2019秋招复习笔记--面试经历记录总结
2019年3月19日腾讯后台开发一面问题待解决(QQ浏览器搜索部门)
1. 你们搜索引擎的QPS有多少?
2000到10000左右
2. 关于文字搜索的部分, Lucene是怎么设置索引/关键字/相似性度量 的?
4. 你做的去重、检查有效性的工具在运行的时候监控过性能吗?哪种资源占用比较多?
5. 你们的搜索引擎支持图片搜索,是怎么做的?用了什么算法(提取图片特征用了什么算法)?
CNN-底层是VGG16, 之前用的是pHOG(分层梯度方向直方图(Pyramid Histogram of Oriented Gradients,PHOG) 是一种描述空间形状的特征向量)
6. 不管是图片的特征还是三维模型的特征, 你们提取了之后保存在数据库里面, 然后新来了一张图片, 你也计算了它的特征,那么如何度量这个特征与你数据库中已有图片的特征的相似度呢?
答:直接使用欧式距离计算。反问: 你们的数据量大概有三百万,你要是这么做的话,挨个计算距离效率也太低了吧?
正确答案:
提取特征之后,用Lire计算特征的局部敏感HashCode(局部敏感哈希的特征是3个字符一组,成为一个单词),然后HashCode采用String类型存储。如果有了一个新的检索项过来,先用同样的算法计算其特征以及局部敏感HashCode, 将其转为字符串。然后采取字符串匹配的方式寻找已经存储的HashCode中的匹配项。字符串匹配程度越高的说明相似性越大,这个交给Lire来做。采用倒排索引的方式来加快检索。数据库里的每个局部敏感HashCode都看作一个个的文档,统计所有文档里面的单词,并建立单词对应的文档索引(倒排索引)。对于被检索的HashCode, 也是分成一个个单词,去找哪些文档里面包含这些单词,按包含单词的多少返回检索结果。
LSH的基本思想是:将原始数据空间中的两个相邻数据点通过相同的映射或投影变换(projection)后,这两个数据点在新的数据空间中仍然相邻的概率很大,而不相邻的数据点被映射到同一个桶的概率很小。也就是说,如果我们对原始数据进行一些hash映射后,我们希望原先相邻的两个数据能够被hash到相同的桶内,具有相同的桶号。对原始数据集合中所有的数据都进行hash映射后,我们就得到了一个hash table,这些原始数据集被分散到了hash table的桶内,每个桶会落入一些原始数据,属于同一个桶内的数据就有很大可能是相邻的,当然也存在不相邻的数据被hash到了同一个桶内。因此,如果我们能够找到这样一些hash functions,使得经过它们的哈希映射变换后,原始空间中相邻的数据落入相同的桶内的话,那么我们在该数据集合中进行近邻查找就变得容易了,我们只需要将查询数据进行哈希映射得到其桶号,然后取出该桶号对应桶内的所有数据,再进行线性匹配即可查找到与查询数据相邻的数据。换句话说,我们通过hash function映射变换操作,将原始数据集合分成了多个子集合,而每个子集合中的数据间是相邻的且该子集合中的元素个数较小,因此将一个在超大集合内查找相邻元素的问题转化为了在一个很小的集合内查找相邻元素的问题,显然计算量下降了很多。
参考 : https://blog.csdn.net/liuheng0111/article/details/52292457
细节:图片提取的特征有4096个维度, 每个维度是一个浮点数,对于每个维度,在不做降维处理之前, 每个维度会对应产生3个字符长度的局部敏感HashCode, 所以一个特征生成的局部敏感HashCode长度为4096*3。但是HashCode作为检索项,如果太长了会影响检索速度,因此作了降维处理, 去除一些冗余的维度后,计算出来的HashCode总长在176个字符左右。
模型的方法类似。
7. 你们这个项目还有哪些可以改进的地方(主键设置不合理, 怎么设置)?
设置数据库主键,除了用自增的序列以外,还可以用UUID(UUID 是 通用唯一识别码(Universally Unique Identifier))
第一期的方案是Solr + MySQL, 缺点主要是每次更新需要重新导入MySQL数据,不得不停机更新;
改用ElasticSearch, 可以不适用数据库,直接插入JSON格式数据建立索引。只在持久化的时候使用MySQL.
