PyTorch学习笔记
课程地址:https://deeplizard.com/course/ptcpailzrd
Syllabus
-
PART 1: TENSORS AND OPERATIONS
-
- Section 1: Introducing PyTorch
- PyTorch Prerequisites - Neural Network Programming Series
- PyTorch Explained - Python Deep Learning Neural Network API
- PyTorch Install - Quick and Easy
- CUDA Explained - Why Deep Learning Uses GPUs
- Section 2: Introducing Tensors
- Tensors Explained - Data Structures of Deep Learning
- Rank, Axes, and Shape Explained - Tensors for Deep Learning
- CNN Tensor Shape Explained - CNNs and Feature Maps
- PyTorch Tensors Explained - Neural Network Programming
- Creating PyTorch Tensors for Deep Learning - Best Options
- Section 4: Tensor Operations
- Flatten, Reshape, and Squeeze Explained - Tensors for Deep Learning
- CNN Flatten Operation Visualized - Tensor Batch Processing
- Tensors for Deep Learning - Broadcasting and Element-wise Operations
- ArgMax and Reduction Ops - Tensors for Deep Learning
- Section 1: Introducing PyTorch
-
PART 2: NEURAL NETWORK TRAINING
-
- Section 1: Data and Data Processing
- Importance of Data in Deep Learning - Fashion MNIST for AI
- Extract, Transform, Load (ETL) - Deep Learning Data Preparation
- PyTorch Datasets and DataLoaders - Training Set Exploration
- Section 2: Neural Networks and PyTorch Design
- Build PyTorch CNN - Object Oriented Neural Networks
- CNN Layers - Deep Neural Network Architecture
- CNN Weights - Learnable Parameters in Neural Networks
- Callable Neural Networks - Linear Layers in Depth
- How to Debug PyTorch Source Code - Debugging Setup
- CNN Forward Method - Deep Learning Implementation
- Forward Propagation Explained - Pass Image to PyTorch Neural Network
- Neural Network Batch Processing - Pass Image Batch to PyTorch CNN
- CNN Output Size Formula - Bonus Neural Network Debugging Session
- Section 3: Training Neural Networks
- CNN Training - Using a Single Batch
- CNN Training Loop - Using Multiple Epochs
- Building a Confusion Matrix - Analyzing Results Part 1
- Stack vs Concat - Deep Learning Tensor Ops
- Using TensorBoard with PyTorch - Analyzing Results Part 2
- Hyperparameter Experimenting - Training Neural Networks
- Section 4: Neural Network Experimentation
- Custom Code - Neural Network Experimentation Code
- Custom Code - Simultaneous Hyperparameter Testing
- Data Loading - Deep Learning Speed Limit Increase
- On the GPU - Training Neural Networks with CUDA
- Data Normalization - Normalize a Dataset
- PyTorch DataLoader Source Code - Debugging Session
- PyTorch Sequential Models - Neural Networks Made Easy
- Batch Norm In PyTorch - Add Normalization To Conv Net Layers
- Section 1: Data and Data Processing
1. PyTorch Explained

2. CUDA Explained
Neural Networks Are Embarrassingly Parallel(易并行)
3. Tensors
3.1. Explained
- number
- scalar
- array
- vector
- 2d-array
- matrix
Computer science: number、scalar、2d-array (multidimensional array or nd-array)
Mathematics: scalar、vector、matrix (tensor or nd-tensor)

Tensors are generalizations.

Tensors and nd-arrays are the same thing!
- A scalar is a 0 dimensional tensor
- A vector is a 1 dimensional tensor
- A metrix is a 2 dimensional tensor
- A nd-array is a n dimensional tensor
3.2. Rank, Axes, Shape
-
Rank:
The rank of tensor refers to the number of dimensions present within the tensor.
It tells us how many indexes are needed to refer to a specific element within the tensor.
-
Axes:
An axis of tensor is a specific dimension of a tensor.
The length of each axis tells us how many indexes are available along each axis.
-
Shape:
The shape of a tensor gives us the length of each axis of the tensor.
-
Reshape:
t = torch.tensor() t.reshape()Reshaping changes the shape but not the underlying data elements.
3.3 CNN Tensor Shape Explained
[Batch, Channels, Height, Width],
eg. [3, 1, 28, 28]
NCHW, NHWC, CHWN
Feature Maps are the output channels created from the convolutions.
