
实现一个简单的Database3(译文)
前文回顾
实现一个简单的Database3(译文)
译注:cstsck在github维护了一个简单的、类似sqlite的数据库实现,通过这个简单的项目,可以很好的理解数据库是如何运行的。本文是第三篇,主要是实现数据库的实现内存中的数据结构并存储数据
Part 3 在内存中,只追加的单表数据库
我们从一个小型的,有许多限制的数据库开始。现在数据库将:
- 支持两个操作:插入一行并打印所有行
- 数据驻留在内存中(没有持久化到磁盘)
- 支持单个、硬编码的表
我们的硬编码表将用来存储用户数据,看起来就行下面展示的这样:
| column | type |
|---|---|
| id | integer |
| username | varchar(32) |
| varchar(255) |
这是一个简单的方案,但是它将让我们的数据库能够支持不同的数据类型和不同大小的文本数据类型。插入语句现在看起来像下面这样:
insert 1 cstack foo@bar.com
这意味我们需要升级prepare_statement()函数来解析参数:
if (strncmp(input_buffer->buffer, "insert", 6) == 0) {
statement->type = STATEMENT_INSERT;
+ int args_assigned = sscanf(
+ input_buffer->buffer, "insert %d %s %s", &(statement->row_to_insert.id),
+ statement->row_to_insert.username, statement->row_to_insert.email);
+ if (args_assigned < 3) {
+ return PREPARE_SYNTAX_ERROR;
+ }
return PREPARE_SUCCESS;
}
if (strcmp(input_buffer->buffer, "select") == 0) {
我们把这些解析出的的参数存储到Statement对象中的一个新的数据结构Row中。
+#define COLUMN_USERNAME_SIZE 32
+#define COLUMN_EMAIL_SIZE 255
+typedef struct {
+ uint32_t id;
+ char username[COLUMN_USERNAME_SIZE];
+ char email[COLUMN_EMAIL_SIZE];
+} Row;
+
typedef struct {
StatementType type;
+ Row row_to_insert; // only used by insert statement
} Statement;
现在我们需要copy这些数据到其他一些代表table的数据结构中。SQLite为了支持快速查找、插入和删除操作而使用B-tree。我们将从一些简单的开始。像B-tree,它把行数据分组成页(pages),但是为了替换把这些页(pages)组织成一颗树的这种方法,这里我们把页来组织成数组(array)。
这是我的计划:
- 存储行数据到叫做页(pages)的内存块中
- 每页尽量多的去存储适合他的大小的数据(在页的大小范围内,尽量多的存储数据)
- 在每页中行数据将被序列化为紧凑表示(compact representation)
- 页只有在需要时候才会被分配
- 保持固定大小的指针数组指向页
首先我们定义一个紧凑表示的行(row):
+#define size_of_attribute(Struct, Attribute) sizeof(((Struct*)0)->Attribute)
+
+const uint32_t ID_SIZE = size_of_attribute(Row, id);
+const uint32_t USERNAME_SIZE = size_of_attribute(Row, username);
+const uint32_t EMAIL_SIZE = size_of_attribute(Row, email);
+const uint32_t ID_OFFSET = 0;
+const uint32_t USERNAME_OFFSET = ID_OFFSET + ID_SIZE;
+const uint32_t EMAIL_OFFSET = USERNAME_OFFSET + USERNAME_SIZE;
+const uint32_t ROW_SIZE = ID_SIZE + USERNAME_SIZE + EMAIL_SIZE;
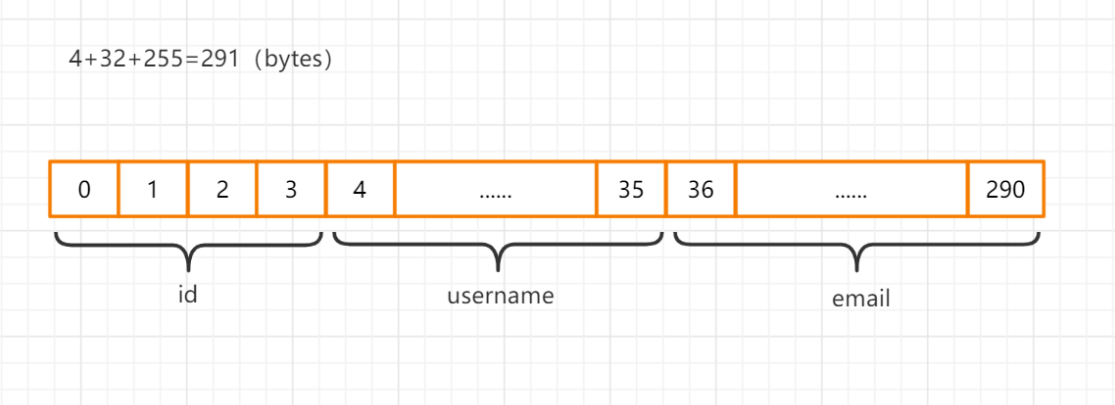