8. 知道网络编程吗?了解网络IO模型吗?讲一讲IO多路复用
9. redis了解吗?你提到了redis的缓存替换策略, allkeys lru 替换策略中的 LRU(Least Recently Used)算法的原理是什么? 不知道? 那如果让你设计,应该怎么设计?
10. 如果让你设计一个数据库,实现增删该查这些功能, 有什么注意事项?
11. 讲一讲多线程编程?
数据库的知识问了很多
针对项目问了很多
一定一定一定要了解项目的所有细节!
2019年3月23日字节跳动后台开发一面问题
HashMap的底层原理,以及如何优化HashMap的查找效率?(HashMap怎么提高 解决Hash冲突的效率?)
MySQL数据库的索引,为什么用B+树不用B树?
数据库的隔离级别, 以及MySQL的默认隔离级别?
Redis常用的数据结构有哪些?(作死把redis往上写,结果连这个都说不全,面试之前需要认真检查简历上所写的一切,保证你能回答上跟简历上所写的任何一个点的中等难度左右的问题)
IO网络模型有哪些?说一说多路复用IO?
线程和进程有哪些区别?
TCP/UDP 的区别
三次挥手、四次握手
JAVA有哪些锁?
悲观锁和乐观锁的区别?
实现乐观锁的CAS方法,具体是怎么做的?这么做有什么问题?
来做一个题:
给你k个有序数组,请排成一个有序数组
先答归并,问时间复杂度。
提示可以用堆, 再问时间复杂度, 现场编程。
你有什么问题问我吗?
怎么提高我这弱鸡的代码能力?
多练习,多写,多总结;
怎么读源码,你们工作上经常读源码吗?
看你的目的,是为了解决工作上的需求就读某一个点; Debug源码;
面试题:1,进程和线程的区别?什么时候用进程?什么时候用线程?为什么你的项目中用的是线程?为什么不用进程?如果只有进程,对你这个项目有没有影响?
2019年4月21日百度JAVA开发一面问题
1. String, StringBuider, StringBuffer的区别, StringBuider和StringBuffer为什么是可变的,他们哪个是线程安全的;
2. CurrentHashMap介绍一下;ArrayList的线程安全版本是什么了解过吗?
3. Sychronized关键字加在类、方法和代码块上的区别是什么?
4. JUC java并发包;
5. MySQL有哪些引擎,介绍一下他们的区别;介绍一下B+树;
6. 介绍一下redis,以及为什么要用redis;
7. 你的论文是哪个期刊?
8. 代码题考的是二叉树的镜像。
9. Object类有哪些方法:
hashcode, equals, getClass, toString,wait, notify, notifyAll, finalize, clone方法
2019年4月24日腾讯正式批一面(腾讯地图)
- 问了一下项目,排序算法怎么做的?
- python的效率为什么低?
多线程
- python的多线程了解吗?(答不太了解,但了解JAVA多线程,讲了一些JAVA多线程)
- 线程之间怎么通信(操作系统级别的线程怎么通信)?
- 怎么用一个进程开另一个进程(说了fork)?
数据库
- MySQL的默认隔离级别?数据库有哪些级别?
- 怎么修改默认隔离级别?
- redis有哪些数据结构?redis持久化有哪些方法?redis线程怎么做的(大概是这个意思)?
计网
- HTTP header包含哪些内容?
- 其中的connection字段的作用是什么?
- TCP三次握手、四次挥手过程、为什么是三次不是两次,为什么等2MSL时间?
- HTTP是哪一层的协议,TCP的拥塞控制机制是怎么实现的?
搜索框架
- lucene方面了解的多吗?
- elesticsearch问了一下,有哪些API?
代码托管
- git 两个人的分支有冲突怎么合并,pull和fetch方法有什么区别?
