剖析网络测量:Counting and Measuring Network Traffic
全文共18000字,讲解了网络测量和计数中的多方面知识:网络测量的意义、网络测量的手段分类、网络测量在实现上的挑战、以及解决这些挑战所用到的技术和协同方案等等。
参考书籍有:《Network Algorithmics: An Interdisciplinary Approach to Designing Fast Networked Devices (2nd Edition)》
本博文首发于博客园:https://www.cnblogs.com/grapefruit-cat/
本文作者:grapefruit-cat ,转载需在文章头部标明出处。
1 前言
在现实中要对某些任务做出优化,必定要先进行一定的测量。只有进行了对性能的测量量化,你才能知道任务的瓶颈在哪,才能对相应执行位置做出好的优化。不要在未做测量的情况下带着主观臆断去做优化!!
Premature optimization is the root of all evil. ——D. E. Knuth.
这个原则在计算机网络里面同样适用。对一个特定网络的流量使用软件或者硬件工具进行测量,不仅可以描述这个网络的特征,而且可以在测试出网络的运行状态,如在流量不稳定或者流量过多时采取相应的优化措施,从而更好地设计网络。
2 为什么需要网络测量?
从架构视角上看,网络测量可以描述出当前网络的流量状态,可以得到当前网络的拓扑信息和性能信息,还可以对一个具体的协议的运行结果进行观测,这就使得当一个新的想法出现时,可以将网络测量当成一种实验的手段,来摸索出新想法的性能表现。
而从提供服务的视角来看,网络测量可以根据测量出的流量特征(如用了什么类型的流量、用了多少)向客户计费;可以检查网络的QoS并观测诊断解决存在的问题;可以为以后增添升级设备做好开销预算。
举一个例子,在服务提供商网络中,数据包计数和流量日志记录为以下任务的优化提供了数据支撑:
- 容量规划(Capacity Planning): 互联网服务提供商(ISP)需要确定流量矩阵,即他们所连接的所有源子网和目的子网之间的流量信息。这些得到的信息可以在短时间尺度(例如,几个小时)内使用,通过重新配置光交换机(optical switches)来执行流量工程(traffic engineering);它也可以用于较长的时间尺度(例如,几个月)来升级链路容量。
- 计费工作(Accounting):ISP与客户和对等体(peer)之间实现了复杂的服务水平协议(service level agreements,SLAS)。基于总体流量(即单纯的传输数据量)的简单计费可以由单个计数器轻松监控得出;然而,更复杂的基于流量类型的协议需要给每个流量类型安排一个计数器,这样才能根据流量类型来进行分级计费。数据包计数器也可以用在ISP之间的互联对等关系上。假设ISP-A目前正在通过ISP-B向ISP-C发送数据包,并且正在考虑与B直接连接(对等互联),那么A进行计费的合理方法是统计到达B对应网络前缀的流量。(ISP-C 并没有直接参与到对等互联关系中,而仅仅是通过 ISP-B 来间接地与 ISP-A 通信。因此,针对ISP-C 的流量并不会作为对等互联计费的一部分。)
- 流量分析(Traffic Analysis):网络的管理者们通常需要时刻留意着不同种类流量的表现。例如测量到点对点流量激增,就需要对其做出一定的速率限制;再例如ICMP消息类型的流量激增意味着有可能发生了Smurf攻击。
3 网络测量的分类
从测量目标去分类,可以把网络测量分为以下三类:
-
端到端性能测量:通过主动测量方式来测量网络中各个节点之间的性能指标,如网页下载的平均时间、TCP批量吞吐量等。
-
状态测量:主要集中在对网络拓扑、配置、路由等的测量,如当前活跃的路由、活跃的拓扑部分、链路的误码率等。
-
流量测量:主要集中在对数据包和数据流的测量,以及对链路的统计信息,如链路使用率、流量矩阵、需求矩阵等。
从测量方式去分类,可以划分为主动测量和被动测量两大类。定义上,主动测量方式通过向目标链路或目标节点主动发送数据包,来测量链路或端到端的延迟、带宽和丢包率等网络性能参数,这种方式比较精确但往往会对网络性能总体产生影响;而被动测量方式通过接入网络的测量探针被动地嗅探网络流量,通过记录和统计网络链路或节点上业务流量的信息来分析网络性能。两种测量都可以在控制平面和数据平面上运行,在同一类平面上两种测量得到的结果种类均相同,即在控制平面上可以得到网络的拓扑、配置以及路由信息,在数据平面上可以得到端到端性能信息、链路统计信息以及数据包和数据流的特征信息。
从测量对象来分类可以分为数据包测量和数据流测量。
下面将从两种测量对象出发作阐述。
4 包测量
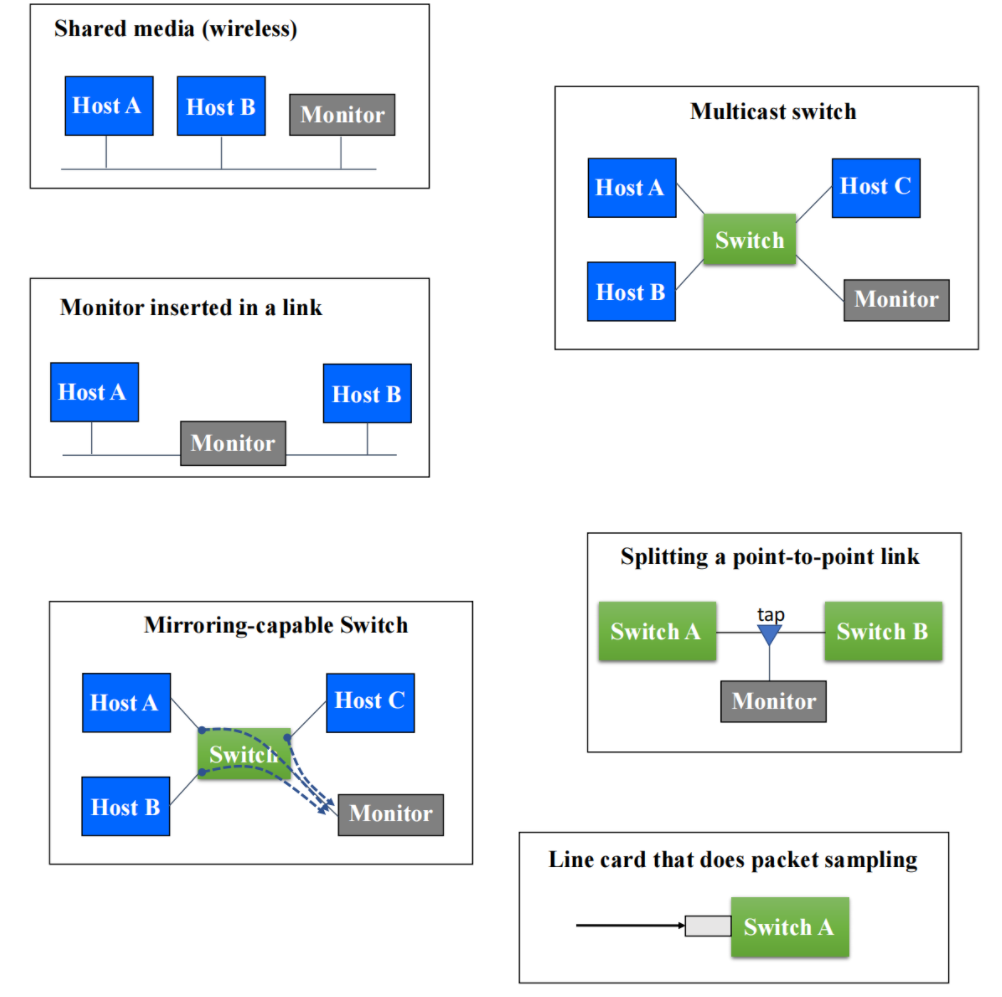
包测量是一种被动测量方式,通过被动地在一或多个链路上收集数据包,记录包中各层的路径信息。它的测量范围主要集中在记录用户行为的细粒度信息,被动地监测网络基础设施的运行,描述当前流量特征和诊断相关问题。下图描述了包测量的中心监测器测量链路时,在不同的网络拓扑中所处的测量位置:
4.1 测量获得的元数据
包测量在开始时需要根据我们测量的需求,对测量的流量进行元数据提取——而不是对单个包包含的所有信息都进行提取分析。我们需要根据一定的标准对数据包进行不同方面的测量分析,具体的分析标准可举例如下:
- 对数据包的IP做特定分析,如需要测量某个特定站点来的流量时,需要区分出特定的IP或IP前缀;