这意味着一个序列化的行的布局看起来就像下面这样:
| column | size (bytes) | offset |
|---|---|---|
| id | 4 | 0 |
| username | 32 | 4 |
| 255 | 36 | |
| total | 291 |
译注:画个图来直观的看一下这个行数据存储格式
我们还需要编码来转换紧凑表示。(即把数据序列化与反序列化)
+void serialize_row(Row* source, void* destination) {
+ memcpy(destination + ID_OFFSET, &(source->id), ID_SIZE);
+ memcpy(destination + USERNAME_OFFSET, &(source->username), USERNAME_SIZE);
+ memcpy(destination + EMAIL_OFFSET, &(source->email), EMAIL_SIZE);
+}
+
+void deserialize_row(void* source, Row* destination) {
+ memcpy(&(destination->id), source + ID_OFFSET, ID_SIZE);
+ memcpy(&(destination->username), source + USERNAME_OFFSET, USERNAME_SIZE);
+ memcpy(&(destination->email), source + EMAIL_OFFSET, EMAIL_SIZE);
+}
接下来,实现一个表的结构指向存储行的页并跟踪页中有多少行:
+const uint32_t PAGE_SIZE = 4096;
+#define TABLE_MAX_PAGES 100
+const uint32_t ROWS_PER_PAGE = PAGE_SIZE / ROW_SIZE;
+const uint32_t TABLE_MAX_ROWS = ROWS_PER_PAGE * TABLE_MAX_PAGES;
+
+typedef struct {
+ uint32_t num_rows;
+ void* pages[TABLE_MAX_PAGES];
+} Table;
我把数据页大小设定为4KB,因为它与大多数计算机架构的虚拟内存系统中使用数据页大小相同。这意味着数据库中的一个数据页的大小和系统中的一页大小正好相同。操作系统在把数据页移入或者移出内存的时候会作为一个完整的单位来操作,而不会拆散他们。
在分配page时我设置了一个很随意的限制,限制分配100个page。当切换到一个tree结构时,我们数据库的最大限制就只是受到系统文件的大小限制了(尽管我仍然是限制在内存中一次可以有多少page可以保持)。
行不能超出page的边界。由于page在内存中可能不会彼此相邻,这个假设可以让读/写行数据更简单。
说到这一点,下面是我们如何弄清楚在内存中去哪里读/写特定行。
+void* row_slot(Table* table, uint32_t row_num) {
+ uint32_t page_num = row_num / ROWS_PER_PAGE;
+ void* page = table->pages[page_num];
+ if (page == NULL) {
+ // Allocate memory only when we try to access page
+ page = table->pages[page_num] = malloc(PAGE_SIZE);
+ }
+ uint32_t row_offset = row_num % ROWS_PER_PAGE;
+ uint32_t byte_offset = row_offset * ROW_SIZE;
+ return page + byte_offset;
+}
现在我们通过execute_statement()函数可以从表结构中读/写了。
-void execute_statement(Statement* statement) {
+ExecuteResult execute_insert(Statement* statement, Table* table) {
+ if (table->num_rows >= TABLE_MAX_ROWS) {
+ return EXECUTE_TABLE_FULL;
+ }
+
+ Row* row_to_insert = &(statement->row_to_insert);
+
+ serialize_row(row_to_insert, row_slot(table, table->num_rows));
