。每个单元格里存放的是一个键值对儿。
+/*
+ * Leaf Node Header Layout
+ */
+const uint32_t LEAF_NODE_NUM_CELLS_SIZE = sizeof(uint32_t);
+const uint32_t LEAF_NODE_NUM_CELLS_OFFSET = COMMON_NODE_HEADER_SIZE;
+const uint32_t LEAF_NODE_HEADER_SIZE =
+ COMMON_NODE_HEADER_SIZE + LEAF_NODE_NUM_CELLS_SIZE;
叶子节点主体就是一个单元格的数组(一个个键值对儿排列为数组),每个单元格是一个key跟随一个value(一个序列化的行)。
+/*
+ * Leaf Node Body Layout
+ */
+const uint32_t LEAF_NODE_KEY_SIZE = sizeof(uint32_t);
+const uint32_t LEAF_NODE_KEY_OFFSET = 0;
+const uint32_t LEAF_NODE_VALUE_SIZE = ROW_SIZE;
+const uint32_t LEAF_NODE_VALUE_OFFSET =
+ LEAF_NODE_KEY_OFFSET + LEAF_NODE_KEY_SIZE;
+const uint32_t LEAF_NODE_CELL_SIZE = LEAF_NODE_KEY_SIZE + LEAF_NODE_VALUE_SIZE;
+const uint32_t LEAF_NODE_SPACE_FOR_CELLS = PAGE_SIZE - LEAF_NODE_HEADER_SIZE;
+const uint32_t LEAF_NODE_MAX_CELLS =
+ LEAF_NODE_SPACE_FOR_CELLS / LEAF_NODE_CELL_SIZE;
根据这些常量,下面是叶子节点布局格式看起来的样子:
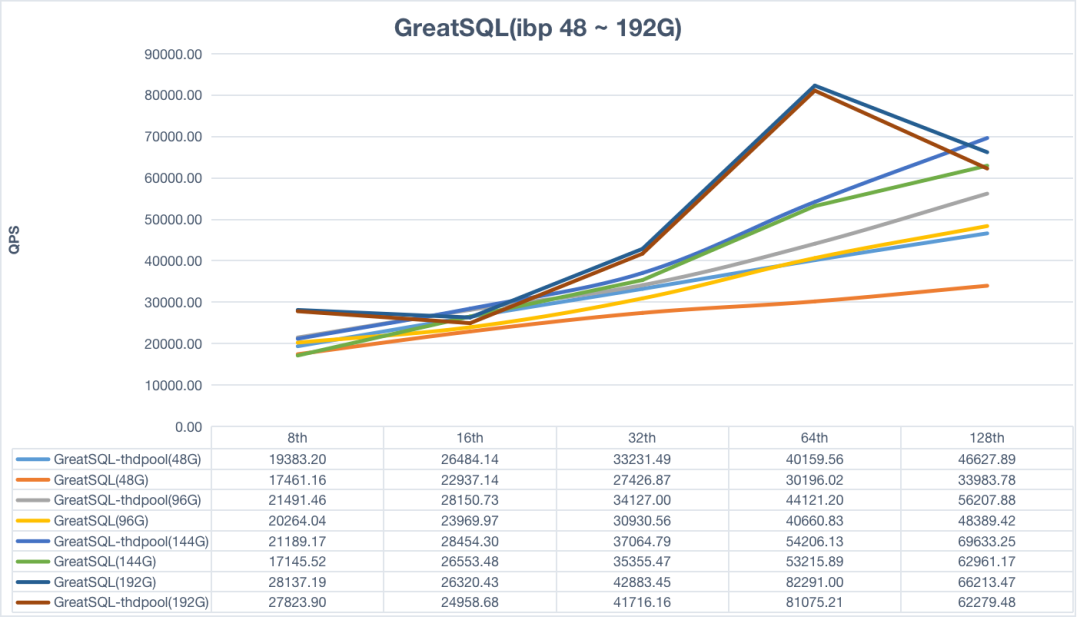
我们叶子节点的格式
在节点头部使用一整个字节来表示 boolean 类型值有点低效,但是这会让编写代码来访问这些值变得方便。
也需要注意到在结尾处有一些空间浪费。我们在节点头部之后尽量多的来存储单元格,但是剩下的空间可能不足以存放一个整个的单元格。这种情况我们将其留空来避免在节点之间拆分单元格(一个单元格不能跨两个节点)。
访问叶子节点(Accessing Leaf Node Fields)
访问keys、values和元数据都涉及到我们刚刚定义的常量的指针算法。
+uint32_t* leaf_node_num_cells(void* node) {
+ return node + LEAF_NODE_NUM_CELLS_OFFSET;
+}
+
+void* leaf_node_cell(void* node, uint32_t cell_num) {
+ return node + LEAF_NODE_HEADER_SIZE + cell_num * LEAF_NODE_CELL_SIZE;
+}
+
+uint32_t* leaf_node_key(void* node, uint32_t cell_num) {
+ return leaf_node_cell(node, cell_num);
+}
+
+void* leaf_node_value(void* node, uint32_t cell_num) {
+ return leaf_node_cell(node, cell_num) + LEAF_NODE_KEY_SIZE;
+}
+
+void initialize_leaf_node(void* node) { *leaf_node_num_cells(node) = 0; }
+
这些方法返回指向相关值的指针,因此它们既可以用作 getter,也可以用作 setter。
修改 Pager 和 Table Objects
即使页不是满的,每个节点也正好占用一个页的空间。这意味着我们的 pager 不再需要读/写页的一部分(而是整存整取一整个页)。
-void pager_flush(Pager* pager, uint32_t page_num, uint32_t size) {
+void pager_flush(Pager* pager, uint32_t page_num) {
if (pager->pages[page_num] == NULL) {
printf("Tried to flush null page\n");
exit(EXIT_FAILURE);
@@ -242,7 +337,7 @@ void pager_flush(Pager* pager, uint32_t page_num, uint32_t size) {
}
ssize_t bytes_written =
- write(pager->file_descriptor, pager->pages[page_num], size);
+ write(pager->file_descriptor, pager->pages[page_num], PAGE_SIZE);
if (bytes_written == -1) {
