GreatSQL 开源数据库 & NVIDIA InfiniBand存算分离池化方案:实现高性能分布式部署
NVIDIA InfiniBand是一种被广泛使用的网络互联技术,基于IBTA(InfiniBand Trade Association)而定义的高带宽、低延时、低CPU占用率、大规模易扩展的通信技术,是世界领先的超级计算机的互连首选,为高性能计算、人工智能、云计算、存储等众多数据密集型应用提供了强大的网络性能支撑。通过高速的InfiniBand技术,将业务负载由单机运行转化为基于多机协作的高性能计算集群,并使高性能集群的性能得以进一步释放与优化。
GreatSQL是由万里数据库维护的国内自主MySQL分支版本,专注于提升MGR可靠性及性能,支持InnoDB并行查询特性,适用于金融级应用。
此次通过对比测试基于InfiniBand 的 NVMe SSD池化方案 及本地NVMe SSD的传统方案的性能表现,评估使用基于InfiniBand的存算分离架构对分布式数据库性能的提升程度及扩展性。
经过双方合作,通过大量数据分析,可以看出基于InfiniBand池化方案的存算分离架构的性能更优、稳定性更强,为GreatSQL实现更高性能的分布式部署提供了有力的技术平台支撑。
1、NVIDIA InfiniBand 池化方案介绍
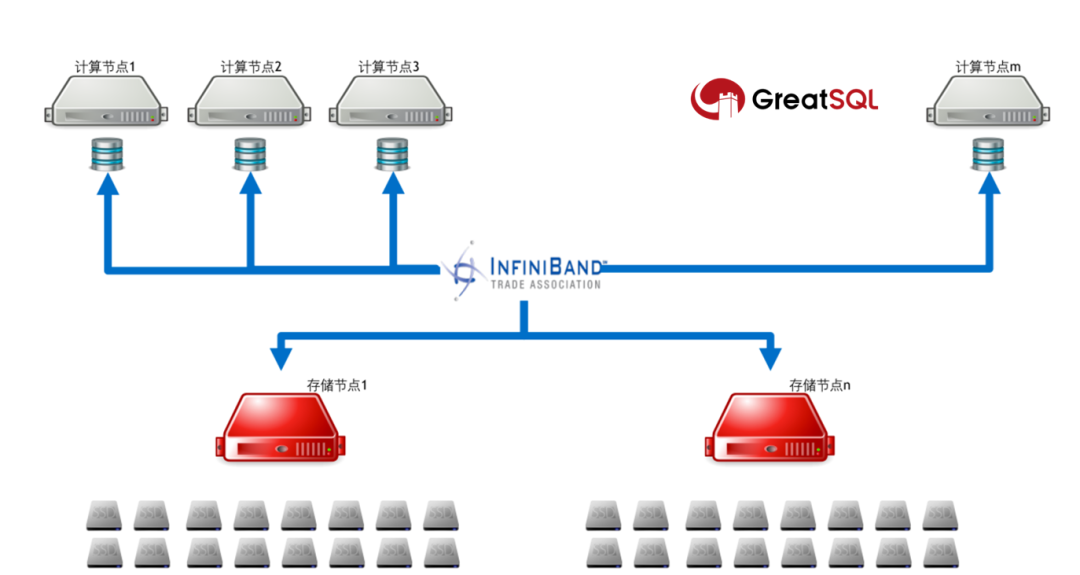
分布式数据库集群由两部分组成:
-
计算节点是无SSD盘的裸金属服务器,运行MySQL数据库服务程序;
-
存储节点提供NVMe SSD资源池,通过软件聚合方式提供高性能Lun实现对于数据库的数据的存储服务;
两部分服务器通过Quantum 平台的InfiniBand网络实现对计算节点和存储节点的无损连接,结合NVMe-oF(NVMe over Fabric)高效的数据存储传输协议,将存储节点的Lun挂载到计算节点,实现结算节点本地高性能的数据存储能力。
- 测试环境
为了可以公平对比两种方案的优劣,两次测试均采用同一台计算服务器进行测试,不同的是,本地方案存储由本地的PCIe4.0 NVMe SSD承载,InfiniBand 池化方案由100Gbps速率的HDR100网卡接入,通过相同型号的NVMe SSD组成的全闪服务器借助NVMe-oF提供高性能虚拟Lun完成数据访问。
2.1 存储设备
本次测试主要采取两种存储方案:
-
InfiniBand + NVMe SSD设备
-
本机挂NVMe SSD设备
$ nvme list
