在Yarn集群上跑spark wordcount任务
- 准备的测试数据文件hello.txt
hello scala
hello world
nihao hello
i am scala
this is spark demo
gan jiu wan le
- 将文件上传到hdfs中
#创建hdfs测试目录
hdfs dfs -mkdir /user/spark/input/
#上传本地文件hello.txt到hdfs
hdfs dfs -put ./hello.txt /user/spark/input/
- 代码(改为读取hdfs上的数据,并写入hdfs)
package org.example
import org.apache.spark.{SparkConf, SparkContext}
/**
* spark-submit --master yarn --class org.example.SparkWordCountYarn /tmp/test/sparkwordcount2-1.0-SNAPSHOT.jar hdfs://hadoop1:8020/user/spark/input/hello.txt hdfs://hadoop1:8020/user/spark/output/helloOutput
*/
object SparkWordCountYarn {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName("WordCount")
.setMaster("yarn")
val srcFile = args(0)
val outPutFile = args(1)
val sc = new SparkContext(conf)
val data = sc.textFile(srcFile)
data.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_+_)
.saveAsTextFile(outPutFile)
}
}
- 执行提交spark人物命令
spark-submit --master yarn --class org.example.SparkWordCountYarn /tmp/test/sparkwordcount2-1.0-SNAPSHOT.jar hdfs://hadoop1:8020/user/spark/input/hello.txt hdfs://hadoop1:8020/user/spark/output/helloOutput
- 执行结果
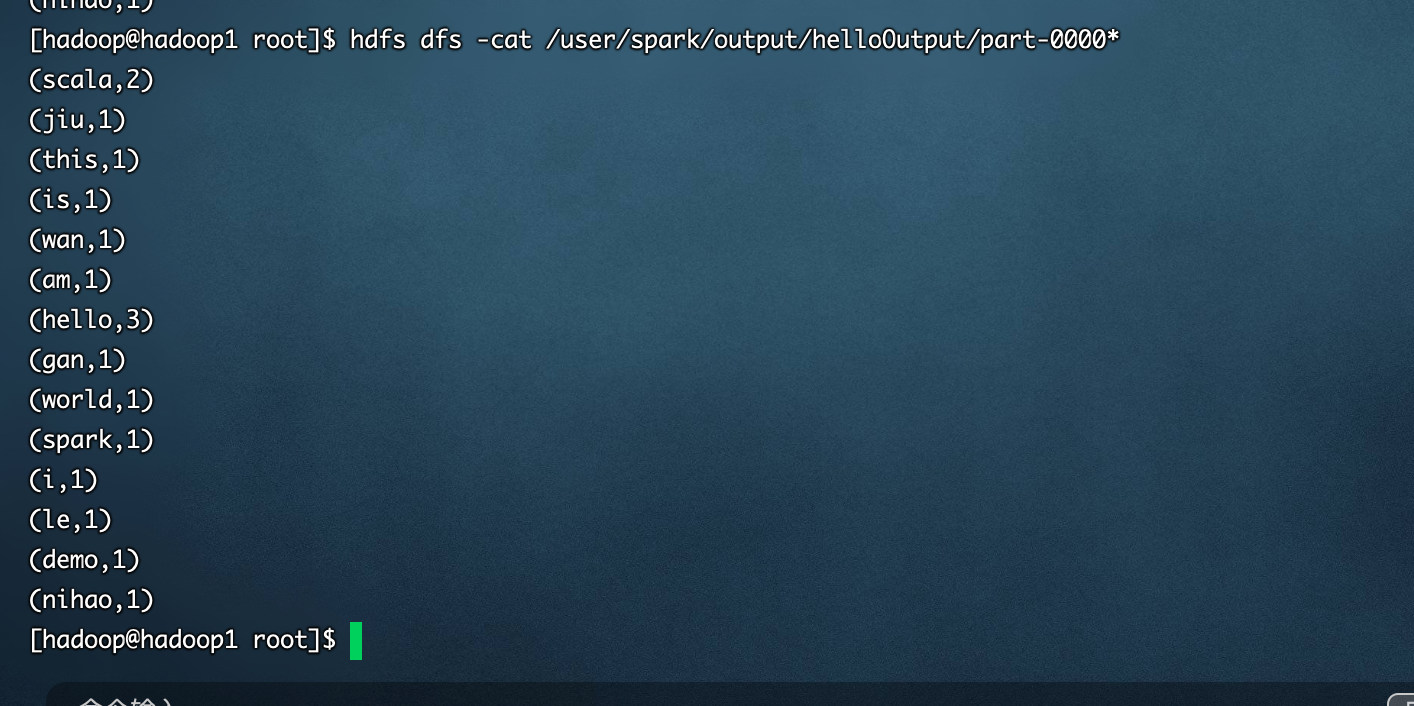
本文作者:明月照江江
本文链接:https://www.cnblogs.com/gradyblog/p/15767793.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步