printf("Error writing: %d\n", errno);
void db_close(Table* table) {
Pager* pager = table->pager;
- uint32_t num_full_pages = table->num_rows / ROWS_PER_PAGE;
- for (uint32_t i = 0; i < num_full_pages; i++) {
+ for (uint32_t i = 0; i < pager->num_pages; i++) {
if (pager->pages[i] == NULL) {
continue;
}
- pager_flush(pager, i, PAGE_SIZE);
+ pager_flush(pager, i);
free(pager->pages[i]);
pager->pages[i] = NULL;
}
- // There may be a partial page to write to the end of the file
- // This should not be needed after we switch to a B-tree
- uint32_t num_additional_rows = table->num_rows % ROWS_PER_PAGE;
- if (num_additional_rows > 0) {
- uint32_t page_num = num_full_pages;
- if (pager->pages[page_num] != NULL) {
- pager_flush(pager, page_num, num_additional_rows * ROW_SIZE);
- free(pager->pages[page_num]);
- pager->pages[page_num] = NULL;
- }
- }
-
int result = close(pager->file_descriptor);
if (result == -1) {
printf("Error closing db file.\n");
现在,在数据库中存储 page number 比存储行数更有意义。page number 需要与 pager 对象相关联,而不是与表关联,因为这是数据库用到的页的数量,而不是特定的表用到的。btree 是通过根节点的 page number 来识别的,所以表对象需要跟踪 page number。
const uint32_t PAGE_SIZE = 4096;
const uint32_t TABLE_MAX_PAGES = 100;
-const uint32_t ROWS_PER_PAGE = PAGE_SIZE / ROW_SIZE;
-const uint32_t TABLE_MAX_ROWS = ROWS_PER_PAGE * TABLE_MAX_PAGES;
typedef struct {
int file_descriptor;
uint32_t file_length;
+ uint32_t num_pages;
void* pages[TABLE_MAX_PAGES];
} Pager;
typedef struct {
Pager* pager;
- uint32_t num_rows;
+ uint32_t root_page_num;
} Table;
@@ -127,6 +200,10 @@ void* get_page(Pager* pager, uint32_t page_num) {
}
pager->pages[page_num] = page;
+
+ if (page_num >= pager->num_pages) {
+ pager->num_pages = page_num + 1;
+ }
}
return pager->pages[page_num];
@@ -184,6 +269,12 @@ Pager* pager_open(const char* filename) {
Pager* pager = malloc(sizeof(Pager));
pager->file_descriptor = fd;
pager->file_length = file_length;
+ pager->num_pages = (file_length / PAGE_SIZE);
+
+ if (file_length % PAGE_SIZE != 0) {
+ printf("Db file is not a whole number of pages. Corrupt file.\n");
+ exit(EXIT_FAILURE);
+ }
for (uint32_t i = 0; i < TABLE_MAX_PAGES; i++) {
pager->pages[i] = NULL;
修改为Cursor Object
游标表示表中的一个位置。当我们的表是一个简单的行数组时(array of rows),我们使用给出的行号就可以访问行数据。现在,表变成了一棵 btree,我们通过节点的 page number 和节点内的单元格号(cell number)来识别一个位置。
typedef struct {