3.4 PyTorch Tensors Explained
torch.Tensor has these attributes:
-
torch.dtype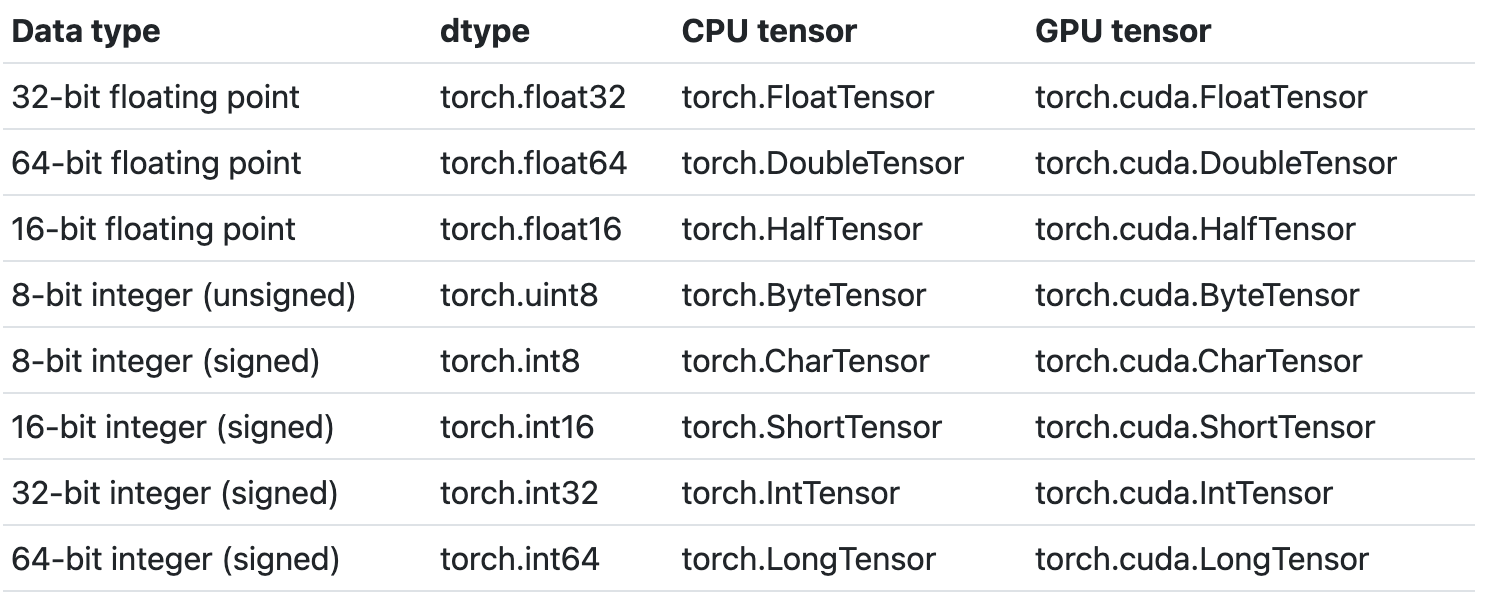
Arithmetic and comparison operations, as of PyTorch version
1.3, can perform mixed-type operations that promote to a commondtype. -
torch.deviceCPU or GPU
One thing to keep in mind about using multiple devices is that tensor operations between tensors must happen between tensors that exists on the same device.
-
torch.layoutThe layout,
stridedin our case, specifies how the tensor is stored in memory. To learn more about stride check here.
Take away from the tensor attributes!
As neural network programmers, we need to be aware of the following:
- Tensors contain data of a uniform type (
dtype). - Tensor computations between tensors depend on the
dtypeand thedevice.
3.5 Creating Tensors Explained
data = np.array([1, 2, 3])
type(data) # numpy.ndarray
t1 = torch.Tensor(data) # tensor([1., 2., 3.])
t2 = torch.tensor(data) # tensor([1, 2, 3], dtype=torch.int32)
t3 = torch.as_tensor(data) # tensor([1, 2, 3], dtype=torch.int32)
t4 = torch.from_numpy(data) # tensor([1, 2, 3], dtype=torch.int32)
torch.eye(2)
'''
tensor([
[1., 0.],
[0., 11.]
])
'''
torch.zeros([2, 2])
torch.ones([2, 2])
torch.rand([2, 2])
torch.Tensor: constructor, default dtype
torch.tensor: factory function, inferred dtype

Given all of these details, these two are the best options:
torch.tensor()torch.as_tensor()
Some things to keep in mind about memory sharing (it works where it can):
- Since
numpy.ndarrayobjects are allocated on the CPU, theas_tensor()function must copy the data from the CPU to the GPU when a GPU is being used. - The memory sharing of
as_tensor()doesn't work with built-in Python data structures like lists. - The
as_tensor()call requires developer knowledge of the sharing feature. This is necessary so we don't inadvertently make an unwanted change in the underlying data without realizing the change impacts multiple objects. - The
as_tensor()performance improvement will be greater if there are a lot of back and forth operations betweennumpy.ndarrayobjects and tensor objects. However, if there is just a single load operation, there shouldn't be much impact from a performance perspective.