- 对数据包的运行协议做特定分析,如区分为TCP、UDP或ICMP包;
- 对数据包的端口号做特定分析,某些特定的端口上运行着特定的协议,如HTTP、DNS、BGP等。
对于如何拿到这些元数据信息,我们可以通过接收数据包时截取头部字段的字节来完成这份工作,这头部的前n个字节往往能够实现对数据包种类的区分。以下展示了一些不同协议的头部字段字节范围:
| 头部种类 | 字节长度 |
|---|---|
| Ethernet MAC | 14 |
| IP header | 20或36(IPv6) |
| IP+UDP | 28或44 |
| IP+TCP | 40或56 |
| 应用层信息 | 整个数据包(应用层头部+overload) |
在对数据包头部包含的信息做分析提取元数据时,不同协议类型的头部字段分析的重点也不同。
对于IP头部信息的测量,对源地址和目标地址的测量可以获取哪一个服务器或哪一个站点在当前是流量较高、热门的;对两个特定地址之间吞吐量的测量可以对性能问题进行检测和诊断;对途经路由器的数据包时延分布情况的测量,可以识别出典型的延迟和异常情况;测量大小字段可以获取数据包大小的流向分布情况,可以得到路由器工作负载模型;如果测量出链路上某些特定方向的流量激增,那么就可以将该信息用于重新分配链路容量和重新配置处理队列。
而在TCP头部信息中,源端口和目的端口的测量记录可以推断出当前热门的应用;对TCP序列号或ACK编号以及数据包时间戳的测量可以得到当前传输中无序或丢失的数据包有哪些,可以得到丢包率、吞吐量和延迟信息;对每个TCP连接的传输的数据包数或字节数的测量可以得到批量传输的频率;对来自客户端的SYN数据包测量,则可以知道当前失败的请求数量,以及可以检测出是否存在Dos攻击;对来自客户端的FIN或RST数据包,可以得到由客户端中止的Web传输的频率,以及推断出相关应用程序的行为。
而在应用层信息的测量中需要对整个数据包内容分析,对不同的应用层头部,如HTTP请求和响应报头、SMTP命令和响应信息、DNS查询和响应信息、OSPF/BGP消息等,可以做不同的测量;而对应用层overload的测量主要集中在附带信息上,如请求的HTTP资源有什么,RPC中的key-value cache操作有哪些,RPC中的pub-sub消息分布等。但要注意的是这些测量在当下加密通信中变得越来越困难。
5 流测量
与包测量以单个数据包为监测单位不同,流测量以”属于同一组“数据包为单位,多个同一组的数据包被划分到一个数据流中去测量。
对”属于同一组“的划分标准,同样可以使用数据包中的头部字段信息。与包测量的流量选取相似,我们可以根据源地址和目的地址、源端口和目的端口、运行协议类型、ToS种类等进行划分。除了数据包本身附带的信息,我们还可以使用路由器上数据包的出入端口信息来进行流划分。另外,数据包还需要根据时间进行划分。同一组的数据包即同一个数据流在时间尺度上不能距离太远,即使是在信息上划分为同一组的数据包,也可能因为时间上的相差而划分到不同的数据流中。
5.1 为什么做数据流的抽象?
数据流划分的意义在于让测量的对象更加接近于“应用程序级别“的交互单元,采用数据流作为测量的基本单位可以更好地反映应用程序的实际行为和需求。
与数据包相比,数据流可以更好地描述应用程序的交互过程。例如,在视频流媒体应用中,一个数据流可能由多个数据包组成,这些数据包共同构成了一个连续的视频帧或音频样本。如果仅考虑单个数据包,则无法完整地描述视频或音频流的特征。
此外,数据流也反映了应用程序之间的交互关系。例如,一个Web页面可以由多个HTTP请求和响应数据流构成,并且这些数据流在应用程序之间的交互中扮演着重要角色。通过对数据流进行分析和测量,我们可以更好地理解应用程序之间的交互方式并评估网络性能。
此外,以数据流为测量单位还可以针对转发或访问控制对路由器进行优化。如采用IP-over-ATM技术的流交换范式可以利用其缓存结果对路由器进行转发或访问控制决策上的优化,再如Netflow技术可以聚合通过路由器的流量信息。
5.2 测量获得的元数据
我们从流测量提取元数据的过程展开论述。首先流测量要对接收到的数据包做一定的划分,如上面所述,划分可以依靠读取数据包头部字段信息来完成,主要读取的信息有源地址和目标地址、端口号、其他 IP 和 TCP/UDP 标头字段(如协议字段、ToS字段等)。划分出数据包子集(准数据流)后,便对整个子集的一些信息做一定的聚合,生成流记录信息,如准数据流的开始和结束时间(第一个和最后一个数据包的时间),流中的总字节数和数据包数量,TCP 标志位序列信息等,这种对整个流的数据特征测量可以帮助我们分析网络流量趋势和周期性变化,以及预测未来流量的可能方向。
除了数据流中来自数据包“自身”的信息以外,还需要测量该数据流的路由信息。常见的路由信息有数据包在路由器交换结构中的转发方向,即数据包的出入端口;还需要记录其源子网和目的子网的信息,这个可以通过记录源和目的IP地址前缀来实现。
流测量获取的信息和包测量有一些异同之处。在基本信息的获取上面,它们两者都可以计算收到数据包的平均大小,可以获取不同IP地址、端口号、协议的混合的流量信息,但在按时间尺度测量流量方面,除了两者都能完成的中长期时间尺度上测量之外,包测量还可以测量出短期时间尺度上网络流量的突发激增。另外在运输层的测量上,两者都能测量出特定连接中传输的总数据量大小,但包测量因其以单个包做测量的特性,能够测量出数据传输中的乱序率或丢包率。
5.3 流测量的底层实现
5.3.1 在何处生成流记录?
