第三篇:字符编码与文件处理
了解字符编码还需要了解的
一 计算机基础知识
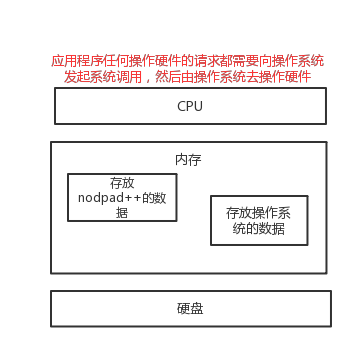
二 文本编辑器存取文件的原理(nodepad++,pycharm,word)
1 1、打开编辑器就打开了启动了一个进程,是在内存中的,所以,用编辑器编写的内容也都是存放与内存中的,断电后数据丢失 2 3 2、要想永久保存,需要点击保存按钮:编辑器把内存的数据刷到了硬盘上。 4 5 3、在我们编写一个py文件(没有执行),跟编写其他文件没有任何区别,都只是在编写一堆字符而已
三 python解释器执行py文件的原理 ,例如python test.py
1 #第一阶段:python解释器启动,此时就相当于启动了一个文本编辑器 2 3 #第二阶段:python解释器相当于文本编辑器,去打开test.py文件,从硬盘上将test.py的文件内容读入到内存中(小复习:pyhon的解释性,决定了解释器只关心文件内容,不关心文件后缀名) 4 5 #第三阶段:python解释器解释执行刚刚加载到内存中test.py的代码( ps:在该阶段,即真正执行代码时,才会识别python的语法,执行文件内代码,当执行到name="egon"时,会开辟内存空间存放字符串"egon")
四 总结python解释器与文件本编辑的异同
1 #1、相同点:python解释器是解释执行文件内容的,因而python解释器具备读py文件的功能,这一点与文本编辑器一样 2 3 #2、不同点:文本编辑器将文件内容读入内存后,是为了显示或者编辑,根本不去理会python的语法,而python解释器将文件内容读入内存后,
可不是为了给你瞅一眼python代码写的啥,而是为了执行python代码、会识别python语法。
2、字符编码介绍
一 什么是字符编码
1 计算机要想工作必须通电,即用‘电’驱使计算机干活,也就是说‘电’的特性决定了计算机的特性。电的特性即高低电平(人类从逻辑上将二进制数1对应高电平,二进制数0对应低电平),
关于磁盘的磁特性也是同样的道理。结论:计算机只认识数字 2 3 很明显,我们平时在使用计算机时,用的都是人类能读懂的字符(用高级语言编程的结果也无非是在文件内写了一堆字符),如何能让计算机读懂人类的字符? 4 5 必须经过一个过程: 6 #字符--------(翻译过程)------->数字 7 8 #这个过程实际就是一个字符如何对应一个特定数字的标准,这个标准称之为字符编码
二 了解一下字符编码的发展史与分类
计算机由美国人发明,最早的字符编码为ASCII,只规定了英文字母数字和一些特殊字符与数字的对应关系。最多只能用 8 位来表示(一个字节),即:2**8 = 256,所以,ASCII码最多只能表示 256 个符号
当然我们编程语言都用英文没问题,ASCII够用,但是在处理数据时,不同的国家有不同的语言,日本人会在自己的程序中加入日文,中国人会加入中文。
而要表示中文,单拿一个字节表表示一个汉子,是不可能表达完的(连小学生都认识两千多个汉字),解决方法只有一个,就是一个字节用>8位2进制代表,位数越多,代表的变化就多,这样,就可以尽可能多的表达出不通的汉字
所以中国人规定了自己的标准gb2312编码,规定了包含中文在内的字符->数字的对应关系。
日本人规定了自己的Shift_JIS编码
韩国人规定了自己的Euc-kr编码(另外,韩国人说,计算机是他们发明的,要求世界统一用韩国编码,但世界人民没有搭理他们)
这时候问题出现了,精通18国语言的小苟同学谦虚的用8国语言写了一篇文档,那么这篇文档,按照哪国的标准,都会出现乱码(因为此刻的各种标准都只是规定了自己国家的文字在内的字符跟数字的对应关系,如果单纯采用一种国家的编码格式,那么其余国家语言的文字在解析时就会出现乱码)
