ClickHouse学习笔记
1. 概述
ClickHouse是一个用于联机分析(OLAP:Online Analytical Processing)的列式数据库管理系统(DBMS:Database Management System),简称CK。
ClickHouse是一个完全的列式数据库管理系统,允许在运行时创建表和数据库,加载数据和运行查询,而无需重新配置和重新启动服务器,支持线性扩展,简单方便,高可靠性,容错。
ClickHouse官方文档:https://clickhouse.yandex/docs/en/
2. 应用场景
OLAP场景关键特征:
- 大多数是读请求
- 数据总是以相当大的批(> 1000 rows)进行写入
- 不修改已添加的数据
- 每次查询都从数据库中读取大量的行,但是同时又仅需要少量的列
- 宽表,即每个表包含着大量的列
- 较少的查询(通常每台服务器每秒数百个查询或更少)
- 对于简单查询,允许延迟大约50毫秒
- 列中的数据相对较小: 数字和短字符串(例如,每个UR60个字节)
- 处理单个查询时需要高吞吐量(每个服务器每秒高达数十亿行)
- 事务不是必须的
- 对数据一致性要求低
- 每一个查询除了一个大表外都很小
- 查询结果明显小于源数据,换句话说,数据被过滤或聚合后能够被盛放在单台服务器的内存中
应用场景:
用于结构良好清晰且不可变的事件或日志流分析。
不适合的场景:
事务性工作(OLTP),高请求率的键值访问,低延迟的修改或删除已存在数据,Blob或文档存储,超标准化数据。
3. 数据类型
- 整型
固定长度的整型,包括有符号整型或无符号整型。
整型范围:
Int8 - [-128 : 127]
Int16 - [-32768 : 32767]
Int32 - [-2147483648 : 2147483647]
Int64 - [-9223372036854775808 : 9223372036854775807]
无符号整型范围:
UInt8 - [0 : 255] :可以使用 UInt8 类型,取值限制为0或1作为Boolean型
UInt16 - [0 : 65535]
UInt32 - [0 : 4294967295]
UInt64 - [0 : 18446744073709551615]
- 浮点型
建议尽可能以整数形式存储数据。
Float32 - float
Float64 - double
Decimal32(S) - [ -1 * 10^(9 - S) : 1 * 10^(9 - S) ]
Decimal64(S) - [ -1 * 10^(18 - S) : 1 * 10^(18 - S) ]
Decimal128(S) - [ -1 * 10^(38 - S) : 1 * 10^(38 - S) ]
Decimal(P, S)
P - 精度。有效范围:[1:38],决定可以有多少个十进制数字(包括分数)。
S - 规模。有效范围:[0:P],决定数字的小数部分中包含的小数位数。
- 字符串型
文本格式建议使用UTF-8 编码。
String:任意长度
FixedString(N):固定长度N的字符串,N必须是严格的正自然数。
UUID:默认值00000000-0000-0000-0000-000000000000
- 日期型
Date:最小值为0000-00-00
DateTime:最小值为 0000-00-00 00:00:00
- 枚举型
Enum8:用 'String'= Int8 对描述。
Enum16:用 'String'= Int16 对描述。
- 数组型
Array(T):由T类型元素组成的数组,T可以是任意类型,包含数组类型,但不推荐使用多维数组。
- 元祖型
Tuple(T1, T2, ...):不能在表中存储元组(除了内存表),它们可以用于临时列分组。
- 其他
Nullable(TypeName):许用特殊标记 (NULL) 表示"缺失值",可以与 TypeName 的正常值存放一起。例如,Nullable(Int8) 类型的列可以存储 Int8 类型值,而没有值的行将存储 NULL。
Nested(Name1 Type1, Name2 Type2, ...):嵌套数据结构类似于嵌套表。嵌套数据结构的参数(列名和类型)与 CREATE 查询类似。每个表可以包含任意多行嵌套数据结构。
IPv4:如116.253.40.133
IPv6:如2a02:aa08:e000:3100::2
4. 表引擎
表引擎(即表的类型)决定了:
- 数据的存储方式和位置,写到哪里以及从哪里读取数据
- 支持哪些查询以及如何支持。
- 并发数据访问。
- 索引的使用(如果存在)。
- 是否可以执行多线程请求。
- 数据复制参数。
在读取时,引擎只需要输出所请求的列,但在某些情况下,引擎可以在响应请求时部分处理数据。对于大多数正式的任务,应该使用MergeTree族中的引擎。
4.1. MergeTree Family
MergeTree(合并树)引擎及其家族(*MergeTree)的其他引擎是ClickHouse健壮性最强的表引擎。
主要特点:
- 存储的数据按主键排序。允许创建一个小的稀疏索引来帮助快速查询数据。
- 允许在指定分区键时使用分区。
- 支持数据复制。
- 支持数据采样。
4.1.1. MergeTree
建表语句:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster] ( name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1], name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2], ... INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1, INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2 ) ENGINE = MergeTree() [PARTITION BY expr] [ORDER BY expr] [PRIMARY KEY expr] [SAMPLE BY expr] [SETTINGS name=value, ...]