流测量生成流记录的过程在哪里实现是一个需要多方考虑的问题。如果由路由器中的CPU负责流记录生成,那么就有可能影响到路由器的路由性能;如果由路由器端口处的线卡负责生成,虽然能够更有效地支持测量,但线卡的适用性和可扩展性受制于其设备兼容性,需要额外的部署和维护成本;除了CPU和线卡,我们还可以利用在数据流途径路由上的数据包监视器来生成流记录。
我们来看一些流测量的底层支持机制。
5.3.2 硬件机制 Flow Cache
Flow Cache是一种基于硬件的缓存机制,可以在网络节点上缓存每个数据流的元数据,例如源 IP 地址、目标 IP 地址、端口号、协议类型、数据包数量等。这些元数据可以用于识别特定类型的数据流,如视频、音频、文件传输等等,并确定它们在网络中的来源和目的地。同时, Flow Cache 还可以记录数据流的持续时间、流量大小和延迟等流特征。
Flow Cache的固件可以使用TCAM或SRAM等方式来实现,而缓存操作依赖于Flow Cache中的控制器(Flow Cache Controller )来实现。Flow Cache Controller 是一个独立的组件,它负责管理整个 Flow Cache 的生命周期,包括缓存的创建、维护和删除等操作。
当一个新的数据包到来时,Flow Cache Controller会根据源和目的地以及端口号三者计算出一个键值(key),并将其作为创建或更新缓存中流条目(entry)的依据—— Flow Cache Controller会检查该 Flow 是否已经存在于缓存中,并根据配置的缓存规则判断是否需要缓存该 Flow。如果需要缓存,则会计算出该 Flow 的元数据存储位置并将其存储到缓存中。图示为Controller 计算键值和索引到缓存条目。
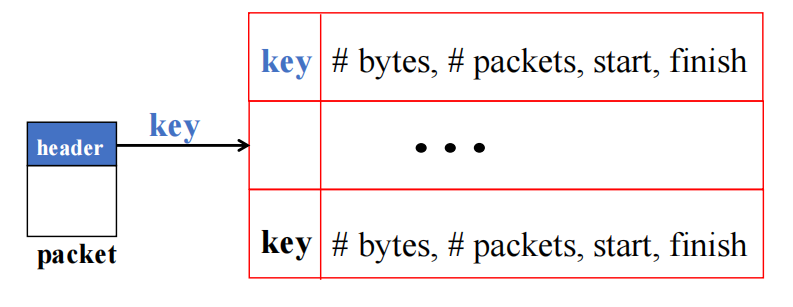
在计算元数据存储位置时,Flow Cache Controller 会考虑多种因素,如存储设备的容量、负载均衡、数据安全性等因素,以保证缓存的高效性和可靠性。同时,它还会监控缓存的使用情况,自动调整缓存策略和存储位置,以最大化缓存的利用率和效果。
当Flow Cache条目达到一些条件如超时、映射冲突的时候,就需要对条目进行删除或替换。超时是指缓存中的数据流条目在一段时间内没有被访问。Flow Cache Controller 会对数据进行周期性排序,对于超时的数据流,即最近未接收到数据包的流,会被Controller自动清除。当缓存被填满时,Controller会根据一定的算法,如LRU、随机选择等,去用新的条目替换掉算法计算映射到的旧条目。
5.4 流测量的开销
流测量的开销主要集中在两个方面:对每个数据包的处理和对每个数据流的处理。
对数据包的处理开销主要集中在Controller计算键值和索引到缓存条目上。在数据流中如果数据包的平均大小较小,那么测量处理的速度就可能会跟不上当前链路的传输速率——当存在许多大小较小的数据包时,测量就必须捕获和分析更多数量的数据包才能获取与大数据包相同的信息量,这会增加处理开销,对存储的要求也更高(要求读写更快),从而影响测量的性能。
对数据流的处理开销则主要集中在Controller创建和替换条目上。这主要由数据流的多少来决定。如果数据流中包含的数据包数量较少,那么总体上的流数量就会较大,接收分析数据流的工作量就会加大,这同样影响测量的性能。
6 网络测量的挑战性
你可能会认为测量工作是一件非常平凡且简单的事情——即使它很必要。但是对于高速运转的网络来说,网络流量测量是一个很困难的问题。
6.1 为什么测量很困难?
首先我们要知道,网络协议提供的信息有时候并不完全符合我们作为用户的需求,例如traceroute工具记录路由路线,它是依赖于数据包的TTL来鉴别路由信息的——而TTL的本意是告诉网络路由器该数据包在网络中的时间是否太长而应被丢弃。显然,数据包承载的信息并没有明确告诉我们该包的路由信息,我们不得不通过其它的手段来获得我们想要的信息。对于网络测量也是如此,网络并没有给我们直接提供明确的测量特征,但我们可以用对不同种类数据包计数的方式去巧妙地获得流量测量信息。
然而,数据包计数并不简单。要想做到精确的网络流量测量,需要精妙的计数器。传统路由器只提供运行SNMP协议的接口计数器,这类计数器很容易物理上实现——由于一个路由器接口仅仅只有几个计数器(如字节计数器、错误计数器等),如此少的数量可以很轻松地用芯片的寄存器来做到。但传统的计数器只能用于很粗糙的计费(accounting)计算,无法做到按流量类型计算的计费,如对收费更高的实时流量的区分,以及对途径不同等级的ISP的区分。所以我们需要精妙的具有过滤功能的计数器。
举一个例子,我们可以通过简单的辨认网络地址前缀的方式来实现过滤计数,但物理上支持基于前缀的计数会有不少的开销:
- 考虑到即使是当前的路由器也支持500000个前缀,未来的路由器可能达到1000000个前缀,那么一个路由器就需要支持上百万个实时计数器;
- 每个数据包在路由时都要被不同的计数器进行信息记录,一个数据包可能对应多个流和多个前缀;
- 随着链路速率不断上升,如从最初以太网标准的10Mbps升至现在的400 Gbps以太网标准,如此高的数据包接收速率意味着计数器的读写速度也要相应提高;
- 计数器的高读写速度意味着达到计数值溢出的时间将变得更短,需要将32位宽度的计数器升级为64位。
要保证高速读写,计数器的存储介质就需要使用昂贵的SRAM或TCAM;但单单对于这一种支持前缀计数的计数器来说,一百万个64位计数器就意味着要使用64Mbit的内存,这代价是不可接受的。所以在当下的主要问题就集中在如何保证计数器高速运行的同时减少计数器的处理量以及所需要的存储开销。
下面我们来介绍一些对这类问题的优化方法,主要从减少存储开销和减少处理量两方面展开。
6.2 减少存储开销
6.2.1 DRAM Backing Storage
我们先集中讨论数据包计数的具体问题。实现数据包计数存储的最简单方法下图所示。图示中有100万个基于目的地前缀进行区分的64位计数器,每一个都使用SRAM来实现,当数据包到达时,相应的计数器将值递增。
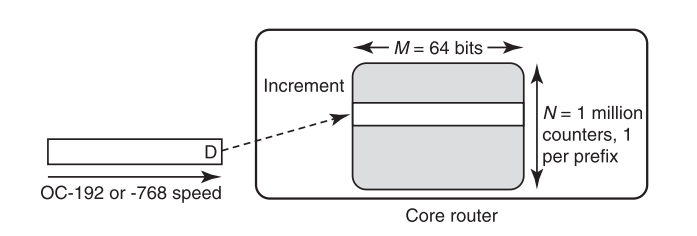
整整64Mbit的SRAM!如此大容量的SRAM非常昂贵的。我们不禁想到,真的有必要使用如此大容量而昂贵的介质去做计数吗?能不能使用DRAM替代SRAM?但如果有一个数据包每8ns到达一次,我们就必须通过SRAM计数器来处理这个数据包,而不能使用DRAM——因为DRAM延迟高达40ns。显然SRAM在处理需要快速响应的任务时的速度是DRAM远远比不上的,然而从直觉上来说,使用完整的64位SRAM是一种显而易见的浪费。
但我们往往可以通过快慢结合的方式来解决这种矛盾的问题。DRAM和SRAM的最佳硬件特性可以结合起来使用,在价格上,DRAM至少比SRAM便宜四倍甚至十倍,但在速度上,DRAM速度较慢。这与计算机中的内存层次结构非常类似(Cache-内存-硬盘 结构)。这种类比表明,DRAM和SRAM可以组合使用,提供既廉价又快速的解决方案。我们可以使用DRAM作为SRAM的备份存储器(Backing Storage)。

观察一下,如果路由器为N个计数器的每个计数器都配置一个64位的DRAM,并再分配一个较小的宽度(例如12位)的SRAM,那么只要每个SRAM计数器在溢出之前能够将自身的值刷新到DRAM,那么计数就是准确的。这会大大减少SRAM的使用开销!该方案上图所示。然而,这需要一个好的算法来决定何时以及如何刷新SRAM计数器。
假设计数器允许每经k次SRAM访问就刷新一次到DRAM。那么我们需要选择足够大的k,使得k次的SRAM访问时间对应1次DRAM访问时间。也就是说,k是DRAM访问速度与SRAM访问速度的比值。那么如何决定所需的最小SRAM宽度呢?D.Shah等人在论文Maintaining statistics counters in router line cards中指出,在“pick-a-counter-to-flush”的算法框架下,“条件最优”的计数器刷新管理算法,是每次刷新都应选择刷新当前数值最大的SRAM计数器。通过这种算法,SRAM计数器的宽度c可以明显小于DRAM计数器的宽度M,准确来说有以下的量化关系:
其中N为计数器数量,k为计数器SRAM刷新频率,c为SRAM宽度。
注意到当k值较大时,分母的影响可以被忽略,那么\(c\)的值就与\(log (log\ kN)\)挂钩。举一个例子,当数据到达速率为每8ns到达一次时,对于一百万级别的N,在3个64位的DRAM的帮助下,仅仅需要空间消耗为8 Mbit、访问速度为2.5μs的SRAM,DRAM的访问速度也只需要达到51.2μs。此时k的值为\(51.2/2.5\approx21\)。如果不使用DRAM,也就是用最笨的办法来实现SRAM计数器,那么就需要使用高达192Mbit的SRAM!
