
爬虫综合大作业
作业来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3159
项目仓库地址:https://github.com/P-and-A/MyScrapy.git
基于文本分析的网络招聘信息挖掘
- 背景
互联网飞速发展,网站上的信息的发布方式呈现多元化和多样化。对于发现人才市场的发展情况,网络招聘以自身的效率高、传递信息快、广泛性等特点,成为求职人首选。分析招聘网站上产生的大量数据,数据挖掘技术就占据了很大的优势。在大量的文献研究中表明,基于文本挖掘和关联算法在网络招聘中的应用性就尤为突出。本文主要对拉钩招聘网的招聘数据进行分析,利用文本挖掘对职位标签,职位描述抽取关键字。其次,使用Excel的数据透视表对城市、学历、工作经验、工资待遇和热门行业属性进行统计分析,并绘制出可视化数据表。通过分析,得出当今社会对人才需求情况。
- 网络招聘信息挖掘综述
2.1. 文本挖掘定义及使用的技术
2.1.1. 文本挖掘定义
文本挖掘是抽取有效、新颖、有用、可理解的、散布在文本文件中的有价值知识,并且利用这些知识更好地组织信息的过程。1998年底,国家重点研究发展规划首批实施项目中明确指出,文本挖掘是“图像、语言、自然语言理解与知识挖掘”中的重要内容。
文本挖掘是信息挖掘的一个研究分支,用于基于文本信息的知识发现。文本挖掘利用智能算法,如神经网络、基于案例的推理、可能性推理等,并结合文字处理技术,分析大量的非结构化文本源(如文档、电子表格、客户电子邮件、问题查询、网页等),抽取或标记关键字概念、文字间的关系,并按照内容对文档进行分类,获取有用的知识和信息。
2.1.2. 文本挖掘技术
本次采用了国内程序员用python开发的一个中文分词模块。
2.2. 网络招聘信息挖掘的流程

- 网络招聘信息挖掘步骤
3.1. 导入通过爬虫爬取的文本信息
数据流向有两个方向,一个是通过Excel自带的数据透视表对招聘信息中的数值及简单文本进行数据关联性分析,数据主要有工作城市、学历要求、工资范围、工作经验、工作领域、公司的融资情况等等,选取这些数据也是因为Excel对这些数据的处理比较方便,使用Excel的缺点就是无法系统地处理不规律的文本。
另一个是通过python语言处理复杂的文本信息,数据主要有招聘信息的标签,招聘描述。
3.2. 使用Excel自带的数据透视表进行分析
选取不同属性值进行关联性分析,结果如下:
l 公司的地域分布
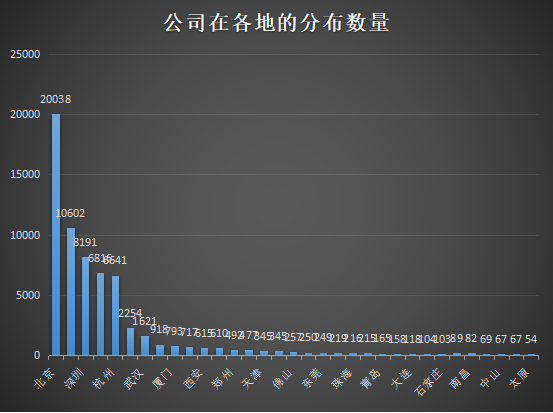
从图中可以看出,发布招聘信息的公司,来自北京的占绝大多数,这跟城市的定位有关系,北京作为中国的首都,经济发展自然是没得说,公司总数也占了全国的多数,而且中国的两大名校,清华、北大也身处北京,人才唾手可得,近在咫尺,自然是要吸纳多一些发展公司的嫩芽。北上广深作为一线城市,互联网发展处于第一梯队理所当然,而有阿里、网易驻扎的杭州紧随其后,地处天府之国的成都也不甘示弱,其互联网产业目前也是蓬勃发展,武汉也有迎头赶上的姿态。其它的也就不分析了。
l 公司的融资情况