代码加试:

2019年4月24日腾讯正式批二面(腾讯地图)
详细的问了项目,三维模型检索这块;整个的流程是怎么做的,去重是怎么做的,检索的效果怎么样;
论文, 论文整体是怎么做的,论文的算法(特征融合后的方法)放到三维模型检索系统里面去的效果又怎么样的提升;
你不是科班的,你觉得你做coding的优势和劣势有哪些?
劣势是没有学过计算机的很多专业课,但劣势可以转为优势:现在有目的的去学,能理解更深;
你目前拿了哪些OFFER?
你能实习多久?
2019年4月25日快手一面
问题问的比较常规,现在记不太清了,有印象的是讲了redis的两种数据持久化的方式: RDB快照和AOF;问了JAVA线程池的核心参数, threadlocal 变量; 问了数据库出现并发修改怎么办;
然后考了两道编程题:
1、用数组实现固定容量的队列,实现put函数和take函数
这一题在面试官的提醒下,用count记录队列长度的方法下,写出了如下代码:
 View Code
View Code两个功能测试正常
2、寻找矩阵的最长上升路径长度:
1 2 3 4 5 6
1 1 1 1 1 3
3 4 1 2 3 4
最长上升路径长度为6
解法是枚举每个起点做深搜,但是递归出口老写不对,截至面试结束调试的结果仍然不正确。下面的代码有问题
View Code阿里巴巴本地生活一面
1. 说一下java的集合,如果想要有序的取出元素怎么做(TreeSet)?
2. 数据库,隔离级别,索引
3. JAVA 虚拟机, GC的过程,GC的算法有哪些。
5. ThreadLocal的原理,ThreadLocal存的变量一定是线程隔离的吗?
6. linux命令, 如何在日志中定位error?
7. 算法题,给定一个数组,除了两个数字只出现了一次, 其他的数字都出现了两次,请找出这两个数字。(剑指OFFER原题)
2019.8.25腾讯地图再面
先做5道笔试题:
1. 写出访问www.lbs.tencent.com 经过的信息传输过程;
2. 写出线程的状态以及各个状态的互相转换条件;
3. 阐述Dijstra算法并写出代码;
4. 股票交易,给出一段时间的股票价格,确定最佳买入时间和最佳卖出时间,以及最大获利
5. 财主有一根可以折断的金条,财主雇了长工给他干活七天,财主用这根金条作为长工的工资。财主必须用金条日结长工的工资。问金条最少折断多少次,可以满足支付的要求。
面试:
0. Dijstra算法有什么缺陷不足之处?
1. 100G的硬盘上的整数型数据, 1G的内存。找出这100G数据里面所有不重复的数据。最少需要多大的辅助内存。
解法1:位图
int型的整数一共有232个,我们申请232 bits, 也就是232位, 用1位表示一个数是否出现了,0表示未出现,1表示出现了。比如4出现了,我们将这232位的第4位置为1。10000出现了则把第10000位置为1。这样232 bits = 232/8 = 229B, 我们知道210约等于1000, 230约等于109。故229 B = 2-1 * 109 B = 2-1 * 1GB = 500MB
;
拓展
如果用两位表示数出现的次数就可以分别统计出现0次、出现1次、出现2次和出现多次的数字。00表示未出现,01表示出现1次,10表示出现两次,11表示两次以上。然后扫描100亿个数,查看位图中对应的位置,如果是00,01,10,则加1变成01,10,11;如果是11,则不变。最后再扫描一遍位图,输出01,10对应的数。 2^32 * 2 = 8Gbits = 1GB。
那么这样做的情况下怎样找到这个数呢?我举个例子,例如我们此时读入一个数是:64,64对应的所在bit位是:64*2=128,也就是说第 127 和 128 位共同
标示了它的出现状态。其他的以此类推。每当我们读出一个数,我们就这样去找到它对应的bit位,先读出bit位的值,再做记录,已经是01的,再次来到,那么
就应该修改为10。最后的我们这样得出结果:扫描整个位图,如果是10的,就下标/2得出这个数。解法2:外排序,类似mapreduce的方法
2. 布隆过滤器有什么作用? 他有什么缺陷?