3.6 Flatten, Reshape, Squeeze
t = torch.tensor([
[1, 1, 1, 1],
[2, 2, 2, 2],
[3, 3, 3, 3]
], dtype=torch.float32)
t.size() # torch.Size([3, 4])
t.shape() # torch.Size([3, 4])
len(t.shape) # 2
torch.tensor(t.shape).prod() # tensor(12)
t.numel() # 12
-
Squeezing and Unsqueezing:
- Squeezing a tensor removes the dimensions or axes that have a length of one.
- Unsqueezing a tensor adds a dimension with a length of one.
t.reshape([1, 12]) t.reshape([1, 12]).shape # tensor([[1., 1., 1., 1., 2., 2., 2., 2., 3., 3., 3., 3.]]) # torch.Size([1, 12]) t.reshape([1,12]).squeeze() t.reshape([1,12]).squeeze().shape # tensor([1., 1., 1., 1., 2., 2., 2., 2., 3., 3., 3., 3.]) # torch.Size([12]) t.reshape([1,12]).squeeze().unsqueeze(dim=0) t.reshape([1,12]).squeeze().unsqueeze(dim=0).shape # tensor([[1., 1., 1., 1., 2., 2., 2., 2., 3., 3., 3., 3.]]) # torch.Size([1, 12]) -
Flatten:
Flattening a tensor means to remove all of the dimensions except for one.
t = torch.ones(4, 3) ''' tensor([[1., 1., 1.], [1., 1., 1.], [1., 1., 1.], [1., 1., 1.]]) ''' flatten(t) # tensor([1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.]) -
Concatenating:
t1 = torch.tensor([ [1,2], [3,4] ]) t2 = torch.tensor([ [5,6], [7,8] ]) torch.cat((t1, t2), dim=0) ''' tensor([[1, 2], [3, 4], [5, 6], [7, 8]]) ''' torch.cat((t1, t2), dim=1) ''' tensor([[1, 2, 5, 6], [3, 4, 7, 8]]) '''
3.7 Flatten of CNN
> t.reshape(1,-1)[0] # Thank you Mick!
tensor([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3])
> t.reshape(-1) # Thank you Aamir!
tensor([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3])
> t.view(t.numel()) # Thank you Ulm!
tensor([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3])
> t.flatten() # Thank you PyTorch!
tensor([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3])
> t.flatten(start_dim=1).shape
torch.Size([3, 16])
> t.flatten(start_dim=1)
tensor(
[
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2],
[3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3]
]
)
3.8 Broadcasting and Element
https://deeplizard.com/learn/video/QscEWm0QTRY
3.9 ArgMax and Reduction Tensor Ops
A reduction operation on a tensor is an operation that reduces the number of elements contained within the tensor.
t = torch.tensor([])
t.sum()
t.numel()
t.prod()
t.mean()
t.std()
t = torch.tensor([
[1,1,1,1],
[2,2,2,2],
[3,3,3,3]
], dtype=torch.float32)
> t.sum(dim=0)
tensor([6., 6., 6., 6.])
> t.sum(dim=1)
tensor([ 4., 8., 12.])
Argmax returns the index location of the maximum value inside a tensor.
t = torch.tensor([
[1,0,0,2],
[0,3,3,0],
[4,0,0,5]
], dtype=torch.float32)
> t.max()
tensor(5.)
> t.argmax()
tensor(11)
> t.flatten()
tensor([1., 0., 0., 2., 0., 3., 3., 0., 4., 0., 0., 5.])
> t.max(dim=0)
(tensor([4., 3., 3., 5.]), tensor([2, 1, 1, 2]))
> t.argmax(dim=0)
tensor([2, 1, 1, 2])
> t.max(dim=1)
(tensor([2., 3., 5.]), tensor([3, 1, 3]))
> t.argmax(dim=1)
tensor([3, 1, 3])
> t = torch.tensor([
[1,2,3],
[4,5,6],
[7,8,9]
], dtype=torch.float32)
> t.mean()
tensor(5.)