所以迫切需要一个世界的标准(能包含全世界的语言)于是unicode应运而生(韩国人表示不服,然后没有什么卵用)
ascii用1个字节(8位二进制)代表一个字符
unicode常用2个字节(16位二进制)代表一个字符,生僻字需要用4个字节
例:
字母x,用ascii表示是十进制的120,二进制0111 1000
汉字中已经超出了ASCII编码的范围,用Unicode编码是十进制的20013,二进制的01001110 00101101。
字母x,用unicode表示二进制0000 0000 0111 1000,所以unicode兼容ascii,也兼容万国,是世界的标准
这时候乱码问题消失了,所有的文档我们都使用但是新问题出现了,如果我们的文档通篇都是英文,你用unicode会比ascii耗费多一倍的空间,在存储和传输上十分的低效
本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间:
三 总结一下以上分析,字符编码发展分为三部分


1 #阶段一:现代计算机起源于美国,最早诞生也是基于英文考虑的ASCII 2 ASCII:一个Bytes代表一个字符(英文字符/键盘上的所有其他字符),1Bytes=8bit,8bit可以表示0-2**8-1种变化,即可以表示256个字符 3 4 ASCII最初只用了后七位,127个数字,已经完全能够代表键盘上所有的字符了(英文字符/键盘的所有其他字符),后来为了将拉丁文也编码进了ASCII表,将最高位也占用了 5 6 #阶段二:为了满足中文和英文,中国人定制了GBK 7 GBK:2Bytes代表一个中文字符,1Bytes表示一个英文字符 8 为了满足其他国家,各个国家纷纷定制了自己的编码 9 日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里 10 11 #阶段三:各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。如何解决这个问题呢??? 12 13 #!!!!!!!!!!!!非常重要!!!!!!!!!!!! 14 说白了乱码问题的本质就是不统一,如果我们能统一全世界,规定全世界只能使用一种文字符号,然后统一使用一种编码,那么乱码问题将不复存在, 15 ps:就像当年秦始皇统一中国一样,书同文车同轨,所有的麻烦事全部解决 16 很明显,上述的假设是不可能成立的。很多地方或老的系统、应用软件仍会采用各种各样的编码,这是历史遗留问题。于是我们必须找出一种解决方案或者说编码方案,需要同时满足: 17 #1、能够兼容万国字符 18 #2、与全世界所有的字符编码都有映射关系,这样就可以转换成任意国家的字符编码 19 20 这就是unicode(定长), 统一用2Bytes代表一个字符, 虽然2**16-1=65535,但unicode却可以存放100w+个字符,因为unicode存放了与其他编码的映射关系,准确地说unicode并不是一种严格意义上的字符编码表,下载pdf来查看unicode的详情: 21 链接:https://pan.baidu.com/s/1dEV3RYp 22 23 很明显对于通篇都是英文的文本来说,unicode的式无疑是多了一倍的存储空间(二进制最终都是以电或者磁的方式存储到存储介质中的) 24 25 于是产生了UTF-8(可变长,全称Unicode Transformation Format),对英文字符只用1Bytes表示,对中文字符用3Bytes,对其他生僻字用更多的Bytes去存 26 27 28 #总结:内存中统一采用unicode,浪费空间来换取可以转换成任意编码(不乱码),硬盘可以采用各种编码,如utf-8,保证存放于硬盘或者基于网络传输的数据量很小,提高传输效率与稳定性。 29 30 !!!重点!!!
