
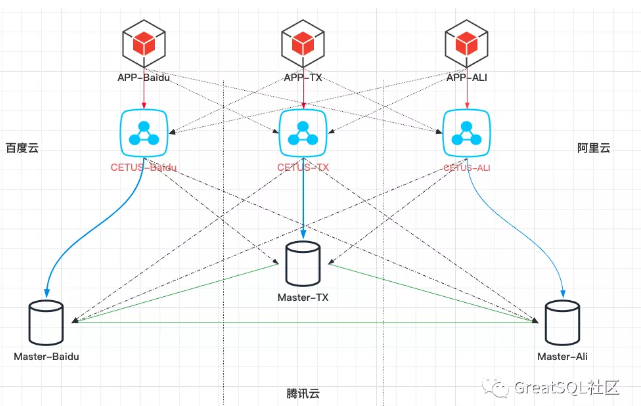
多云部署多主模式的MGR集群,每个云一个MGR 节点,满足业务单元化改造的需求
欢迎来到 GreatSQL社区分享的MySQL技术文章,如有疑问或想学习的内容,可以在下方评论区留言,看到后会进行解答
-
GreatSQL社区原创内容未经授权不得随意使用,转载请联系小编并注明来源。
-
本文来自投稿:by 作业帮DBA团队
一、架构需求:
-
正常情况下每个云的业务程序(下图中的APP) 通过本地的cetus 写入本地的MGR 节点(默认启动时通过cetus 配置本地MGR 节点为rw); 读请求会根据 cetus 读写分离策略路由到不同的云的MGR 节点
-
当本地MGR 节点故障,则cetus 会自动检测配置中的后端MGR 节点,选取一个新的存活节点作为rw 节点。此时业务跨云读写。
-
当单个云整体故障时(单云孤岛),集群剩余节点可以正常提供服务,业务层需要切流,将业务流量指向其他正常云的服务(APP)
二、测试流程
1.性能测试对比
-
同机房是指 sysbench 以及压测的节点都在同一个机房; 跨机房指 sysbench 和 压测脚本中配置的mysql_host 在不同的机房
-
主要进行Read_Write 以及 Write_Only 两个模式进行对比
主机配置: 35C 376G
MySQL 版本: GreatSQL 8.0.25