> t.mean().item()
5.0
> t.mean(dim=0).tolist()
[4.0, 5.0, 6.0]
> t.mean(dim=0).numpy()
array([4., 5., 6.], dtype=float32)
4. Data and Data Processing
4步:
- 准备数据
- 构建模型
- 训练模型
- 评估模型
ETL流程:
- E:Extract data from a data source.(提取数据)
- T:Transform data into a desirable format.(转换数据)
- L:Load data into a suitable structure.(加载数据)
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
#from plotcm import plot_confusion_matrix
import pdb
torch.set_printoptions(linewidth=120)

train_set = torchvision.datasets.FashionMNIST(
root='./data'
,train=True
,download=True
,transform=transforms.Compose([
transforms.ToTensor()
])
)
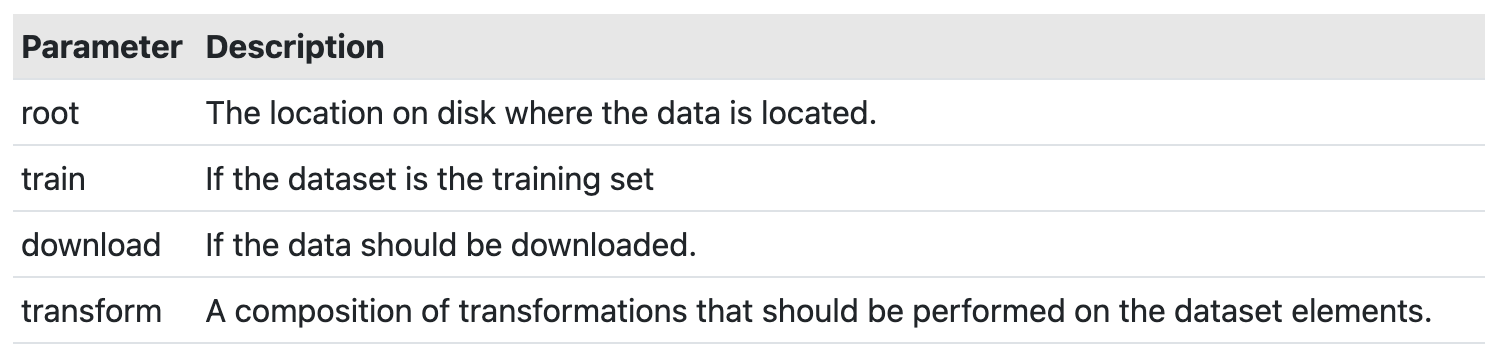
train_loader = torch.utils.data.DataLoader(train_set
,batch_size=1000
,shuffle=True
)
import torch
import torchvision
import torchvision.transforms as transforms
train_set = torchvision.datasets.FashionMNIST(
root='./data/FashionMNIST',
train=True,
download=True,
transform=transforms.Compose([
transforms.ToTensor()
])
)
train_loader = torch.utils.data.DataLoader(
train_set, batch_size=100
)
batch = next(iter(train_loader1))
images, labels = batch
print(images.shape, labels.shape)
grid = torchvision.utils.make_grid(images, nrow=10)
plt.figure(figsize=(15, 15))
plt.imshow(np.transpose(grid, (1, 2, 0)))
print("labels:", labels)

5. Torch CNN
import torch.nn as nn
class Networf(nn.Module):
def __init__(self):
super(Network, self).__int__()
self.conv1 = nn.Conv2d(in_channels=1, out_chennels=6, kernel_size=5)
self.conv2 = nn.Conv2d(in_channels=6, out_chennels=12, kernel_size=5)
self.fc1 = nn.Linear(in_features=12*4*4, out_features=120)
self.fc2 = nn.Linear(in_features=120, out_features=60)
self.out = nn.Linear(in_features=60, out_features=10)
def forward(self, t):
return t;
'''
def __repr__(self):
return 'network'
'''
network = Network()
network

network.conv1
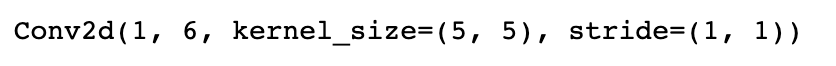
nerwork.conv1.weight

network.conv1.weight.shape
# torch.Size([6, 1, 5, 5])
for param in networ.parameters():
print(param.shape)

for name, param in network.named_parameters():
print(name, '\t\t', param.shape)

6. Training Torch CNN
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
torch.set_printoptions(linewidth=120)
# torch.set_grad_enabledn(True)
print(torch.__version__)
print(torchvision.__version__)
def get_num_correct(preds, labels):
return preds.argmax(dim=1).eq(labels).sum().item()
class Network(nn.Module):
def __init__(self):
super(Network, self).__init__()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5)
self.conv2 = nn.Conv2d(in_channels=6, out_channels=12, kernel_size=5)
self.fc1 = nn.Linear(in_features=12*4*4, out_features=120)
self.fc2 = nn.Linear(in_features=120, out_features=60)
self.out = nn.Linear(in_features=60, out_features=10)
def forward(self, t):
t = F.relu(self.conv1(t))
t = F.max_pool2d(t, kernel_size=2, stride=2)
t = F.relu(self.conv2(t))
t = F.max_pool2d(t, kernel_size=2, stride=2)
t = F.relu(self.fc1(t.reshape(-1, 12*4*4)))
t = F.relu(self.fc2(t))
t = self.out(t)
return t
network = Network()
optimizer = optim.Adam(network.parameters(), lr=0.01)
for epoch in range(5):
total_loss = 0
total_correct = 0
for batch in train_loader:
images, labels = batch
preds = network(images)
loss = F.cross_entropy(preds, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
total_correct += get_num_correct(preds, labels)
print("epoch:", epoch, "total_correct:", total_correct, "loss:", total_loss)
print(total_correct / len(train_set))
7. Confusion Matrix
# @torch.no_grad()
def get_all_preds(model, loader):
all_preds = torch.tensor([])
for batch in loader:
images, labels = batch
preds = model(images)
all_preds = torch.cat((all_preds, preds), dim=0)
return all_preds
prediction_loader = torch.utils.data.DataLoader(train_set, batch_size=10000)
train_preds = get_all_preds(network, prediction_loader)
