计网学习笔记九 Routing Fundamentals
在这一讲开始讲路由器的控制平面。简单介绍了routing,两个最小cost算法。
参考看的文章:
VC网络和数据报网络中路由的区别:Differences between Virtual Circuits and Datagram Networks
三种路由方式(静态、默认和动态):Types of Routing
Routing简介
network对象不同:datagram和vc网络不同的route方式
需要有的特点:效率,弹性(鲁棒)和稳定性(避免震荡)
下面的内容会围绕一个抽象的network来介绍routing的一些组成元素。
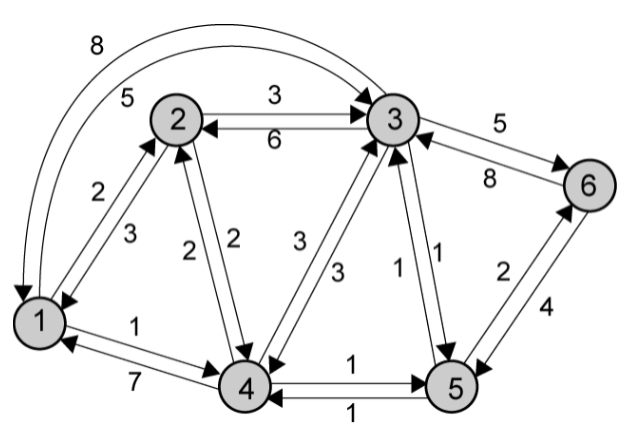
Performance criteria 性能指标
可以按照以下几种方式来评判一条路由的性能:
- 最小跳数:直接等于routing过程中经过的跳数,越少越好;
- 最小消耗:根据链路消耗来决定routing路径,决定链路消耗的方式有:
- 链路上的延迟,即可以将当前路由器interface上的queue长度作为评判标准;
- 吞吐量,即interface的传输速率;
- 还有丢包率、运营商发送价格等...
Decision time 什么时候决策
对数据报网络,每个packet到达的时候就查一下表,然后决策;
对VC网络,只在VC网络建立的时候做一次decision,即在那时已经把路由表建好。