buffer_pool: 24G
测试数据: sbtest 8张表 * 3000w
sysbench压测脚本:
- oltp_read_write.lua
- oltp_write_only.lua
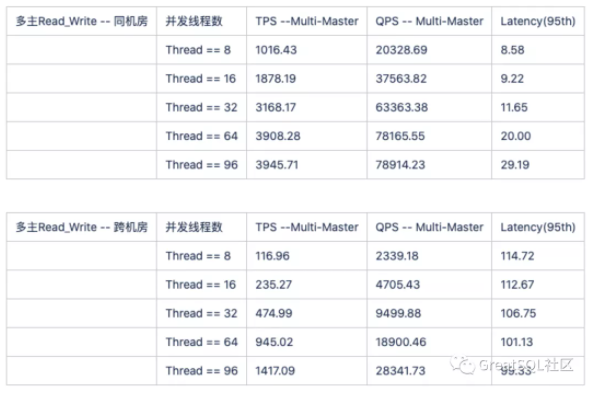
=> Read_Write 压测对比
跨机房情况下集群吞吐量下降明显,耗时增加明显
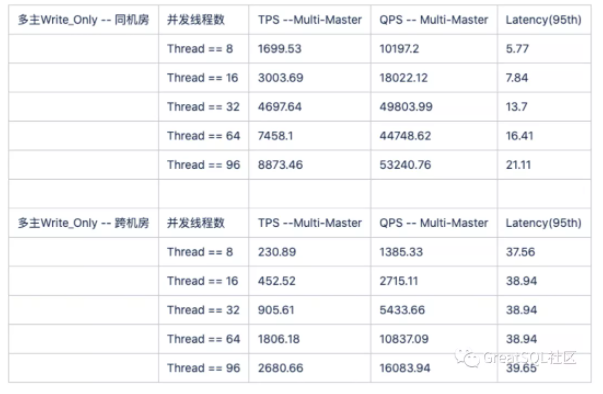
=> Write_Only 压测对比
跨机房对比同机房耗时增加20ms 左右
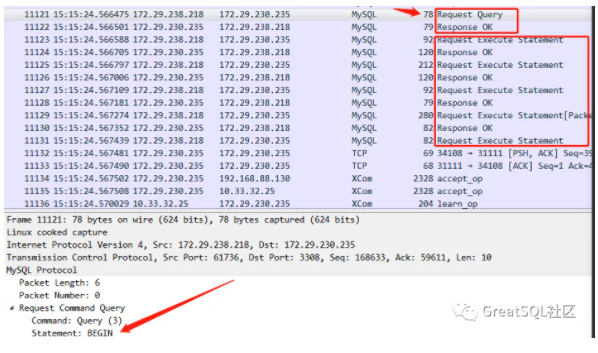
跨机房下耗时高原因排查:
经过抓包分析,压测使用的脚本中的事务都是带有begin,commit。在commit 之前的每个语句都要增加一个rtt 的延迟时间(机房之间的耗时在3ms 左右)。
因此在跨机房的情况下每个事务的响应时间都会至少额外增加(每个事务中 sql个数 * 3ms) 的时间。
2.故障场景测试
主要测试在单节点故障,多节点故障,单机房整体故障时对业务的预期影响以及DB 侧应对的策略 集群初始状态: (3个 主机,每台主机部署一个MGR 节点+cetus 节点)

Cetus中rw节点在172上
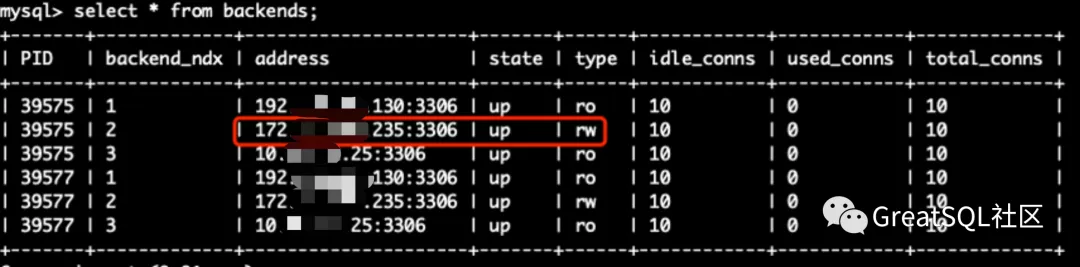
==> 单实例故障场景:
1.Kill掉172实例后,在192和10实例上观察集群状态,172被踢出MGR集群 Cetus中rw节点切到了192上,172实例offline+ro状态
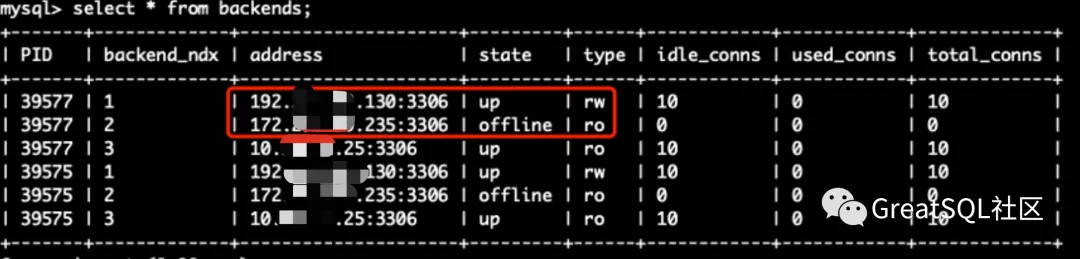
2.重新启动172实例,并启动group_replication加入组复制

mysql> start group_replication;
mysql> select * from information_schema.replication_group_member

观察cetus中后端的状态:172实例恢复up + ro 状态
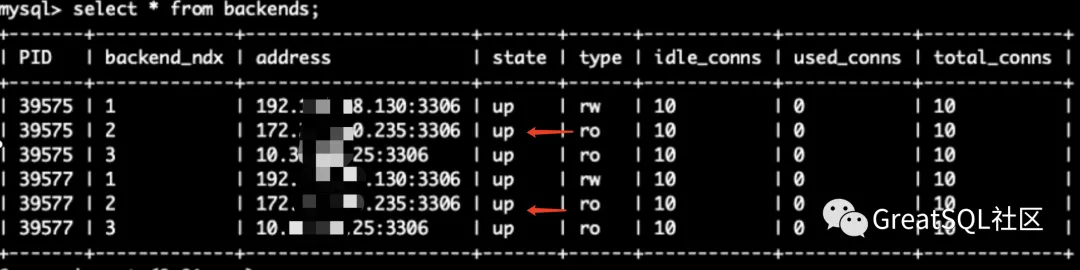
注意:cetus 用户有super 权限,当DB实例重启后Cetus会尝试自动start group_replication,如果start group_replication失败Cetus会不断尝试重启,不建议开启
结论:MGR集群中少数实例宕机后重新启动实例,start group_replication后会自动加入MGR集群并补齐数据(如果binlog存在),Cetus中实例状态也会恢复为up+ro
问题:如果实例发生故障前在Cetus中为rw状态,当实例故障时Cetus中的rw节点会切换到别的实例,故障实例恢复后在Cetus中为ro状态,如果需要恢复rw状态,需要手动维护
==> 多实例故障