print(train_preds.shape)
print(train_preds.requires_grad) # True 说明用到了梯度跟踪
print(train_preds.grad) # 没有值,因为只有在反向传播时才会计算梯度
print(train_preds.grad_fn)
'''
# 局部关闭梯度跟踪
with torch.no_grad():
prediction_loader = torch.utils.data.DataLoader(train_set, batch_size=10000)
train_preds = get_all_preds(network, prediction_loader)
'''
preds_correct = get_num_correct(train_preds, train_set.targets)
print("total correct:", preds_correct)
print("accuracy:", preds_correct / len(train_set))
stacked = torch.stack((train_set.targets, train_preds.argmax(dim=1)), dim=1)
cmt = torch.zeros(10, 10, dtype=torch.int64)
for p in stacked:
tl, pl = p.tolist()
cmt[tl, pl] = cmt[tl, pl] + 1
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
from resources.plotcm import plot_confusion_matrix
cm = confusion_matrix(train_set.targets, train_preds.argmax(dim=1))
names = ('T-shirt.top', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot')
plt.figure(figsize=(10, 10))
plot_confusion_matrix(cm ,names, normalize=True)
import itertools
import numpy as np
import matplotlib.pyplot as plt
def plot_confusion_matrix(cm, classes, normalize=False, title='Confusion matrix', cmap=plt.cm.Blues):
"""
This function prints and plots the confusion matrix.
Normalizetion can be applied by setting 'normalize=True.
"""
if normalize:
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
print("normalized confusion matrix")
else:
print('Confusion matrix, without normalization')
print(cm)
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment='center',
color='white' if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
8. Stack vs Concat
Concatenate:拼接
Stack:叠加
Concatenating joins a sequence of tensors along an existing axis.
Stacking joins a sequence of tensors along a new axis.
- PyTorch
import torch
t1 = torch.tensor([1, 1, 1])
t2 = torch.tensor([2, 2, 2])
t3 = torch.tensor([3, 3, 3])
torch.cat((t1, t2, t3), dim=0)
# tensor([1, 1, 1, 2, 2, 2, 3, 3, 3])
torch.stack((t1, t2, t3), dim=0)
'''
tensor([[1, 1, 1],
[2, 2, 2],
[3, 3, 3]])
'''
torch.cat(
(
t1.unsqueeze(0),
t2.unsqueeze(0),
t3.unsqueeze(0)
),
dim=0
)
'''
tensor([[1, 1, 1],
[2, 2, 2],
[3, 3, 3]])
'''
torch.stack((t1, t2, t3), dim=1)
'''
tensor([[1, 2, 3],
[1, 2, 3],
[1, 2, 3]])
'''
torch.cat(
(
t1.unsqueeze(1),
t2.unsqueeze(1),
t3.unsqueeze(1)
),
dim=1
)
'''
tensor([[1, 2, 3],
[1, 2, 3],
[1, 2, 3]])
'''
- Tensorflow
import tensorflow as tf
t1 = tf.constant([1, 1, 1])
t2 = tf.constant([2, 2, 2])
t3 = tf.constant([3, 3, 3])
tf.concat((t1, t2, t3), axis=0)
# <tf.Tensor: shape=(9,), dtype=int32, numpy=array([1, 1, 1, 2, 2, 2, 3, 3, 3], dtype=int32)>
tf.stack((t1, t2, t3), axis=0)
'''
<tf.Tensor: shape=(3, 3), dtype=int32, numpy=
array([[1, 1, 1],
[2, 2, 2],
[3, 3, 3]], dtype=int32)>
'''
tf.concat(
(
tf.expand_dims(t1, 0),
tf.expand_dims(t2, 0),
tf.expand_dims(t3, 0)
),
axis=0
)
'''
<tf.Tensor: shape=(3, 3), dtype=int32, numpy=
array([[1, 1, 1],
[2, 2, 2],
[3, 3, 3]], dtype=int32)>
'''
tf.stack((t1, t2, t3), axis=1)
'''
<tf.Tensor: shape=(3, 3), dtype=int32, numpy=
array([[1, 2, 3],
[1, 2, 3],
[1, 2, 3]], dtype=int32)>
'''
tf.concat(
(
tf.expand_dims(t1, 1),
tf.expand_dims(t2, 1),
tf.expand_dims(t3, 1)
),
axis=1
)
'''
<tf.Tensor: shape=(3, 3), dtype=int32, numpy=
array([[1, 2, 3],
[1, 2, 3],
[1, 2, 3]], dtype=int32)>
'''
- Numpy
import numpy as np
t1 = np.array([1, 1, 1])
t2 = np.array([2, 2, 2])
t3 = np.array([3, 3, 3])
np.concatenate((t1, t2, t3), axis=0)
# array([1, 1, 1, 2, 2, 2, 3, 3, 3])
np.stack((t1, t2, t3), axis=0)
'''
array([[1, 1, 1],
[2, 2, 2],
[3, 3, 3]])
'''
np.concatenate(
(
np.expand_dims(t1, 0),
np.expand_dims(t2, 0),
np.expand_dims(t3, 0),
),
axis=0
)
'''
array([[1, 1, 1],
[2, 2, 2],
[3, 3, 3]])
'''
np.stack((t1, t2, t3), axis=1)
'''
array([[1, 2, 3],
[1, 2, 3],
[1, 2, 3]])
'''
np.concatenate(
(
