
正则表达式和通配符及相关linux命令实操
介绍:
正则表达式和通配符含义是完全不同的,比如通配符和正则表达式都使用星号(*)字符。通配符中使用特定的字符(如?
和*)表示替换(substitution),而正则表达式中同样的字符表示要对前面的内容进行匹配的次数。
和*)表示替换(substitution),而正则表达式中同样的字符表示要对前面的内容进行匹配的次数。
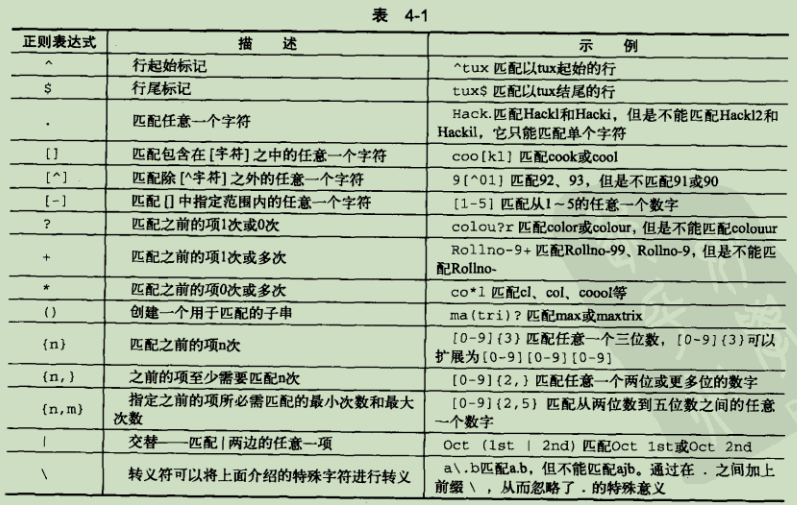
正则表达式的c*l,可以匹配cl、ccl、l等
通配符的c*l,可以匹配cl、cool、c酷的l等
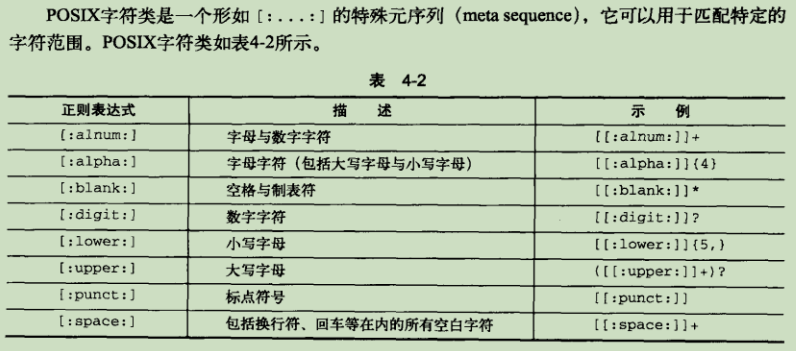
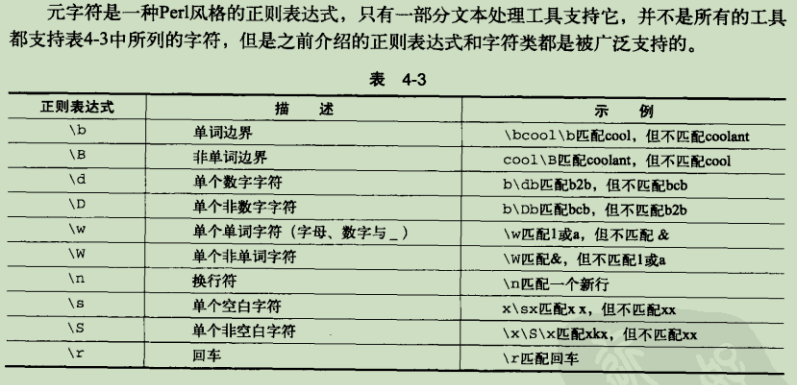
正则表达式基本组成:
单引号与双引号
在命令中使用单引号,不转义引号内容,原样输出;使用双引号,转义引号内容
*并非适用于所有命令
逻辑测试语句 && || !
