2022暑假每日一题笔记(三)
T1--693. 行程排序
玛丽需要从某地飞往另一目的地,由于没有直达飞机,所以需要在中途转很多航班。
例如:SFO -> DFW DFW -> JFK JFK -> MIA MIA -> ORD。
显然旅途中不可能到同一中转城市两次或以上,因为这没有意义。
不幸的是,她将自己的机票的顺序搞乱了,将机票按乘坐顺序整理好对她来说不是一件容易的事。
请你帮助玛丽整理机票,使机票按正确顺序排列。
输入格式
第一行包含整数 T,表示共有 T 组测试数据。
每组数据第一行包含整数 N。
接下来 2N 行,每 2 行一组,表示一张机票的信息,每行包含一个字符串,其中第一行表示出发地,第二行表示目的地。
输出格式
每组数据输出一个结果,每个结果占一行。
结果表示为 Case #x: y,其中 x 是组别编号(从 1 开始),y 是表示实际行程的机票列表,行程中的每个航段应以 source-destination 的形式输出,航段之间用空格隔开。
数据范围
1≤T≤100,
1≤N≤10000
输入样例:
2
1
SFO
DFW
4
MIA
ORD
DFW
JFK
SFO
DFW
JFK
MIA
输出样例:
Case #1: SFO-DFW
Case #2: SFO-DFW DFW-JFK JFK-MIA MIA-ORD
参考了y总的代码。
#include <bits/stdc++.h>
using namespace std;
int n;
int main(){
int t;
cin >> t;
for (int x = 1;x <= t;x ++){
unordered_map<string,int> s;
unordered_map<string,string> link;
cin >> n;string a,b;
for (int i = 0;i < n;i ++){
cin >> a >> b;
s[a] ++,s[b] ++; // 统计机场出现次数
link.insert({a,b}); // 记录机票
}
string head; // 遍历查找起点
// 起点必然满足两个条件:1.只在一张机票出现 2.不能作为目的地
for (auto &[k,v] : s){
if (v == 1 && link.count(k)) head = k;
}
string str = head;
printf("Case #%d: ",x);
for (int i = 0;i < n;i ++){
cout << str << "-";
str = link[str];
cout << str << ' ';
}
puts("");
}
return 0;
}
T2--3428. 放苹果
把 M 个同样的苹果放在 N 个同样的盘子里,允许有的盘子空着不放,问共有多少种不同的分法?
盘子相对顺序不同,例如 5,1,1 和 1,5,1 算作同一种分法。
输入格式
输入包含多组测试数据。
每组数据占一行,包含两个整数 M 和 N。
输出格式
每组数据,输出一行一个结果表示分法数量。
数据范围
1≤M,N≤10
输入样例:
7 3
输出样例:
8
不会,参考题解。
DFS思路类似递归实现组合型枚举。
对于1,1,5和1,5,1两种放法,本题中将它们视为一种方案,所以DFS搜索时通过升序加以限制,只记录升序的方案,这样就不会重复计算。
#include <bits/stdc++.h>
using namespace std;
int m,n;
int dfs(int u,int last,int sum){
// u:放置第u个盘子,last:上个盘子放的苹果数,sum:剩余可放苹果数
if (u == n+1){
if (sum == 0) return 1; // 全部苹果放入n个盘子为一个方案
return 0;
}
int res = 0;// 放完前u个盘子,枚举后面的盘子
for (int i = last;i <= sum;i ++){
// 从上次放的苹果数开始枚举,保证方案不重复
res += dfs(u+1,i,sum - i);
}
return res;
}
int main(){
while (cin >> m >> n){
cout << dfs(1,0,m) << '\n';
}
return 0;
}
T3--3477. 简单排序
给定一个包含 n 个整数的数组,请你删除数组中的重复元素并将数组从小到大排序后输出。
输入格式
第一行包含一个整数 n。
第二行包含 n 个不超过 1000 的正整数。
输出格式
输出去重和排序完毕后的数组。
数据范围
1≤n≤1000
输入样例:
6
8 8 7 3 7 7
输出样例:
3 7 8
在离散化中用到的数组排序和去重。
#include <bits/stdc++.h>
using namespace std;
int main(){
int n,x;
vector<int> v;
cin >> n;
for (int i = 0;i < n;i ++){
cin >> x;
v.push_back(x);
}
sort(v.begin(),v.end());
v.erase(unique(v.begin(),v.end()),v.end());
for (auto it : v) cout << it << ' ';
return 0;
}
更加简单的做法:
#include<bits/stdc++.h>
using namespace std;
int main()
{
int n,i,a[1001];
cin>>n;
for(i=1;i<=n;i++)cin>>a[i];
sort(a+1,a+1+n);
for(i=1;i<=n;i++)if(a[i]!=a[i-1])cout<<a[i]<<' ';
return 0;
}
T4--3531. 哈夫曼树
给定 N 个权值作为 N 个叶子结点,构造一棵二叉树,若该树的带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)。
现在,给定 N 个叶子结点的信息,请你构造哈夫曼树,并输出该树的带权路径长度。
相关知识:
1、路径和路径长度
在一棵树中,从一个结点往下可以达到的孩子或孙子结点之间的通路,称为路径。通路中分支的数目称为路径长度。若规定根结点的层数为 1,则从根结点到第 L 层结点的路径长度为 L−1。
2、结点的权及带权路径长度
若将树中结点赋给一个有着某种含义的数值,则这个数值称为该结点的权。结点的带权路径长度为:从根结点到该结点之间的路径长度与该结点的权的乘积。
3、树的带权路径长度
树的带权路径长度规定为所有叶子结点的带权路径长度之和,记为 WPL。
输入格式