但是还有一个问题需要解决:如何找出当前计数值最大的SRAM计数器。在2000年Bhagwan和Lin描述了一种流水线堆结构的实现,该结构可以在硬件复杂性和空间上以相当高的代价确定最大的值。它们的堆结构需要每个计数器的配置一个大小高达\(log_2N\)的指针,用以识别当前需要刷新的计数器。在N高达百万的量级下,这种指针反而会破坏我们将所需的SRAM位数从64减少到10的整体目标。
每个堆值都配置一个指针,这似乎很难避免。一方面,计数器必须位于固定的位置,以便在数据包到达时进行更新,但堆中的值必须不断移动以维护堆属性。另一方面,当最大值到达堆的顶部时,必须将其与计数器索引相关联,以便将索引对应计数器SRAM刷新到DRAM中。还要注意的是,堆中所有值的存储,包括指针和值,都必须在存储在SRAM中以提高访问速度。Ramabhadran和Varghese在2003年提出的一种LR算法优化了这个问题(Efficient implementation of a statistics counter architecture),它可以达到相同的SRAM计数器宽度,并使用位图去维护所有高于刷新频数k的计数器。
从表面上看,整个方法与通常使用的内存层次结构类似,其中较快的SRAM充当较慢的DRAM的缓存。然而,与传统的单一缓存方式不同,这种设计确保了最坏情况下的性能而不是预期的情况下的性能,即在任何情况下都能提供一定程度的性能保证,而不仅仅是在常见情况下。不同之处还有,传统的缓存只存储一些频繁访问的数据,而不是全部数据;而计数器缓存则会为所有接收到的数据存储条目,但会试图去减少每个条目所占用的存储空间,以便在内存有限的情况下尽可能多地存储数据。
6.2.2 随机计数
使用DRAM作为备份存储器可以大幅度减少存储开销,但减少的SRAM计数器宽度会换来更多的处理量和复杂性。那么我们的第二种方法就是用结果的准确性和确定性来换取计数器宽度的减少,即“精度换开销”。
精确的统计数据通常过于昂贵且难以获得,而许多问题的近似答案是可以接受的,如流量大小的分布、出现频率前N的流等,对于这些信息,其实只需要记录一个近似的值就足够了。
随机计数的基本思想为:对一个宽度为b的计数器,其记录值最大上限为\(2^b\),即如果按照传统的确定性的方式计数,一个b位的计数器最多只能计数\(2^b\)次;但如果引入随机计数,假设一个计数器被选中后进行计数的概率为\(1/c\),那么它的计数次数最高可以达到\(2^b*c\)次。计数上限整整高了c倍!
为什么随机计数也能获得相对正确的结果?这是因为在随机计数的基本思想中,标准结果与实际结果的标准差(即计数器误差的期望值)大致为几个c的大小,其中c对于计数器值来说是非常小的。即在基本的随机计数方法中,当计数器值远大于计数概率c时,标准差会变得很小。也就是说,如果计数器的值足够大,则误差会相对较小且可控,从而使得估计的结果更加精确可靠。因此,这种方法可以在保证一定精度的同时,降低算法的复杂度和内存需求。对此R. Morris提出的随机计数思想也是如此,他注意到,越高的计数值可以容忍计数结果中越高的误差绝对值。例如,如果标准差等于计数器值,则真实值可能在计数器确定的值的一半到两倍之间。允许误差随着计数器值的增加而缩放,反过来可以使用更小的计数器宽度,即要实现\(2^b\)的计数上限,只需要k的计数器宽度,使得\(2^b=2^k*c\)。
对于计数概率c的确定,Morris的理论将c的值设定为一个不确定的值——c将会随着计数器当前值x变动。而c与x的关系可以用下式表示:
这样计数误差的范围会随着计数器值的大小而变动。而计数器值x可以表示出结果的近似值,近似值为\(2^x\)(要注意,计数器值并不等于结果数值!)。因此,对同样的结果上限值MAX,采用随机计数后,计数器的宽度k仅仅为\(log\ (log MAX)\)。关系式梳理如下:
6.2.3 阈值聚合(Threshold Aggregation)
前面讲的都是如何将计数器的宽度减少,接下来我们需要关注的是如何将计数器的数量减少。我们可以使用计数器阈值聚合的方法。
爱因斯坦有一句这样的话,“Not everything that is counted counts, and not everything that can be counted .”
不是所有的值都是值得保留的。计数也是如此,计数是为了得到满足我们需求的值,在这过程中难免会有一些额外的值被计算进来,要保存这些值就需要额外的计数器。所以我们有必要抛弃掉这些用途不大的额外值,此时阈值聚合计数技术就派上用场了。
在传统的计数器中,每个计数器通常都需要单独存储,并且可能需要占用大量的内存空间。而且当计数器数量非常大时,对这些计数器进行处理和分析的时间和资源成本也会显著增加。阈值聚合是一种常见的减少计数器的方法。该技术主要通过将原始计数器的值进行聚合来实现减少计数器的目的,从而降低计算和存储成本。
阈值聚合可以用于在流测量中对”大象“流和”老鼠“流的区分上。在我们日常生活中,我们会开通各种的流量套餐,每种流量套餐有它自己的流量额度——所用流量低于这个额度时按照套餐计费,高于这个额度时则动态计费,这个额度就是一个阈值。另外,对于一个关心着路由流量热点或网络是否正在被攻击ISP运营商来说,大象流显然比老鼠流更值得留意。
(大象流是通过网络链路进行大量的,持续的传递数据的过程;而老鼠流是通过网络链路进行少量的,短时间的数据传递过程。具体区分的临界点,不同的场景是不一样的。参见定义:Elephant flow和Mouse flow)
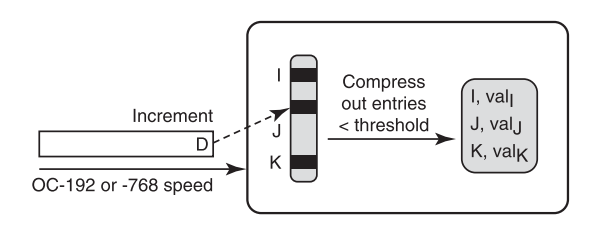
下面来结合上图来简单解释一下阈值聚合。图中展示了一种最简单的阈值聚合方式:将高于或等于特定阈值的计数器值保存下来,其它的计数器值扔掉。阈值可以选取一个与总流量大小有关的值,如总流量大小的0.1%,这个值就可以作为区分大象流和老鼠流的标准,留下了的计数器值就代表了当前存在的大象流。假如网络中最多只有1000个大象流,我们只需要使用1000个计数器就能完成流测量!
