用scrapy框架爬取映客直播用户头像
1. 创建项目 scrapy startproject yingke cd yingke
2. 创建爬虫 scrapy genspider live
3. 分析http://www.inke.cn/hotlive_list.html网页的response,找到响应里面数据的规律,并找到的位置,通过response.xpath()获取到
4. 通过在pipline里面进行数据的清洗,过滤,保存
5. 实现翻页,进行下一页的请求处理
6. 运行爬虫 scrapy crawl live
说明:这个程序直接在parse方法里面进行图片保存,保存在本地,正常使用yield关键字进行在pipline中保存。
# -*- coding: utf-8 -*- import scrapy import re class LiveSpider(scrapy.Spider): name = 'live' allowed_domains = ['inke.cn'] start_urls = ['http://www.inke.cn/hotlive_list.html?page=1'] def parse(self, response): div_list = response.xpath("//div[@class='list_box']") for div in div_list: item = {} img_src = div.xpath("./div[@class='list_pic']/a/img/@src").extract_first() item["user_name"] = div.xpath( "./div[@class='list_user_info']/span[@class='list_user_name']/text()").extract_first() print(item["user_name"]) yield scrapy.Request( # 发送详情页的请求 img_src, callback=self.parse_img, meta={"item": item} ) # 下一页 now_page = re.findall("page=(.*)", response.request.url)[0] now_page= int(now_page) next_url = "http://www.inke.cn/hotlive_list.html?page={}".format(str(now_page+ 1)) yield scrapy.Request( next_url, callback=self.parse ) def parse_img(self, response): user_name = response.meta["item"]["user_name"] with open("images/{}.png".format(user_name), "wb") as f: f.write(response.body)
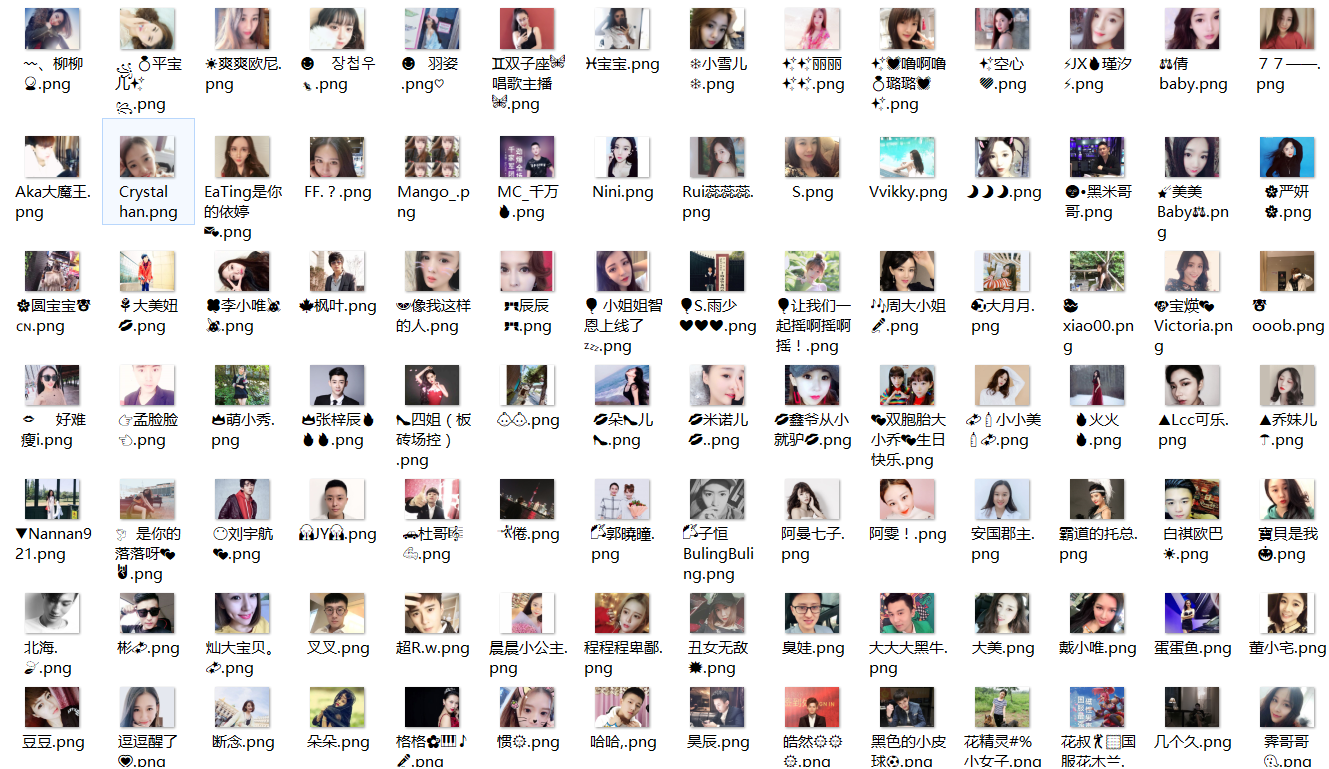
运行效果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号