- ON CLUSTER cluster:指定分片,可用于建分布式表。
- ENGINE - 引擎名和参数(必填)。
- PARTITION BY — 分区键(可选)。
参数为Date类型,默认要天分区;要按月分区,可以使用表达式toYYYYMM(date_column)
- ORDER BY — 表的排序键(可选)。
可以是一组列的元组或任意的表达式。例如: ORDER BY (CounterID, EventDate) 。
- PRIMARY KEY - 主键(可选),如果要设成跟排序键不相同。
通常主键默认和排序(ORDER BY)字段相同,不需另外指定。
- SAMPLE BY — 用于抽样的表达式(可选)。
如果要用抽样表达式,主键中必须包含这个表达式。例如: SAMPLE BY intHash32(UserID) ORDER BY (CounterID, EventDate, intHash32(UserID)) 。
- SETTINGS — 影响 MergeTree 性能的额外参数(可选):
控制合并树的其他参数设置(可选)。index_granularity——索引的粒度。索引“标记”之间的数据行数。默认值:8192。
新版CLickHouse不建议使用以下方式建表:
ENGINE [=] MergeTree(date-column [, sampling_expression], (primary, key), index_granularity)
4.1.2. ReplacingMergeTree
该引擎和MergeTree的不同之处在于它会删除具有相同主键的重复项。
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster] ( name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1], name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2], ... ) ENGINE = ReplacingMergeTree([ver]) [PARTITION BY expr] [ORDER BY expr] [SAMPLE BY expr] [SETTINGS name=value, ...]
- ver — 版本列。类型为 UInt*, Date 或 DateTime。可选参数。
合并的时候,ReplacingMergeTree 从所有具有相同主键的行中选择一行留下:如果 ver 列未指定,选择最后一条。如果 ver 列已指定,选择 ver 值最大的版本。
4.1.3. SummingMergeTree
该引擎继承自 MergeTree。区别在于,当合并SummingMergeTree表的数据片段时,ClickHouse 会把所有具有相同主键的行合并为一行,该行包含了被合并的行中具有数值数据类型的列的汇总值。如果主键的组合方式使得单个键值对应于大量的行,则可以显著的减少存储空间并加快数据查询的速度。
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster] ( name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1], name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2], ... ) ENGINE = SummingMergeTree([columns]) [PARTITION BY expr] [ORDER BY expr] [SAMPLE BY expr] [SETTINGS name=value, ...]
- columns - 包含了将要被汇总的列的列名的元组。可选参数。 所选的列必须是数值类型,并且不可位于主键中。
如果没有指定 columns,ClickHouse 会把所有不在主键中的数值类型的列都进行汇总。
4.1.4. AggregatingMergeTree
该引擎继承自 MergeTree,并改变了数据片段的合并逻辑。 ClickHouse 会将相同主键的所有行(在一个数据片段内)替换为单个存储一系列聚合函数状态的行。
可以使用 AggregatingMergeTree 表来做增量数据统计聚合,包括物化视图的数据聚合。
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster] ( name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1], name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2], ... ) ENGINE = AggregatingMergeTree() [PARTITION BY expr] [ORDER BY expr] [SAMPLE BY expr] [SETTINGS name=value, ...]
4.1.5. CollapsingMergeTree
该引擎继承于 MergeTree,并在数据块合并算法中添加了折叠行的逻辑。
CollapsingMergeTree 会异步的删除(折叠)这些除了特定列 Sign 有 1 和 -1 的值以外,其余所有字段的值都相等的成对的行。没有成对的行会被保留。
该引擎可以显著的降低存储量并提高 SELECT 查询效率。
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster] ( name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1], name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2], ... ) ENGINE = CollapsingMergeTree(sign) [PARTITION BY expr] [ORDER BY expr] [SAMPLE BY expr] [SETTINGS name=value, ...]