Table* table;
- uint32_t row_num;
+ uint32_t page_num;
+ uint32_t cell_num;
bool end_of_table; // Indicates a position one past the last element
} Cursor;
Cursor* table_start(Table* table) {
Cursor* cursor = malloc(sizeof(Cursor));
cursor->table = table;
- cursor->row_num = 0;
- cursor->end_of_table = (table->num_rows == 0);
+ cursor->page_num = table->root_page_num;
+ cursor->cell_num = 0;
+
+ void* root_node = get_page(table->pager, table->root_page_num);
+ uint32_t num_cells = *leaf_node_num_cells(root_node);
+ cursor->end_of_table = (num_cells == 0);
return cursor;
}
Cursor* table_end(Table* table) {
Cursor* cursor = malloc(sizeof(Cursor));
cursor->table = table;
- cursor->row_num = table->num_rows;
+ cursor->page_num = table->root_page_num;
+
+ void* root_node = get_page(table->pager, table->root_page_num);
+ uint32_t num_cells = *leaf_node_num_cells(root_node);
+ cursor->cell_num = num_cells;
cursor->end_of_table = true;
return cursor;
}
void* cursor_value(Cursor* cursor) {
- uint32_t row_num = cursor->row_num;
- uint32_t page_num = row_num / ROWS_PER_PAGE;
+ uint32_t page_num = cursor->page_num;
void* page = get_page(cursor->table->pager, page_num);
- uint32_t row_offset = row_num % ROWS_PER_PAGE;
- uint32_t byte_offset = row_offset * ROW_SIZE;
- return page + byte_offset;
+ return leaf_node_value(page, cursor->cell_num);
}
void cursor_advance(Cursor* cursor) {
- cursor->row_num += 1;
- if (cursor->row_num >= cursor->table->num_rows) {
+ uint32_t page_num = cursor->page_num;
+ void* node = get_page(cursor->table->pager, page_num);
+
+ cursor->cell_num += 1;
+ if (cursor->cell_num >= (*leaf_node_num_cells(node))) {
cursor->end_of_table = true;
}
}
叶子节点(Leaf Node)的插入操作
在本文中,我们只是完整的实现获取一个单节点的 btree。回想一下上一篇文章内容,一棵 btree 是从一个空的叶子节点开始的:
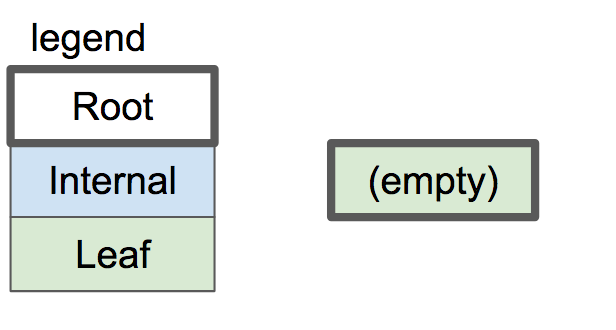
空btree
键值对儿可以被插入到叶子节点中,直到叶子节点变满达到存储限制。
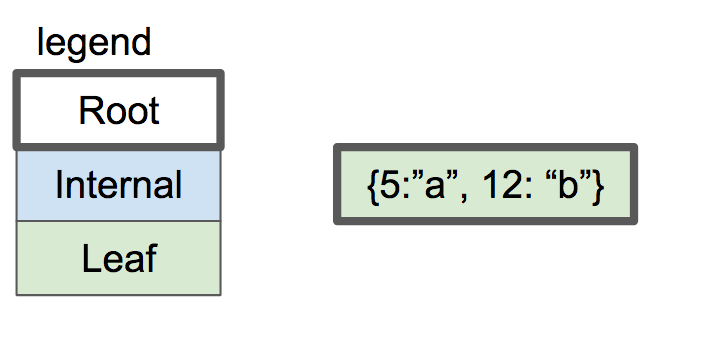
一个节点的btree
当我们第一次打开数据库时(初次启动时),数据库文件是空的,没有任何用户数据,所以我们初始化 page 0 为一个空的叶子节点(同时也是根节点)。
Table* db_open(const char* filename) {
Pager* pager = pager_open(filename);
- uint32_t num_rows = pager->file_length / ROW_SIZE;
Table* table = malloc(sizeof(Table));
table->pager = pager;
- table->num_rows = num_rows;
+ table->root_page_num = 0;
+
+ if (pager->num_pages == 0) {
+ // New database file. Initialize page 0 as leaf node.