但是很明显我们发现了一个悖论问题:阈值聚合可以减少计数器数量,但要应用阈值聚合,就必须先对所有输入的数据流进行计数器计数。这就违背了我们开始减少存储开销的意愿。所以怎样才能做到,既不用跟踪所有的流,也能辨别出大象流呢?下面我们来看一种依赖于流哈希的方法。图中为对多个流进行并行哈希映射并判断是否为需要的流:

计算识别大象流的核心在于多个哈希层(图中的stage)的并行协作。其中,一个哈希桶由多个计数器组成,每当有数据包到达时,Controller会根据哈希函数来计算该包的索引键值,并将其存进相应的计数器中。也就是说,一个计数器记录着一个流的信息。
首先让我们考虑仅仅存在一个哈希层的情形。当一个属于数据流F的数据包到达时,Controller将其计算并索引到相应的计数器,并将数据包的大小添加到计数器值中;当数据流F发送的字节数大于阈值T时,对应F流的计数器的值也就超出了阈值,那么我们就意识到这是一个属于大象流的计数器,就可以将该流的数据送进流内存做进一步的分析处理。
但单个哈希层有一个明显的缺陷:由于我们需要减少计数器数量,所以哈希层中的计数器数量是少于所有流的数量的,那么不同的流就有可能哈希到同一个计数器中。这会导致两种测量上的误差:老鼠流会哈希到属于大象流的计数器中,或多个老鼠流哈希到同一个计数器而导致计数值高于阈值,使得Controller认为这是一个大象流。
所以我们使用并行的多个哈希层来做流哈希映射,不同的哈希层使用不同的哈希函数。对一个数据包,只有其哈希到各层的计数器值都大于阈值,才能认为这是一个大象流,才可以将流数据送进流内存中。如图所示,假设对于一个属于数据流F的数据包到达Controller,它在不同哈希层分别被哈希到3,1,7这三个计数器中,只有Controller判断三个计数器值都大于阈值时,流F的数据才会被送到流内存中。
我们继续做一个简单的分析。假设有一条100 MB/s的链路,流的数量为100,000,我们希望在1秒的测量间隔内识别链路传输量1%以上的流量,即流量大小为1MB以上的流。如果按照传统方式,我们至少需要100,000个计数器。但现在,假设每个哈希层有1000个计数器,阈值为1MB。让我们来计算一下,一个流发送了100KB大小的数据并被识别送到流内存的概率是多少。
要使该流成功在一个哈希层中被识别出,即该流的计数器需要达到阈值,那么该计数器中在该流输入前的值,即其他流哈希到该计数器的总和,需要达到1 MB-100KB=900KB。而在每个哈希层的1000个桶中,至多有99.9MB/900KB=111个这样的准备达到阈值的桶。因此流在一个哈希层被识别成功的可能性至多为11.1%。而对于四个并行的哈希层,不大于100KB的小流量通过所有哈希层的概率是一个非常小的值,其最大值为\(1.52*10^{-4}\)。
这种阈值聚合方案的可拓展性极高。如果流的数量增加到100万,我们只需添加第五个哈希层即可获得相同的效果。因此,处理10万个流需要大约4000个计数器和大约100个存储单元的流内存;而处理100万个流仅仅需要大约5000个计数器和相同大小的流存储器。这仅仅是一个对数级别的增长速度。另外,在数据包到达时,每个哈希层会做一次读取和一次写入。如果哈希层足够少,即使在高速情况下,这种访问次数是可以负担得起的——因为哈希层的访问可以并行执行。
6.3 减少处理量
到目前为止,我们已经在数据包计数方面做出了存储开销的优化。但是,除了单纯的计数以外,我们还需要对数据包中的日志信息进行处理分析——数据包日志有助于分析人员对网络运行模式和受到的网络攻击进行回顾性分析。
在网络中,有一些通用的流量测量分析系统,如Cisco的NetFlow技术,在极细粒度下(对于数据流的粒度,每个流由单独的一条TCP或UDP连接标识),它可以分析并报告每个流记录。但要注意的是,存储数据包日志所需的大量内存需要使用DRAM来实现(流内存,并非计数器的存储结构)——显然,如果在每次数据包到达时写入DRAM,这个写入速度对于传输链路的高速率来说是不可行的,就像对于计数器不能单纯使用DRAM计数一样。由此,最基础的NetFlow技术面临着两个问题:
- 处理流信息开销上:更新DRAM会降低转发速率。
- 收集报告信息开销上:NetFlow生成的数据量太大,可能超过收集服务器或其网络连接的处理能力。基础NetFlow技术的信息丢失率甚至可以高达90%。
两个问题都与处理量过大密切相关。所以为了减少处理量,Cisco建议在使用NetFlow技术时,需要搭配采样技术去使用。
6.3.1 采样技术
我们先来直观地感受一下NetFlow中采样技术带来的好处:
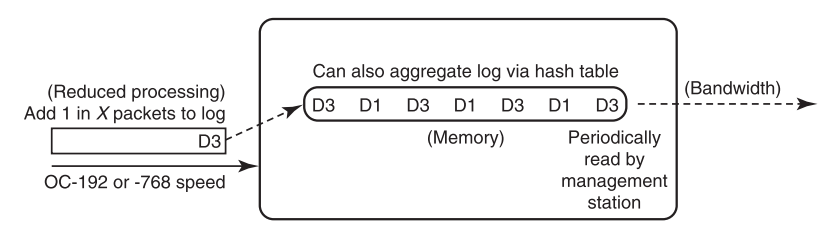
上图为对数据包进行流采样的过程。如图,应用了采样技术后,只有采样的数据包才会更新DRAM流缓存。例如,对16个数据包中的I或1000个数据包的1个进行采样,这是被允许而且是较为常见的。采样的优点在于,如每16个数据包到达时,DRAM最多写入1个数据包,这使得DRAM的访问时间可以比数据包到达时间慢16倍。但要注意的是,抽样在估计中引入了相当大的不准确性,不过对于长时间的测量(误差平均值)以及应用程序不需要精确的数据,这种不准确性无关紧要。
下面我们来系统地阐述采样技术。
我们之前进行流测量的方式,是对所有的数据包都进行处理和记录然后根据元数据生成流记录。但是,处理和记录每个数据包会占用大量的计算和存储资源,从而影响网络性能并增加成本。特别是在高速网络环境下,需要处理可能非常巨大,这使得准确测量和分析网络流量的代价变得非常高昂。所以我们引入了采样技术。
采样技术在生成数据流记录之前就对数据包进行采样。它首先通过随机采样(1-out-of-n)的方式对数据包采样,然后再基于采样的数据包构建流记录。这样可以有效减轻网络测量的计算和存储开销,避免在另外n-1个数据包上产生额外的计算和存储开销,同时避免为许多小型的数据流创建流记录,从而提高记录效率并降低存储成本。
当前的采样技术有几种比较先进的处理方式:
不维护流状态
在设备不维护任何流状态的情况下,对流的随机子集中的数据包进行采样。