- sign—类型列的名称:1是“状态”行,-1是“取消”行。
列数据类型 — Int8。
4.1.6. VersionedCollapsingMergeTree
该引擎继承了MergeTree,并将折叠行的逻辑添加到合并数据部分的算法中。版本化的collapsingmergetree与collapsingmergetree具有相同的用途,但使用了不同的折叠算法,允许在多个线程中以任意顺序插入数据。尤其是,“版本”列有助于正确折叠行,即使它们是按错误的顺序插入的。相反,collapsingmergetree只允许严格连续插入。
允许快速写入不断变化的对象状态。
删除背景中的旧对象状态。这大大减少了存储容量。
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster] ( name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1], name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2], ... ) ENGINE = VersionedCollapsingMergeTree(sign, version) [PARTITION BY expr] [ORDER BY expr] [SAMPLE BY expr] [SETTINGS name=value, ...]
- sign—类型的列的名称:1是“状态”行,-1是“取消”行。
列数据类型应为Int8
- version—具有对象状态版本的列的名称。
列数据类型应为Uint*。
4.1.7. GraphiteMergeTree
该引擎继承于 MergeTree,用于细化和聚合/平均(汇总)Graphite Data。
如果不需要汇总,您可以使用任何Clickhouse表引擎来存储Graphite Data,但是如果需要汇总,请使用GraphiteMergeTree。该引擎减少了存储容量,并提高了Graphite Data的效率。
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster] ( Path String, Time DateTime, Value <Numeric_type>, Version <Numeric_type> ... ) ENGINE = GraphiteMergeTree(config_section) [PARTITION BY expr] [ORDER BY expr] [SAMPLE BY expr] [SETTINGS name=value, ...]
- config_section—配置文件中配置项的名称,
4.1.8. 数据副本
只有 MergeTree 系列里的表可支持副本:
- ReplicatedMergeTree
- ReplicatedSummingMergeTree
- ReplicatedReplacingMergeTree
- ReplicatedAggregatingMergeTree
- ReplicatedCollapsingMergeTree
- ReplicatedVersionedCollapsingMergeTree
- ReplicatedGraphiteMergeTree
副本是表级别的,不是整个服务器级的。所以,服务器里可以同时有复制表和非复制表。
副本不依赖分片。每个分片有它自己的独立副本。
4.2. Log Family
这些引擎是为了需要写入许多小数据量(少于一百万行)的表的场景而开发的。
这系列的引擎有:
主要特点:
- 数据存储在磁盘上。
- 写入时将数据追加在文件末尾。
- 不支持突变操作。
- 不支持索引。意味着 SELECT 在范围查询时效率不高。
- 非原子地写入数据。
如果某些事情破坏了写操作,例如服务器的异常关闭,你将会得到一张包含了损坏数据的表。
4.2.1. StripeLog
在你需要写入许多小数据量(小于一百万行)的表的场景下使用这个引擎。
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster] ( column1_name [type1] [DEFAULT|MATERIALIZED|ALIAS expr1], column2_name [type2] [DEFAULT|MATERIALIZED|ALIAS expr2], ... ) ENGINE = StripeLog
4.2.2. TinyLog
最简单的表引擎,用于将数据存储在磁盘上。每列都存储在单独的压缩文件中。写入时,数据将附加到文件末尾。
并发数据访问不受任何限制:如果同时从表中读取并在不同的查询中写入,则读取操作将抛出异常,如果同时写入多个查询中的表,则数据将被破坏。
这种表引擎的典型用法是 write-once:首先只写入一次数据,然后根据需要多次读取。查询在单个流中执行。换句话说,此引擎适用于相对较小的表(建议最多1,000,000行)。如果您有许多小表,则使用此表引擎是适合的,因为它比Log引擎更简单(需要打开的文件更少)。当您拥有大量小表时,可能会导致性能低下,但在可能已经在其它 DBMS 时使用过,则您可能会发现切换使用 TinyLog 类型的表更容易。不支持索引。
4.2.3. Log
Log与TinyLog的不同之处在于,"标记" 的小文件与列文件存在一起。这些标记写在每个数据块上,并且包含偏移量,这些偏移量指示从哪里开始读取文件以便跳过指定的行数。这使得可以在多个线程中读取表数据。对于并发数据访问,可以同时执行读取操作,而写入操作则阻塞读取和其它写入。Log 引擎不支持索引。同样,如果写入表失败,则该表将被破坏,并且从该表读取将返回错误。Log 引擎适用于临时数据,write-once 表以及测试或演示目的。
4.3. Distributed
分布式引擎本身不存储数据, 但可以在多个服务器上进行分布式查询。读是自动并行的。读取时,远程服务器表的索引(如果有的话)会被使用。分布式引擎参数:服务器配置文件中的集群名,远程数据库名,远程表名,数据分片键(可选)。