+ table->num_rows += 1;
+
+ return EXECUTE_SUCCESS;
+}
+
+ExecuteResult execute_select(Statement* statement, Table* table) {
+ Row row;
+ for (uint32_t i = 0; i < table->num_rows; i++) {
+ deserialize_row(row_slot(table, i), &row);
+ print_row(&row);
+ }
+ return EXECUTE_SUCCESS;
+}
+
+ExecuteResult execute_statement(Statement* statement, Table* table) {
switch (statement->type) {
case (STATEMENT_INSERT):
- printf("This is where we would do an insert.\n");
- break;
+ return execute_insert(statement, table);
case (STATEMENT_SELECT):
- printf("This is where we would do a select.\n");
- break;
+ return execute_select(statement, table);
}
}
最后,我们需要初始化table,创建各自的内存释放函数并且需要处理一些报错情况:
+ Table* new_table() {
+ Table* table = (Table*)malloc(sizeof(Table));
+ table->num_rows = 0;
+ for (uint32_t i = 0; i < TABLE_MAX_PAGES; i++) {
+ table->pages[i] = NULL;
+ }
+ return table;
+}
+
+void free_table(Table* table) {
+ for (int i = 0; table->pages[i]; i++) {
+ free(table->pages[i]);
+ }
+ free(table);
+}
在主函数中调用table初始化,并处理报错:
int main(int argc, char* argv[]) {
+ Table* table = new_table();
InputBuffer* input_buffer = new_input_buffer();
while (true) {
print_prompt();
@@ -105,13 +203,22 @@ int main(int argc, char* argv[]) {
switch (prepare_statement(input_buffer, &statement)) {
case (PREPARE_SUCCESS):
break;
+ case (PREPARE_SYNTAX_ERROR):
+ printf("Syntax error. Could not parse statement.\n");
+ continue;
case (PREPARE_UNRECOGNIZED_STATEMENT):
printf("Unrecognized keyword at start of '%s'.\n",
input_buffer->buffer);
continue;
}
- execute_statement(&statement);
- printf("Executed.\n");
+ switch (execute_statement(&statement, table)) {
+ case (EXECUTE_SUCCESS):
+ printf("Executed.\n");
+ break;
+ case (EXECUTE_TABLE_FULL):
+ printf("Error: Table full.\n");
+ break;
+ }
}
}
做了这些修改后我们就能实际保存数据到数据库了。
~ ./db
db > insert 1 cstack foo@bar.com
Executed.
db > insert 2 bob bob@example.com
Executed.
db > select
(1, cstack, foo@bar.com)
(2, bob, bob@example.com)
Executed.
db > insert foo bar 1
Syntax error. Could not parse statement.