3. 1000杯水一杯水有毒,小老鼠喝了有毒的水一周后毒发身亡。小老鼠数量不限,如何最快找出这杯有毒的水。
4. 一个形状不规则的杯子装5L水,一个形状不规则杯子可装7L水。如何量出6L的水?
5. HashMap是怎么实现的?初始容量是多少?什么时候会扩容?
6. 什么是幂等性
7. Java Web的几大域?
8. Session与Cookie的区别;
9. TCP为什么是三次握手?什么叫信息对等?
10. 进程间通信的方式有哪几种? 共享内存怎么实现?
11. MySQL左连接和右连接有什么区别?
12. MySQL索引失效条件有哪些?
13. 一条语句执行很慢,怎么做MySQL查询优化?
2019.09.01 阿里中台技术一面
1. 讲一下实习的项目架构
2. 多个人同时点击下载按钮怎么办?
2. CountDownLatch怎么用的,如果latch里面有一个线程阻塞了怎么办?
3. 线程池的核心参数解释一下?
4. 线程池的拒绝策略有哪些?
5. 了解Java的内存模型吗?讲一下内存模型,GC?
6. 垃圾回收器CMS 和G1有什么区别?
https://www.cnblogs.com/greatLong/articles/11450753.html
7. 传统的IO和NIO有什么区别?
反思:
1. NIO 需要补
2. CMS和G1
3. 比较爱考实际场景的解决方案
2019.09.02 FreeWheel笔试
1. FreeWheel 对各地提供服务,如果客户发现某地的服务不可用,怎么排查和定位问题?
2. 什么是NAT? 他是为了解决什么问题提出来的?
IP地址只有32位,满打满算只有42.9亿个地址,还要去掉保留地址、组播地址,能用得只有36亿左右,IPv4很早就被列强瓜分完毕,感谢有NAT这项技术苦苦支撑,我们还可以继续在互联网遨游。
公司局域网、机构局域网、个人局域网可以使用私网IPv4地址(10.0.0.0/8,172.16.0.0/12,192.168.0.0/16),然后在各个局域网的边界WAN口使用一个或多个公网IPv4进行一对多的转换。
如果是一对一转换,那压根节省不了IPv4地址空间;所以一般NAT都是一对多的,即一个公网IPv4映射多个私网IPv4,那问题来了,NAT设备如何区分不同的私网IPv4的host呢?
NAT使用基于session 转换规则:
对于TCP/UDP使用
Host's私有IPV4+Port <------->NAT公网IPV4+Port
对于ICMP使用Host's 私有IPv4+session ID<----->NAT公网IPv4+session ID
规则其实非常好理解,由于session ID在NAT设备上是独一无二的,所以NAT可以很容易区别局域网内部的不同host。
至于其它传输协议,NAT使用的也是类似session ID的转换规则,即使用可以将不同host 轻易分辨出来的字段做键值(KEY),动态创建映射表项,做双向的地址+KEY的转换。
3. 阐述5个HTTP的方法,并讲述他们在RESTful中的...(忘了)?
常用的5个方法是DG3P(Delete, Get, Post, Put, Patch)
4. 简述系统调用,什么是系统调用?
每个进程的虚拟地址空间可以划分为两个部分:用户空间和内核空间。在用户态下只能访问用户空间;而在核心态下,既可以访问用户空间,又可以访问内核空间。系统调用是在内核完成的。
6. 什么是虚拟内存,虚拟内存有什么作用?
从概念上来说,虚拟内存被组织成为一个由存放在磁盘上的 N 个连续的字节大小的单元组成的数组,也就是字节数组。每个字节都有一个唯一的虚拟地址作为数组的索引。磁盘上活动的数组内容被缓存在主存中。在存储器结构中,较低层次上的磁盘的数据被分割成块,这些块作为和较高层次的主存之间的传输单元。主存作为虚拟内存的缓存。
5. 简述数据库ACID的含义?
6. 一个score数据表,有学生ID, 科目, score三个字段, 输出所有score相同的字段?