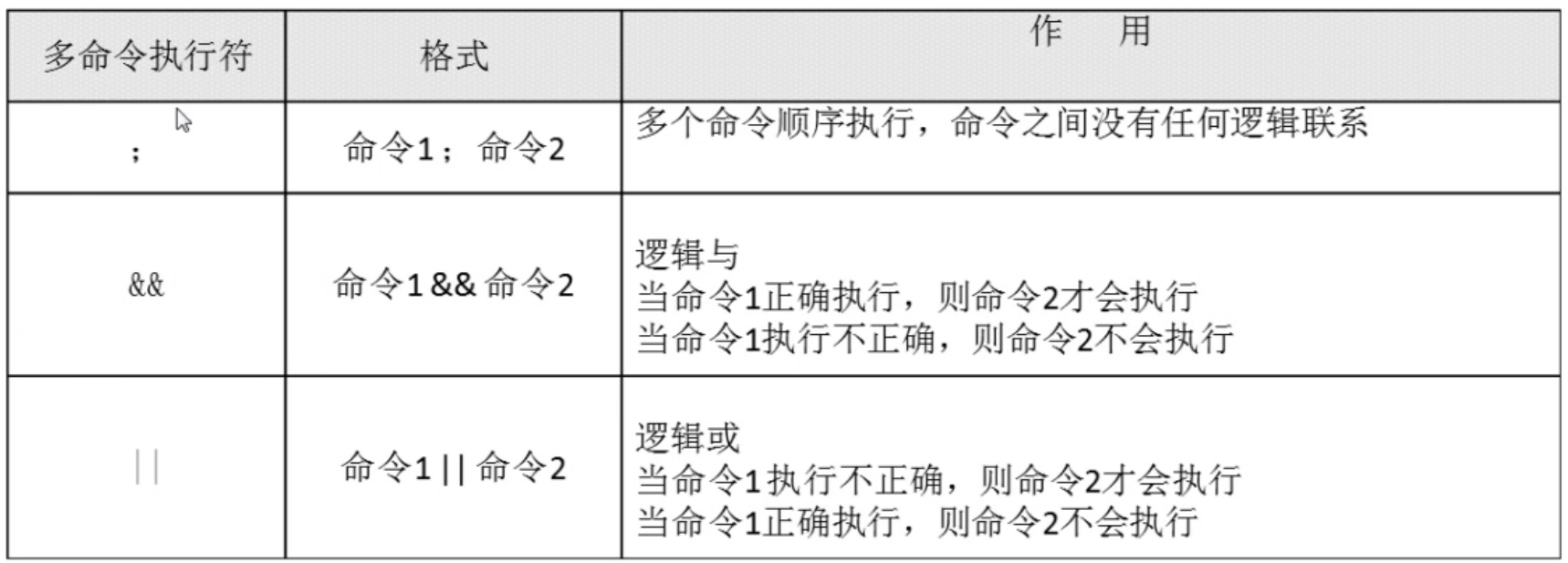
a && b a执行成功才执行b
a || b a执行失败才执行b
! a a执行结果取反
》》》locate #生成索引,再查询
locate命令能够在文件、程序和目录中查找与提供的搜索项匹配的内容,并把任何匹配的结果依次显示到终端界面上。
所属包名mlocate
参数
-i 忽略大小写
-n 只显示匹配到的几行
使用:第一次执行先root下 执行命令 updatedb ,生成索引;
有新的文件产生后,数据库不会自动刷新,只是定时刷新,有需要手动执行达到立即刷新
然后搜索文件 locate filename
如 locate fstab
locate -n5 service
》》》grep
grep参数
-v 排除查找,即取反
-E 启动正则表达式,grep -E xxx查询等价于egrep xxx
-i 忽略大小写
-w 完全匹配字符
-c:统计符合条件的行数
-n:显示符合条件的行并显示每行编号
-x 完全匹配整行
-r -R 级联
-l 仅显示匹配到内容的文件名 -L 仅显示没有匹配到内容的文件名
-A 打印匹配到内容行及前面几行 -B打印匹配到内容行及后面几行
-C 打印匹配到内容行及前面、后面各几行
-o 仅显示匹配到的内容
示例
1、过滤空白行
cat filename | grep -v '^$' 或者grep -v "^$" filename
2、过滤注释行
cat filename | grep -v '^#'
3、同时过滤空白行与注释行
cat filename | grep -v '^$' | grep -v '^#'
或者使用
cat filename | grep -Ev '^#|^$'
4、过滤文件filename已-开头的行
cat filename | grep -v "^-"
5、过滤文件filename中存在-的行
cat filename | grep -v "-"
6、查询不以字母开头的行
cat filename |grep ^[a-zA-Z]
7、查询条件 r**t相关的行
cat filename |grep r..t
8、查询rt或者rot或者ro...t等
cat filename |grep 'ro*t'
9、查询连续出现两个oo的行
grep 'o\{2\}' filename
10、查询/tmp下文本内容含有test字符的文件
grep test /tmp/* 或者grep test /tmp -R
补:
统计文件夹下文件的个数
ls -l | grep "^-"| wc -l 或者ls -l|grep "^-" -c
统计文件夹下目录的个数
ls -l | grep "^d"| wc -l
统计文件夹下文件个数,包括子目录下的文件
ls -lR | grep "^-"| wc -l
统计文件夹下目录个数,包括子目录
ls -lR | grep "^d"| wc -l
或查询
find / |grep -E 'etc|selinux|config' #查询根下含有etc、selinux、config文件或文件夹
与查询
find / |grep -E 'etc.selinux.config' #查询根下同时含有etc、selinux、config的文件或文件夹
补充题:
查询file1文件内是否有文本 hey you !,通过单引号、双引号、不加引号来理解怎么用
grep hey you ! file1
grep 'hey you !' file1
grep "hey you !" file1 # “!”是一个shell命令,用于引用命令历史,后面跟一个pid,代表先前运行过的命令
如果要搜索精确的匹配结果,就使用单引号;
如果要把shell变量结合到搜索内容中(很少有这样的需要),就使用双引号;
但如果搜索关键字只包含数字和字母,完全不使用任何引号也没有问题。
》》》egrep
grep -Ev '^#|^$' filename 等价于egrep -v '^#|^$' filename
》》》wc
参数:
1.-l 选项:显示统计的行数
2.-w 选项:显示统计的单词数