Node SN Model Namespace Usage Format FW Rev
--------------------- -------------------- ---------------------------------------- --------- -------------------------- ---------------- --------
# InfiniBand + NVMe SSD设备
/dev/nvme0n1 MNC12 Mellanox BlueField NVMe SNAP Controller 1 1.10 TB / 1.10 TB 512 B + 0 B 1.0
# 本机挂载的两个NVMe SSD设备
/dev/nvme2n1 S5L9NE0NA00144 SAMSUNG MZWLJ7T6HALA-0007C 1 7.68 TB / 7.68 TB 512 B + 0 B EPK99J5Q
/dev/nvme3n1 S5L9NE0NA00091 SAMSUNG MZWLJ7T6HALA-0007C
2.2 CPU&内存
-
内存:512GB
-
CPU,最多128核
$ lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 128
On-line CPU(s) list: 0-127
Thread(s) per core: 2
Core(s) per socket: 32
Socket(s): 2
NUMA node(s): 1
Vendor ID: AuthenticAMD
BIOS Vendor ID: Advanced Micro Devices, Inc.
CPU family: 23
Model: 49
Model name: AMD EPYC 7542 32-Core Processor
BIOS Model name: AMD EPYC 7542 32-Core Processor
Stepping: 0
CPU MHz: 3381.667
CPU max MHz: 2900.0000
CPU min MHz: 1500.0000
BogoMIPS: 5799.52
Virtualization: AMD-V
L1d cache: 32K
L1i cache: 32K
L2 cache: 512K
L3 cache: 16384K
NUMA node0 CPU(s): 0-127