MySQL中,查询表(dat_bill_2018_11)中字段(product_id)值重复的记录:
SELECT product_id, COUNT(*) AS sumCount FROM dat_bill_201811 GROUP BY product_id HAVING sumCount > 1;说明:先用GROUP BY 对 product_id 进行分组,同时使用COUNT(*)进行统计,再用HAVING来过滤大于1的,这样查找出来的就是重复的记录了。
7. 编程题:
给定一个数组[7,6,4,2,10,8], 一个整数m。把这个数组分成m个子数组,每个子数组统计其和。把所有子数组和的最大值作为该分隔方案的值,输出所有分隔方案里面的最小值。
如[7,6,2,10,8]分隔成两个子数组,分成[7,6,2], [10, 8]时是所有分隔方案里子数组和的最大值最小的方案,输出18。
8. 算法题,抽象起来,是有一棵树(多叉树),然后给定这棵树的两个节点,找出这两个节点的最近公共祖先。
9. 系统设计题:
1) 如何设计一个系统统计广告播放次数;
2) 广告播放模块和频次统计模块如何通信
3) 如果服务器在不同国家(如美国、欧洲),怎么保证系统的高并发高可用。
面试题:
1. leetcode brick walls;
2. leetcode 410
3. 随着系统的更新,linux的/boot空间下积攒了越来越多的旧的内核文件,如何删除这些旧的内核文件?
4. 数据库问了一些不太深的东西,redis和Mysql 的区别与联系。
反思:
1. 手写SQL没有写对
2. 问了下CDN网络,不知道
3. leetcode的题不太难,但没有提供出最有解,需要多刷题。
2019.09.11 腾讯运营管理一面
2019.09.11 阿里巴巴中台交易流水二面
1. 讲下Java线程池,什么时候会用到线程池(降一个场景)?
2. 围绕着流量导出项目问:
1) 你的导出过程用了子线程countDownLatch, 如果有一个子线程挂了怎么办?
await()设定等待时间
2) 如果await超时返回了或者抛出异常了怎么办?怎么排查?排查出原因怎么恢复?
3) 如果数据量很大,你怎么加快导出速度?
4)给你一台服务器,8核,最多能开几个线程?
不知道
对于32位系统来说,没有配置3GB用户内存模式的情况下,用户地址空间可用内存是2GB-128KB,内核可用内存是2GB。开启以后,用户地址空间可用内存是3GB-128KB
理论上,一个用户进程最大可以分配的内存是2G(实际能用的大约为1.5G),一个线程栈需要预留1M内存空间,那么理论数据:32位电脑每个进程最多可以开2*1024/1=2048个线程,即2000个左右线程。线程是好东西,但是不能滥用,因为像在windows系统下,系统是抢占式的,线程多了,系统在线程间切换也要花费非常多时间和资源。
默认情况下,一个线程的栈要预留1M的内存空间
而一个进程中可用的内存空间只有2G,所以理论上一个进程中最多可以开2048个线程
但是内存当然不可能完全拿来作线程的栈,所以实际数目要比这个值要小。
你也可以通过连接时修改默认栈大小,将其改的比较小,这样就可以多开一些线程。
如将默认栈的大小改成512K,这样理论上最多就可以开4096个线程。即使物理内存再大,一个进程中可以起的线程总要受到2GB这个内存空间的限制。
比方说你的机器装了64GB物理内存,但每个进程的内存空间还是4GB,其中用户态可用的还是2GB。
如果是同一台机器内的话,能起多少线程也是受内存限制的。每个线程对象都要站用非页面内存,而非页面内存也是有限的,当非页面内存被耗尽时,也就无法创建线程了。
如果物理内存非常大,同一台机器内可以跑的线程数目的限制值会越来越大。在Windows下写个程序,一个进程Fork出2000个左右线程就会异常退出了,为什么?
这个问题的产生是因为windows32位系统,一个进程所能使用的最大虚拟内存为2G,而一个线程的默认线程栈StackSize为1024K(1M),这样当线程数量逼近2000时,2000*1024K=2G(大约),内存资源就相当于耗尽。
5) 假设能开10个线程,要多少轮次才能导完1000万条记录?
6) 你说分库分表,那么一张MySQL表最多存多少数据?
6.5) 你的导出的各个小的表的数据怎么merge的?