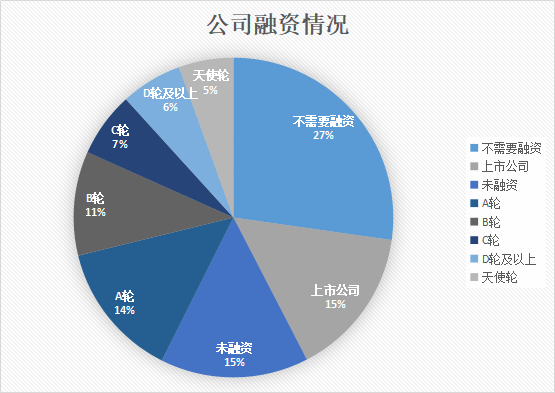
从公司的融资情况来看,大批未融资的公司积蓄力量,慢慢发展公司实例等待着市场和资本的考验,天使轮阶段的公司其实不多,从A轮到C轮,每一个节点之后的公司数量都基本减半,而在D轮及以上,公司数量却呈上升趋势,可见,融资处于C轮阶段的公司是公司发展的一个里程碑,而上市公司虽然以及稳定,但是在这个资本以及科技高速发展的时代,公司还是需要人才来增长公司实力,发展公司业务的。

从上图可以看到,公司的发展基本上需要资本的参与,公司处于天使轮或是为融资,公司其实不需要招聘太多人,因为公司规模还很小,甚至只是一个概念而已,两阶段的公司所需的职位数基本持平,当公司进入A轮及后面的融资阶段后,对招聘的需求大大增加,说明公司的业务发展也非常迅速,急需用人,这个需求增长在D轮达到最高。D轮之后,公司发展进入另一个稳定阶段,对招聘的需求开始降低。
l 工资情况
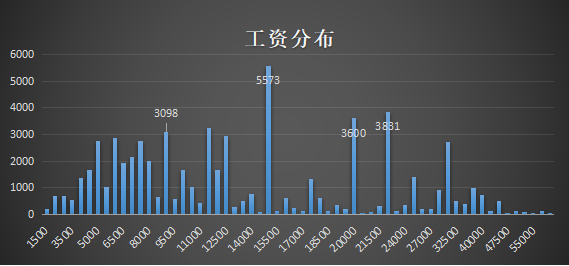
从工资分布图来看,工资分布情况没有较大统一规律性,大致像一个驼峰的形状,就这样而言比较难找规律,以工资15000为分界线,月工资在15000以下的职位还是占绝大多数,为什么还有那么多人能拿不算低的工资呢,我觉得可以结合发布招聘信息城市来分析,就像大多数职位都是来自北上广深的公司的,而且和当地的放假和消费水平也有关。月工资在15000以上的也有几个下降和增长的阶段,由此可见,公司企业还是对人才的价值付得起钱的。
l 学历与工资


上面这两张图展示的是学历与求职的关系,前一幅图说明,总体来看,博士生的薪水是最高的,硕士生的低于硕士,硕士生与博士生的工资偏差要大于其它学历与上一级学历要求的工资偏差,说明了工资随学历要求增长并不是简单的线性增长,学历越高越难考取,能拿到的工资自然也要翻几番。大专学历和不限学历的工作,薪水差异比较小,高端人才和普通人的区别还是很明显的。本科生的处于中间。后一幅图说明当前的职位招聘更多集中在本科和大专和学历不限这几个级别,对要求硕士和博士的还是很少。职位招聘并没有对学历有那么高的起步要求。因此,就薪水这一点考虑,相信大家对学历追求会有自己的选择。不必为了拿取高工资,而盲目考取高学历,就本科学历而言还是非常有用的。
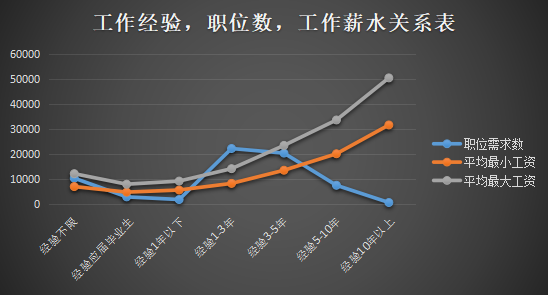