在此前的处理中,我们需要用计数器将流分别划分出来,再将流数据送到流内存中进行处理。我们可以对此做优化:在设备中不维护任何流状态,即丢弃流计数的步骤,直接对数据包进行流划分后采样。为了实现这一过程,可以对每个数据包的五元组(源IP地址、目标IP地址、协议类型、源端口、目标端口)进行哈希处理,并对哈希结果符合某种条件的数据包进行抽样。这样可以达到在不维护流状态的情况下,对随机一部分流量采样的目的(相当于假定了符合某种条件的数据包属于同一个流)。
轨迹采样 Trajectory Sampling
轨迹采样可以确保数据包在多跳路由器之间得到一致的采样处理。
在采样过程中,对多个路由器来说,即使经过它们的流是一样的,但对流的采样却是相互独立不受影响的——这会导致路由器之前的采样结果有差异!如果我们有对路径效应分析的需求,那么这种差异是不能接受的。管理人员可以使用轨迹采样来查看路径效应,例如数据包循环、数据包丢失和多个最短路径,这些效应可能无法使用普通采样的NetFlow进行区分。
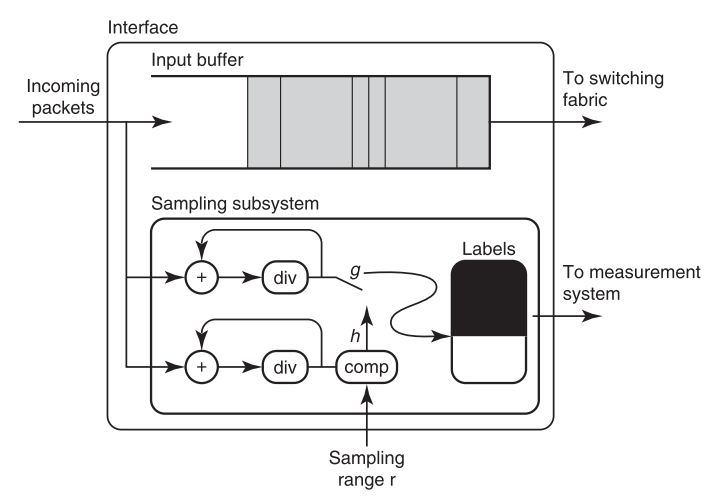
所以我们引入了轨迹采样技术。轨迹采样的主要思想是让数据流路径上的路由器使用一个公共的哈希函数做出相关的包采样决策。上图显示了进入路由器线卡的数据包的处理过程。对于每个数据包,都使用一个哈希函数h,通过将数据包的哈希值与指定的范围进行比较,来决定是否对数据包进行采样。如果对包进行采样,则使用包上的第二个哈希函数g再次哈希,并进行日志存储。
轨迹采样有两个要注意的地方:
- 如何确保路由器使用相同的哈希函数?
- 数据包里面的内容在传输过程中是会变化的,如何确保哈希函数的输入相同?
对第一个问题,我们可以让管理人员去配置路由器,以确保路由器使用相同的g和h哈希函数;对第二个问题,对于要进行哈希的数据包头部字段,我们只选择传输过程中不变的字段来计算哈希值。例如,可以选择使用五元组(源IP地址、目的IP地址、协议类型、源端口和目标端口)与IP标识符或者五元组加上TCP标志作为哈希函数的输入。
轨迹采样和NetFlow正常采样有两个差异:
- 使用哈希函数而不是随机数来决定何时对数据包进行采样;
- 对不变的数据包内容使用第二个哈希函数,可以更紧凑地表示数据包头部信息。
布隆过滤器(Bloom Filter)
我们可以只抽样每个数据流的第一个数据包进行分析,而不对整个数据流进行分析。
使用Bloom Filter是一种实现这种数据采样技术的方法。Bloom Filter是一种基于哈希函数的快速、空间效率高的数据结构,用于判断某个元素是否存在于一个集合中。它使用位数组(BitSet)标记某个元素是否出现过,而不需要存储元素本身。
具体地说,Bloom Filter包括一个位数组和多个哈希函数。将要检查是否存在的元素通过多个哈希函数分别映射到位数组的不同位置上,并将对应的位设置为1。当检查新元素是否存在时,将该元素经过相同的哈希函数计算得到的位进行比较,若所有位均为1,则认为该元素存在于集合中,否则认为不存在。哈希函数的设计可以使误判率控制在可接受范围内。
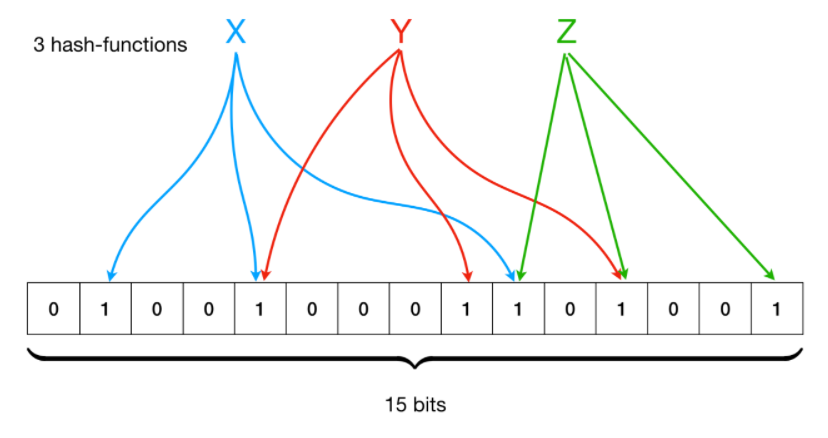
Bloom Filter的设计原理与上文阈值聚合中并行哈希层的思想类似。如上图,假设一个Bloom Filter中有三个哈希函数\(h1\),\(h2\),\(h3\),那么它会将输入的值,如x,计算得到\(h1(x)=1\),\(h2(x)=4\),\(h3(x)=9\),然后将BitSet的1,4,9位设置为1——这样就将输入值x映射到BitSet中的3个二进制位了。之后检查x是否已被记录只需要计算出对应的二进制位并检查是否全为1即可。要注意的是,当输入值计算得到的二进制位全为1时,实际上是不能100%的肯定该输入值已被Bloom Filter记录过的,因为有可能该输入值的所有位都刚好是被其他输入值设置为1)这种将划分错误的情况,称为误判(wrong position)。计算误判率的公式为:
其中插入Bloom Filter中的元素数目为n,BitSet位数为m,哈希函数的数目为k。从上式可以看出,当BitSet位数m增大或插入Bloom Filter中的元素数目n减小时,均可以使得误判率P下降。
在这种情况下,我们可以将正在传输的所有数据流的ID存储在Bloom Filter中。然后,当接收到新的数据包时,我们可以使用Bloom Filter查看该数据包所属的数据流是否已经被分析过,如果已经被分析过,则将其丢弃;否则,将其作为该数据流的第一个数据包进行分析。这样可以减少需要分析的数据包数量,从而提高网络流量分析的效率。
7 协同方案
本节要解决的具体问题有关协同方案(concerted schemes)。例如,ISP希望收集客户发送的流量统计信息,并根据流量类型和目的地向客户收费,一方面,这需要解决如何将Accounting正确进行的问题,另一方面,解决方案运行的开销要在可承受范围内。要想在整个网络中进行这般操作,就需要一个全面的协同的方案。
前文在讲述采样技术的过程中,我们从只需要单个本地路由器支持的单点方案转向了轨迹采样这样的协同方案——这要求多个路由器的合作来提取更多有用的信息。协同方案可以在不同的时间尺度(例如,路由计算,转发)上涉及网络系统的所有方面(例如,协议,路由器)。
我们接下来将看到两个使用协同方案的示例,分别为 Juniper networks 提出的DCU Accounting方案,以及协同思想进行流量矩阵计算。
7.1 Destination Class Usage
我们先来看一个单点Accounting带来的反面例子:
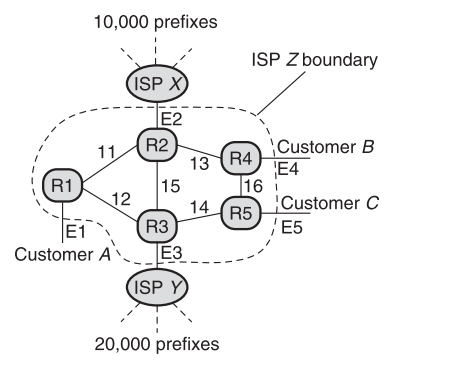
如图为一个小型的 ISP 网络,假设ISP Z希望以一个价格a向客户A收取通过ISP X流出的所有流量的费用,并以另一个价格b向客户A收取通过ISP Y流出的所有流量的费用。这样的话,一种最笨的解决方案是让 路由器R1 为发送到每个前缀的流量维护一个单独的计数器。在图中,R1至少需要维护10,000+20,000 = 30000个前缀计数器!这不仅使实现更加复杂,而且也与用户需求不符,因为用户最终将这30000个前缀聚合成仅仅两个资费类别。此外,如果路由变化频繁,每个ISP的前缀数量可能会快速变化而丢失,这就需要不断更新用于映射的Controller。
Juniper Networks公司给出了一个漂亮的协同计费方案:DCU计费(destination class usage,目标类使用 ) !
