
Redis十大数据类型及命令详解
Redis数据类型
1、redis字符串(String)
- string是redis最基本的类型,一个key对应一个value
- string类型是二进制安全的,意思是redis的string可以包含任何数据。例如说是jpg图片或者序列化对象
- 一个redis中字符串value最多可以是512M
- 应用场景:
- 缓存:存储用户会话、页面内容(如
SET user:1 "{name: 'Alice', age: 30}")。- 计数器:统计访问量(
INCR page_views)。- 分布式锁:通过
SET key value NX EX 10实现简单的锁机制。- 限流:结合
INCR和EXPIRE控制接口调用频率。
2、redis列表(List)
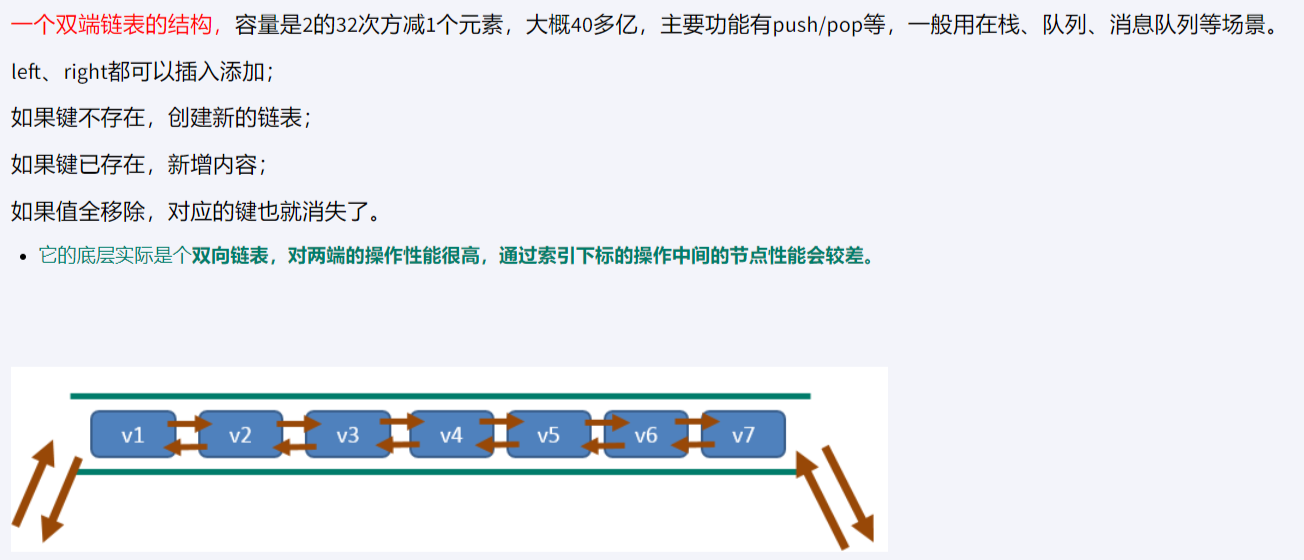
- 有序:列表中的元素是有序的,这意味着可以按照插入的顺序来获取元素。
- 可重复:与集合(Set)不同,列表允许元素重复。
- 灵活:列表可以在头部(左边)或尾部(右边)添加或删除元素。
- 底层是一个双向链表,最多可以包含2^32-1个元素(每个列表超过40亿个元素)
- 应用场景:
- 消息队列:实现生产者-消费者模型(
LPUSH tasks "task1",BRPOP tasks 0)。- 最新消息列表:保存最新 N 条动态(
LPUSH news ...+LTRIM news 0 9)。- 栈/队列:通过
LPUSH+LPOP(栈)或LPUSH+RPOP(队列)实现。
3、redis哈希表(Hash)
- 键值对集合:哈希表存储的是键值对,其中键(field)和值(value)都可以是字符串。
- 灵活性:哈希表允许存储多个字段和值,非常适合表示对象。
- 高效性:由于哈希表的内部实现(如压缩链表或哈希表),Redis能够快速地执行哈希表的增删改查操作。
- Redis中每个hash可以存储2^32-1键值对(40多亿)
- 应用场景:
- 对象存储:存储用户属性(
HSET user:1 name Alice age 30)。- 部分更新:仅修改某个字段(
HINCRBY user:1 score 10),避免全量读取。
4、redis集合(set)
- 无序性:集合中的元素是无序的,即不保证元素的插入顺序。
- 唯一性:集合中的元素是唯一的,不允许有重复的元素。
- 动态性:集合可以动态地添加或删除元素。
- Redis 中Set集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。
- 集合中最大的成员数为 2^32 - 1 (4294967295, 每个集合可存储40多亿个成员)
- 应用场景:
- 标签系统:存储文章标签(
SADD article:1:tags "tech" "redis")。- 共同好友/兴趣:计算用户交集(
SINTER user:1:friends user:2:friends)。- 去重:记录用户 IP 访问记录(
SADD unique_ips 192.168.1.1)。
5、redis有序集合(zset)
- 有序性:*每个元素都会关联一个double类型的分数*,集合中的元素按照分数进行排序,分数越低,排名越靠前。
- 唯一性:集合中的元素是唯一的,不允许有重复的元素。但是,多个元素可以有相同的分数。
- 动态性:有序集合可以动态地添加、删除或更新元素及其分数。
- zset集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。 集合中最大的成员数为 2^32 - 1
- 应用场景:
- 排行榜:按积分排序用户(