示例:
Distributed(logs, default, hits[, sharding_key])
将会从位于“logs”集群中 default.hits 表所有服务器上读取数据。 远程服务器不仅用于读取数据,还会对尽可能数据做部分处理。 例如,对于使用 GROUP BY 的查询,数据首先在远程服务器聚合,之后返回聚合函数的中间状态给查询请求的服务器。再在请求的服务器上进一步汇总数据。
4.4. Memory
Memory 引擎以未压缩的形式将数据存储在RAM中。数据完全以读取时获得的形式存储。换句话说,从这张表中读取是很轻松的。并发数据访问是同步的。锁范围小:读写操作不会相互阻塞。不支持索引。阅读是并行化的。在简单查询上达到最大生产率(超过10 GB /秒),因为没有磁盘读取,不需要解压缩或反序列化数据。(值得注意的是,在许多情况下,与 MergeTree 引擎的性能几乎一样高)。重新启动服务器时,表中的数据消失,表将变为空。通常,使用此表引擎是不合理的。但是,它可用于测试,以及在相对较少的行(最多约100,000,000)上需要最高性能的查询。
5. SQL语法
- SELECT查询
SELECT [DISTINCT] expr_list [FROM [db.]table | (subquery) | table_function] [FINAL] [SAMPLE sample_coeff] [ARRAY JOIN ...] [GLOBAL] ANY|ALINNER|LEFT JOIN (subquery)|table USING columns_list [PREWHERE expr] [WHERE expr] [GROUP BY expr_list] [WITH TOTALS] [HAVING expr] [ORDER BY expr_list] [LIMIT [n, ]m] [UNION ALL ...] [INTO OUTFILE filename] [FORMAT format] [LIMIT n BY columns]
语法与关系型数据库MYSQL基本一致。
除了SELECT之后的表达式列表(expr_list),所有的子句都是可选的。
- INSERT写入
INSERT INTO [db.]table [(c1, c2, c3)] VALUES (v11, v12, v13), (v21, v22, v23), ...
语法与关系型数据库MYSQL基本一致。
- remote数据同步
INSERT INTO [db.][tablename] SELECT * FROM remote(ip,db.tablename[,username[,password])
- mysql表同步
CREATE TABLE tmp ENGINE = MergeTree ORDER BY id AS SELECT * FROM mysql('host:port', 'database', 'table', 'user', 'password'[, replace_query, 'on_duplicate_clause']);
- CREATE创建
CREATE DATABASE [IF NOT EXISTS] db_name; CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster] ( name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1], name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2], ... ) ENGINE = engine
- ALTER修改
ALTER TABLE [db].name [ON CLUSTER cluster] ADD|DROP|CLEAR|COMMENT|MODIFY COLUMN ...
- DROP 删库/表
DROP DATABASE [IF EXISTS] db [ON CLUSTER cluster] #删除数据库 DROP [TEMPORARY] TABLE [IF EXISTS] [db.]name [ON CLUSTER cluster] #删除表
- ALTER修改
ALTER TABLE [db.]table DELETE WHERE filter_expr... #删除数据 ALTER TABLE [db.]table UPDATE column1 = expr1 [, ...] WHERE ... #修改数据
- TRUNCATE 清表
TRUNCATE TABLE [IF EXISTS] [db.]name [ON CLUSTER cluster]
6. 实践
ClickHouse在galaxy-0-10至galaxy-0-14五台物理机上有安装部署,本次实践是基于此测试集群进行操作。
- 分片配置文件路径:/etc/metrika.xml
里面有配置分片名称(cluster_3shards_1replicas)及信息,若要创建分布式库/表,则在语句末尾加上ON CLUSTER cluster_3shards_1replicas即可。
登陆ClickHouse通过SQL也可查看分片信息:

- 配置文件路径:/etc/clickhouse-server/config.xml
- 日志文件路径:/var/log/clickhouse-server/
- 建表信息路径:/data/clickhouse/metadata/
- 分区数据路径:/data/clickhouse/data/
下面以进行分布式操作为例(单机操作省略[ON CLUSTER cluster_3shards_1replicas]即可):
6.1. 连接ClickHouse
clickhouse-client -m -u [username] -h [ip] --password [password] --port [port]
- username:用户名
- password:密码
- ip:服务器IP
