Python爬虫爬取知乎文章内容(解决最新js反爬2021.9 x-zse-96 2.0版本加密破解分析)
有个需求爬取知乎文章,正好记录下爬取过程以及出现问题并解决方法
我是在没有登录的情况下爬取文章的
本文仅供研究与学习使用
知乎现今的 x-zse 参数的加密方法已升级成了:x-zse-96 2.0版本。
来看这篇帖子的应该都知道,这个参数动态唯一,没有就拿不到api数据。
查阅了网上有关文章,仅有x-zse-86 2.0版本的解密方法,现今已不适用,加上之前写的文章中有提及该解密方法,所以写一篇最新的,供大家研究与学习。
1.F12进入源码分析

2.响应json内容

3.断点调试

4.md5参数加密
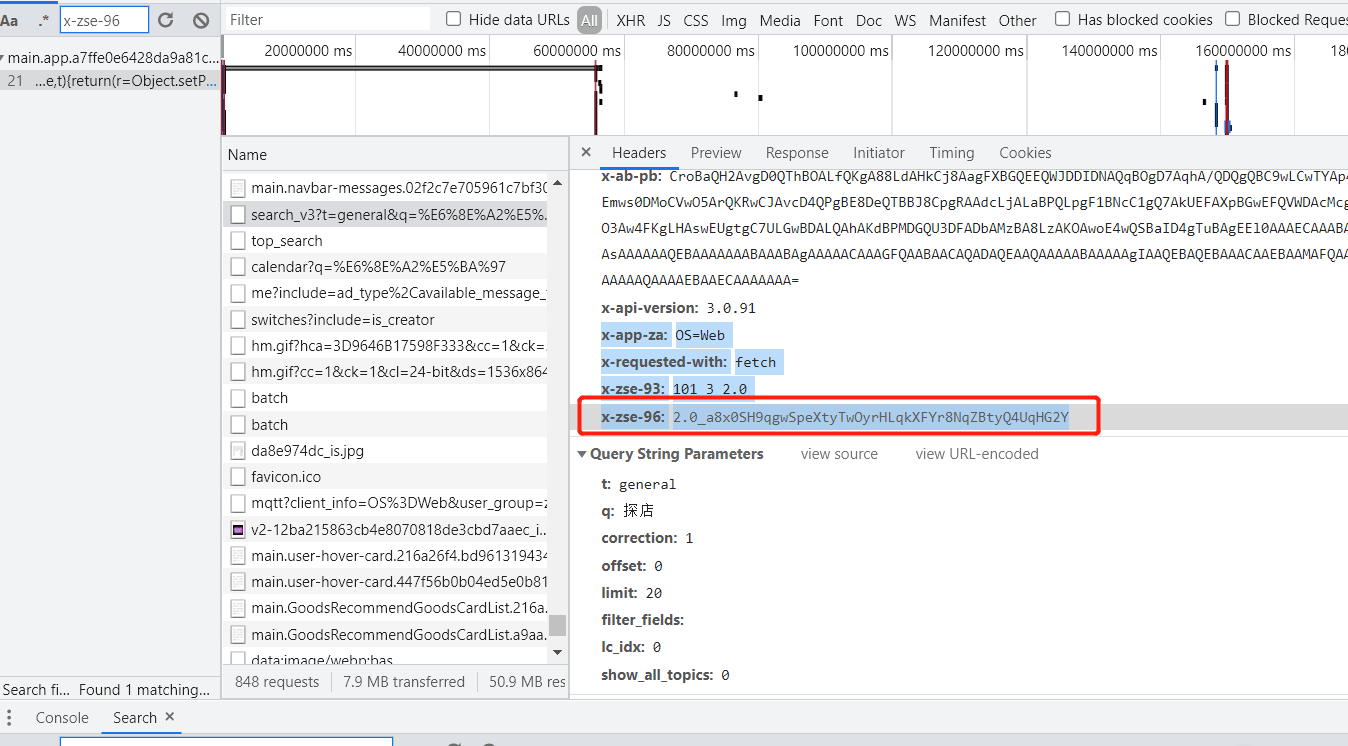
不难发现明文是 headers 里的 x-zse-93 + url + cookie.d_c0
知乎貌似一直都是采用 md5 加密方式进行数据加密的,直接上去测就好了。
在终端输入:r.default(d)
运行结果:

如果您觉得阅读本文对您有帮助,请点一下“推荐”按钮,您的“推荐”将是我最大的写作动力!欢迎各位转载!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异
· 三行代码完成国际化适配,妙~啊~
2020-09-16 若遇到APP无法抓包怎么办,可以通过安装Drony 进行转发抓包