MySQL:关于MGR中监控的两个重要指标简析
欢迎来到 GreatSQL社区分享的MySQL技术文章,如有疑问或想学习的内容,可以在下方评论区留言,看到后会进行解答
转载声明:以下文章来源于MySQL学习 ,作者八怪(高鹏)
一、两个重要的指标
这两个指标就是 replication_group_member_status 视图中的
-
COUNT_TRANSACTIONS_IN_QUEUE :等待冲突验证的队列数量,实际上是进行pipeline处理的队列数量(内部表示m_transactions_waiting_certification),单位为事务数量。
-
COUNT_TRANSACTIONS_REMOTE_IN_APPLIER_QUEUE:等待应用的队列数量(内部表示m_transactions_waiting_apply),单位为事务数量。
这两个值,特别是第二个我们通常用于在单主模式下,作为判断是否延迟的标准。本文就是来解释一下这两个指标具体的含义。
二、相关来源和broadcast线程
实际上这两个信息实际上主要是供流控使用的,主要来自本地节点和远端节点pipeline的信息。那么远端的信息是如何获取到的呢?实际上在我们的MGR线程中有一个叫做Certifier_broadcast_thread::dispatcher的线程,这个线程发送本地的pipeline信息给远端节点。这个线程主要完成的工作包含:
30秒设置一次
设置send_transaction_identifiers = true,这个值主要用于在构建Pipeline_stats_member_message类型消息的时候是否包含gtid信息。这些GTID信息主要是包含committed_transactions和last_conflict_free_transaction。这些信息同样会在replication_group_member_status中进行体现,也就是我们看到的TRANSACTIONS_COMMITTED_ALL_MEMBERS和LAST_CONFLICT_FREE_TRANSACTION。
每秒进行 构建Pipeline_stats_member_message类型的消息(type CT_PIPELINE_STATS_MEMBER_MESSAGE),并且发送给远端节点。其中包含了我们上述的2个重要指标也就是m_transactions_waiting_certification/m_transactions_waiting_apply.
-
COUNT_TRANSACTIONS_IN_QUEUE (m_transactions_waiting_certification) 实际上这是appler线程进行pipeline处理的队列数量,来自于applier_module->get_message_queue_size(),一旦处理完成就会写入到relay log,相应的队列也会出队。实际它的入队是xcom engine线程进行的push操作。一旦写入relay log后就会进行pop处理,队列数量也会减少。参考Applier_module::applier_thread_handle处 applier线程处理的流程。因此并不是单主就不会有冲突验证队列,一样是有的,只是处理要快于多主,因为任何事务的event都需要进行pipeline处理,其中包含了冲突验证、GTID生成、写入relay log等操作。
-
COUNT_TRANSACTIONS_REMOTE_IN_APPLIER_QUEUE(m_transactions_waiting_apply) 来自于m_transactions_waiting_apply.load(),这个值在Applier_handler::handle_event函数增加,当pipeline的Applier_handler处理完成,也就是写入了relay log后增加。这个值在hook group_replication_trans_before_commit处进行减少,函数首先就会判断提交的事务是不是来自applier通道,如果是则进行减少。当然如果是主库我们事务提交是前台线程自己,而不是applier通道,所以不会影响这个值。
简单的写入relay log的逻辑和指标增加逻辑:
error = channel_interface.queue_packet((const char *)p->payload, p->len); //写入 relay log 调用依旧为queue event
if (event->get_event_type() == binary_log::GTID_LOG_EVENT &&
local_member_info->get_recovery_status() ==
Group_member_info::MEMBER_ONLINE) {
applier_module->get_pipeline_stats_member_collector()
->increment_transactions_waiting_apply(); //增加等待应用
当然本消息中包含了所有replication_group_member_status的指标,这里简单列举如下:
m_transactions_certified.load()
这个值在认证最后进行更新,用于统计当前认证了多少任务,当然这里只是通过了
Certifier::certify的事务的个数,因此单主也会有这个值。
m_transactions_applied.load()
已经应用的事务,这个值在hook group_replication_trans_before_commit处进行增加
首先就会判断提交的事务是不是来自applier通道,如果是则进行增加
m_transactions_local.load()
本地事务的数量,这个值在hook group_replication_trans_before_commit处进行增加
在group_replication_trans_before_commit中会判断提交的事务到底是applier通道过的
sql线程还是前台session,如果是前台session则增加
(cert_interface != nullptr) ? cert_interface->get_negative_certified(): 0
冲突认证操作失败的事务数量
(cert_interface != nullptr) ? cert_interface->get_certification_info_size(): 0
冲突认证数据库的大小
send_transaction_identifiers
30秒一次设置为true,是否发送了本地相关的GTID信息
committed_transactions