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc rep_good nopl nonstop_tsc cpuid extd_apicid aperfmperf pni pclmulqdq monitor ssse3 fma cx16 sse4_1 sse4_2 x2apic movbe popcnt aes xsave avx f16c rdrand lahf_lm cmp_legacy svm extapic cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw ibs skinit wdt tce topoext perfctr_core perfctr_nb bpext perfctr_llc mwaitx cpb cat_l3 cdp_l3 hw_pstate sme ssbd mba sev ibrs ibpb stibp vmmcall fsgsbase bmi1 avx2 smep bmi2 cqm rdt_a rdseed adx smap clflushopt clwb sha_ni xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local clzero irperf xsaveerptr wbnoinvd arat npt lbrv svm_lock nrip_save tsc_scale vmcb_clean flushbyasid decodeassists pausefilter pfthreshold avic v_vmsave_vmload vgif umip rdpid overflow_recov succor smca
2.3 操作系统
OS:CentOS 8
内核:Linux g4 5.4.90-1.el8.x86_64 #1 SMP Fri Mar 11 10:11:26 UTC 2022 x86_64 x86_64 x86_64 GNU/Linu
文件系统
$ mount | grep xfs
LABEL=/nvme0 /nvme0 xfs defaults,noatime,nodiratime,inode64 0 0
LABEL=/nvme2 /nvme2 xfs defaults,noatime,nodiratime,inode64 0 0
LABEL=/nvme3 /nvme3 xfs defaults,noatime,nodiratime,inode64 0 0
$ df -hT
/dev/nvme0n1 xfs 1.0T 247G 778G 25% /nvme0