Kill掉172和10的2个实例,在存活实例192上查询members状态,172和10实例为UNREACHABLE

Cetus中存活实例192可读不可写,写入报错service unavailable
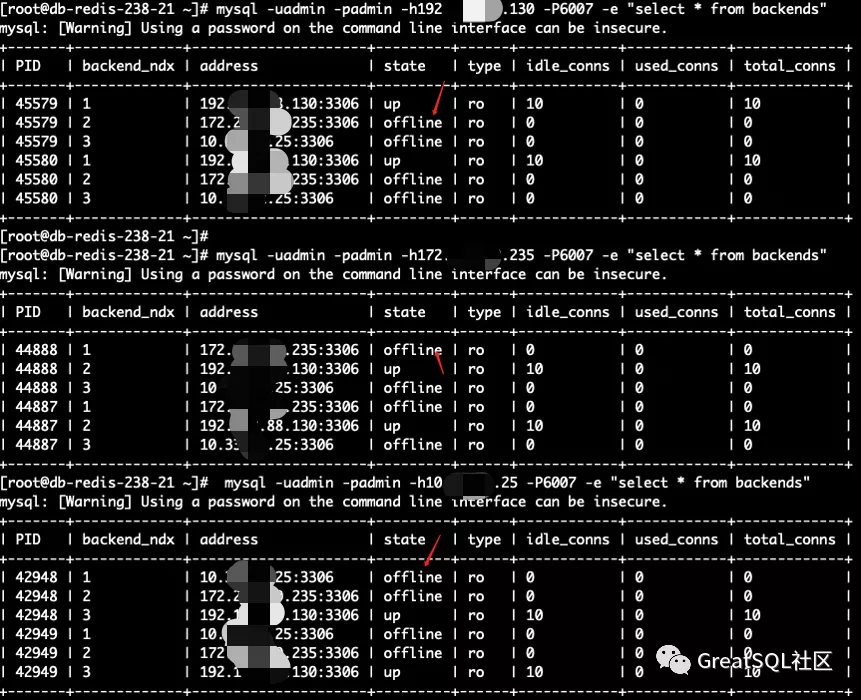
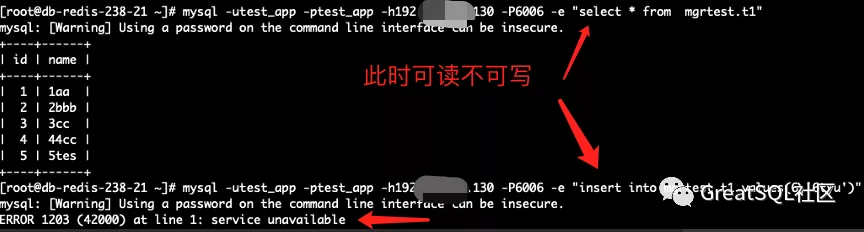
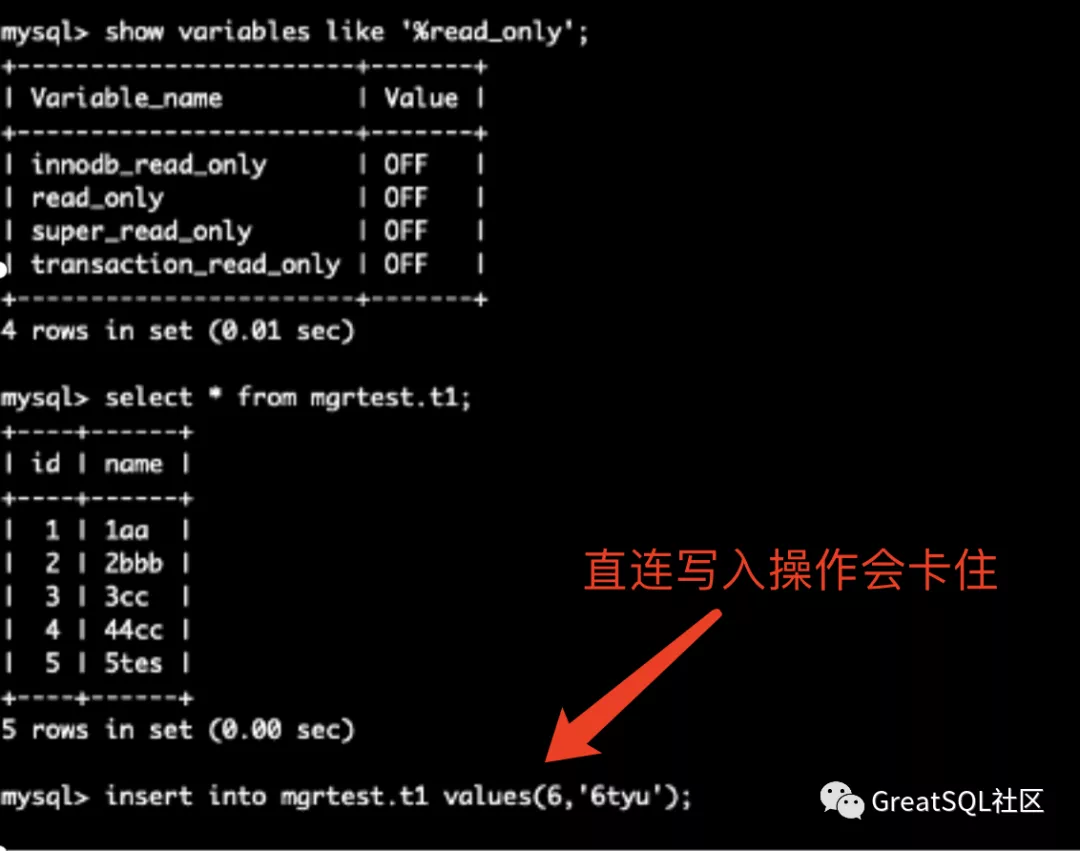
如果直连192实例写入会hang死
重启172和10实例后,启动group_replication失败,需要重新引导组复制
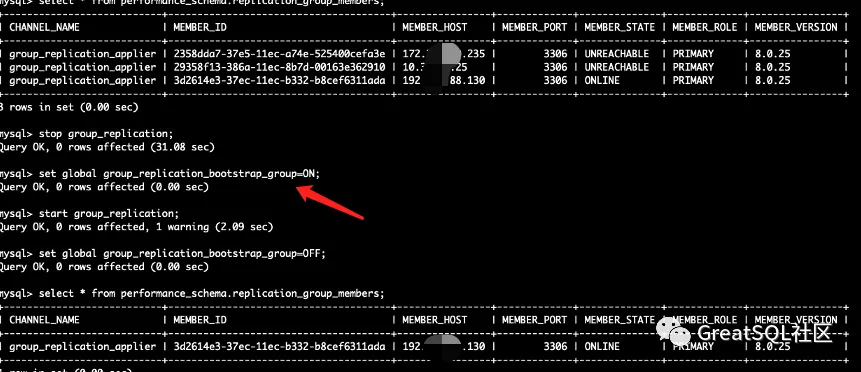
在172和10的实例上start group_replication加入MGR集群成功
结论:MGR集群中多数实例宕机后重新启动实例,start group_replication会失败,此时MGR集群已不存在,需要重新初始化集群才能将原有实例加入集群
问题:MGR集群中多数实例故障会导致集群崩溃,整个集群可读不可写,如果故障实例短时间能恢复则可手动重置MGR集群让实例重新加入集群,不可写时间相对较短,对业务影响较小。
如果故障实例短时间不能恢复,则需要强制激活存活的少数节点为新MGR集群(单主模式),恢复写能力,对业务提供服务,然后利用存活节点数据备份重新搭建DB实例,恢复新的多主MGR集群
==> 单机房网络隔离