7) 好的给你加机器,你这个分布式的导出系统有几个模块?
8) 怎么保证导出数据的实时性?(导出的时候数据不能再写到这个库了,那导出期间的数据怎么办?)
读写分离,从库导出主库写入,记录导出阶段的新数据
9) MySQL的事务是怎么实现的?
反思:
1. 对迁移能力要求比较高,需要对具体场景提出相应的解决方案。需要通过多看大数据、高并发场景的设计方案来提高自己。
2. 对MySQL需要全面的学习和掌握,本次面试的MVCC, 事务的实现方法没有很好的掌握,单表最大容量等。
2019.9.18 依图两轮面试
第一轮
介绍项目经历
1. 项目细节
如果你的服务挂了怎么还原?
如果多人同时访问你的服务怎么处理?
2. 计算机网络方面的知识
tcp, udp 拥塞控制的原理,怎么实现的。
代码题:最大连续子序列和
第二轮面试
1. 实验室项目经历
2. 实习项目经历问的比较少
代码题
字符串中回文字符串的数目
第三轮面试
1. 挑你觉得最有收获的项目经历讲一讲
2. 为什么你觉得第二段实习经历更有收获
3. 你希望你的工作环境是什么样的?
4. 写个题: 反转链表
5. 你对你应聘的这个岗位有什么理解?
2019.9.19 旷视两轮面试
第一轮面试
讲项目架构。
如果你的redis分布式锁发生死锁了怎么办?
setnx加锁 del解锁 expire设置超时时间 set(key, value, nx, time)可以让setnx和 设置超时时间变成原子的。
服务挂了怎么恢复?
Java 集合类有哪些, list set map哪个是顶层接口? set的实现有哪些? ArrayList和linkedlist的区别是什么, 看过源码吗? 建议看一下源码。
String 类哪些方法是final的? 建议看一下源码?
线程池, 如果有新任务来了,在线程池有空余线程的情况下,是先进workque再出队列去取线程池取线程, 还是直接去线程池取线程?
https://www.cnblogs.com/dafanjoy/p/9729358.html
写了个简单的题:
一个链表 绝对值有序,请将其排序。
-1 -> 2 -> -3 -> 4 -> -5
最终输出为
-5 -> -3 -> -1 -> 2 -> 4
第二轮面试
算法题
0 1 5 6
2 4 7 12
3 8 11 13
9 10 14 15
按0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 的顺序打印这个矩阵。
线程和进程的区别。
问了 卡特兰数 n辆车进站,问有多少种出站顺序
百度智能云开发部面试
一面
1. 项目经历
2. 查看某个磁盘下哪个文件夹占用比较多用什么命令
使用df -h查看磁盘空间占用情况
使用sudo du -s -h /* | sort -nr命令查看目录占用空间
du的功能: `du` reports the amount of disk space used by the specified files and for each subdirectory (of directory arguments). with no arguments,`du` reports the disk space for the current directory。很明显,与df不同,它用来查看文件或目录所占用的磁盘空间的大小。二、du常用的选项:-h:以人类可读的方式显示-a:显示目录占用的磁盘空间大小,还要显示其下目录和文件占用磁盘空间的大小-s:显示目录占用的磁盘空间大小,不要显示其下子目录和文件占用的磁盘空间大小-c:显示几个目录或文件占用的磁盘空间大小,还要统计它们的总和
3. 一个磁盘明明还有空余但却不能创建新文件,为什么
