进程调度算法--引阿秀学习笔记 虚拟内存、物理内存、页表、快表、动态分区分配算法
1.先来先服务 First-come First-serverd(FCFS)
按照请求顺序进行调度,利于长作业,不利短作业,短作业等待前面长作业执行完毕才可执行,造成短作业等待时间长。
2.短作业优先 shortest job first(SJF)
按估计运行时间最短的作业顺序进行调度,长作业可能会饿死(假如一直有短作业到来)
3.最短剩余时间优先 shortest remaining time next(SRTN)
最短作业优先抢占,按剩余运行时间进行调度,当新作业到达时,整个运行时间与当前进程的剩余时间比较,如果新的作业时间更少,则挂起当前进程,运行新进程,否则新进程等待。
4.时间片轮转
将所有的就绪进度按 FCFS 原则排成队列,每次调度时,将CPU时间分配给队首进程,该进程可以执行一个时间片。
当时间片用完,计时器发出时钟中断,调度程序停止该进程的执行,并将其送往就绪队列的队尾,同时将CPU分配给新的队首进程。
时间片轮转算法的效率和时间片的大小有很大关系:
🔴 因为进程切换都要保存进程的信息并且载入新的进程信息,如果时间片太小,会导致进程切换太频繁,切换会消耗大量时间。
🔴 时间片太长,那么实时性无法保证。
5.优先级调度
为每个进程分配一个优先级,按优先级进行调度。为了防止低优先级的进程永远得不到调度,可以随着时间的推移增加等待进程的优先级。
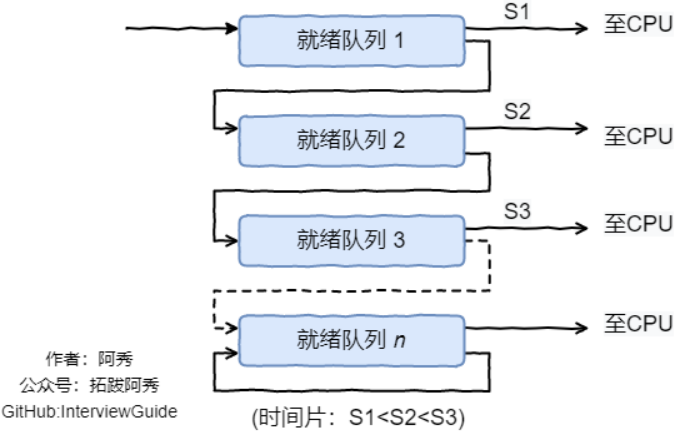
6.多级反馈队列
一个进程需要执行100个时间片,采用时间片轮转调度算法,需要交换100次。
多级队列是为这种执行多个时间片的进程考虑,它设置了多个队列,每个队列时间片大小都不同,例如 1,2,4,8....,进程在第一个队列没执行完,就会被移到下一个队列。
这种方式,100个时间片只需要交换7次。每个队列的优先权也不同,最上面的优先权最高,因此只有上一个队列没有进程在排队,才能调度当前队列上的进程。
类似 时间片轮转调度算法 与 优先级调度算法的结合。
物理内存:寄存器、高速缓存、主存、磁盘
🔴 寄存器:速度最快、量少、价格高
🔴 高速缓存(Cache):速度高于内存,接近于CPU速度,存储CPU运行时常用的指令。放置于 内存与CPU之间(大约是内存的访问一百倍速度)
🔴 主存(RAM):内存
🔴 磁盘:速度最慢、量多、价格低。
操作系统会对物理内存进行管理,有一个部分称为 内存管理器(Memory Manager),主要工作是有效的管理内存,记录哪些内存是正在使用的,分配内存,回收内存等。
虚拟内存:
操作系统为每一个进程分配一个独立的地址空间,但是虚拟内存与物理内存存在映射关系,通过页表寻址完成虚拟地址和物理地址的转换。
内核(系统)态与用户态:为了保护系统安全,有一些指令比较危险。
进入内核态:系统调用、异常、设备中断。系统调用是主动,其余两者为被动。
页表:
虚拟内存的概念。操作系统虚拟内存到物理内存的映射,被称为页表。
不可能每一个虚拟内存的Byte都对应到物理内存的地址,因为这样的页表非常大,于是引入 页(Page)概念,进行分页,减小虚拟内存页对应物理内存页映射表的大小。
缺页异常:malloc和mmap函数分配内存是仅建立了 进程虚拟地址空间,并没有分配虚拟内存对应的物理内存,进程访问没有建立映射关系的虚拟内存时,处理器自动触发 缺页异常,引发缺页中断。
缺页中断:缺页异常后产生一个缺页中断,操作系统根据页表中的 外存地址 在外村中找到所缺的一页,将其调入 内存。
在进行动态内存分配的时,(C++ 中 new),操作系统会在硬盘中创建或申请一段虚拟内存空间,并更新到页表(分配一个页表条目),该条目指向硬盘上新创建的虚拟页,产生映射关系。
快表:存于Cache
又称联想寄存器(TLB),是一种访问速度比内存快很多的高速缓冲存储器,用来存放当前访问的若干页表项,以加速地址变换过程(内存中的页表常称为慢表)
系统中具有快表后,地址转换过程:
🔴 CPU给出逻辑地址,由某个硬件算得页号、页内偏移量,将页号与快表中的所有页号进行比较。
🔴 如果找到匹配的页号,说明要访问的页表项在快表中有副本,则直接从中取出该页对应的内存块号,再将内存块号与页内偏移量拼接形成物理地址,最后,访问该物理地址对应的内存单元。因此,若快表命中,则访问某个逻辑地址仅需一次访存即可。
