

Pre-Trained Image Processing Transformer
paper:https://arxiv.org/abs/2010.04159
code:https://github.com/fundamentalvision/Deformable-DETR
基于洗漱空间采样的注意力机制:利用Deformable convolution(将固定形状的卷积过程改造成了能适应物体形状的可变的卷积过程,从而使结构适应物体形变的能力更强)对感受野上的每一个点加一个偏移量,偏移的大小是通过学习得来的,偏移后感受野不再是个正方形,而是和物体的实际形状相匹配。这么做的好处就是无论物体怎么形变,卷积的区域始终覆盖在物体形状的周围。
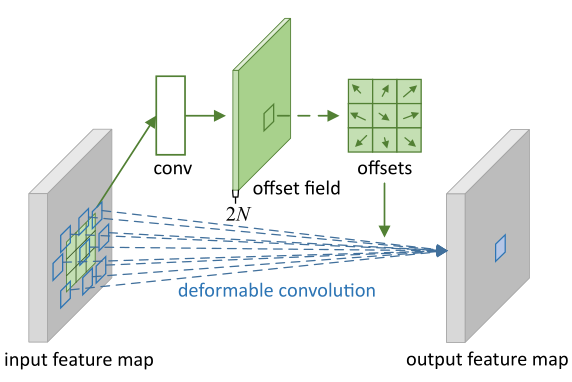
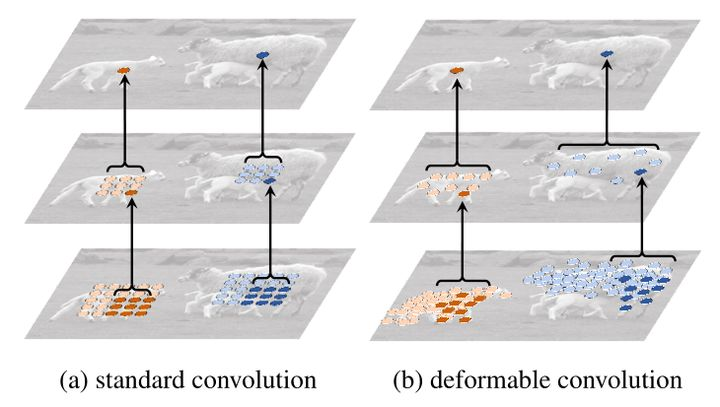
这篇论文提出了一个可变形注意力模块用来代替传统transformer中的attention module,只关注特征中的一部分关键位置。
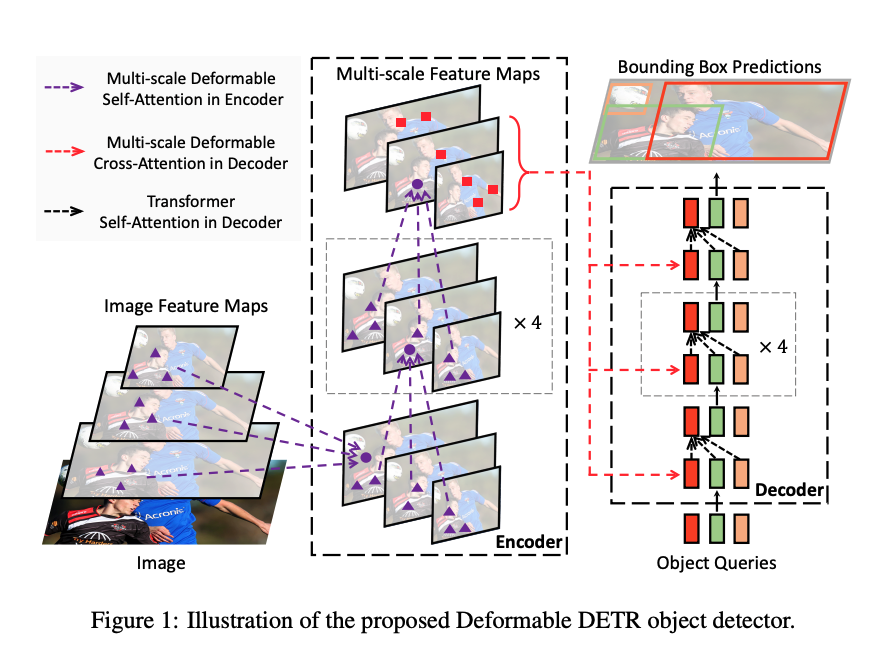
Step1: 利用CNN获取多尺度特征(针对不同特征层的特征点可能拥有相同的位置编码,就无法区分他们,为了解决这个问题,增加一个'scale-level embedding',它是可学习的,仅用于区分不同的特征层,也就是同一特征层中的所有特征点会对应相同的scale-level embedding。可以这么理解,每个班级都有个叫小明的同学,如果只看姓名的话,就无法区分,现在加上了班级就可以明确区分了)
Step2: 变形注意力机制与传统self-attention的区别是query不是和全局每个位置的key都计算注意力权重,而是对于每个query,仅在全局位置中采样部分位置的key,并且value也是基于这些位置进行采样插值得到的,最后将这个局部&稀疏的注意力权重施加在对应的value上。
Step3: Decorder部分与Transformer中主要的区别在于使用可变形注意力替代了原生的交叉注意力。类似地,每层的解码过程是self-attention+cross-attention+ffn,下一层输入的object query是上一层输出的解码特征
提出的两点提升性能的策略:1. Iterative Bounding Box Refinement 使用bbox检测头部对解码特征进行预测,得到相对于参考点(boxes or points)的偏移量,然后加上参考点坐标(先经过反sigmoid处理,即先从归一化的空间从还原出来),最后这个结果再经过sigmoid(归一化)得到校正的参考点,供下一层使用
2.two-stages 在原始 DETR 中,decoder中的目标查询与当前图像无关。 受两阶段目标检测器的启发,用于生成区域建议(region proposals)作为第一阶段。 生成的区域提议将作为目标查询输入decoder进行进一步细化,形成两阶段可变形 DETR。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人