Decision place 在哪里决策
集中式:用一个专门的节点算好,然后配置到其它节点中(类似SDN);
分布式:每个路由节点分布地计算路由表;
Info source 提供信息的源
例子:高德地图是中心化的,收集全部的数据后发回中心地方统一计算;
信息源可以来自本地信息、邻近的交换信息、network中的全部交换信息,交换信息具体有一条链路的负载、消耗、路由器存着的一些信息如distance vector.(但并不是需要所有的信息,看路由算法,可能会挑其中的一类或两类)
Info update timing 更新频率
分以下几种:
- 周期性更新;
- 发生重大(主要)变化时才进行更新,如可以考虑链路负载,一分钟更新一次负载,然后更新;
- 手动更新。
Different Routing Strategies 路由策略
分两种:
- 集中式:即静态路由,由中心节点计算后进行路由表发放,如SDN;或者网管手动配置。
- 分布式:有三种:flooding、random和adaptive(自适应路由,也就是动态路由)。
下面对这些路由策略具体介绍。
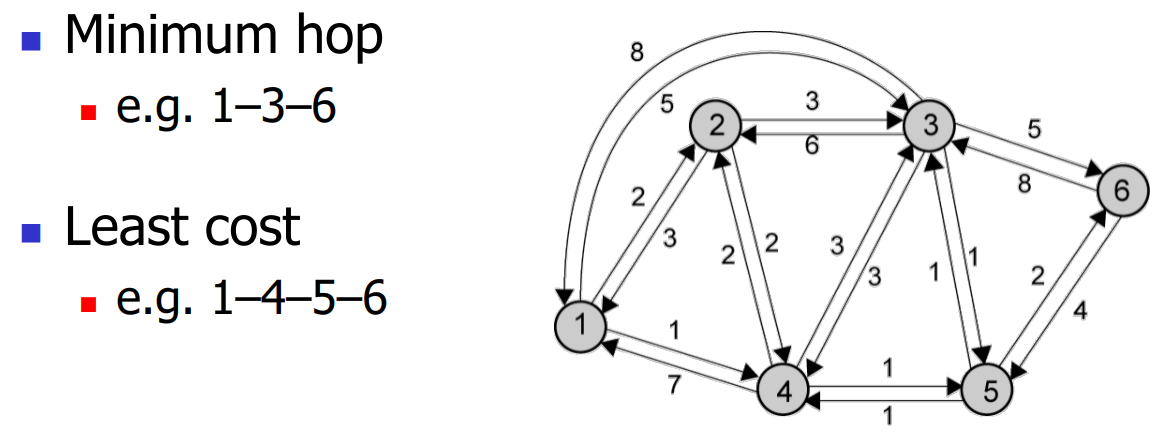
Central Routing
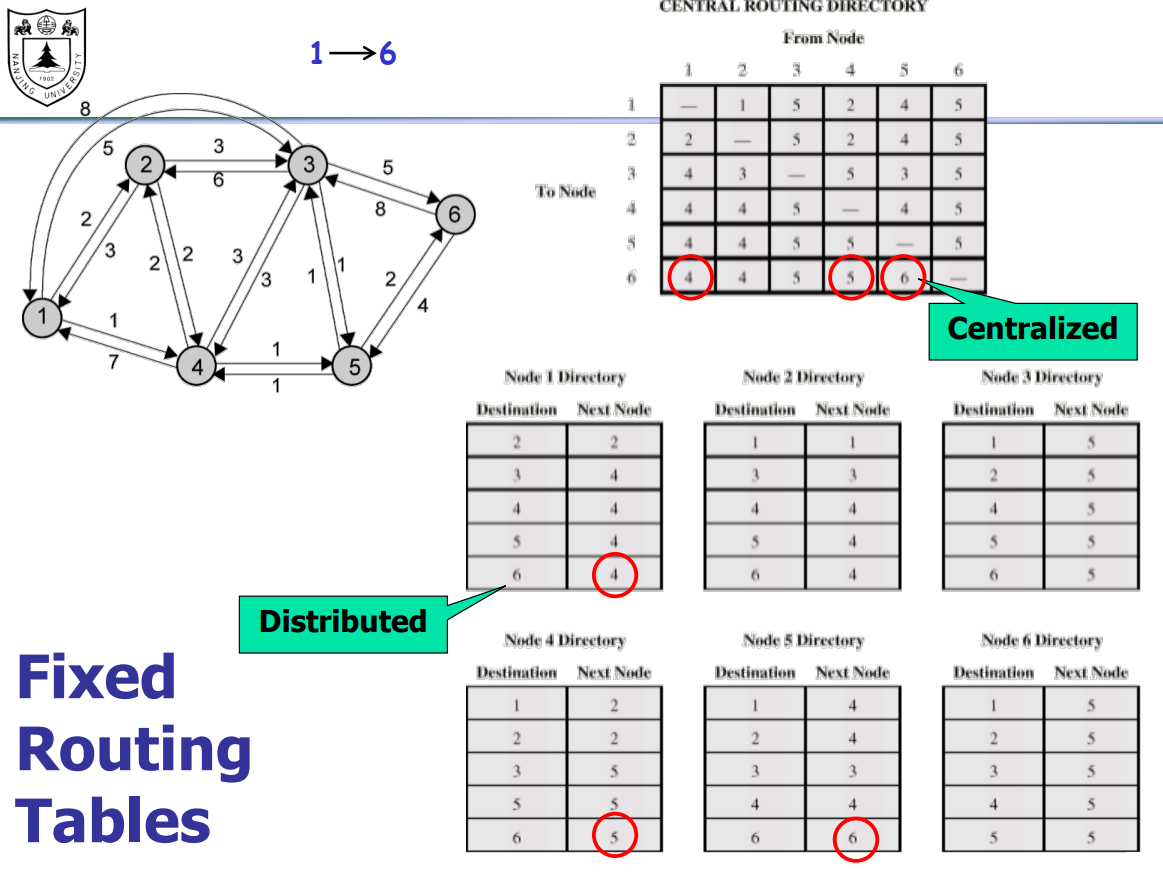
- Single fixed route for each source to destination pair.