+ void* root_node = get_page(pager, 0);
+ initialize_leaf_node(root_node);
+ }
return table;
}
接下来我们定义一个函数用来插入一个键值对儿到一个叶子节点中。它将采用游标来作为需要插入键值对儿的位置的表示。
+void leaf_node_insert(Cursor* cursor, uint32_t key, Row* value) {
+ void* node = get_page(cursor->table->pager, cursor->page_num);
+
+ uint32_t num_cells = *leaf_node_num_cells(node);
+ if (num_cells >= LEAF_NODE_MAX_CELLS) {
+ // Node full
+ printf("Need to implement splitting a leaf node.\n");
+ exit(EXIT_FAILURE);
+ }
+
+ if (cursor->cell_num < num_cells) {
+ // Make room for new cell
+ for (uint32_t i = num_cells; i > cursor->cell_num; i--) {
+ memcpy(leaf_node_cell(node, i), leaf_node_cell(node, i - 1),
+ LEAF_NODE_CELL_SIZE);
+ }
+ }
+
+ *(leaf_node_num_cells(node)) += 1;
+ *(leaf_node_key(node, cursor->cell_num)) = key;
+ serialize_row(value, leaf_node_value(node, cursor->cell_num));
+}
+
我们还没有实现节点的分裂,所以暂时在节点变满的时候先报错处理。接下来我们把单元格(cells)向右移动一个空间(one space)来给新的单元格让出位置。然后我们在空位置写入键值对儿。
因为目前我们是假设 btree 只有一个节点,我们的 execute_insert() 函数只需要调用这个helper方法(调用leaf_node_insert()插入数据):
ExecuteResult execute_insert(Statement* statement, Table* table) {
- if (table->num_rows >= TABLE_MAX_ROWS) {
+ void* node = get_page(table->pager, table->root_page_num);
+ if ((*leaf_node_num_cells(node) >= LEAF_NODE_MAX_CELLS)) {
return EXECUTE_TABLE_FULL;
}
Row* row_to_insert = &(statement->row_to_insert);
Cursor* cursor = table_end(table);
- serialize_row(row_to_insert, cursor_value(cursor));
- table->num_rows += 1;
+ leaf_node_insert(cursor, row_to_insert->id, row_to_insert);
free(cursor);
做了这些修改后,我们的数据库就能像以前一样运行了。除了现在它会很快地返回“Table Full”的错误,因为我们现在还不能拆分根节点。
叶子节点可以存储多少行呢?
打印常量的命令
我增加了一个新的 meta command,来打印一些插入操作时的变量。
+void print_constants() {
+ printf("ROW_SIZE: %d\n", ROW_SIZE);
+ printf("COMMON_NODE_HEADER_SIZE: %d\n", COMMON_NODE_HEADER_SIZE);
+ printf("LEAF_NODE_HEADER_SIZE: %d\n", LEAF_NODE_HEADER_SIZE);
+ printf("LEAF_NODE_CELL_SIZE: %d\n", LEAF_NODE_CELL_SIZE);
+ printf("LEAF_NODE_SPACE_FOR_CELLS: %d\n", LEAF_NODE_SPACE_FOR_CELLS);
+ printf("LEAF_NODE_MAX_CELLS: %d\n", LEAF_NODE_MAX_CELLS);
+}
+
@@ -294,6 +376,14 @@ MetaCommandResult do_meta_command(InputBuffer* input_buffer, Table* table) {
if (strcmp(input_buffer->buffer, ".exit") == 0) {
db_close(table);
exit(EXIT_SUCCESS);
+ } else if (strcmp(input_buffer->buffer, ".constants") == 0) {
+ printf("Constants:\n");
+ print_constants();
+ return META_COMMAND_SUCCESS;
} else {
return META_COMMAND_UNRECOGNIZED_COMMAND;
}
我还加了一些测试,这样我们就能在变量发生变化时获取报警信息。
+ it 'prints constants' do
+ script = [
+ ".constants",
+ ".exit",
+ ]
+ result = run_script(script)
+
+ expect(result).to match_array([
+ "db > Constants:",
+ "ROW_SIZE: 293",
+ "COMMON_NODE_HEADER_SIZE: 6",
+ "LEAF_NODE_HEADER_SIZE: 10",
+ "LEAF_NODE_CELL_SIZE: 297",
+ "LEAF_NODE_SPACE_FOR_CELLS: 4086",
+ "LEAF_NODE_MAX_CELLS: 13",
+ "db > ",
+ ])
+ end
经过测试,可以看出我们的 table 现在可以存储 13 行数据。
Tree 可视化
为了有助于 debug 和可视化,我又增加了一个 meta command 来打印 btree 的表示形式。
+void print_leaf_node(void* node) {
+ uint32_t num_cells = *leaf_node_num_cells(node);
+ printf("leaf (size %d)\n", num_cells);
+ for (uint32_t i = 0; i < num_cells; i++) {