np.expand_dims(t1, 1),
np.expand_dims(t2, 1),
np.expand_dims(t3, 1),
),
axis=1
)
'''
array([[1, 2, 3],
[1, 2, 3],
[1, 2, 3]])
'''
9. TensorBoard
from itertools import product
'''
batch_size_list = [100, 1000, 10000]
lr_list = [.01, .001, .0001, .00001]
'''
parameters = dict(
lr = [.01, .001],
batch_size = [10, 100, 1000],
shuffle = [True, False]
)
param_values = [v for v in parameters.values()]
print(param_values)
'''
for batch_size in batch_size_list:
for lr in lr_list:
'''
for lr, batch_size, shuffle in product(*param_values):
coomment = f' batch_size={batch_size} lr={lr} shuffle={shuffle}'
network = Network()
train_loader = torch.utils.data.DataLoader(train_set, batch_size=batch_size, shuffle=shuffle)
optimizer = optim.Adam(network.parameters(), lr=lr)
images, labels = next(iter(train_loader))
grid = torchvision.utils.make_grid(images)
tb = SummaryWriter(comment=coomment)
tb.add_image('images', grid)
tb.add_graph(network, images)
for epoch in range(10):
total_loss = 0
total_correct = 0
for batch in train_loader:
images, labels = batch
preds = network(images)
loss = F.cross_entropy(preds, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item() * batch_size
total_correct += get_num_correct(preds, labels)
tb.add_scalar('Loss', total_loss, epoch)
tb.add_scalar('Number Correct', total_correct, epoch)
tb.add_scalar('Accuracy', total_correct / len(train_set), epoch)
'''
tb.add_histogram('conv1.bias', network.conv1.bias, epoch)
tb.add_histogram('conv2.weight', network.conv1.weight, epoch)
tb.add_histogram('conv3.weight.grad', network.conv1.weight.grad, epoch)
'''
for name, weight in network.named_parameters():
tb.add_histogram(name, weight, epoch)
tb.add_histogram(f'{name}.grad', weight.grad, epoch)
print("epoch:", epoch, "total_loss:", total_loss, "total_correct:", total_correct)
tb.close()
tensorboard --logdir=runs
10. Simultaneous Hyperparameter Testing(GPU and CPU)
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import torchvision
import torchvision.transforms as transforms
from torchvision.datasets import FashionMNIST
import time
import json
import pandas as pd
from IPython.display import clear_output, display
from collections import OrderedDict
from collections import namedtuple
from itertools import product
torch.set_printoptions(linewidth=120)
torch.set_grad_enabled(True)
print(torch.__version__)
print(torchvision.__version__)
- RunBuilder:
class RunBuilder():
@staticmethod
def get_runs(params):
Run = namedtuple('Run', params.keys())
runs = []
for v in product(*params.values()):
runs.append(Run(*v))
return runs
- RunManager:
class RunManager():
def __init__(self):
self.epoch_count = 0
self.epoch_loss = 0
self.epoch_num_correct = 0
self.epoch_start_time = None
self.run_params = None
self.run_count = 0
self.run_data = []
self.run_start_time = None
self.network = None
self.loader = None
self.tb = None
def begin_run(self, run, network, loader):
self.run_start_time = time.time()
self.run_params = run
self.run_count += 1
self.network = network
self.loader = loader
self.tb = SummaryWriter(comment=f'-{run}')
images, labels = next(iter(self.loader))
grid = torchvision.utils.make_grid(images)
self.tb.add_image('images', grid)
self.tb.add_graph(self.network, images.to(getattr(run, 'device', 'cpu')))
def end_run(self):
self.tb.close()
self.epoch_count = 0
def begin_epoch(self):
self.epoch_start_time = time.time()
self.epoch_count += 1
self.epoch_loss = 0
self.epoch_num_correct = 0
def end_epoch(self):
epoch_duration = time.time() - self.epoch_start_time
run_duration = time.time() - self.run_start_time
loss = self.epoch_loss / len(self.loader.dataset)
accuracy = self.epoch_num_correct / len(self.loader.dataset)
self.tb.add_scalar('Loss', loss, self.epoch_count)
self.tb.add_scalar('Accuracy', accuracy, self.epoch_count)
for name, param in self.network.named_parameters():