- Determine routes using a least cost algorithm.
- Routes re-config upon major changes in network topology.
固定的路由表,由中心节点使用路由算法生成。生成总表后分到各个节点中。(互联网最悠久,但不是最常用)
Flooding
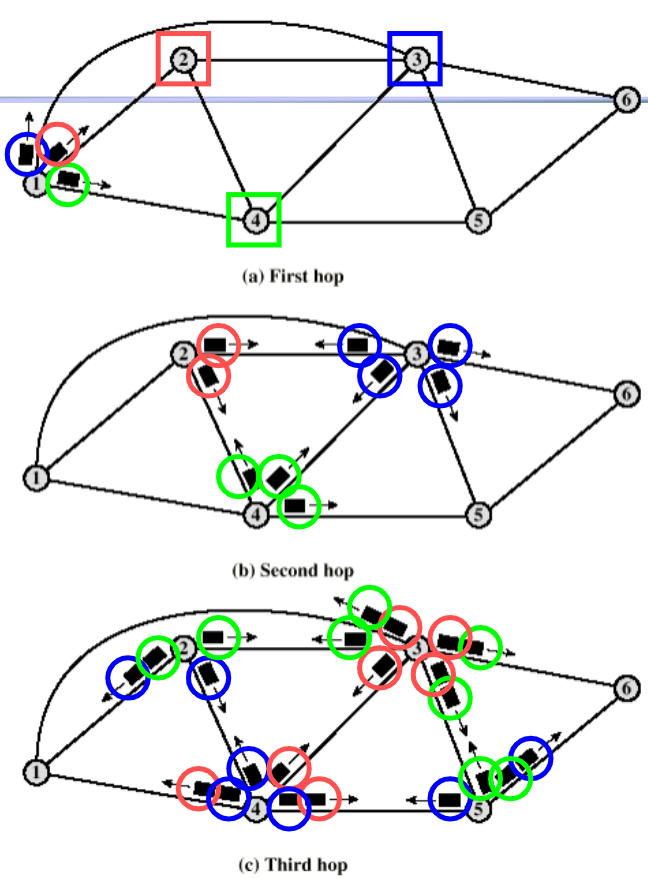
例子:传感器网络可以采用这种路由方式。
不需要任何的网络信息。
收到就flooding一下,最终有一系列的复制样本到达目的地;
代价就是会创建太多复制样本,高度占用信道;
还有会出现一个环路问题:加入TTL就可以解决。
如图接收端总共收到四份。非常鲁棒!只要双方保证连通性,保证可以收到packet。而且至少有一个包可以走上最小路径。
可以用来在一开始时找最小路径,用一次flooding即可,在VC网络很常见。
Random Routing
每次发包选一个口,可以是随机的,可以是轮询的,或者对每个口加权;
不需要任何的network信息支持,对连通性很强的网络很适合(有很多很多邻居);策略就是使packet在网络中一直走,来回走,直到目的地;
在random的基础上可以进行一定的加权。如何加权?

cost的标准和上面的一样:

Adaptive Routing
也就是动态路由(dynamic routing)。很重要!几乎所有分组交换网络都使用!