ZADD leaderboard 1000 "user1")。- 延迟队列:用时间戳作为 score,定时拉取到期任务。
- 范围查询:查找价格区间的商品(
ZRANGEBYSCORE products 50 100)。
6、redis地理(GEO)
Redis的地理(GEO)功能提供了一种存储地理位置信息并进行地理空间查询的方法。Redis*使用GeoHash算法将二维的经纬度坐标编码为一维的字符串,从而实现对地理位置的快速查询和计算。*
- 存储地理位置:可以存储地理位置的经纬度信息(坐标信息)。
- 距离计算:可以计算两个地理位置之间的距离。
- 范围查询:可以查询指定范围内的地理位置。
- 性能高效:由于使用了GeoHash算法,Redis的地理功能在性能上非常高效。
- 应用场景:
- 附近的人:查询某坐标 5km 内的用户(
GEORADIUS users 116.40 39.90 5 km)。- 配送范围:计算两点距离(
GEODIST store:1 user:1 km)。
7、redis基数统计(HyperLogLog)
Redis的基数统计(HyperLogLog)是一种*用于估算数据集合中不重复元素数量的算法*。与传统的集合数据结构(如Redis的Set)相比,HyperLogLog在存储空间和计算效率上具有显著优势,尤其是在处理大规模数据集时。
- 存储空间小:HyperLogLog使用极少的存储空间来估算集合的基数(即不重复元素的数量)。即使在存储数亿个不重复元素时,HyperLogLog也能保持较小的内存占用,或者说计算基数所需的空间总是固定且是很小的。
- 计算效率高:HyperLogLog的基数估算操作非常快速,几乎可以在常数时间内完成。
- 估算精度:虽然HyperLogLog提供的是基数的估算值而非精确值,但其估算精度通常足够高,可以满足大多数应用场景的需求。在标准误差范围内(通常为0.81%),HyperLogLog的估算值非常接近实际基数。
- HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素。
- 在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基 数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比
- 应用场景:
- UV 统计:统计网站每日独立访客(
PFADD uv:2024-06-10 "user1" "user2")。- 去重计数:合并多个 HyperLogLog 估算总 UV(
PFMERGE uv:total uv:2024-06-10 uv:2024-06-11)。
8、redis位图(bitmap)
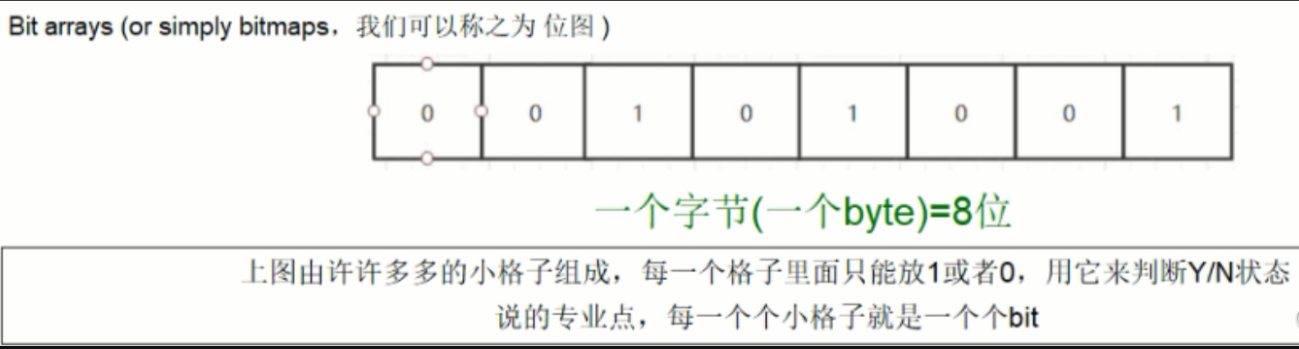
Redis的位图(Bitmap)是一种使用位数组来存储和操作二进制数据的数据结构。位图中的每一位可以表示一个数据点的存在状态(0或1),这使得位图在处理大量数据时非常高效,尤其是在需要快速进行存在性检查或统计操作的情况下。*简而言之就是由0和1状态表现的二进制位的bit数组*
- 空间效率:位图使用位数组来存储数据,因此可以非常高效地利用存储空间。例如,一个位图可以轻松地表示数百万个数据点的存在状态,而占用的内存空间却非常少。
- 操作速度:由于位图的内部实现通常基于高效的位操作算法,因此位图上的操作(如设置、清除、检查位等)通常非常快速。
- 灵活性:位图可以灵活地表示各种类型的数据点,只要这些数据点可以被映射到一个唯一的索引上。例如,你可以使用位图来表示用户的登录状态、商品的库存状态,判断Y/N状态,其现实生活中的实例为,软件的签到,打卡等等。
- 应用场景:
- 用户签到:记录每日签到状态(