🔴 如果没有找到匹配的页号,则需要访问内存中的页表(慢表),找到对应页表项,得到页面存放的内存块号,再将内存块号与页内偏移量拼接形成物理地址,最后,访问该物理地址对应的内存单元。因此,若快表未命中,则访问某个逻辑地址需要两次访存(注意:在找到页表项后,应同时将其存入快表,以便后面可能的再次访问。但若快表已满,则必须按照一定的算法对旧的页表项进行替换)
因为局部性原理,一般来说快表的命中率可以达到90%以上。
无快表地址变换:①算页号、页内偏移量 ②检查页号合法性 ③查页表(慢表),找到页面存放的内存块号 ④根据内存块号与页内偏移量得到物理地址 ⑤访问目标内存单元(两次访存)
有快表地址变换:①算页号、页内偏移量 ②检查页号合法性 ③查快表。若命中,即可知道页面存放的内存块号,可直接进行⑤;若未命中则进行④ ④查页表,找到页面存放的内存块号,并且将页表项复制到快表中 ⑤根据内存块号与页内偏移量得到物理地址 ⑥访问目标内存单元(命中,一次访存,未命中,两次访存)
例:某系统使用基本分页存储管理,并采用了具有快表的地址变换机构。访问一次快表耗时1us, 访问一次内存耗时100us。若快表的命中率为90%,那么访问一个逻辑地址的平均耗时是多少? (1+100) * 0.9 + (1+100+100) * 0.1 = 111 us 有的系统支持快表和慢表同时查找,如果是这样,平均耗时应该是(1+100) * 0.9+ (100+100) *0.1=110.9 us 若未采用快表机制,则访问一个逻辑地址需要100+100 = 200us 显然,引入快表机制后,访问一个逻辑地址的速度快多了。
内存交换和覆盖有什么区别?
交换技术主要是在不同进程(作业)之间进行,而覆盖则用于同一程序或进程中。
动态分区分配算法:
1.首次适应算法:每次都从低地址开始查找,找到第一个能满足大小的空闲分区。
实现:空闲分区以地址递增的次序排列。每次分配内存时顺序查找空闲分区链(或空闲分表),找到大小能满足的第一个空闲分区。
2.最佳适应算法:动态分配是一种连续的分配方式,为各进程分配必须是连续的一整片区域,为尽可能留下大片的空闲区,优先使用最小的空闲区。
实现:空闲分区按照容量次序链接,每次分配内存顺序查找空闲分区链(或空闲分区表),找到第一个满足的空闲分区。
3.最坏适应算法(最大适应):为了解决最佳适应算法留下难以利用的小碎片,在每次分配时优先使用最大的连续空闲。
实现:空闲分区容量递减次序链接,每次分配内存顺序查找空闲分区链(或空闲分区表),找到一个满足的空闲分区。
4.邻近适应算法:首次适应每次从链头开始查找,可能导致低地址部分出现小的分区,每次分配查找都要经过这些分区,增加了查找的开销,每次从上次结束的地方开始检索。
实现:空闲分区以地址递增的顺序排列(排成一个循环链表),每次分配内存从上次查找结束的位置开始查找空闲分区链(或空闲分区表),找到一个满足的空闲分区。
首次适应不仅最简单,通常也是最好最快,不过首次适应算法会使得内存低地址部分出现很多小的空闲分区,而每次查找都要经过这些分区,因此也增加了查找的开销。
邻近算法试图解决这个问题,但实际上,它常常会导致在内存的末尾分配空间分裂成小的碎片,它通常比首次适应算法结果要差。
最佳导致大量碎片,最坏导致没有大的空间。
首次适应比最佳适应要好,他们都比最坏好。
| 算法 | 算法思想 | 分区排列顺序 | 优点 | 缺点 |
|---|---|---|---|---|
| 首次适应 | 从头到尾找适合的分区 | 空闲分区以地址递增次序排列 | 综合看性能最好。算法开销小,回收分区后一.般不需要对空闲分区队列重新排序 | |
| 最佳适应 | 优先使用更小的分区,以保留更多大分区 | 空闲分区以容量递增次序排列 | 会有更多的大分区被保留下来,更能满足大进程需求 | 会产生很多太小的、难以利用的碎片;算法开销大,回收分区后可能需要对空闲分区队列重新排序 |
| 最坏适应 | 优先使用更大的分区,以防止产生太小的不可用的碎片 | 空闲分区以容量递减次序排列 | 可以减少难以利用的小碎片 | 大分区容易被用完,不利于大进程;算法开销大(原因同上) |
| 邻近适应 | 由首次适应演变而来,每次从上次查找结束位置开始查找 | 空闲分区以地址递增次序排列(可排列成循环链表) | 不用每次都从低地址的小分区开始检索。算法开销小(原因同首次适应算法) | 会使高地址的大分区也被用完 |


 浙公网安备 33010602011771号
浙公网安备 33010602011771号