需要网络信息,根据路由算法来权衡获取信息的质量和获取开销;
可以糅合一些重要信息,如链路断啦、负载太高啦啥的,有助于拥堵控制。
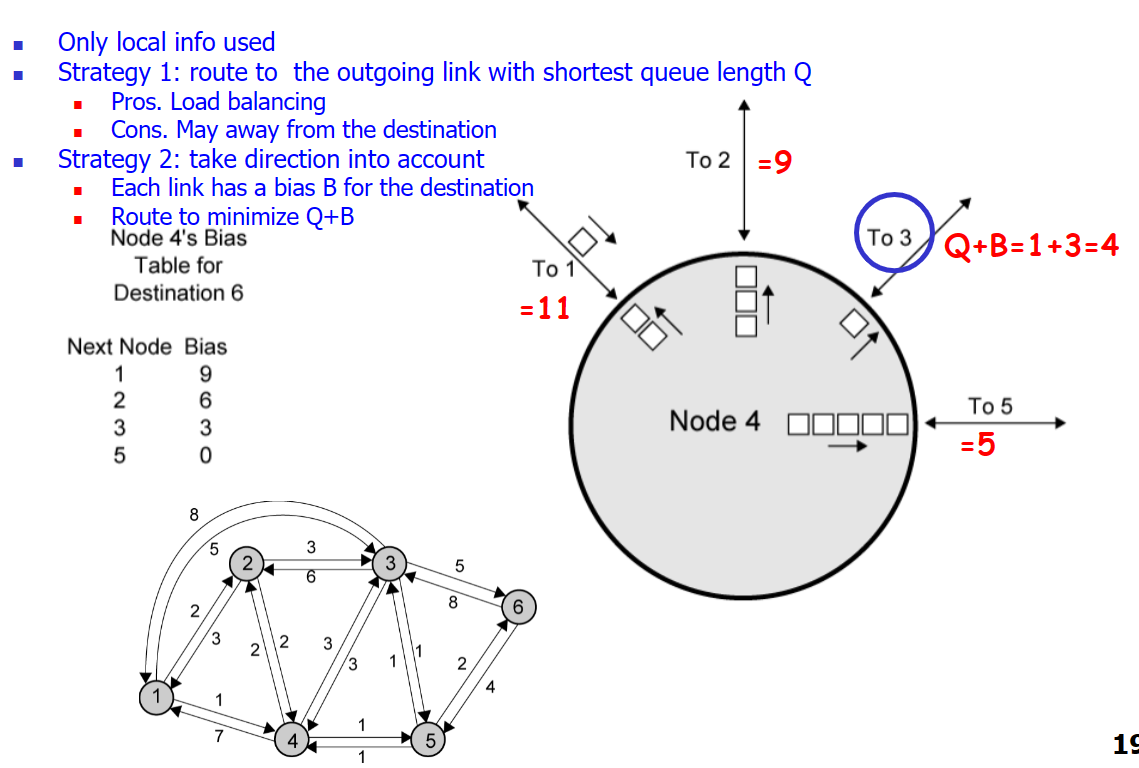
下面给一个Adaptive Routing例子,演示了在单节点路由,只需本地信息不需要网络信息进行路由:
路由策略有两种:
-
直接根据队列长度进行路由选择;
-
设置指向目标节点的偏好量B;看节点对四个邻居的偏好量,选择最高那个进行转发;
如果对这些种类傻傻地分不清,可以看看文章:
Least Cost Algorithms
简单介绍完路由,让我们来细致一点看动态路由具体是怎样算出路由的最小消耗路径的。主要有两种算法,都是之前学过的,用来建立一个最小生成树的算法,所以这里也不详细描述算法过程。算法只是路由过程的一个抽象,具体规定要看具体的协议。协议下一节描述。
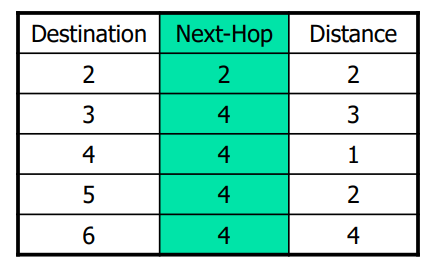
Dijkstra’s Algorithm
算出当前节点到其它节点的最短路径,从近到远生成;

最终节点1的路由表如下:
震荡问题