3.-c 选项:显示统计的字节数
1、统计文件夹下文件的个数,不包括链接文件 #不包含.开头的文件,同下
ls -l | grep "^-"| wc -l
2、统计文件夹下目录的个数,不包括链接目录
ls -l | grep "^d"| wc -l
3、统计文件夹下文件个数,包括子文件,不包括链接文件
ls -lR | grep "^-"| wc -l
4、统计文件夹下目录个数,包括子目录,不包括链接目录
ls -lR | grep "^d"| wc -l
》》》find
参数:
1.-name选项:按照文件名称查找,允许使用通配符。
2.-type选项:按照文件类型查找。文件类型有f普通文件、d目录、l符号链接
3.-user选项:按照文件所有者查找。-group 根据用户组搜索
4.-size选项:按照文件大小查找。
5.-maxdepth<目录层级〉:设置最大目录层级;
6.-fprint 文件路径 :将查找内容输出到文件
7.-exec 对搜索到的每个文件执行命令
补充:-print 默认是开启的,find查询时已经使用输出到屏幕了
-size参数补充:根据文件大小查找,使用数字+后缀,后缀有b(默认值,512字节块)、c(字节)、k、M、G
使用数字+ [-/+] +后缀,+号表示查找大于数值的文件,-号查找小于数值的文件,不加+/-查找对应大小的文件(取整后,非绝对相等)
如 find . -size +10M 查找当前目录下大于10M的文件
find . size 10M 查找当前目录下约等于10M的文件
补充:find的”and、or、!“,即多条件筛选
find
参数 -a 即and,多条件同时筛选
参数 -o 即or,命中一个条件就可以
参数! 取反
如find . -name "hello" -a -type f 查找文件名是hello,同时是普通文件的文件
find . -size +10M -o -size 10M 查找大于等于10M的文件
find . ! -name "hello" 查找文件名不是hello的文件
示例
1.find /etc -name "net*.conf" 查找etc目录下所有文件名是以"net"开头,".conf"结尾的文件
2.find /boot -type d 查找boot目录下所有的目录
3.find /boot -size +1024k 查找boot目录下所有大于1024k的文件
4.find /home -user horse 查找home目录下所有归属者是horse的文件
基于目录深度搜索
find -maxdepth 3 -type f 向下最大深度限制为3,文件类型为普通文件
find -mindepth 2 -type f 搜索出深度距离当前目录至少2个子目录的所有文件
忽略一个或多个目录下文件
注意:-path 的前缀要和find的目录一样
#忽略单个目录
#-a逻辑与,当-path "./var"为真,则执行-prune,返回真;-o逻辑或,增加查询条件,与前面排除目录条件组合输出符合的内容
理解方法:find . {{{-path "./var"} -a {-prune}} -o {-name ".log"}} -print
find . -path "./var" -a -prune -o -name ".log" -print
#忽略多个目录
find . \( -path "./var" -o -path "./opt" \) -a -prune -o -name ".log" -print
或者
#忽略单个目录,其中./var*表示./var下所有文件
find . ! -path "./var*" -name ".log"
#忽略多个目录
find . ! -path "./var*" ! -path "./opt*" -name "*.log"查找一个或多个目录下文件
在当前目录下的dir1目录及dir1子目录下查找文件
find ./ -path "./dir1*" -name 1.txt
在当前目录下的dir1、dir2目录及dir1、dir2子目录下查找文件
find ./ \( -path "./dir1*" -o -path "./dir2*" \) -name a找到范围时间内的文件