“DCU 通过执行 IP 目标地址查找来对来自客户的数据包进行计数,并且可以跟踪来自客户边缘且发往提供商核心路由器上特定前缀的流量。”
DCU由两个部分组成,分别为硬件实现和协议制定:
-
使用类计数器(Class Counters)。Class Counters是网络路由器中的一种计数器,用于记录每个流包含的数据包数量。在路由器的转发表中,每个条目都有一个16位的类ID,每个类ID中的1个bit表示一个类别。当数据包传输时,如果它与某个前缀匹配,并且具有关联的类ID,则与该类别对应的位的计数器会递增。
类计数器支持最多16个不同的类别,但单个数据包可以导致多个类计数器的递增。因此,这种方法能够更精确地记录每个流量的使用情况。同时,该解决方案也符合硬件设计实际情况,因为16个计数器与一个计数器相比并没有显著增加处理难度,并且可以在芯片上维护这些计数器以实现并行递增,从而提高效率。这种计数器通常被用于ISP等场景中,用于实现更精细化的计费策略和QoS(服务质量)控制。
-
路由支持(Routing Support):为了解决前缀变动的问题(这会导致Controller不断将每个前缀映射到不同的类中),DCU方案借助路由协议来解决。其想法是,来自ISP X的所有前缀都被赋予一种颜色(可以使用简单的路由策略过滤器进行控制),而来自ISP Y的前缀则被赋予另一种颜色。因此,当像上图R1这样的路由器收到带有颜色c的前缀P的路由信息时,它会自动将前缀P映射到类c中。这个路由协议上的小改变可以极大地减少Controller的工作量。
Juniper Networks还有其他方案,包括使用基于分组分类器的计数器和基于MPLS隧道的计数器。这些方案比DCU计费稍微灵活一些,因为它们可以在确定数据包的类时考虑数据包的源地址。但是这些方案因为缺乏路由支持,所以不具备DCU计费的管理扩展性。
7.2 计算流量矩阵
虽然DCU解决方案仅对Accounting有用,但它的一些基本思想可以帮助解决流量矩阵问题。流量矩阵问题是许多互联网服务提供商非常感兴趣的问题。
7.2.1 流量矩阵的意义
流量矩阵(Traffic Matrix)是指在网络中各个节点之间的流量量化信息。它记录了从源节点到目标节点的流量量级或流量比例。流量矩阵可以根据不同的时间尺度(从几小时到几个月)进行测量和分析。
我们继续利用 7.1 图中的ISP网络来介绍,来自ISP Z中的路由器的一些链路会到达属于其他ISP (如E2, E3)或客户(如E1, E4, E5)的路由器,我们称这种联系为external links;指向从外部指向ISP内部路由器的external links称为input links,而从ISP指向外部路由器的external links称为output links。
流量矩阵列举了网络中每对input和output links之间发送的流量(在某个任意时间段,例如一整天)。例如,在 7.1 图中,流量矩阵可以告诉ISP Z的管理者,custom A 白天有60mbps的流量input,其中有20mbps作为output通往 ISP X 的peer-link E2上,剩余的40mbps由link E5作为output通往custom B。
对于网络运营商来说,流量矩阵是必不可少的。它们可用于:
- 做出更优的路由决策:通过分析流量矩阵,ISP可以了解当前网络中的流量分布情况,并根据需要调整路由设置,例如可以通过改变OSPF权重或建立MPLS隧道来解决次优路由问题);
- 用于了解何时建立
circuit switch,以用于避免hot spot产生(为hot spot流量分配专用的物理路径,避免与其他流量竞争网络资源,使得hot spot流量可以在专用路径上独立传输) - 用于网络诊断,了解网络堵塞的原因;
- 以及用于网络规划(了解不同链路的负载情况,从而决定是否需要升级或调整特定链路的带宽或容量,以满足未来的流量需求)。
流量矩阵很好!但是现在存在一个问题:传统路由器只提供单个聚合计数器(即 SNMP link byte counter),而从聚合计数器获得的值去推断流量矩阵是有大问题的。
为什么 SNMP link byte counter 不能用来推断流量矩阵?