SETBIT user:1:sign:2024 5 1表示第 5 天签到)。- 活跃用户统计:统计连续登录天数(
BITCOUNT user:1:login)。
9、redis位域(bitfield)
Redis的位域(Bitfield)功能允许你在位图(Bitmap)上进行更复杂的位操作,如读取、写入和递增特定长度的位字段。使得Redis能够更高效地处理二进制数据。
- bitfield命令可以一次性操作多个比特位域(指的是连续的多个比特位),它会执行一系列操作并返回一个响应数组,这个数组中的元素对应参数列表中的相应操作的执行结果。
- 灵活性强:位域操作允许你指定要操作的位字段的长度(从1位到64位),这使得你可以在位图上表示不同类型的数据(如布尔值、整数、浮点数等)。
- 高效性:位域操作通常在单个命令中完成多个位的读写操作,从而减少了网络往返次数和Redis服务器的处理时间。
- 原子性:位域操作是原子的,这意味着它们在执行过程中不会被其他命令打断,从而保证了数据的一致性和完整性。
10、redis流(Stream )
Redis流(Stream)是Redis 5.0版本引入的一种新的数据结构,主要用于消息队列(MQ,Message Queue),Redis 本身是有一个 Redis 发布订阅 (pub/sub) 来实现消息队列的功能,但它有个缺点就是消息无法持久化,如果出现网络断开、Redis 宕机等,消息就会被丢弃。简单来说发布订阅 (pub/sub) 可以分发消息,但无法记录历史消息。而 Redis Stream 提供了消息的持久化和主备复制功能,可以让任何客户端访问任何时刻的数据,并且能记住每一个客户端的访问位置,还能保证消息不丢失
- 消息序列化:流中的每条消息都有一个唯一的ID,这个ID通常是由Redis自动生成的,但也可以由客户端指定。消息ID是有序的,因此流中的消息是按顺序排列的。
- 消费者组:流支持消费者组的概念,允许多个消费者协作处理流中的消息。每个消费者组都有自己的消费进度(即已处理的消息ID),并且可以将消息分配给不同的消费者进行处理。
- 持久化:流支持AOF(Append Only File)和RDB(Redis Database Backup file)两种持久化方式,确保消息在Redis重启后不会丢失。
- 消息确认:消费者可以显式地确认已经处理的消息,这样Redis就可以将这些消息从流中删除或标记为已处理。
- 应用场景:
- 日志收集:实时记录并分发日志到多个消费者。
- 事件溯源:存储用户操作事件流(
XADD user_events * action login user_id 1)。
redis通用命令
| 命令 | 作用 |
|---|---|
| keys * | 查看当前库中所有key |
| exsis key | 判断某个key是否存在 |
| type key | 查看指定key的数据类型 |
| del key | 删除指定的key数据 |
| unlink key | 非阻塞删除,仅仅将keys从keyspace元数据中删除,正真的删除会在后续异步中操作 |
| ttl key | 查看还有多少秒过期,-1代表永不过期,-2代表已经过期 |
| expire key seconds | 为指定的key设置过期时间 |
| move key dbindex[0~15] | 将当前数据库的key移动到给定的数据库db当中 |
| select dbindex[0~15] | 切换数据库【0~15】,默认为0 |
| dbsize | 查看当前数据库key的数量 |
| fiushdb | 清空当前库 |
| flushall | 通杀全部库 |


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现