当链路的cost设置不好时会发生震荡问题,即不同链路上的流量负载反复变动,从一边跑向另一边,又从那边跑回来(流量不同,更改路由,导致流量又不同,又更改路由);
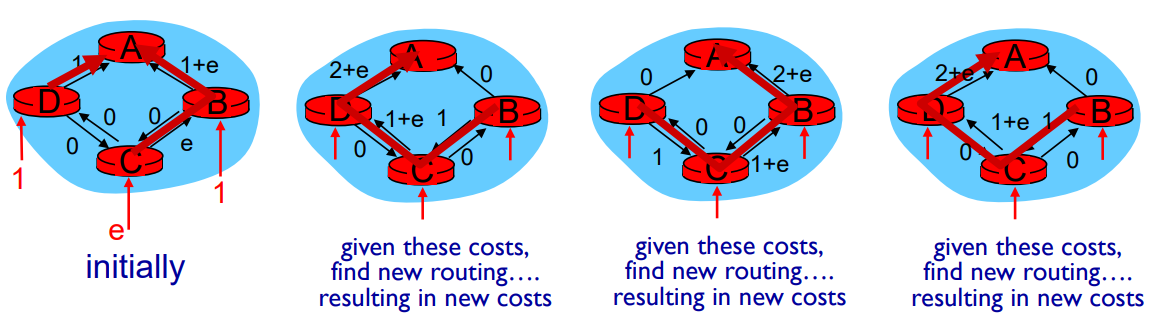
解决方法:链路代价更新不要和路由算法严格绑定。具体过程:RFC 7964
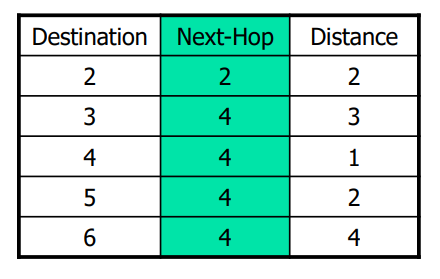
Bellman-Ford Algorithm
先看一跳信息,再根据一跳结果看两跳信息,再看三跳四跳...迭代次数至少为N-1,直到没有新的交换信息。

最终节点1的路由表如下:
好消息与坏消息
BF算法在路由的使用有句话:“好消息传得快,坏消息传得慢”。是什么意思呢?
在network里面,节点会对本地连接的链路进行监听,如果链路的cost改变了,那么更新路由信息,重新计算DV,如果DV改变了就要将其向邻居通告;所以对应会出现以下两种情况:
好消息
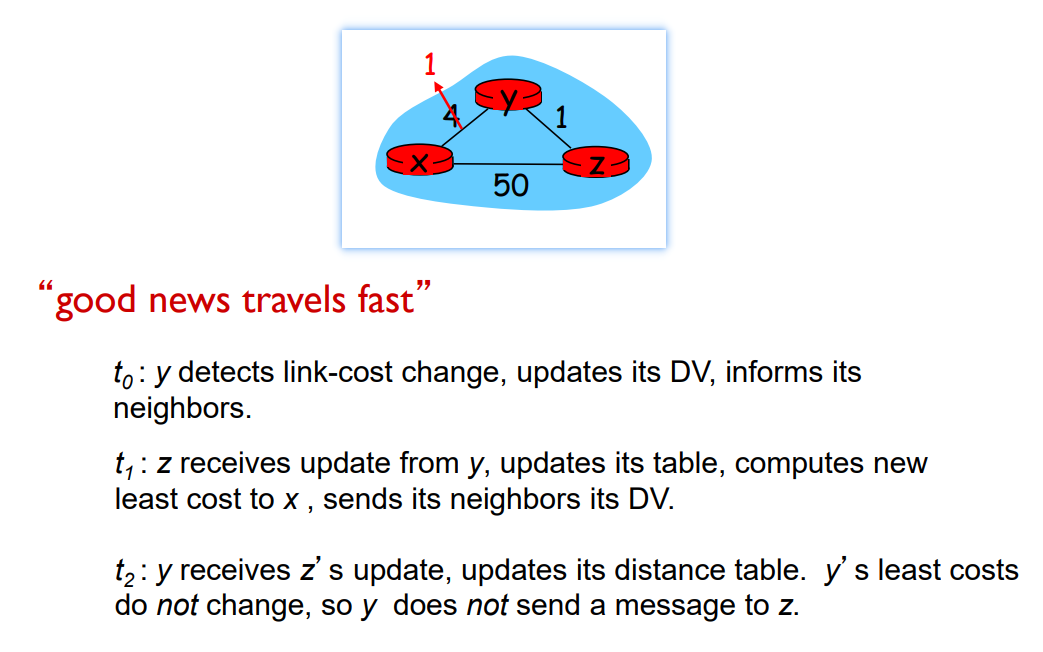
可以看出这种链路的改变是很好的,z接收到y的DV改变信息也能很快完成自身的调整;
坏消息
坏消息也被称为“count to infinity” 问题。如下,如果c(x,y)变为60而不是1,会发生很严重的情况!