db > .exit
~
现在是写一些测试的好时机,有几个原因:
- 我们计划大幅度修改存储表的数据结构,并且测试是可捕获回归
- 还有一些边界条件我们没有手动测试(例如填满一张表)
我们将在下一部分中解决这些问题。现在,看一下这一部分完整的区别(与上一部分对比,行开头“+”为新增,“-”为删除):
@@ -2,6 +2,7 @@
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
+#include <stdint.h>
typedef struct {
char* buffer;
@@ -10,6 +11,105 @@ typedef struct {
} InputBuffer;
+typedef enum { EXECUTE_SUCCESS, EXECUTE_TABLE_FULL } ExecuteResult;
+
+typedef enum {
+ META_COMMAND_SUCCESS,
+ META_COMMAND_UNRECOGNIZED_COMMAND
+} MetaCommandResult;
+
+typedef enum {
+ PREPARE_SUCCESS,
+ PREPARE_SYNTAX_ERROR,
+ PREPARE_UNRECOGNIZED_STATEMENT
+ } PrepareResult;
+
+typedef enum { STATEMENT_INSERT, STATEMENT_SELECT } StatementType;
+
+#define COLUMN_USERNAME_SIZE 32
+#define COLUMN_EMAIL_SIZE 255
+typedef struct {
+ uint32_t id;
+ char username[COLUMN_USERNAME_SIZE];
+ char email[COLUMN_EMAIL_SIZE];
+} Row;
+
+typedef struct {
+ StatementType type;
+ Row row_to_insert; //only used by insert statement
+} Statement;
+
+#define size_of_attribute(Struct, Attribute) sizeof(((Struct*)0)->Attribute)
+
+const uint32_t ID_SIZE = size_of_attribute(Row, id);
+const uint32_t USERNAME_SIZE = size_of_attribute(Row, username);
+const uint32_t EMAIL_SIZE = size_of_attribute(Row, email);
+const uint32_t ID_OFFSET = 0;
+const uint32_t USERNAME_OFFSET = ID_OFFSET + ID_SIZE;
+const uint32_t EMAIL_OFFSET = USERNAME_OFFSET + USERNAME_SIZE;
+const uint32_t ROW_SIZE = ID_SIZE + USERNAME_SIZE + EMAIL_SIZE;
+
+const uint32_t PAGE_SIZE = 4096;
+#define TABLE_MAX_PAGES 100
+const uint32_t ROWS_PER_PAGE = PAGE_SIZE / ROW_SIZE;
+const uint32_t TABLE_MAX_ROWS = ROWS_PER_PAGE * TABLE_MAX_PAGES;
+
+typedef struct {
+ uint32_t num_rows;
+ void* pages[TABLE_MAX_PAGES];
+} Table;
+
+void print_row(Row* row) {
+ printf("(%d, %s, %s)\n", row->id, row->username, row->email);
+}
+
+void serialize_row(Row* source, void* destination) {
+ memcpy(destination + ID_OFFSET, &(source->id), ID_SIZE);
+ memcpy(destination + USERNAME_OFFSET, &(source->username), USERNAME_SIZE);
+ memcpy(destination + EMAIL_OFFSET, &(source->email), EMAIL_SIZE);
+}
+
+void deserialize_row(void *source, Row* destination) {
+ memcpy(&(destination->id), source + ID_OFFSET, ID_SIZE);
+ memcpy(&(destination->username), source + USERNAME_OFFSET, USERNAME_SIZE);
+ memcpy(&(destination->email), source + EMAIL_OFFSET, EMAIL_SIZE);
+}
+
+void* row_slot(Table* table, uint32_t row_num) {
+ uint32_t page_num = row_num / ROWS_PER_PAGE;
+ void *page = table->pages[page_num];
+ if (page == NULL) {
+ // Allocate memory only when we try to access page
+ page = table->pages[page_num] = malloc(PAGE_SIZE);
+ }
+ uint32_t row_offset = row_num % ROWS_PER_PAGE;
+ uint32_t byte_offset = row_offset * ROW_SIZE;
+ return page + byte_offset;
+}
+
+Table* new_table() {
+ Table* table = (Table*)malloc(sizeof(Table));
+ table->num_rows = 0;
+ for (uint32_t i = 0; i < TABLE_MAX_PAGES; i++) {
+ table->pages[i] = NULL;
+ }
+ return table;
+}
+
+void free_table(Table* table) {
+ for (int i = 0; table->pages[i]; i++) {
+ free(table->pages[i]);
+ }
+ free(table);
+}
+
InputBuffer* new_input_buffer() {
InputBuffer* input_buffer = (InputBuffer*)malloc(sizeof(InputBuffer));
input_buffer->buffer = NULL;