-mmin N 修改时间:文件内容最后一次修改时间,单位分钟
-amin N 访问时间:用户最近的一次访问时间,单位分钟
-cmin N 变化时间:文件权限、所有权最后一次改变时间,单位分钟
-mtime N 修改时间:文件内容最后一次修改时间,单位天
-atime N 访问时间:用户最近的一次访问时间,单位天
-ctime N 变化时间:文件权限、所有权最后一次改变时间,单位天
-newermt 指定日期
-newer 指定参考文件
find /home -type f -mmin -1 //查找/home下在一分钟内修改的文件
find /home -type f -mmin 1 //查找/home刚好在前一分时修改的文件
find /home -type f -mmin +1 //查找/home下在一分钟前修改的文件
find /home -type f -newermt "2022-5-06" //查找5月6号的文件
find /home -type f -newer file.txt //查找比file.txt修改时间更短的(修改时间距当前时间更近的)文件
查询条件还有'-10 minutes' '-24 hours' '1 day ago ' 'yesterday'
补充:find 参数-perm
根据文件的读写执行权限来查找文件
使用man find查看帮助文件,分为四种 mode、+mode、-mode、/mode
find -perm mode , 表示严格匹配
find -perm -mode , 表示mode中转换成二进制的1在文件权限位里面必须匹配,即匹配文件权限需大于等于mode
find -perm +mode , 与 -mode的区别是+mode只需其中的任意一个1的部分被匹配
find -perm /mode ,同find -perm +mode
如find / -perm g=wx,-o=x 查找根下文件权限是g=wx,o=x的文件
find / -perm -0064 查找根下文件权限大于0064的文件
说明:0064转换为二进制000 000 110 100,特殊位、读权限、写权限、执行权限,-0064表示必须匹配二进制中1的占位,0不用管,可匹配到0066或者1164等等
find / -perm +0064 匹配对文件属组用户、其他用户有任意权限的文件
说明+0064表示匹配至少每个权限中二进制1一次,可匹配到0011或者0042等等
补充:
find . -name " *MP3" -exec rename 's/MP3/mp3/g' {} ;
》》》ls
ls -lt /home //按时间顺排序文件,降序排序,即最新的在前
ls -ltr /home //按时间顺排序文件,升序排序
ls -lt /home|grep "5月" 查询/home下时间为5月的文件
ls -ltR /home|grep "5月" 查询/home及其子目录时间为5月的文件
》》》cut
参数:
-d 指定分隔符,默认为Tab
-f 指定显示的列数
-c 只选中指定
示例
cut -d: -f1 /etc/passwd #-d:以":"做分隔符,-f1参数代表只看第一列的内容
cut -c 1,2,3,4,5 /etc/passwd #显示1,2,3,4,5列内容
cut -c 1-5 /etc/passwd #显示1,2,3,4,5列内容
cut -c -5 /etc/passwd #显示1,2,3,4,5列内容
》》》printf
printf [输出类型 输出格式] 输出内容
输出类型:
- %ns:输出字符串。n是数字指输出⼏个字符
- %ni:输出整数。n是数字指输出⼏个数字
- %m.nf:输出浮点数。m和n是数字,指代输出的整数位和⼩数位,如%8.2f代表共输出8位数,其中2位是⼩数,6位是整数 输出格式:
- \a:输出告警声⾳
- \b:输出退格键,也就是Backspace键
- \f:清除屏幕
- \n:换⾏
- \r:回⻋,也就是Enter键
- \t:⽔平输出退格键,也就是Tab键
- \v:垂直输出退格键,也就是Tab键