全局提交的事务的gtid信息,这里这个信息30秒发送一次,主要来自于
为 CT_CERTIFICATION_MESSAGE 消息后处理的所有节点执行 GTID事务的交集
last_conflict_free_transaction
最后一次没有冲突的事务数量
m_transactions_local_rollback.load()
由于冲突认证,本地需要回滚的事务数量
mode
是否开启了流量控制
然后会根据是否开启流控进行综合各个节点的pipeline信息,进行流控指标的计算,如果一旦计算出需要进行流控处理,则事务需要在group_replication_trans_before_commit处进行流控等待。
每60秒进行
发送本节点的GTID_EXECUTED给远端节点,这个主要用于冲突验证数据库的清理和计算全局提交的GTID信息,发送类型为Gtid_Executed_Message,type为CT_CERTIFICATION_MESSAGE调用gcs_module->send_message(gtid_executed_message, true);发送消息 因此replication_group_member_status中的GTID信息并不是很及时,有至少60秒,最多120秒的延迟,但是其他信息还是比较及时的,但是也不是实时同步的。
三、applier通道的pipeline
实际上这个主要是当xcom engine线程发送消息给applier线程后,apllier线程会进行一些处理如下是远端节点收到事务信息后进行的pipeline处理:
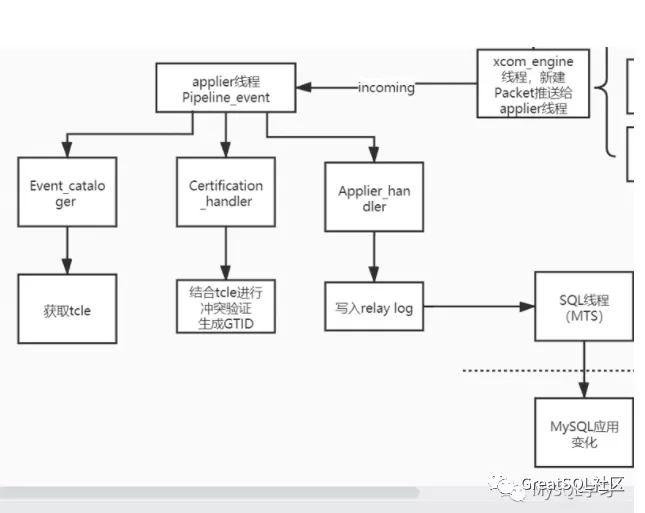
这里的event_cataloger-->certification_handler-->applier_handler 进行的处理就是所谓的applier通道的pipeline。当然如果是本地事务,则不需要写入到relay log,但是其他流程还是需要的。
四、关于replication_group_member_status信息的装载
这部分信息主要装载逻辑如下:
ha_perfschema::rnd_next
->table_replication_group_member_stats::rnd_next
读取数据
->table_replication_group_member_stats::make_row
->PFS_engine_table::read_row
获取值,这里就是相应的对应关系
->table_replication_group_member_stats::read_row_values
其中 table_replication_group_member_stats::make_row就是读取我们上面说的这些信息,而table_replication_group_member_stats::read_row_values则是转换为我们DBA可见的形式。这两个指标如下:
case 3: /** transaction_in_queue */
set_field_ulonglong(f, m_row.trx_in_queue);
break;
...
case 9:
set_field_ulonglong(f, m_row.trx_remote_applier_queue);
其实也就是我们上面说的m_transactions_waiting_certification和m_transactions_waiting_apply。但是我们需要注意的是这里获取的时候分为了本地节点和远端节点。在get_group_member_stats有如下逻辑:
如果是本地UUID则
-> applier_module->get_local_pipeline_stats()
如果是远端UUID则
-> applier_module->get_flow_control_module()->get_pipeline_stats
(member_info->get_gcs_member_id().get_member_id()))
而远端节点的信息正是来自于各个节点broadcast线程的发送。对于单主模式的主节点来讲:
-
m_transactions_waiting_apply:正常情况下应该维持为0,因为本地事务不会写到relay log。特殊情况除外。
-
m_transactions_waiting_certification:每个节点都可以不为0,因为过冲突验证和GTID生成是不能避免的。
具体逻辑在 Certification_handler::handle_transaction_id 中对本地事务和远端事务处理的分支上。
Enjoy GreatSQL 😃
文章推荐:
GreatSQL MGR FAQ
https://mp.weixin.qq.com/s/J6wkUpGXw3YkyEUJXiZ9xA
万答#12,MGR整个集群挂掉后,如何才能自动选主,不用手动干预
https://mp.weixin.qq.com/s/07o1poO44zwQIvaJNKEoPA
『2021数据技术嘉年华·ON LINE』:《MySQL高可用架构演进及实践》
https://mp.weixin.qq.com/s/u7k99y6i7riq7ScYs7ySnA
一条sql语句慢在哪之抓包分析
https://mp.weixin.qq.com/s/AYibbzl860D90rOeyjB6IQ
万答#15,都有哪些情况可能导致MGR服务无法启动
https://mp.weixin.qq.com/s/inSGpd0Q_XIl2Mb-VsvNsA
技术分享 | 为什么MGR一致性模式不推荐AFTER
https://mp.weixin.qq.com/s/rNeq479RNsklY1BlfKOsYg
关于 GreatSQL
GreatSQL是由万里数据库维护的MySQL分支,专注于提升MGR可靠性及性能,支持InnoDB并行查询特性,是适用于金融级应用的MySQL分支版本。
Gitee:
https://gitee.com/GreatSQL/GreatSQL
GitHub:
https://github.com/GreatSQL/GreatSQL
Bilibili:
https://space.bilibili.com/1363850082/video
微信&QQ群:
可搜索添加GreatSQL社区助手微信好友,发送验证信息“加群”加入GreatSQL/MGR交流微信群
QQ群:533341697
微信小助手:wanlidbc
本文由博客一文多发平台 OpenWrite 发布!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号