+ uint32_t key = *leaf_node_key(node, i);
+ printf(" - %d : %d\n", i, key);
+ }
+}
+
@@ -294,6 +376,14 @@ MetaCommandResult do_meta_command(InputBuffer* input_buffer, Table* table) {
if (strcmp(input_buffer->buffer, ".exit") == 0) {
db_close(table);
exit(EXIT_SUCCESS);
+ } else if (strcmp(input_buffer->buffer, ".btree") == 0) {
+ printf("Tree:\n");
+ print_leaf_node(get_page(table->pager, 0));
+ return META_COMMAND_SUCCESS;
} else if (strcmp(input_buffer->buffer, ".constants") == 0) {
printf("Constants:\n");
print_constants();
return META_COMMAND_SUCCESS;
} else {
return META_COMMAND_UNRECOGNIZED_COMMAND;
}
然后进行测试:
+ it 'allows printing out the structure of a one-node btree' do
+ script = [3, 1, 2].map do |i|
+ "insert #{i} user#{i} person#{i}@example.com"
+ end
+ script << ".btree"
+ script << ".exit"
+ result = run_script(script)
+
+ expect(result).to match_array([
+ "db > Executed.",
+ "db > Executed.",
+ "db > Executed.",
+ "db > Tree:",
+ "leaf (size 3)",
+ " - 0 : 3",
+ " - 1 : 1",
+ " - 2 : 2",
+ "db > "
+ ])
+ end
啊哦,我们还是没有按照排序的顺序来存储行。你会注意到 execute_insert() 函数在叶子节点中插入时的位置就是 table_end() 函数返回的位置。所以数据是按照我们插入的顺序存储的,这是跟以前一样的。
后续
这些(改变)看起来像是倒退了一步。我们的数据库现在存储的行数据量要比以前要少很多,并且我们仍然存储的是无序的行数据。但是就像我在开始说的,这是一个巨大的变化,重要的是要将这些改变分解为方便管理的几步来慢慢实现。
下一次,我们将实现通过主键来查找一行记录的功能,并且开始让行数据存储变得有序。
代码变更比较
@@ -62,29 +62,101 @@ const uint32_t ROW_SIZE = ID_SIZE + USERNAME_SIZE + EMAIL_SIZE;
const uint32_t PAGE_SIZE = 4096;
#define TABLE_MAX_PAGES 100
-const uint32_t ROWS_PER_PAGE = PAGE_SIZE / ROW_SIZE;
-const uint32_t TABLE_MAX_ROWS = ROWS_PER_PAGE * TABLE_MAX_PAGES;
typedef struct {
int file_descriptor;
uint32_t file_length;
+ uint32_t num_pages;
void* pages[TABLE_MAX_PAGES];
} Pager;
typedef struct {
Pager* pager;
- uint32_t num_rows;
+ uint32_t root_page_num;
} Table;
typedef struct {
Table* table;
- uint32_t row_num;
+ uint32_t page_num;
+ uint32_t cell_num;
bool end_of_table; // Indicates a position one past the last element
} Cursor;
+typedef enum { NODE_INTERNAL, NODE_LEAF } NodeType;
+
+/*
+ * Common Node Header Layout
+ */
+const uint32_t NODE_TYPE_SIZE = sizeof(uint8_t);
+const uint32_t NODE_TYPE_OFFSET = 0;
+const uint32_t IS_ROOT_SIZE = sizeof(uint8_t);
+const uint32_t IS_ROOT_OFFSET = NODE_TYPE_SIZE;
+const uint32_t PARENT_POINTER_SIZE = sizeof(uint32_t);
+const uint32_t PARENT_POINTER_OFFSET = IS_ROOT_OFFSET + IS_ROOT_SIZE;
+const uint8_t COMMON_NODE_HEADER_SIZE =
+ NODE_TYPE_SIZE + IS_ROOT_SIZE + PARENT_POINTER_SIZE;
+
+/*
+ * Leaf Node Header Layout
+ */
+const uint32_t LEAF_NODE_NUM_CELLS_SIZE = sizeof(uint32_t);
+const uint32_t LEAF_NODE_NUM_CELLS_OFFSET = COMMON_NODE_HEADER_SIZE;
+const uint32_t LEAF_NODE_HEADER_SIZE =
+ COMMON_NODE_HEADER_SIZE + LEAF_NODE_NUM_CELLS_SIZE;
+
+/*
+ * Leaf Node Body Layout
+ */
+const uint32_t LEAF_NODE_KEY_SIZE = sizeof(uint32_t);
+const uint32_t LEAF_NODE_KEY_OFFSET = 0;
+const uint32_t LEAF_NODE_VALUE_SIZE = ROW_SIZE;
+const uint32_t LEAF_NODE_VALUE_OFFSET =
+ LEAF_NODE_KEY_OFFSET + LEAF_NODE_KEY_SIZE;
+const uint32_t LEAF_NODE_CELL_SIZE = LEAF_NODE_KEY_SIZE + LEAF_NODE_VALUE_SIZE;
+const uint32_t LEAF_NODE_SPACE_FOR_CELLS = PAGE_SIZE - LEAF_NODE_HEADER_SIZE;
