
机器学习
一、机器学习的概念:个程序被认为能从经验E中学习,解决任务T,达到性能度量值P,当且仅当,有了经验E后,经过P评判,程序在处理T时的性能有所提升
监督学习(supervised ):(又分为回归问题和分类问题)监督学习。其基本思想是,我们数据集中的每个样本都有相应的“正确答案”。再根据这些样本作出预测,就像房子和肿瘤的例子中做的那样。我们还介绍了回归问题,即通过回归来推出一个连续的输出,之后我们介绍了分类问题,其目标是推出一组离散的结果。
无监督学习:不同于监督学习的数据的样子,即无监督学习中没有任何的标签或者是有相同的标签。所以我们已知数据集,却不知如何处理,也未告知每个数据点是什么,就是一个数据集。你能从数据中找到某种结构吗?针对数据集,无监督学习就能判断出数据有两个不同的聚集簇。这是一个,那是另一个,二者不同。是的,无监督学习算法可能会把这些数据分成两个不同的簇。所以叫做聚类算法。
二、单变量线性回归(Linear Regression with One Variable)
2.1 模型表示
我将在整个课程中用小写的来表示训练样本的数目。
以之前的房屋交易问题为例,假使我们回归问题的训练集(Training Set)如下表所示:
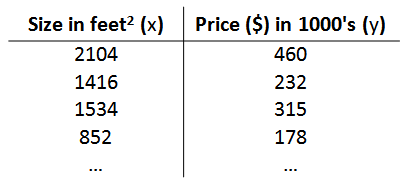
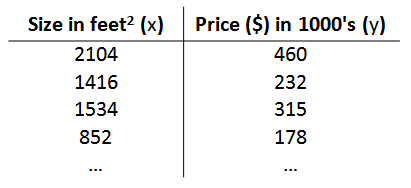
我们将要用来描述这个回归问题的标记如下:
m代表训练集中实例的数量
x代表特征/输入变量
y代表目标变量/输出变量
(x,y)代表训练集中的实例
(xi,yi)代表第 个观察实例
h代表学习算法的解决方案或函数也称为假设(hypothesis)
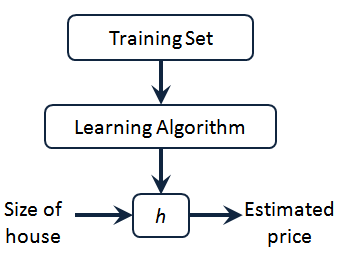
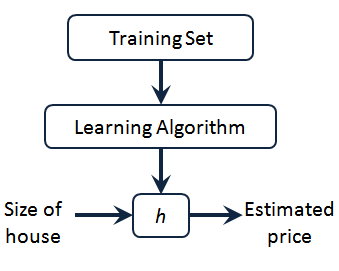
这就是一个监督学习算法的工作方式,我们可以看到这里有我们的训练集里房屋价格 我们把它喂给我们的学习算法,学习算法的工作了,然后输出一个函数,通常表示为小写 h 表示。 代表hypothesis(假设),表示一个函数,输入是房屋尺寸大小,就像你朋友想出售的房屋,因此 h根据输入的 x值来得出y 值, 值对应房子的价格 因此,h 是一个从x 到 y的函数映射。
我将选择最初的使用规则代表hypothesis,因而,要解决房价预测问题,我们实际上是要将训练集“喂”给我们的学习算法,进而学习得到一个假设,然后将我们要预测的房屋的尺寸作为输入变量输入给,预测出该房屋的交易价格作为输出变量输出为结果。那么,对于我们的房价预测问题,我们该如何表达 ?
一种可能的表达方式为:,因为只含有一个特征/输入变量,因此这样的问题叫作单变量线性回归问题。
2 、单变量线性回归(Linear Regression with One Variable)
2.1 模型表示
以之前的房屋交易问题为例,假使我们回归问题的训练集(Training Set)如下表所示:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号