@@ -40,17 +140,105 @@ void close_input_buffer(InputBuffer* input_buffer) {
free(input_buffer);
}
+MetaCommandResult do_meta_command(InputBuffer* input_buffer, Table *table) {
+ if (strcmp(input_buffer->buffer, ".exit") == 0) {
+ close_input_buffer(input_buffer);
+ free_table(table);
+ exit(EXIT_SUCCESS);
+ } else {
+ return META_COMMAND_UNRECOGNIZED_COMMAND;
+ }
+}
+
+PrepareResult prepare_statement(InputBuffer* input_buffer,
+ Statement* statement) {
+ if (strncmp(input_buffer->buffer, "insert", 6) == 0) {
+ statement->type = STATEMENT_INSERT;
+ int args_assigned = sscanf(
+ input_buffer->buffer, "insert %d %s %s", &(statement->row_to_insert.id),
+ statement->row_to_insert.username, statement->row_to_insert.email
+ );
+ if (args_assigned < 3) {
+ return PREPARE_SYNTAX_ERROR;
+ }
+ return PREPARE_SUCCESS;
+ }
+ if (strcmp(input_buffer->buffer, "select") == 0) {
+ statement->type = STATEMENT_SELECT;
+ return PREPARE_SUCCESS;
+ }
+
+ return PREPARE_UNRECOGNIZED_STATEMENT;
+}
+
+ExecuteResult execute_insert(Statement* statement, Table* table) {
+ if (table->num_rows >= TABLE_MAX_ROWS) {
+ return EXECUTE_TABLE_FULL;
+ }
+
+ Row* row_to_insert = &(statement->row_to_insert);
+
+ serialize_row(row_to_insert, row_slot(table, table->num_rows));
+ table->num_rows += 1;
+
+ return EXECUTE_SUCCESS;
+}
+
+ExecuteResult execute_select(Statement* statement, Table* table) {
+ Row row;
+ for (uint32_t i = 0; i < table->num_rows; i++) {
+ deserialize_row(row_slot(table, i), &row);
+ print_row(&row);
+ }
+ return EXECUTE_SUCCESS;
+}
+
+ExecuteResult execute_statement(Statement* statement, Table *table) {
+ switch (statement->type) {
+ case (STATEMENT_INSERT):
+ return execute_insert(statement, table);
+ case (STATEMENT_SELECT):
+ return execute_select(statement, table);
+ }
+}
+
int main(int argc, char* argv[]) {
+ Table* table = new_table();
InputBuffer* input_buffer = new_input_buffer();
while (true) {
print_prompt();
read_input(input_buffer);
- if (strcmp(input_buffer->buffer, ".exit") == 0) {
- close_input_buffer(input_buffer);
- exit(EXIT_SUCCESS);
- } else {
- printf("Unrecognized command '%s'.\n", input_buffer->buffer);
+ if (input_buffer->buffer[0] == '.') {
+ switch (do_meta_command(input_buffer, table)) {
+ case (META_COMMAND_SUCCESS):
+ continue;
+ case (META_COMMAND_UNRECOGNIZED_COMMAND):
+ printf("Unrecognized command '%s'\n", input_buffer->buffer);
+ continue;
+ }
+ }
+
+ Statement statement;
+ switch (prepare_statement(input_buffer, &statement)) {
+ case (PREPARE_SUCCESS):
+ break;
+ case (PREPARE_SYNTAX_ERROR):
+ printf("Syntax error. Could not parse statement.\n");
+ continue;
+ case (PREPARE_UNRECOGNIZED_STATEMENT):
+ printf("Unrecognized keyword at start of '%s'.\n",
+ input_buffer->buffer);
+ continue;
+ }
+
+ switch (execute_statement(&statement, table)) {
+ case (EXECUTE_SUCCESS):
+ printf("Executed.\n");
+ break;
+ case (EXECUTE_TABLE_FULL):
+ printf("Error: Table full.\n");
+ break;
}
}
Enjoy GreatSQL 😃
关于 GreatSQL
GreatSQL是由万里数据库维护的MySQL分支,专注于提升MGR可靠性及性能,支持InnoDB并行查询特性,是适用于金融级应用的MySQL分支版本。
相关链接: GreatSQL社区 Gitee GitHub Bilibili
GreatSQL社区:
欢迎来GreatSQL社区发帖提问
https://greatsql.cn/

技术交流群:
微信:扫码添加
GreatSQL社区助手微信好友,发送验证信息加群。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号