+const uint32_t LEAF_NODE_MAX_CELLS =
+ LEAF_NODE_SPACE_FOR_CELLS / LEAF_NODE_CELL_SIZE;
+
+uint32_t* leaf_node_num_cells(void* node) {
+ return node + LEAF_NODE_NUM_CELLS_OFFSET;
+}
+
+void* leaf_node_cell(void* node, uint32_t cell_num) {
+ return node + LEAF_NODE_HEADER_SIZE + cell_num * LEAF_NODE_CELL_SIZE;
+}
+
+uint32_t* leaf_node_key(void* node, uint32_t cell_num) {
+ return leaf_node_cell(node, cell_num);
+}
+
+void* leaf_node_value(void* node, uint32_t cell_num) {
+ return leaf_node_cell(node, cell_num) + LEAF_NODE_KEY_SIZE;
+}
+
+void print_constants() {
+ printf("ROW_SIZE: %d\n", ROW_SIZE);
+ printf("COMMON_NODE_HEADER_SIZE: %d\n", COMMON_NODE_HEADER_SIZE);
+ printf("LEAF_NODE_HEADER_SIZE: %d\n", LEAF_NODE_HEADER_SIZE);
+ printf("LEAF_NODE_CELL_SIZE: %d\n", LEAF_NODE_CELL_SIZE);
+ printf("LEAF_NODE_SPACE_FOR_CELLS: %d\n", LEAF_NODE_SPACE_FOR_CELLS);
+ printf("LEAF_NODE_MAX_CELLS: %d\n", LEAF_NODE_MAX_CELLS);
+}
+
+void print_leaf_node(void* node) {
+ uint32_t num_cells = *leaf_node_num_cells(node);
+ printf("leaf (size %d)\n", num_cells);
+ for (uint32_t i = 0; i < num_cells; i++) {
+ uint32_t key = *leaf_node_key(node, i);
+ printf(" - %d : %d\n", i, key);
+ }
+}
+
void print_row(Row* row) {
printf("(%d, %s, %s)\n", row->id, row->username, row->email);
}
@@ -101,6 +173,8 @@ void deserialize_row(void *source, Row* destination) {
memcpy(&(destination->email), source + EMAIL_OFFSET, EMAIL_SIZE);
}
+void initialize_leaf_node(void* node) { *leaf_node_num_cells(node) = 0; }
+
void* get_page(Pager* pager, uint32_t page_num) {
if (page_num > TABLE_MAX_PAGES) {
printf("Tried to fetch page number out of bounds. %d > %d\n", page_num,
@@ -128,6 +202,10 @@ void* get_page(Pager* pager, uint32_t page_num) {
}
pager->pages[page_num] = page;
+
+ if (page_num >= pager->num_pages) {
+ pager->num_pages = page_num + 1;
+ }
}
return pager->pages[page_num];
@@ -136,8 +214,12 @@ void* get_page(Pager* pager, uint32_t page_num) {
Cursor* table_start(Table* table) {
Cursor* cursor = malloc(sizeof(Cursor));
cursor->table = table;
- cursor->row_num = 0;
- cursor->end_of_table = (table->num_rows == 0);
+ cursor->page_num = table->root_page_num;
+ cursor->cell_num = 0;
+
+ void* root_node = get_page(table->pager, table->root_page_num);
+ uint32_t num_cells = *leaf_node_num_cells(root_node);
+ cursor->end_of_table = (num_cells == 0);
return cursor;
}
@@ -145,24 +227,28 @@ Cursor* table_start(Table* table) {
Cursor* table_end(Table* table) {
Cursor* cursor = malloc(sizeof(Cursor));
cursor->table = table;
- cursor->row_num = table->num_rows;
+ cursor->page_num = table->root_page_num;
+
+ void* root_node = get_page(table->pager, table->root_page_num);
+ uint32_t num_cells = *leaf_node_num_cells(root_node);
+ cursor->cell_num = num_cells;
cursor->end_of_table = true;
return cursor;
}
void* cursor_value(Cursor* cursor) {
- uint32_t row_num = cursor->row_num;
- uint32_t page_num = row_num / ROWS_PER_PAGE;
+ uint32_t page_num = cursor->page_num;
void* page = get_page(cursor->table->pager, page_num);
- uint32_t row_offset = row_num % ROWS_PER_PAGE;