self.tb.add_histogram(name, param, self.epoch_count)
self.tb.add_histogram(f'{name}.grad', param.grad, self.epoch_count)
results = OrderedDict()
results["run"] = self.run_count
results["epoch"] = self.epoch_count
results["loss"] = loss
results["accuracy"] = accuracy
results["epoch duration"] = epoch_duration
results["run duration"] = run_duration
for k, v in self.run_params._asdict().items(): results[k] = v
self.run_data.append(results)
df = pd.DataFrame.from_dict(self.run_data, orient='columns')
clear_output(wait=True)
display(df)
def track_loss(self, loss):
self.epoch_loss += loss.item() * self.loader.batch_size
def track_num_correct(self, preds, labels):
self.epoch_num_correct += self._get_num_correct(preds, labels)
@torch.no_grad()
def _get_num_correct(self, preds, labels):
return preds.argmax(dim=1).eq(labels).sum().item()
def save(self, fileName):
pd.DataFrame.from_dict(
self.run_data,
orient='columns',
).to_csv(f'{fileName}.csv')
with open(f'{fileName}.json', 'w', encoding='utf-8') as f:
json.dump(self.run_data, f, ensure_ascii=False, indent=4)
- Data
train_set = FashionMNIST(
root='./data/',
train=True,
download=True,
transform=transforms.Compose([
transforms.ToTensor(),
])
)
loader = DataLoader(train_set, batch_size=len(train_set), num_workers=1)
data = next(iter(loader))
mean = data[0].mean()
std = data[0].std()
print(mean, std)
# plt.hist(data[0].flatten())
# plt.axvline(mean)
# plt.show()
train_set_normal = FashionMNIST(
root='./data/FashionMnist',
train=True,
download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean, std)
])
)
- Training:
trainsets = {
'not_normal': train_set,
'normal': train_set_normal
}
params = dict(
lr = [.01],
batch_size = [100, 1000],
shuffle = [True],
num_works = [0, 1],
device = ['cuda', 'cpu'],
trainset = ['not_normal', 'normal']
)
m = RunManager()
for run in RunBuilder.get_runs(params):
network = Network()
train_loader = DataLoader(trainsets[run.trainset], batch_size=run.batch_size, shuffle=run.shuffle, num_workers=run.num_workers)
optimizer = optim.Adam(network.parameters(), lr=run.lr)
m.begin_run(run, network, train_loader)
for epoch in range(5):
m.begin_epoch()
for batch in train_loader:
# images, labels = batch
images = batch[0].to(device)
labels = batch[1].to(device)
preds = network(images)
loss = F.cross_entropy(preds, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
m.track_loss(loss)
m.track_num_correct(preds, labels)
m.end_epoch()
m.end_run()
m.save('./Result/results')
11. Sequential Module
torch.manual_seed(50)
sequential1 = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(in_channels=6, out_channels=12, kernel_size=5),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Flatten(start_dim=1),
nn.Linear(in_features=12*4*4, out_features=120),
nn.ReLU(),
nn.Linear(in_features=120, out_features=60),
nn.ReLU(),
nn.Linear(in_features=60, out_features=10)
)
torch.manual_seed(50)
layers = OrderedDict([
('conv1', nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5)),
('relu1', nn.ReLU()),
('maxpool1', nn.MaxPool2d(kernel_size=2, stride=2)),
('conv2', nn.Conv2d(in_channels=6, out_channels=12, kernel_size=5)),
('relu2', nn.ReLU()),
('maxpool2', nn.MaxPool2d(kernel_size=2, stride=2)),
('flatten', nn.Flatten(start_dim=1)),
('fc1', nn.Linear(in_features=12*4*4, out_features=120)),
('relu3', nn.ReLU()),
('fc2', nn.Linear(in_features=120, out_features=60)),
('relu4', nn.ReLU()),
('output', nn.Linear(in_features=60, out_features=10))
])
sequential2 = nn.Sequential(layers)
torch.manual_seed(50)
sequential3 = nn.Sequential()
sequential3.add_module('conv1', nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5))
sequential3.add_module('relu1', nn.ReLU()),
sequential3.add_module('maxpool1', nn.MaxPool2d(kernel_size=2, stride=2)),