print与printf区别:print输出时自动加入一个换行符
print $(cat /etc/passwd)
printf '%s\t\n' $(cat /etc/passwd)
》》》awk
awk '条件1{动作1}条件2{动作2}...' ⽂件名
条件(Pattern):
- ⼀般使⽤关系表达式作为条件
- x > 10判断变量x是否⼤于10
- x>=10⼤于等于
动作(Action):
- 格式化输出
- 流程控制语句
参数
-F 设置分隔符,默认分割符为制表符
实例
awk '/root/,/mysql/' test #将显⽰root第⼀次出现到mysql第⼀次出现之间的所有⾏
#计算已使用内存
awk '/MemTotal/{total=$2}/MemFree/{free=$2}END{print (total-free)/1024}' /proc/meminfo
awk -F : '$3>=1000{printf $1 "\n"}' /etc/passwd #
以下三条命令注意对比观察
grep "/bin/bash" /etc/passwd|awk -F : '{printf $1 "\t" $3 "\n"}'
root 0
kylin 1000
cat /etc/passwd | grep "/bin/bash" | awk 'BEGIN{FS=":"}{printf $1 "\t" $3 "\n"}'
root 0
kylin 1000
cat /etc/passwd | grep "/bin/bash" | awk '{FS=":"}{printf $1 "\t" $3 "\n"}'
root:x:0:0:root:/root:/bin/bash
kylin 1000
awk '/^(no|so)/' test-----打印所有以模式no或so开头的⾏。
awk '/^[ns]/{print $1}' test-----如果记录以n或s开头,就打印这个记录
awk '$1 ~/[0-9][0-9]$/ {print $1}' test-----如果第⼀个域以两个数字结束就打印这个记录。
awk '$1 == 100 || $2 < 50' test-----如果第⼀个域等于100或者第⼆个域⼩于50,则打印该⾏。
awk '$1 != 10' test-----如果第⼀个域不等于10就打印该⾏。
awk '/test/{print $1 + 10}' test-----如果记录包含正则表达式test,则第⼀个域加10并打印出来
awk '{print ($1 > 5 ? "ok "$1: "error "$1)}' test-----如果第⼀个域⼤于5则打印问号后⾯的表达式值,否则打印冒号后⾯的表达式值。
awk '/^root/,/^mysql/' test----打印以正则表达式root开头的记录到以正则表达式mysql开头的记录范围内的所有记录。如果找到⼀个新的正则表达式root开头的记录,则继续打印直到下⼀个以正则表达式mysql开头的记录为⽌,或到⽂件末尾awk 'BEGIN{printf "hello,your name ";getline name < "/dev/tty"}$1 ~name{print "found " name on line ,NR "."}END{print "see you," name "."}' testfile
》》》sed
sed [选项] '[动作]' ⽂件名
选项:
-n :⼀般sed命令会把所有数据都输出到屏幕,如果加⼊此选择,则只会把经过sed命令处理的⾏输出到屏幕
-e:允许对输⼊数据应⽤多条sed命令编辑
-i:⽤sed的修改结果直接修改读取数据的⽂件,⽽不是输出到屏幕
动作:
=:打印行号
a:追加,在当前⾏后添加⼀⾏或多⾏
c:⾏替换,⽤c后⾯的字符串替换原数据
i:插⼊,在当前⾏前插⼊⼀⾏或多⾏。
d:删除,删除指定⾏
p:打印,输出指定的⾏
s:字串替换,⽤⼀个字符串替换另⼀个字符串。格式为"⾏范围s/旧字串/新字串/匹配数g"。不指定行范围查询所有行
示例
1、查询或修改内容仅输出到屏幕,原文件内容不变