- uint32_t byte_offset = row_offset * ROW_SIZE;
- return page + byte_offset;
+ return leaf_node_value(page, cursor->cell_num);
}
void cursor_advance(Cursor* cursor) {
- cursor->row_num += 1;
- if (cursor->row_num >= cursor->table->num_rows) {
+ uint32_t page_num = cursor->page_num;
+ void* node = get_page(cursor->table->pager, page_num);
+
+ cursor->cell_num += 1;
+ if (cursor->cell_num >= (*leaf_node_num_cells(node))) {
cursor->end_of_table = true;
}
}
@@ -185,6 +271,12 @@ Pager* pager_open(const char* filename) {
Pager* pager = malloc(sizeof(Pager));
pager->file_descriptor = fd;
pager->file_length = file_length;
+ pager->num_pages = (file_length / PAGE_SIZE);
+
+ if (file_length % PAGE_SIZE != 0) {
+ printf("Db file is not a whole number of pages. Corrupt file.\n");
+ exit(EXIT_FAILURE);
+ }
for (uint32_t i = 0; i < TABLE_MAX_PAGES; i++) {
pager->pages[i] = NULL;
@@ -194,11 +285,15 @@ Pager* pager_open(const char* filename) {
@@ -195,11 +287,16 @@ Pager* pager_open(const char* filename) {
Table* db_open(const char* filename) {
Pager* pager = pager_open(filename);
- uint32_t num_rows = pager->file_length / ROW_SIZE;
Table* table = malloc(sizeof(Table));
table->pager = pager;
- table->num_rows = num_rows;
+ table->root_page_num = 0;
+
+ if (pager->num_pages == 0) {
+ // New database file. Initialize page 0 as leaf node.
+ void* root_node = get_page(pager, 0);
+ initialize_leaf_node(root_node);
+ }
return table;
}
@@ -234,7 +331,7 @@ void close_input_buffer(InputBuffer* input_buffer) {
free(input_buffer);
}
-void pager_flush(Pager* pager, uint32_t page_num, uint32_t size) {
+void pager_flush(Pager* pager, uint32_t page_num) {
if (pager->pages[page_num] == NULL) {
printf("Tried to flush null page\n");
exit(EXIT_FAILURE);
@@ -242,7 +337,7 @@ void pager_flush(Pager* pager, uint32_t page_num, uint32_t size) {
@@ -249,7 +346,7 @@ void pager_flush(Pager* pager, uint32_t page_num, uint32_t size) {
}
ssize_t bytes_written =
- write(pager->file_descriptor, pager->pages[page_num], size);
+ write(pager->file_descriptor, pager->pages[page_num], PAGE_SIZE);
if (bytes_written == -1) {
printf("Error writing: %d\n", errno);
@@ -252,29 +347,16 @@ void pager_flush(Pager* pager, uint32_t page_num, uint32_t size) {
@@ -260,29 +357,16 @@ void pager_flush(Pager* pager, uint32_t page_num, uint32_t size) {
void db_close(Table* table) {
Pager* pager = table->pager;
- uint32_t num_full_pages = table->num_rows / ROWS_PER_PAGE;
- for (uint32_t i = 0; i < num_full_pages; i++) {
+ for (uint32_t i = 0; i < pager->num_pages; i++) {
if (pager->pages[i] == NULL) {
continue;
}
- pager_flush(pager, i, PAGE_SIZE);
+ pager_flush(pager, i);
free(pager->pages[i]);
pager->pages[i] = NULL;
}
- // There may be a partial page to write to the end of the file
- // This should not be needed after we switch to a B-tree
- uint32_t num_additional_rows = table->num_rows % ROWS_PER_PAGE;
- if (num_additional_rows > 0) {
- uint32_t page_num = num_full_pages;
- if (pager->pages[page_num] != NULL) {
- pager_flush(pager, page_num, num_additional_rows * ROW_SIZE);
- free(pager->pages[page_num]);