192 实例单云网络隔离。此时当前云内的业务通过192上的cetus 进行读写操作时, 可读不可写,写入报错service unavailable;另外两个节点组成的MGR集群可以正常提供服务 192 cetus实例查看的状态
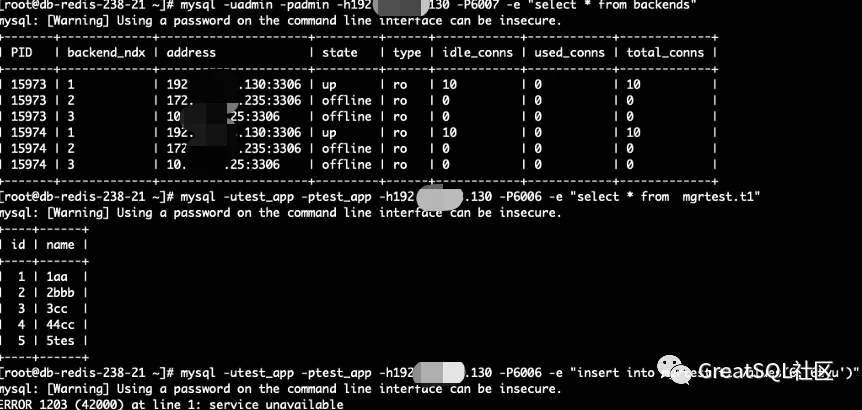
172 和10节点MGR集群状态,数据写入正常
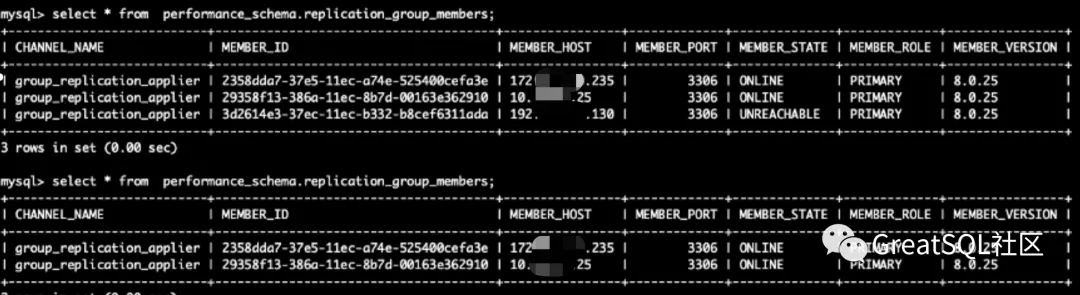
网络恢复后被隔离的192实例自动加入MGR集群且补齐网络隔离期间MGR集群写入的数据
问题点:如果业务主要流量在被隔离的机房且上层无法切流到多数节点的MGR集群,则需要强制激活隔离机房的实例为单实例多主模式MGR集群,恢复写能力(后续再添加实例),此时原来的MGR集群会被拆分为2个同时可用的MGR集群(少数节点的单实例多主模式MGR集群和多数节点的多实例多主模式MGR集群)
如果2个集群都有数据写入则后续会因为写入数据冲突或者gtid不一致无法合并为1个集群,如果后续想合并数据最好是通过业务层做数据回归
==> 多机房网络隔离
此时各机房互相访问不通,则会形成多个可读不可写的实例
- 短时间内网络不能恢复 需要强制激活某个实例恢复读写能力,在192上观察另外2个节点变为UNREACHABLE
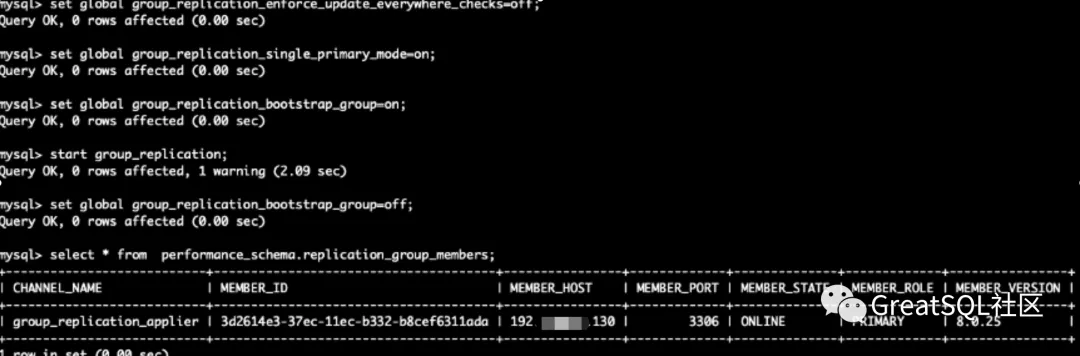
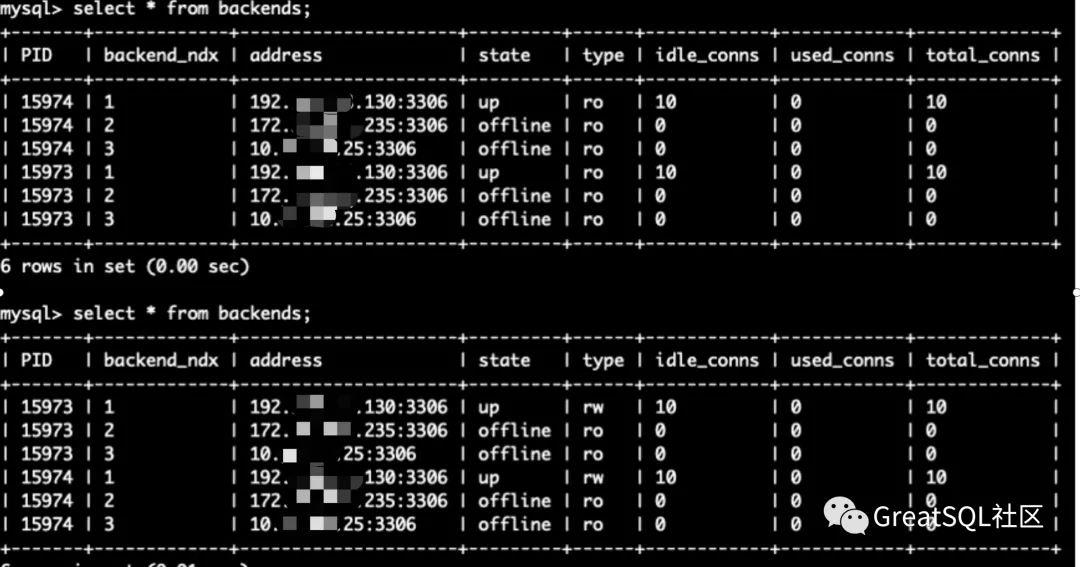