- port:端口
- -m:允许多行查询
6.2. 创建数据库
创建分布式测试数据库test
CREATE DATABASE test ON CLUSTER cluster_3shards_1replicas;
6.3. 创建表
以深圳通原始数据为例,在每个分片上创建表szt_data
CREATE TABLE test.szt_data ON CLUSTER cluster_3shards_1replicas ( id String, card_id String, deal_time String, trade_type String, trade_sum Int16, trade_value Int16, terminal_code String, com_line String, line_station String, car_gate String, flag String, finish_time Date ) ENGINE = MergeTree() PARTITION BY finish_time ORDER BY (card_id, terminal_code) SETTINGS index_granularity = 8192
以结算日期(Date型finish_time)按天进行分区,以卡号和设备编号进行排序,使用默认索引粒度8192。
- toYYYYMM(EventDate):按月分区
- toMonday(EventDate):按周分区
- toDate(EventDate):按天分区
- PARTITION BY cloumn_name:指定列分区(不建议以非日期类型作为分区)
对于分区可进行如下操作:
ALTER TABLE [db.][tablename] DROP PARTITION [partition] #删除分区 ALTER TABLE [db.][tablename] DETACH PARTITION [partition]#下线分区 ALTER TABLE [db.][tablename] ATTACH PARTITION [partition]#恢复分区 ALTER TABLE [db.][tablename] FREEZE PARTITION [partition]#备份分区
创建分布式表all_szt_data
CREATE TABLE test.all_szt_data ON CLUSTER cluster_3shards_1replicas AS test.szt_data ENGINE = Distributed(cluster_3shards_1replicas, test, szt_data, rand())
- cluster_3shards_1replicas:配置文件中集群名称
- test:数据库名称
- szt_data:表名
- rand():分片方式,随机
6.4. 删除库/表
语法同mysql,若要删除创建的分布式库/表,在末尾加上ON CLUSTER cluster_3shards_1replicas即可。
DROP DATABASE test; #删除数据库 DROP TABLE szt_data; #删除表 DROP TABLE all_szt_data; #删除分布式表
6.5. 数据导入
上面建表时分别在各机器上创建了本地表(szt_data)和分布式表(all_szt_data),数据导入时可指定导入哪台机器上或者导入分布式表,若导入分布式表数据会随机分到各分片上。
- 命令行导入
clickhouse-client -u [username] -h [ip] --password [password] --port [port] --query="INSERT INTO [tablename] FORMAT CSV" < [filepath] cat [filepath] | clickhouse-client -u [username] -h [ip] --password [password] --port [port] --query="INSERT INTO [tablename] FORMAT CSV"
同时可在clickhouse-client命令后面添加以下选项:
- --format_csv_delimiter:指定分隔符。上面命令中文件是以逗号分割
- --input_format_allow_errors_num:容错数量
其他选项可输入命令clickhouse-client --help查看。
6.6. 数据修改
语法与普通关系型数据库稍微有些区别,由于分布式表并不存储数据,所以无法直接对分布式表进行修改,对于本地表中数据指定记录的修改,可用以下方式:
ALTER TABLE test.szt_data UPDATE trade_sum=1000 WHERE id='20181016094339_020001045'; #修改数据 ALTER TABLE test.szt_data DELETE WHERE id='20181016094339_020001045'; #删除数据
6.7. 查询
语法同普通关系型数据库
SELECT * FROM test.szt_data LIMIT 10; #查询本地表 SELECT * FROM test.all_szt_data LIMIT 10; #查询分布式表
- 查看分片信息
SELECT * FROM system.clusters;
- 查看分区信息
SELECT partition, name, active FROM system.parts WHERE table = 'szt_data';
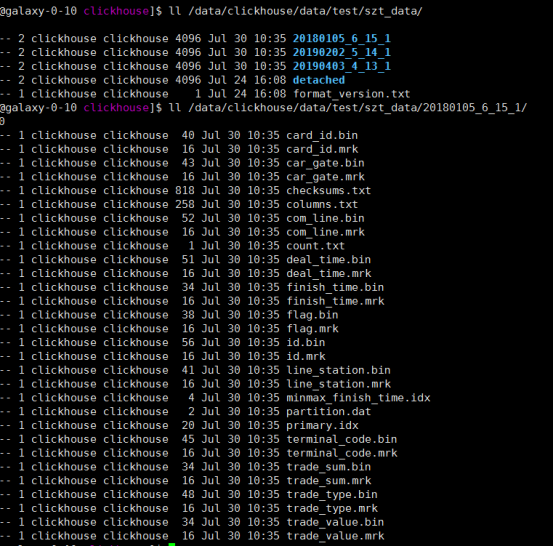
对应存储目录下的文件:
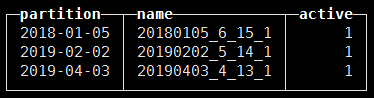
从目录结构可看出,ClickHouse为列式存储,每个数据文件夹下均存储了以列为单位的文件。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号