sequential3.add_module('conv2', nn.Conv2d(in_channels=6, out_channels=12, kernel_size=5)),
sequential3.add_module('relu2', nn.ReLU()),
sequential3.add_module('maxpool2', nn.MaxPool2d(kernel_size=2, stride=2)),
sequential3.add_module('flatten', nn.Flatten(start_dim=1)),
sequential3.add_module('fc1', nn.Linear(in_features=12*4*4, out_features=120)),
sequential3.add_module('relu3', nn.ReLU()),
sequential3.add_module('fc2', nn.Linear(in_features=120, out_features=60)),
sequential3.add_module('relu4', nn.ReLU()),
sequential3.add_module('output', nn.Linear(in_features=60, out_features=10))
12. BatchNorm
torch.manual_seed(50)
network2 = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.BatchNorm2d(6),
nn.Conv2d(in_channels=6, out_channels=12, kernel_size=5),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Flatten(start_dim=1),
nn.Linear(in_features=12*4*4, out_features=120),
nn.ReLU(),
nn.BatchNorm1d(120),
nn.Linear(in_features=120, out_features=60),
nn.ReLU(),
nn.Linear(in_features=60, out_features=10)
)
13. Reset Weight
- Individual layer
torch.manual_seed(50)
layer = nn.Linear(2, 1)
...
torch.manual_seed(50)
layer.reset_parameters()
- Individual layer inside a network
torch.manual_seed(50)
network = nn.Sequential(nn.Linear(2, 1))
...
torch.manual_seed(50)
network[0].reset_parameters()
-
Subset of layers inside a network
-
All weights layer by layer(不推荐)
network = nn.Sequential(nn.Linear(2, 1)) ... torch.manual_seed(50) for module in network.children(): module.reset_parameters() -
All weights using snapshot
orch.manual_seed(50) network = nn.Sequential(nn.Linear(2, 1)) torch.save(network.state_dict(), "./Module/network.pt") ... network.load_state_dict(torch.load("./Module/network.pt")) -
All weights using re-initialization
torch.manual_seed(50) network = nn.Sequential(nn.Linear(2, 1)) ... torch.manual_seed(50) network = nn.Sequential(nn.Linear(2, 1))
-
14. Training Multiple Networks
要重置网络
class NetworkFactory():
@staticmethod
def get_network(name):
if name == 'network':
torch.manual_seed(50)
return nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(in_channels=6, out_channels=12, kernel_size=5),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Flatten(start_dim=1),
nn.Linear(in_features=12*4*4, out_features=120),
nn.ReLU(),
nn.Linear(in_features=120, out_features=60),
nn.ReLU(),
nn.Linear(in_features=60, out_features=10)
)
else:
return None
network = NetworkFactory.get_network(run.network).to(device)
15. Others
- 在MNIST数据集中,用
Max_Pool层会导致精度下降,原因是MNIST数据集时经过处理的数据集,已经很简单了,使用Max_Pool层会丢失很多关键信息。 - It does not matter how slow you go as long as you do not stop!
16. 自定义Dataset
以Dogs-vs- Cats数据集为例
import torch
from torch.utils.data import Dataset, DataLoader
import torchvision.transforms as transforms
import os
from PIL import Image
from tqdm import tqdm
class MyDataset(Dataset):
def __init__(self, root, transform=None):
self.images = []
self.labels = []
self.transform = transform
for filename in tqdm(os.listdir(root)):
image = root + filename
if filename.split('.')[0] == 'cat':
self.labels.append(0)
self.images.append(image)
elif filename.split('.')[0] == 'dog':
self.labels.append(1)
self.images.append(image)
self.labels = torch.tensor(self.labels)
def __getitem__(self, index):
img_p = self.images[index]
label = self.labels[index]
img = Image.open(img_p).convert('RGB')
if self.transform is not None:
img = self.transform(img)
return img, label
def __len__(self):
return len(self.images)
if __name__ == "__main__":
train_set = MyDataset(
root='./data/dogs-vs-cats/train/',
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Resize((224, 224))
])
)
train_loader = DataLoader(train_set, batch_size=1000)
images, labels = next(iter(train_loader))
print(images[0][0][0][0])
print(images.shape, labels.shape)
print(labels[:10])
2022.10.21 更新

 浙公网安备 33010602011771号
浙公网安备 33010602011771号