第一行包含整数 N,表示叶子结点数量。
第二行包含 N 个整数,表示每个叶子结点的权值。
输出格式
输出一个整数,表示生成哈夫曼树的带权路径长度。
数据范围
2≤N≤1000,
叶子结点的权值范围 [1,100]。
输入样例:
5
1 2 2 5 9
输出样例:
37
#include <bits/stdc++.h>
using namespace std;
int main(){
int n;
cin >> n;
int x;
priority_queue<int,vector<int>,greater<int>> heap;
for (int i = 0;i < n;i ++) {
cin >> x;
heap.push(x);
}
int res = 0;
for (int i = 0;i < n-1;i ++){
int a = heap.top();heap.pop();
int b = heap.top();heap.pop();
int s = a + b;
heap.push(s);
res += s;
}
cout << res << '\n';
return 0;
}
T5--3438. 数制转换
求任意两个不同进制非负整数的转换(2 进制 ∼ 16 进制),所给整数在 int 范围内。
不同进制的表示符号为(0,1,…,9,a,b,…,f)或者(0,1,…,9,A,B,…,F)
输入格式
输入只有一行,包含三个整数 a,n,b。a 表示其后的 n 是 a 进制整数,b 表示欲将 a 进制整数 n 转换成 b 进制整数。
a,b 是十进制整数。
数据可能存在包含前导零的情况。
输出格式
输出包含一行,该行有一个整数为转换后的 b 进制数。
输出时字母符号全部用大写表示,即(0,1,…,9,A,B,…,F)。
数据范围
2≤a,b≤16,
给定的 a 进制整数 n 在十进制下的取值范围是 [1,2147483647]。
输入样例:
15 Aab3 7
输出样例:
210306
由于本题数据范围较小,可以通过十进制过渡一下,数据范围大的话直接用短除法(参考考研笔记(一)的最后一道题)。
秦九韶算法:常用于a进制转十进制。
一般地,一元n次多项式的求值需要经过(n+1)*n/2次乘法和n次加法,而秦九韶算法只需要n次乘法和n次加法,降低了时间复杂度。( O(n^2) --> O(n) )
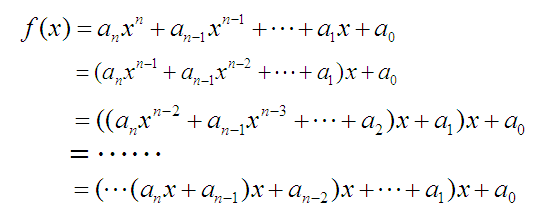
求解流程:(1)用秦九韶算法将a进制转十进制;(2)用短除法十进制转b进制。
代码参考y总讲解:
#include <bits/stdc++.h>
using namespace std;
char iotc(int x){ // int转char
if (x <= 9) return x+'0';
return x-10+'A';
}
int ctoi(char c){ // char转int
if (c <= '9') return c-'0';
else if (c <= 'Z') return c+10-'A';
return c+10-'a';
}
int main(){
int a,b;
string n;
cin >> a >> n >> b;
int t;
for (auto i : n) t = t*a + ctoi(i); // 秦九韶算法,转十进制
string ans;
while (t) ans += t%b,t /= b; // 短除法,转b进制
reverse(ans.begin(),ans.end());
for (auto i : ans) cout << iotc(i);
return 0;
}
T6--3511. 倒水问题
有三个杯子,容量分别为 A,B,C。
初始时,C 杯装满了水,而 A,B 杯都是空的。
现在在保证不会有漏水的情况下进行若干次如下操作:
将一个杯子 x 中的水倒到另一个杯子 y 中,当 x 空了或者 y 满了时就停止(满足其中一个条件才停下)。
请问,在操作全部结束后,C 中的水量有多少种可能性。
输入格式
输入包含多组测试数据。
每组数据占一行,包含三个整数 A,B,C。
输出格式
每组数据输出一个结果,占一行。
数据范围
0≤A,B,C≤4000,
每个输入最多包含 100 组数据。
输入样例:
0 5 5
2 2 4
输出样例:
2
3
把三个杯子的水量合并为一个状态,DFS所有状态,然后记录C杯子的不同容量。
#include <bits/stdc++.h>
using namespace std;
typedef long long LL;
LL cup[3],c[3]; // cup,c分别记录当前杯子装的水和杯子容量
unordered_set<LL> states;
unordered_set<int> ans;
// 每个杯子容量不超过4位数,三个杯子共12位数,表示一个状态
LL get(){ // 计算当前杯子状态
return cup[0]*1e8 + cup[1]*1e4 + cup[2];
}
void pour(int a,int b){ // 模拟倒水,三个杯子共有6种倒法
LL x = min(cup[a],c[b] - cup[b]); // 倒空或倒满
cup[a] -= x,cup[b] += x;
}
void dfs(){
LL state = get();
if (states.count(state)) return;
states.insert(state);
ans.insert(cup[2]);
LL temp[3]; // 临时记录当前状态,倒水时会改变状态
for (int i = 0;i < 3;i ++)
for (int j = 0;j < 3;j ++){
if (i != j){
memcpy(temp,cup,sizeof cup);
pour(i,j);
dfs();
memcpy(cup,temp,sizeof cup); // 恢复现场
}
}
}
int main(){
while (cin >> c[0] >> c[1] >> c[2]){
states.clear(); // 清空状态
ans.clear();
cup[0] = cup[1] = 0;
cup[2] = c[2];
dfs();
cout << ans.size() << '\n';
}
return 0;
}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· C#/.NET/.NET Core技术前沿周刊 | 第 29 期(2025年3.1-3.9)
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异