聚合计数器: SNMP link byte counter 提供的是对整个链路上所有流量的聚合计数(字节流量的总数)。它无法提供对特定流量对(例如源IP地址和目标IP地址)的细分计数。
稀疏网络:许多网络都是稀疏的,即只有少数几个external link。在这种情况下, SNMP link byte counter 的数量可能与链接数量(即已知量数量)相当。缺乏足够的计数器使得推断流量矩阵变得更加困难。
变量数量:流量矩阵中可能存在大量的 input/output link pair,而 SNMP link byte counter 的数量相对较少。在已知流量路由的情况下,我们会产生O(V)个方程和O(V^2)个变量,其中V是external link的数量。这样的方程数量不足以解决所有的变量。例如假设有3个external link,T_xy为由E_x到E_y的流量,方程右侧为external link 流量计数值:
\[T_{12}+T_{13}+T_{21}+T_{31}= Traffic\ \ E1\\ T_{21}+T_{23}+T_{12}+T_{32}= Traffic\ \ E2\\ T_{31}+T_{32}+T_{13}+T_{32}= Traffic\ \ E3 \]明显该方程无法求解。
对于存在的流量矩阵推断难题,我们接下来将介绍三种协同方案。
7.2.2 网络层析
Internet tomography(互联网层析成像)是一种利用从端点数据中获取的信息来研究网络内部特征的方法。它类似于医学中的CT(计算机断层扫描)技术,旨在通过检查来自"边缘节点"(即数据的起源和请求节点)的信息来绘制数据在互联网中的路径,方法核心在于多信息源和统计推断。
在推断流量矩阵时,由于SNMP计数器的特性导致不可能进行确定性的推断,所以需要采用统计推断的方法(尽管存在一定的误差)。Internet tomography利用统计学和概率模型来推断流量矩阵中的未知变量,它基于多处协同观察到的数据和一些假设的流量分布模型(如 Gaussian Distribution 高斯分布, 或 Gravity Model 重力模型),使用统计学原理(如maximum likelihood,最大似然估计)或优化技术(如quadratic programming,二次规划)来推断流量矩阵中的变量值。
Internet tomography 的最大优点是它不需要改造现有的路由器(它通过在网络中部署测量设备,如探针,来观察流量数据,而不需要对路由器进行任何修改或添加额外的硬件),而且在路由器中实施成本较低(利用现有设备,无需额外测量节点)。
这种方法的缺点在于:
- 推断结果的潜在误差:误差可能高达20%!见Robust Traffic Matrix Estimation with Imperfect Information: Making Use of Multiple Data Sources)
- 对路由错误的敏感性:如果存在单个链路故障或路由错误,推断结果可能会出现50%的偏差(如一个链路断开而没有被发现,明面上拓扑结构照旧)
- 对网络拓扑的敏感性:网络拓扑的变化或结构的复杂性可能导致推断结果的不准确性。
7.2.3 per-prefix 计数器
前文中介绍的DCU计费方案其实可以算是一个用来解决流量矩阵问题的基于路由器实现和路由协议变化的系统解决方案,DCU体现了现代路由器的设计思想。而这节内容延续这种协同工作思想,继续介绍一种用于流量矩阵计算的路由器计数器设计——per-prefix计数器。
在使用per-prefix计数器的方案中,每个输入line card都有一个转发引擎(forwarding engine),其中包含转发前缀表的副本。假设转发前缀表中的每个前缀 P 都有一个关联的计数器,那么每个前缀与 P 匹配的数据包在进入line card时,都会使计数器增加相应的字节数。最后,通过汇总 input link 尾端路由器中的per-prefix计数器,就可以构建流量矩阵。为了实现这一点,该方法必须有一定的关键信息支持:包括路由协议(如OSPF)计算的路由信息和前缀路由与 output link 之间的映射关系。
我们来举一个例子:在7.1的图中,如果R1在来自链路E1的流量上使用per-prefix计数器,那么就可以对来自ISP X的10,000个前缀对应的计数器求和,从而找到Customer A和ISP X之间的流量关系。
这种方案的一个优点是它提供了堪称完美的流量矩阵!第二个优点是它可以用于像DCU那样的基于目的地址的差异性流量计费。但也存在两个缺点:一方面是在实施上维护 per-prefix计数器 的复杂性。传统路由器中缺乏这样的设计,支持这种方案意味着需要对传统路由器进行改进或引入新的路由器实现。另一方面,由于协同工作,需要从每个路由器收集和合成大量数据以形成流量矩阵,这可能需要大量的带宽和存储资源,并且需要高效的数据处理和分析算法来处理这些大规模的数据集。
7.2.4 类计数器
class counter(类计数器)在我们介绍DCU章节中已经有所提及,这节我们继续介绍它在流量矩阵计算中的使用。
我们可以将每个前缀通过转发表映射到一个小的类别ID,该ID通常为8至14位(256至16,384个类别)。当一个输入数据包与前缀P匹配时,P的转发条目将数据包映射到一个类计数器,并对该计数器进行递增操作。对于多达10,000个计数器,类别计数器可以轻松存储在转发ASIC的片上SRAM中,从而允许在内部并行进行递增操作和其他功能。
在前文的DCU Accounting中,DCU建议路由器使用策略过滤器按计费类别为路由进行分类着色,并使用路由协议传递这些颜色分类信息,这些分类信息可以用来在每个路由器上自动设置类别id。对于流量矩阵计算,可以使用类似的思想,根据矩阵等价类对路由进行着色。
矩阵等价类:所有源自同一 external link 或网络的前缀都属于同一个类别。
那么原理知道了,类计数器是怎样使用在流量矩阵计算中的呢?
我们知道,许多ISP在主要城市设有PoP,这就需要计算聚合的PoP到PoP流量矩阵。通过将不同的PoP分配到不同的类别中,可以直接依靠类别计数器来计算和分析PoP到PoP之间的流量矩阵,这样可以更加方便地获取和处理与特定PoP相关的流量信息,而无需对完整的 路由器--路由器矩阵 进行聚合。例如,在7.1图中,R4和R5可能属于同一个PoP,那么E4和E5就可以被映射到同一个类别中。
根据2003年的测量数据,类别计数器的数量大大减少——使用150个计数器就足以处理最大的ISP的情况。这意味着通过合理的分类和计数器使用,可以在保证高效性能的前提下,减少需要处理的计数器数量,从而降低了系统的复杂性和资源消耗。
8 被动测量的例子:Sting
到目前为止,前文都专注于涉及对路由器实现(如计数器)和其他子系统(如路由协议)进行更改的路由器测量问题。但是这类方案需要多个路由器供应商进行合作,由于更改需要与现有的网络设备和协议进行兼容,所以使用这类方案会面临着逐步部署的困难。与之相比,被动测量侧重于通过 “欺骗网络” 来获得有用的测量数据,而无需改变网络内部结构。被动测量的基本思想是克服互联网协议套件所提供的测量支持的缺乏。
假设你不再是一个ISP,而是某个公司的网络管理员。一家新兴的 ISP 声称可以提供比你现在使用的 ISP 更好的服务。那么你肯定想测试一番来验证他们说的真假!为了验证,你将轮流使用两个 ISP ,从你的站点到全国各地的各种Web服务器进行端到端的性能测量。
标准解决方案是使用基于发送ICMP消息的Ping和Traceroute等工具。但是这些工具存在一个问题:ISP 经常过滤或限制此类消息(你可以自己试试看,ISP 会隐藏它们的路由节点,避免你搞到它们的网络拓扑)。为了克服这个限制,Stefan Savage发明的Sting 工具提出了一个绕过这个限制的想法:
将测量数据包伪装成TCP数据包,互联网服务提供商和Web服务器无法丢弃或限制此类数据包(因为在它们眼里这不属于垃圾数据)——这意味着通过利用TCP协议的各种机制,Sting工具能够提供更多的测量自由度。
我们先来看如何确定源和远程Web服务器之间丢包概率。
确定丢包概率有助于了解大多数流量在网络上是不是仅仅为单向传输。对于Ping工具,即使Ping没有受到速率限制,它也只是提供了双向丢包概率的综合信息。而Sting工具提出了一种从源到远程Web服务器确定丢包概率的算法:
data seeding阶段:首先通过与服务器建立正常的TCP连接,并按顺序向服务器发送N个数据包。此阶段忽略了Acknoledgement,因为我们关注的是测量,而不是数据传输;hole filling阶段:接下来,发送一个带有比data seeding阶段中最后一个发送的数据包序列号大1的数据包。如果收到Acknoledgement,说明一切正常,没有丢失任何数据包。如果没有,在进行足够的重传之后,接收方会回复已经按顺序接收到的最大序列号X。发送方现在只发送与 X+1 相对应的段。最终,接收方会发送一个更新的Acknoledgement,其中包含下一个按顺序接收到的最大序列号。接收方会填充下一个"hole",并继续进行,直到填充完所有的"hole"。在第二阶段结束时,发送方准确地知道在第一阶段中丢失了哪些数据包,并可以计算出丢包率。
计算反向丢包率更加具有挑战性,因为接收方的TCP可能会将确认信息批量发送,而不是对每个数据包进行单独的确认。然而由于Sting工具并不遵守真正意义上的TCP连接,那么就可以通过改变工具的行为来欺骗接收方:Sting在第一阶段发送乱序的数据包,而不是按顺序发送,以引诱接收方提供更准确的确认信息。通过这种方式,Sting能够绕过接收方TCP的批量确认机制,获得所需的信息以计算反向丢包率。
(这听起来和hacker做的事情没有什么区别……但这就是Sting的思想所在,"Stop thinking of a protocol as a protocol"!)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号