4. 写个SQL语句: SQL从成绩表中找出排名前三的学生信息(一个学生可能有多门课的成绩)
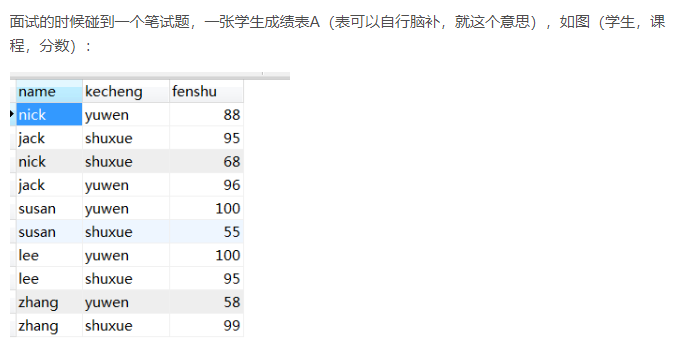
SELECT name from a GROUP BY name ORDER BY sum(fenshu) DESC LIMIT 0,3 ;
5. 查看网络端口用什么命令
6. 面向对象编程的特点
7. 你怎么理解面向接口编程
8. tcp三次握手会产生哪些数据包
9. 每个数据包会交换哪些信息
10. 一个tcp可以支持多少个http连接
11. 算法题: 对两个有序链表排序
二面
1. 项目经历
2. 算法题: 找出一个数组中第三大的数组(数组有重复数字),如果不存在第三大的数组返回-1
3. 智力题: 36匹马, 6条跑道, 怎样用最少的比赛次数找出跑的最快的前3匹马
4. 聊天
度小满面试
一面
1. 怎么样中断线程
来源
https://www.cnblogs.com/liyutian/p/10196044.html
https://www.cnblogs.com/luckygxf/p/4737655.html
1. Thread.stop()方法:
该方法已经被弃用(a.会立即停止run方法所有工作,报错catch finnally语句,导致清理工作无法完成; b. 会立即释放该线程持有地所有地锁,出现线程不同步的问题。)
来源 https://www.cnblogs.com/lt132024/p/6438897.html
a. 对正常运行中的线程,interrupt() 方法仅仅是在当前线程中打一个停止的标记(Thread.interrupted()方法返回中断标志位的状态并且清除中断标志位, Thread.IsInterrupted()方法返回中断标志位并且不清除中断标志位),并不是真的停止线程,需要由目标线程自行根据标记来决定如何处理中断;
b. 对于处在阻塞态的线程,由于代码阻塞无法检查中断标志位,对该线程对象调用interrupt()方法会使得其抛出一个InterruptedException。
3. 使用人为设置的标志位终止线程(共享变量)
在 run() 方法执行完毕后,该线程就终止了。可以设置的一个标志位循环检查该标志位来决定是否退出循环。
2. AtomicInteger怎么保证原子性的
3. 用interrupt中断线程有什么不好的地方
4. GC的过程, 什么样的对象可以作GC root使用?
4.1 部署JVM项目有哪些虚拟机参数可以调?
5. HashMap 怎么实现的
6. 如果我自己定义了一个类作为HashMap的key应该注意些什么(重写HashCode), 为什么?
7. 重写equals方法要注意些什么
8. 一个类里面有两处代码,一个方法加了方法锁,一个代码块使用Object对象加了锁。这两个代码都操作一个int型的变量, 怎么保证线程安全
9. 编译型语言和解释型语言有什么区别?(强类型、弱类型)
写了两道算法题:
a. 河滩上有两堆石子,一堆红色一堆蓝色,怎么把所有的红色石子放到蓝色的前面?
红色石子设为1, 蓝色石子设为0, 排成一列的石子中,将所有的1放到0前面。
b. 用快排写topK
二面
说一下数据库的锁机制
redis作分布式锁是怎么实现的
说一下死锁
说一下GC
知道Spring 的AOP吗?
知道 RPC吗?
代码题:
逆时针打印矩阵
三面:
1. 对自己前面的面试表现比较满意的有哪些,不太满意的有哪些?
2. 平时自己怎么学习的? 有写博客?博客地址发我看看。
3. 用过kafka吗?
4. 介绍项目
猿辅导一面
1. 知道redis setnx底层的机制吗
2. 方法区在哪, 元数据区保存的是什么?