以上两张图展示了工作经验在找工作中的重要性,前一幅图说明,工作年限越长,薪水待遇总体越高,公司更愿意给经验丰富的求职者好的待遇,因为一般来说工资经验代表着工作能力和工作经验,能有那么长工作经验的人,一般都是适应了这个行业的老手了。后面的图说明1-3年工作经验的是招聘中的主要目标人群,一方面已经不再是刚毕业的应届生,具有工作的实战经历,另一方面,3年工作期满,很多人希望换一个环境,或是之前的工作环境已经适合不了自身发展。10年以上工作经验的,虽然待遇很不错,但是招聘职位并不多,一般这样的职场老鸟,工作也比较稳定,也比较少换工作。
l 主流岗位的情况比较
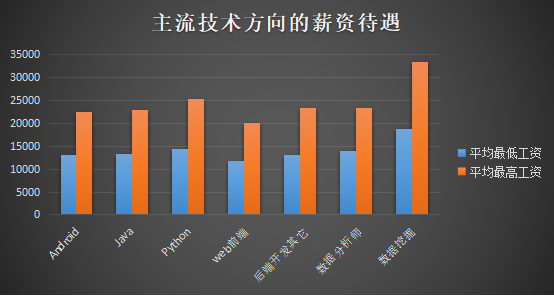
上面的图展示了七个方向的薪资待遇,可以看出在这个大数据时代,关于数据方面的职位薪资高于其他方向,高薪资会吸引很多人才转行或从事这个行业。

从上图可以看出无论是哪个行业对具有3-5年经验的人才都有较大的需求,其次是1-3年经验的。具有3-5年经验的人才往往对他从事的行业有比较全面的了解,能尽快上手工作、融入工作中,一定程度上减少了培养成本。
3.2. 招聘信息长文本属性处理
3.2.1. 分词
我们主要爬取的信息为中文,中文不像英语句子那样,一个单词就有一个空格间隔,为了更加便利的统计分析,必须对获取的大量非结构化数据进行中文分词,提取特定的或者自己想要的数据。一般来说,分词就是在一段话中或是一句话中提取单独的词语。我们对爬取的大量数据主要采用TF-IDF算法进行分词,它也是python结巴分词库里的一个函数。TF-IDF(term frequency–inverse document frequency)是一种用于资讯检索与资讯探勘的常用加权技术。TF-IDF是一种统计方法,用以评估一个词语对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
在一份给定的文件里,词频(term frequency,TF)指的是某一个给定的词语在该文件中出现的频率。这个数字是对词数(term count)的归一化,以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词数,而不管该词语重要与否。)对于在某一特定文件里的词语 ti来说,它的重要性可表示为:
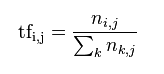
以上式子中 ni,j 是该词ti 在文件dj中的出现次数,而分母则是在文件dj中所有字词的出现次数之和。
逆向文件频率(inverse document frequency,IDF)是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到:

其中,|D|为语料库中的文件总数,在我们抓取的数据中,我们把一条招聘信息当做一个文件,文件总数即为我们抓取的招聘信息数目的总和;|j:ti∈dj|为包含词语ti的文件数目(ni,j≠0的数目),如果该词语不在语料库中,就会导致被除数为零 ,因此一般情况下对分母进行+1操作,即|j:ti∈dj|+1。
然后,
Tfidfi,j = tfi,j × idfi
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
有很多不同的数学公式可以用来计算TF-IDF。我们以上述的数学公式加上一个例子来进行这个公式的演算。词频 (TF) 是一词语出现的次数除以该文件的总词语数。假如一篇文件的总词语数是100个,而词语“移动互联网”出现了5次,那么“移动互联网”一词在该文件中的词频就是5/100=0.05。一个计算文件频率 (DF) 的方法是测定有多少份文件出现过“移动互联网”一词,然后除以文件集里包含的文件总数。所以,如果“移动互联网”一词在1,0000份文件出现过,而文件总数是10,000,000份的话,其逆向文件频率就是 log(10,000,000 / 1,0000)=3。最后的TF-IDF的分数为0.05 * 3=0.15。
l 设置自定义词典
在进行分词的过程中,我们发现,结巴分词的TF-IDF算法对我们提供的文本信息进行分词的时候,会出现以下问题,比如,在分“移动互联网”这个词的时候,它有时会把“移动”和“互联网”当成是两个词从而分出来,但是这并不是我们想要的结果,会影响到我们对词频的计算,所以我们对一些专有、专业名词进行预先定义,把一些结构像“移动互联网”那样的词加入了我们分词的自定义词典,当程序在进行分词的时候,遇到这类词就会读取我们定义的词典,而不会再去划分词语,所以这样可以解决此算法的缺陷。
l 设置频繁干扰分词的停用词
在分词结果中存在很多连词、感叹词、介词、助词以及标点符号,或者一些通用名称词,如“描述”、“发布”等,称为停用词,他们对区分文本没有作用,需要将它们删除或过滤掉。设置完停用词之后,相比一开始的分词结果,精简了许多,去掉了例如“,”、“、”,“的”、之类的停用词。

设置了自定义词典和停用词之后的效果

没有设置自定义词典和没有使用停用词的效果

停用词

自定义词典
3.2.2. 词频统计与词云
对分词的结果做一个词频统计,计算出每个词出现的次数并统计它们的词频,然后用python第三方库wordcloud来绘制词云。

工作福利词云

工作标签词云
从词云可以形象看出公司主要福利都是五险一金、双休,招聘的职位主要是分布在Java、数据分析、广告这些领域上。

关联分析是发现事物之间关联关系的分析过程,其典型应用就是购物篮分析。购物篮分析是确定顾客在一次购物中可能一起购买的商品,发现其购物篮中不同商品之间的联系,分析顾客的购买习惯,从而发现购买行为之间的关联,这种关联的发现可以帮助零售商制定营销策略,既然这么说,我们也能通过分析招聘信息,来分析招聘规则,以此来帮助就业者就业,有选择的投简历。
我们使用了Weka的Apriori算法来提取招聘信息的规则,我们设置了最小置信度为0.9,得出了以上的关联规则,我就举其中一两个说明一下,比如第一条,如果一个公司的招聘信息要求应聘者的工作经验为3-5年,并且学历要求为本科,那么这份工作工作类型为全职,而且这条关联规则的置信度为100%。比如第四条,如果一个公司的招聘信息要求应聘者的学历为本科,那么这份工作工作类型为全职,这条关联规则的置信度为99%。
- 结果与建议
从挖掘结果看,高校可有针对性的调整人才培养方案,开设R、Java、Python语言课程,提升学生应用相关软件的能力,积累解决实际问题的经验,学会团队协作。企业对市场营销、软件和产品的开发与设计类人才需求量较大,应届毕业生要重视参加软件和产品的开发、设计等职业培训工作,适度利用业余时间做兼职,积累工作经验,在实践中学习与客户沟通的技巧。
此外,我们不难看出移动互联网行业发展前景广阔,求职者若对移动互联网、大数据感兴趣,可优先考虑向技术类方向发展,并且要注意工作经验的积累。若求职者想要去规模较大的上市公司,那么有较高学历的技术型人才有较大优势。
最后感谢李家俊在分词,原理分析,文档编辑等方面的大力帮助,帮助我解决了中间遇到的很多问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号