y和z互相发消息更新,44次后才稳定下来;(因为y不知道z的DV是经过y它自己的)
解决方法就是,做点手脚,使用毒性逆转(poisoned reverse):告诉y我z到x的DV是无限。
但因为毒性逆转只看下一跳,所以在三个或以上节点的环路出现时不能根本上解决问题。见习题P11.b。
Dijkstra vs. Bellman-Ford
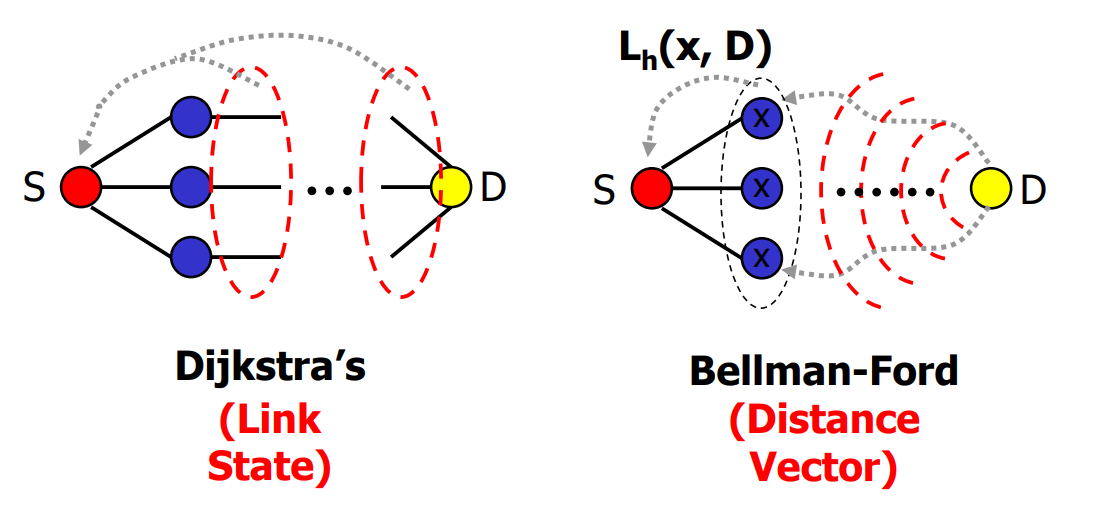
Dijkstra又称为link state路由算法,Bellman-Ford又称为distance vector路由算法。
对于LS来说:
- 每一条链路上的信息都要广播给整个网络上的路由器节点,也就是说牵一发而动全身;
- 每个路由器节点都有整个网络拓扑的信息(每个节点都用这拓扑来计算路由)
- 由于算法特性,链路上的cost不能设置为负数。
对于DV来说:
- 每个路由器节点存储的不是整个拓扑的信息,而是只需要维护其邻居节点的DV就行了;
- 自己的DV如果改变了,需要对其广播出去,让邻居知道好做路由调整;
- 是将一层层的DV广播出去;
两者的信息复杂度、算法收敛速度、鲁棒性比较如下:

Determine Link Cost 链路代价计算
ARPANET中的路由算法
ARPANET作为互联网雏形,路由算法的发展经过了三个阶段,不同阶段链路代价的标准也不同:
第一阶段使用的是DV路由算法:

第二阶段是LS算法:

到了第三阶段,因为震荡问题的出现,LS算法作了一点改进:在负载量高的链路上增加一个等待的步骤,等待一定的时间后再进行路由更新;并且对链路cost的标准做出了改变:

Calculate Link Cost
Link utilization:计算链路使用率
Leveling: 对过去的数据在一个时间窗口做一个平滑


 浙公网安备 33010602011771号
浙公网安备 33010602011771号