3. set(key, value, nx, time)有没有其他问题。
有。如果某些原因导致线程B执行的很慢很慢,过了30秒都没执行完,这时候锁过期自动释放,线程B得到了锁。随后,线程A执行完了任务,线程A接着执行del指令来释放锁。但这时候线程B还没执行完,线程A实际上删除的是线程B加的锁。
解决:
可以在del释放锁之前做一个判断,验证当前的锁是不是自己加的锁。
至于具体的实现,可以在加锁的时候把当前的线程ID当做value,并在删除之前验证key对应的value是不是自己线程的ID。
4. 给定一个数字字符串,判断他可能的合法的IP方案。leetcode 95
5.卫语句
https://www.cnblogs.com/Braveliu/p/7364369.html
函数中的条件逻辑使人难以看清正常的分支执行路径。使用卫语句表现所有特殊情况。
所谓卫语句,如果某个条件极其罕见,就应该单独检查该条件,并在该条件为真时立刻从函数中返回。这样的单独检查常常被称为“卫语句”。
6. CMS垃圾回收器垃圾回收有几个阶段?(G1有哪些阶段?)
2019_09_28 猿辅导二面
0. 问了下项目经历,你这个项目有哪些技术难点?
1. 线程池的核心参数
2. 了解cachedThreadPool吗
3. Redis为什么QPS高?
4. Linux怎么查看日志的行数
sed -n '$=' 文件名
cat 文件名 | wc -l
wc -l 文件名
5. 软连接和硬链接有什么区别
在Linux的文件系统中,保存在磁盘分区中的文件不管是什么类型都给它分配一个编号,称为索引节点号inode 。
软连接,其实就是新建立一个文件,这个文件就是专门用来指向别的文件的(那就和windows 下的快捷方式的那个文件有很接近的意味)。软链接产生的是一个新的文件,但这个文件的作用就是专门指向某个文件的,删了这个软连接文件,那就等于不需要这个连接,和原来的存在的实体原文件没有任何关系,但删除原来的文件,则相应的软连接不可用(cat那个软链接文件,则提示“没有该文件或目录“)
- 硬连接是不会建立inode的,他只是在文件原来的inode link count域再增加1而已,也因此硬链接是不可以跨越文件系统的。相反是软连接会重新建立一个inode,当然inode的结构跟其他的不一样,他只是一个指明源文件的字符串信息。一旦删除源文件,那么软连接将变得毫无意义。而硬链接删除的时候,系统调用会检查inode link count的数值,如果他大于等于1,那么inode不会被回收。因此文件的内容不会被删除。
- 硬链接实际上是为文件建一个别名,链接文件和原文件实际上是同一个文件。可以通过ls -i来查看一下,这两个文件的inode号是同一个,说明它们是同一个文件;而软链接建立的是一个指向,即链接文件内的内容是指向原文件的指针,它们是两个文件。
- 软链接可以跨文件系统,硬链接不可以;
- 软链接可以对一个不存在的文件名(filename)进行链接(当然此时如果你vi这个软链接文件,linux会自动新建一个文件名为filename的文件),硬链接不可以(其文件必须存在,inode必须存在);
- 软链接可以对目录进行连接,硬链接不可以。
- 两种链接都可以通过命令 ln 来创建。ln 默认创建的是硬链接。
使用 -s 开关可以创建软链接。
6. 代码题:
对stack里面的数排序,可以用辅助栈,不能用其他数据结构
7.代码题:
对链表的给定区间翻转
大华一面
用过mybatis? foreach标签有什么用?
Java IO了解吗?
HashMap key为null会被放到哪?
单索引和联合索引的区别?
怎么优化一条运行的很慢的SQL语句?
为什么%like不走索引?
Sychronized 和 Lock 有什么区别?
ConcurrentHashMap 怎么实现线程安全的? 内部分段分了几段?
线程有哪些状态?
线程的这些状态之间的转换用什么函数?
怎么开启一个新线程?
继承Thread和实现Runnable接口有什么区别?
ArrayList底层是怎么实现的?
快手一面
1. 说下JVM内存模型
2. 程序计数器是怎么工作的?
3. CMS的几个工作阶段
4. JVM中多个线程同时申请堆上的内存,会不会出现冲突
5. Sychronized关键字和Lock有什么区别?
6. ReentrenLock和Sychronized关键字有什么区别?
7. 线程池的工作原理, workque的类型
8. 计算机网络的七层模型的作用分别是什么?
9. 写一个最大堆
快手二面
前一面的面试官都问了你什么?
写一个单例模式.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号