/dev/nvme2n1 xfs 7.0T 1.1T 6.0T 15% /nvme2
/dev/nvme3n1 xfs 7.0T 245G 6.8T 4% /nvme3
2.4 压测参数&指标
-
压测工具:sysbench
- 模式:oltp_read_write。
- 每轮压测时长:900秒。
- 每轮压测休眠间隔:180秒。
-
共64个表。
-
每个表12500000条记录。
-
整个测试库大小约186G。
-
采用InnoDB引擎。
-
并发线程数变化:8、16、32、64、128。
-
ibp(innodb buffer pool)变化:47G、93G、140G、186G(约为物理数据的25%、50%、75%、100%)。
-
主要参数选项
sync_binlog = 1
innodb_flush_log_at_trx_commit = 1
innodb_log_buffer_size = 32M
innodb_log_file_size = 2G
innodb_log_files_in_group = 3
innodb_doublewrite_files = 2
innodb_io_capacity = 400000
innodb_io_capacity_max = 800000
innodb_flush_method = O_DIRECT
innodb_thread_concurrency = 0
sysbench测试命令模板:
$ sysbench oltp_read_write.lua \
--tables=64 \
--table_size=12500000\
--report-interval=1 \
--threads=128 \
--rand-type=uniform \
--db-ps-mode=disable \
--mysql-ignore-errors=all \
--time=900 run
3.性能表现&总结
3.1测试总结
结论先行,整体测试情况如下:
-
当ibp不足以覆盖全部物理数据时:
1)GreatSQL 8.x性能远高于GreatSQL 5.7。
2)并发线程数越高,IB+NVMe SSD vs 本地NVMe SSD 的差距越小。
3) ibp越大,GreatSQL 5.7和8.0性能越接近。
-
当ibp基本可以覆盖全部物理数据时:
1) GreatSQL 5.7的性能整体比GreatSQL 8.0略好。
-
总的测试下来看,IB NVMe SSD 相比 本地NVMe SSD的性能更好,也更稳定一些。
-