sed '2,4d' /etc/hosts #删除第2到4行的内容
sed '2a hello' /etc/hosts #在第2行后,新添加一行写入hello内容
sed '2c hello' /etc/hosts #第2行内容替换为hello
sed '3s/hi/hello/g' /etc/hosts #把第三⾏的hi替换成hello
sed '3s/hi/hello/' /etc/hosts #把第三⾏的hi替换成hello,只替换一次hi,g指global
sed '2,5s/hi/hello/3g' /etc/hosts #把2-5行匹配到的hi,每行从第3次匹配到的替换为hello
root@pioneer:~/1DAY# sed '2,5s/hi/hello/3g' a.sh
hihihihihihihi
hihihellohellohellohellohello
hihihellohellohellohellohello
hihihellohellohellohellohello
hihihellohellohellohellohello
hihihihihihihised -e 's/hi/hello/g;s/world/earth/g' /etc/hosts #同时处理多条内容
2、直接修改文件内容
sed -i '2,4d' /etc/hosts #删除第2到4行的内容,文件内容被修改
sed '/^$/d' file #移除空白行
》》》sort
sort [] ⽂件名
选项:
不加参数,以第一个字母ascii码对应值有小到大排序,即特殊符号,数字,小写字母,大写字母
-f:忽略⼤⼩写
-n:以数值型进⾏排序,默认使⽤字符串型排序
-r:反向排序
-t:指定分隔符,默认分隔符是制表符
-k n[,m]:按照指定的字段范围排序。从第n字段开始,m字段结束(默认到⾏尾)
示例:
sort /etc/passwd
sort -t : -k 3,3 /etc/passwd #制定分隔符后,按第三列排序。排序时按字符排,不是数值
sort -n -t : -k 3,3 /etc/passwd #按数值排
》》》seq
用法:seq [选项]... 尾数
或:seq [选项]... 首数 尾数
或:seq [选项]... 首数 增量 尾数
参数:
-s 指定输出分隔符,默认为\n,即默认为回车换行
-w 指定定宽输出,不能和-f一起使用
-f 按照指定格式输出,不能和-f一起使用
示例:
root@kylin-W515:~# seq 1 2 10
1
3
5
7
9
root@kylin-W515:~# seq -s , 1 5 #-s指定分隔符
1,2,3,4,5
root@kylin-W515:~# seq -s "echo -e "\t"" 1 5 #使用echo输出制表符作为分隔符
1 2 3 4 5
root@kylin-W515:~# seq -w 9 11 #指定定宽输入,会自动用0补全
09
10
11
root@kylin-W515:~# seq -w 9 011
009
010
011
root@kylin-W515:~# seq -f '%04g' 9 11 # '%04g' 指定位宽为4位,数字不足用0补齐
0009
0010
0011
root@kylin-W515:~# seq -f '%4g' 9 11 # '%4g' 指定位宽为4位,数字不足用空格补齐
9
10
11
root@kylin-W515:~# seq -f '测试%04g.txt' 9 11 #可在格式中的%和g前后添加字符
测试0009.txt
测试0010.txt
测试0011.txt》》》uniq 只打印不相同的行,相同行的内容只打印一次
-c 输出行号
-d 仅打印重复行,打印一次
-D 打印重复行,有几行打印几行
-u 打印不重复的行
kylin@kylin-W515:~/桌面$ cat cc
11
22
11
33
aa
aa
kylin@kylin-W515:~/桌面$ uniq cc
11
22
11
33
aa
kylin@kylin-W515:~/桌面$ uniq -c cc
1 11
1 22
1 11
1 33
2 aa