- pager->pages[page_num] = NULL;
- }
- }
-
int result = close(pager->file_descriptor);
if (result == -1) {
printf("Error closing db file.\n");
@@ -305,6 +389,14 @@ MetaCommandResult do_meta_command(InputBuffer* input_buffer, Table *table) {
if (strcmp(input_buffer->buffer, ".exit") == 0) {
db_close(table);
exit(EXIT_SUCCESS);
+ } else if (strcmp(input_buffer->buffer, ".btree") == 0) {
+ printf("Tree:\n");
+ print_leaf_node(get_page(table->pager, 0));
+ return META_COMMAND_SUCCESS;
+ } else if (strcmp(input_buffer->buffer, ".constants") == 0) {
+ printf("Constants:\n");
+ print_constants();
+ return META_COMMAND_SUCCESS;
} else {
return META_COMMAND_UNRECOGNIZED_COMMAND;
}
@@ -354,16 +446,39 @@ PrepareResult prepare_statement(InputBuffer* input_buffer,
return PREPARE_UNRECOGNIZED_STATEMENT;
}
+void leaf_node_insert(Cursor* cursor, uint32_t key, Row* value) {
+ void* node = get_page(cursor->table->pager, cursor->page_num);
+
+ uint32_t num_cells = *leaf_node_num_cells(node);
+ if (num_cells >= LEAF_NODE_MAX_CELLS) {
+ // Node full
+ printf("Need to implement splitting a leaf node.\n");
+ exit(EXIT_FAILURE);
+ }
+
+ if (cursor->cell_num < num_cells) {
+ // Make room for new cell
+ for (uint32_t i = num_cells; i > cursor->cell_num; i--) {
+ memcpy(leaf_node_cell(node, i), leaf_node_cell(node, i - 1),
+ LEAF_NODE_CELL_SIZE);
+ }
+ }
+
+ *(leaf_node_num_cells(node)) += 1;
+ *(leaf_node_key(node, cursor->cell_num)) = key;
+ serialize_row(value, leaf_node_value(node, cursor->cell_num));
+}
+
ExecuteResult execute_insert(Statement* statement, Table* table) {
- if (table->num_rows >= TABLE_MAX_ROWS) {
+ void* node = get_page(table->pager, table->root_page_num);
+ if ((*leaf_node_num_cells(node) >= LEAF_NODE_MAX_CELLS)) {
return EXECUTE_TABLE_FULL;
}
Row* row_to_insert = &(statement->row_to_insert);
Cursor* cursor = table_end(table);
- serialize_row(row_to_insert, cursor_value(cursor));
- table->num_rows += 1;
+ leaf_node_insert(cursor, row_to_insert->id, row_to_insert);
free(cursor);
下面是测试过程:
+ it 'allows printing out the structure of a one-node btree' do
+ script = [3, 1, 2].map do |i|
+ "insert #{i} user#{i} person#{i}@example.com"
+ end
+ script << ".btree"
+ script << ".exit"
+ result = run_script(script)
+
+ expect(result).to match_array([
+ "db > Executed.",
+ "db > Executed.",
+ "db > Executed.",
+ "db > Tree:",
+ "leaf (size 3)",
+ " - 0 : 3",
+ " - 1 : 1",
+ " - 2 : 2",
+ "db > "
+ ])
+ end
+
+ it 'prints constants' do
+ script = [
+ ".constants",
+ ".exit",
+ ]
+ result = run_script(script)
+
+ expect(result).to match_array([
+ "db > Constants:",
+ "ROW_SIZE: 293",
+ "COMMON_NODE_HEADER_SIZE: 6",
+ "LEAF_NODE_HEADER_SIZE: 10",
+ "LEAF_NODE_CELL_SIZE: 297",
+ "LEAF_NODE_SPACE_FOR_CELLS: 4086",
+ "LEAF_NODE_MAX_CELLS: 13",
+ "db > ",
+ ])
+ end
end
Enjoy GreatSQL 😃
关于 GreatSQL
GreatSQL是由万里数据库维护的MySQL分支,专注于提升MGR可靠性及性能,支持InnoDB并行查询特性,是适用于金融级应用的MySQL分支版本。
相关链接: GreatSQL社区 Gitee GitHub Bilibili
GreatSQL社区:
社区博客有奖征稿详情:https://greatsql.cn/thread-100-1-1.html

技术交流群:
微信:扫码添加
GreatSQL社区助手微信好友,发送验证信息加群。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号