尝试对比测试了组提交(binlog group commit),在本案中对性能影响很小,这里不再赘述。
-
尝试对比设置 innodb_thread_concurrency = 64|128,发现加上后,在ibp足够大,且并发也打满128线程后,性能更稳定些,波动没那么大了,且最终整体性能也能提升约8% ~ 10%(不过也要考虑到,真实生产环境中,很少会跑满这么大压力)。
-
总的来说,当物理内存不足以覆盖业务数据时(生成环境中这种情况很常见),如果单靠增加物理内存以提升数据库性能可能从性价比角度看并不划算,不如换个思路,提升本地物理I/O设备的性能,毕竟现在NVMe SSD的性能可以跑到很高。
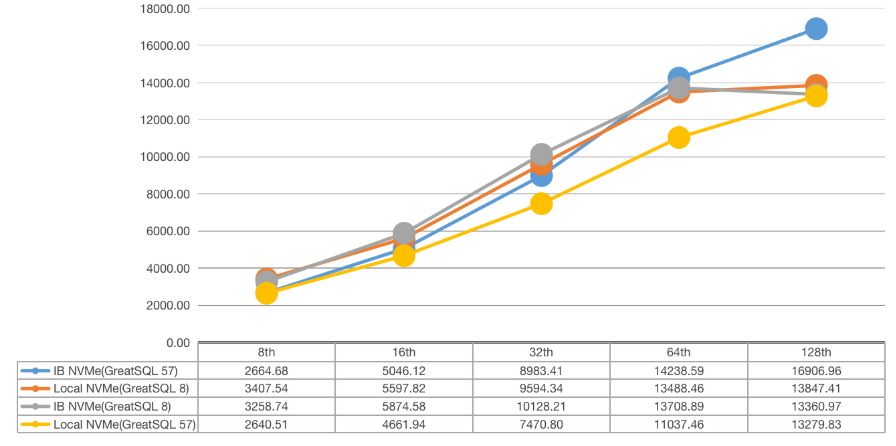
3.2 测试数据对比图表
1)ibp=47G
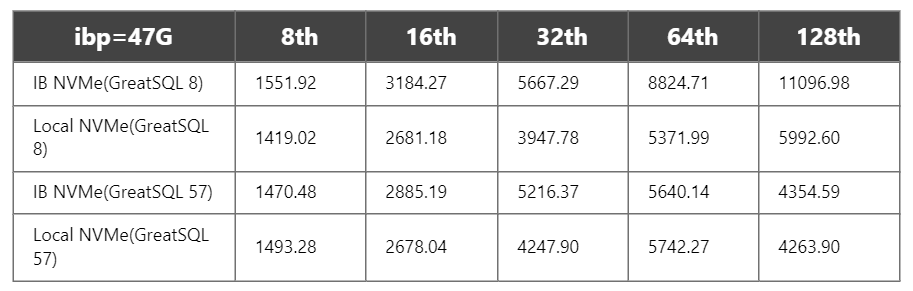
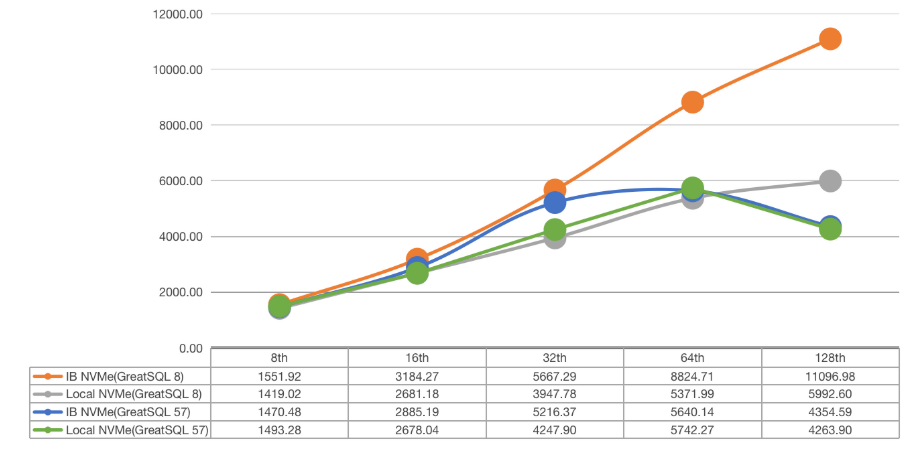
2)ibp=93G
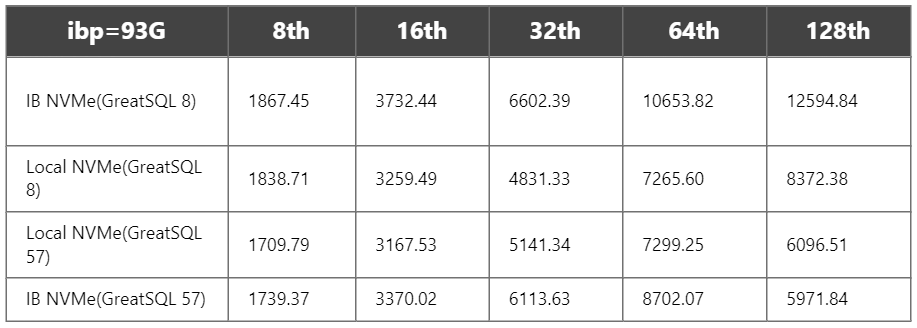
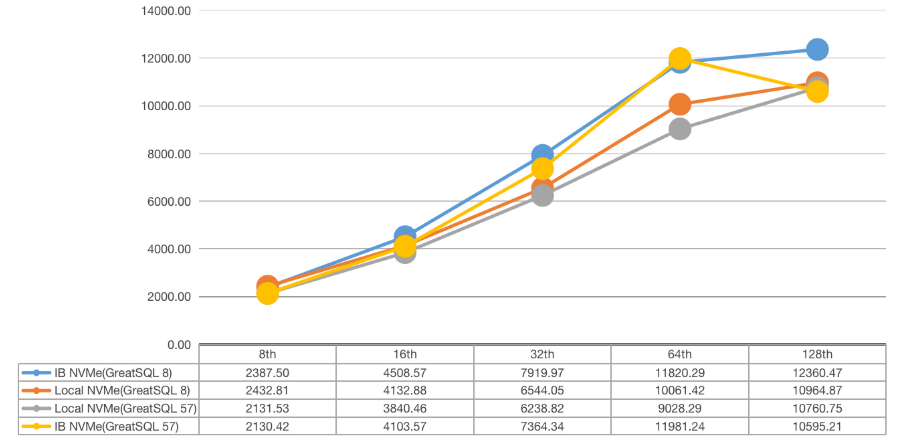
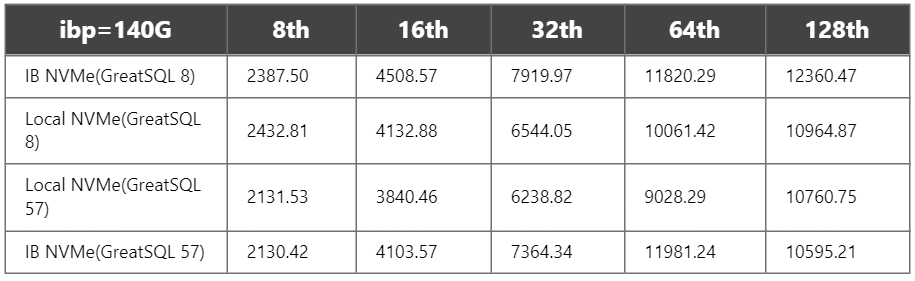
3)ibp=140G
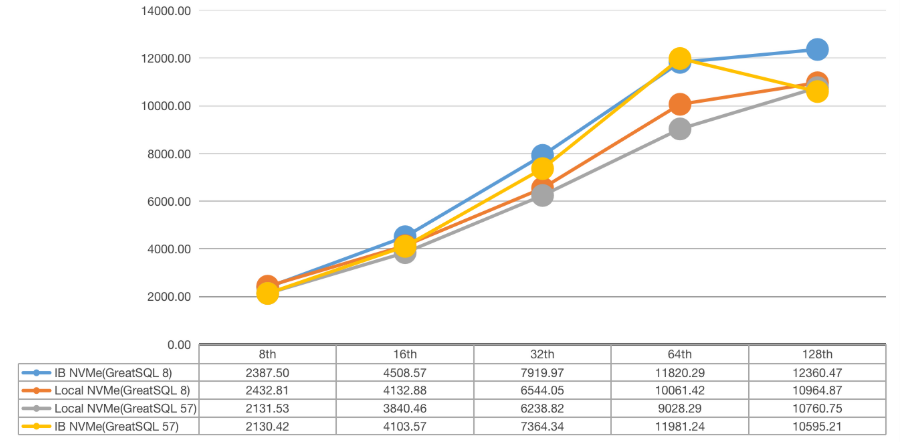
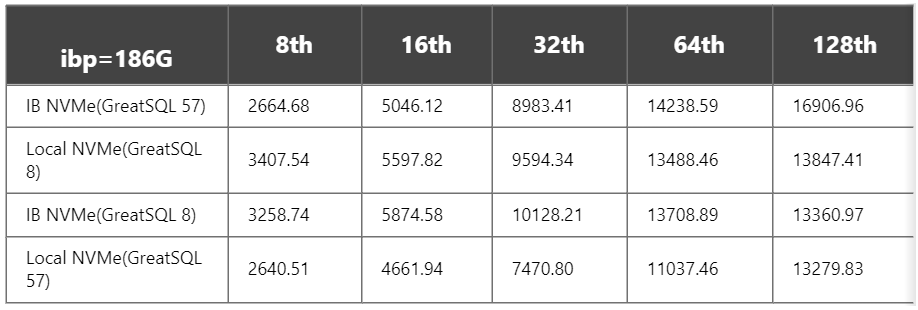
4)ibp=186G
4.结语
从以上测试数据中,可以明显看到采用了InfiniBand池化方案数据库性能在不同场景中性能都有不同程度的明显提升,尤其在高并发场景下,表现突出。
未来,万里数据库将联合NVIDIA在万里数据库GreatDB集中式及分布式数据库产品中,探索更多基于InfiniBand在数据库中的结合点和创新点,基于NVIDIA InfiniBand打造数据库+网络软硬一体化联合解决方案,为用户创造更多价值。
关于 GreatSQL
GreatSQL是由万里数据库维护的MySQL分支,专注于提升MGR可靠性及性能,支持InnoDB并行查询特性,是适用于金融级应用的MySQL分支版本。
GreatSQL社区 Gitee GitHub Bilibili

技术交流群:
微信:扫码添加
GreatSQL社区助手微信好友,发送验证信息加群。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号