Cetus中192实例从up+ro恢复为up+rw
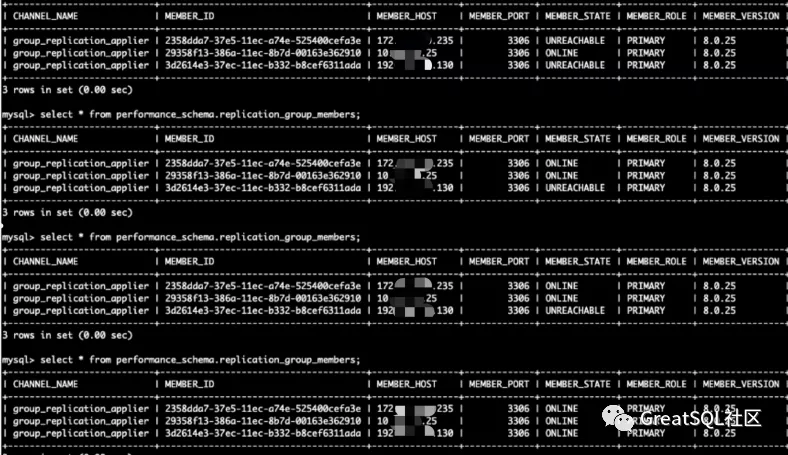
- 机房之间网络抖动,随着网络恢复MGR集群自动恢复
能忍受抖动时间内可读不可写,不需要强制激活节点恢复写能力,网络恢复后MGR集群会自动恢复
测试总结:
当前测试主要结合CETUS来满足在各种不同场景下我司的业务需求。
不同公司的不同业务有着不同的形态.
在使用其他proxy 进行测试时,需要注意在各种场景下业务的预期状态是什么样的.
- 比如在单云隔离时,被隔离的云内的业务是希望能继续读取数据还是不可读不可写;
- 是否允许跨云访问,能接受的耗时范围是多少?
以上种种需要使用proxy或者其他外挂手段设置不同的读写策略。
总体测试下来MGR的多主模式的性能以及故障处理满足我们的使用需求。
Enjoy GreatSQL 😃
文章推荐:
GreatSQL MGR FAQ
https://mp.weixin.qq.com/s/J6wkUpGXw3YkyEUJXiZ9xA
万答#12,MGR整个集群挂掉后,如何才能自动选主,不用手动干预
https://mp.weixin.qq.com/s/07o1poO44zwQIvaJNKEoPA
『2021数据技术嘉年华·ON LINE』:《MySQL高可用架构演进及实践》
https://mp.weixin.qq.com/s/u7k99y6i7riq7ScYs7ySnA
一条sql语句慢在哪之抓包分析
https://mp.weixin.qq.com/s/AYibbzl860D90rOeyjB6IQ
万答#15,都有哪些情况可能导致MGR服务无法启动
https://mp.weixin.qq.com/s/inSGpd0Q_XIl2Mb-VsvNsA
技术分享 | 为什么MGR一致性模式不推荐AFTER
https://mp.weixin.qq.com/s/rNeq479RNsklY1BlfKOsYg
关于 GreatSQL
GreatSQL是由万里数据库维护的MySQL分支,专注于提升MGR可靠性及性能,支持InnoDB并行查询特性,是适用于金融级应用的MySQL分支版本。
Gitee:
https://gitee.com/GreatSQL/GreatSQL
GitHub:
https://github.com/GreatSQL/GreatSQL
Bilibili:
https://space.bilibili.com/1363850082/video
微信&QQ群:
可搜索添加GreatSQL社区助手微信好友,发送验证信息“加群”加入GreatSQL/MGR交流微信群
QQ群:533341697
微信小助手:wanlidbc
本文由博客一文多发平台 OpenWrite 发布!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号