html不规则需要格式化小技巧
当python爬虫遇到html不规则怎么办?
比如爬取微博个人信息,在这给大家讲一个小技巧
https://weibo.com/a1937000700?is_hot=1
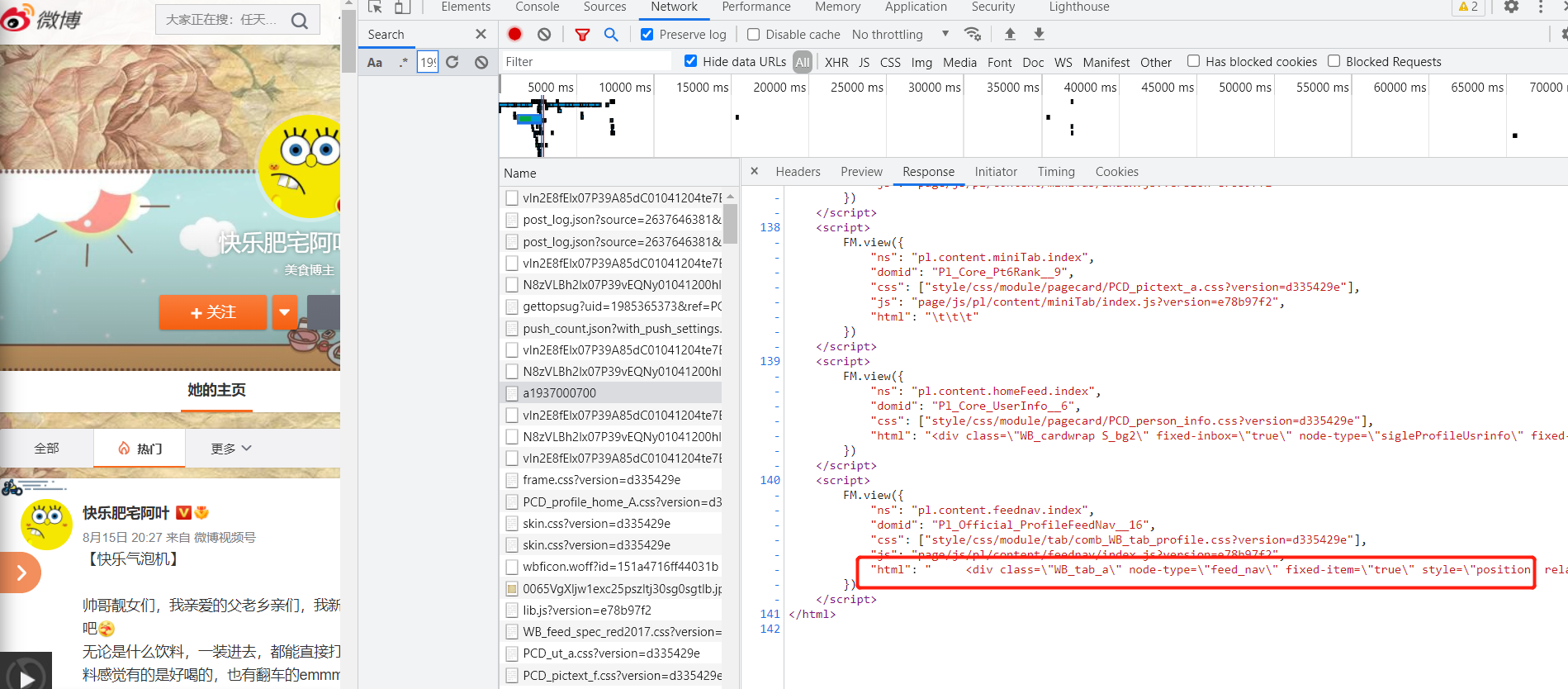
需要解析html提取个人信息
第一步、在pycharm 新建HTML file
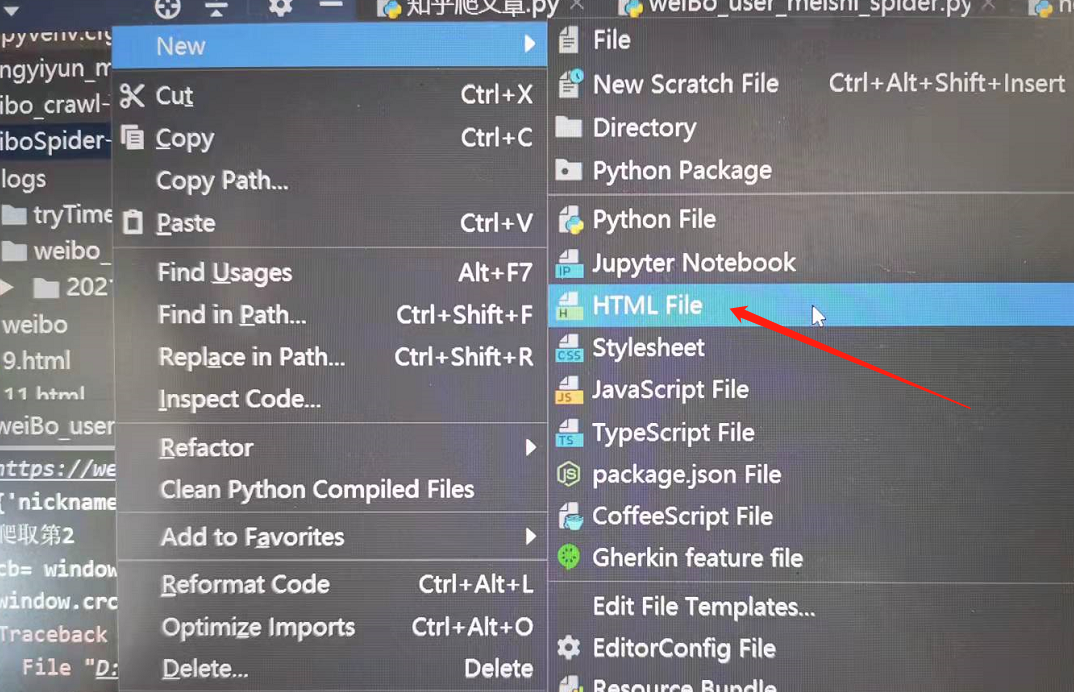
第二步、复制html中的元素到新建HTML file并打开


第三步、按F12 HTML标签结构一目了然

当python爬虫遇到html不规则怎么办?
比如爬取微博个人信息,在这给大家讲一个小技巧
https://weibo.com/a1937000700?is_hot=1
需要解析html提取个人信息

 浙公网安备 33010602011771号
浙公网安备 33010602011771号