基于目前的现状,内存中的编码固定就是unicode,我们唯一可变的就是硬盘的上对应的字符编码。
此时你可能会觉得,那如果我们以后开发软时统一都用unicode编码,那么不就都统一了吗,关于统一这一点你的思路是没错的,但我们不可会使用unicode编码来编写程序的文件,因为在通篇都是英文的情况下,耗费的空间几乎会多出一倍,这样在软件读入内存或写入磁盘时,都会徒增IO次数,从而降低程序的执行效率。因而我们以后在编写程序的文件时应该统一使用一个更为精准的字符编码utf-8(用1Bytes存英文,3Bytes存中文),再次强调,内存中的编码固定使用unicode。
1、在存入磁盘时,需要将unicode转成一种更为精准的格式,utf-8:全称Unicode Transformation Format,将数据量控制到最精简
2、在读入内存时,需要将utf-8转成unicode
所以我们需要明确:内存中用unicode是为了兼容万国软件,即便是硬盘中有各国编码编写的软件,unicode也有相对应的映射关系,但在现在的开发中,程序员普遍使用utf-8编码了,估计在将来的某一天等所有老的软件都淘汰掉了情况下,就可以变成:内存utf-8<->硬盘utf-8的形式了。
文件处理
1 文件操作
一 介绍
计算机系统分为:计算机硬件,操作系统,应用程序三部分。
我们用python或其他语言编写的应用程序若想要把数据永久保存下来,必须要保存于硬盘中,这就涉及到应用程序要操作硬件,众所周知,应用程序是无法直接操作硬件的,这就用到了操作系统。操作系统把复杂的硬件操作封装成简单的接口给用户/应用程序使用,其中文件就是操作系统提供给应用程序来操作硬盘虚拟概念,用户或应用程序通过操作文件,可以将自己的数据永久保存下来。
有了文件的概念,我们无需再去考虑操作硬盘的细节,只需要关注操作文件的流程:
1 打开文件,得到文件句柄并赋值给一个变量 2 通过句柄对文件进行操作 3 关闭文件
二 在python中
#1. 打开文件,得到文件句柄并赋值给一个变量 f=open('a.txt','r',encoding='utf-8') #默认打开模式就为r #2. 通过句柄对文件进行操作 data=f.read() #3. 关闭文件 f.close()
f=open('a.txt','r')的过程分析
#1、由应用程序向操作系统发起系统调用open(...) #2、操作系统打开该文件,并返回一个文件句柄给应用程序 #3、应用程序将文件句柄赋值给变量f
三 要注意两点!!!
1 打开一个文件包含两部分资源:操作系统级打开的文件+应用程序的变量。在操作完毕一个文件时,必须把与该文件的这两部分资源一个不落地回收,回收方法为: 2 1、f.close() #回收操作系统级打开的文件 3 2、del f #回收应用程序级的变量 4 5 其中del f一定要发生在f.close()之后,否则就会导致操作系统打开的文件还没有关闭,白白占用资源, 6 而python自动的垃圾回收机制决定了我们无需考虑del f,这就要求我们,在操作完毕文件后,一定要记住f.close() 7 8 虽然我这么说,但是很多同学还是会很不要脸地忘记f.close(),对于这些不长脑子的同学,我们推荐傻瓜式操作方式:使用with关键字来帮我们管理上下文 9 with open('a.txt','w') as f: 10 pass 11 12 with open('a.txt','r') as read_f,open('b.txt','w') as write_f: 13 data=read_f.read() 14 write_f.write(data) 15 复制代码
1 f=open(...)是由操作系统打开文件,那么如果我们没有为open指定编码,那么打开文件的默认编码很明显是操作系统说了算了,操作系统会用自己的默认编码去打开文件,在windows下是gbk,在linux下是utf-8。 2 这就用到了上节课讲的字符编码的知识:若要保证不乱码,文件以什么方式存的,就要以什么方式打开。 3 4 f=open('a.txt','r',encoding='utf-8')
四 python2中的file与open
1 #首先在python3中操作文件只有一种选择,那就是open() 2 3 #而在python2中则有两种方式:file()与open() 4 两者都能够打开文件,对文件进行操作,也具有相似的用法和参数,但是,这两种文件打开方式有本质的区别,file为文件类,用file()来打开文件,相当于这是在构造文件类,而用open()打开文件,是用python的内建函数来操作,我们一般使用open()打开文件进行操作,而用file当做一个类型,比如type(f) is file
2 打开文件的模式
文件句柄 = open('文件路径', '模式')
模式可以是以下方式以及他们之间的组合:
| Character | Meaning |
| ‘r' | open for reading (default) |
| ‘w' | open for writing, truncating the file first |
| ‘a' | open for writing, appending to the end of the file if it exists |
| ‘b' | binary mode |
| ‘t' | text mode (default) |
| ‘+' | open a disk file for updating (reading and writing) |
| ‘U' | universal newline mode (for backwards compatibility; should not be used in new code) |
1 #1. 打开文件的模式有(默认为文本模式): 2 r ,只读模式【默认模式,文件必须存在,不存在则抛出异常】 3 w,只写模式【不可读;不存在则创建;存在则清空内容】 4 a, 之追加写模式【不可读;不存在则创建;存在则只追加内容】 5 6 #2. 对于非文本文件,我们只能使用b模式,"b"表示以字节的方式操作(而所有文件也都是以字节的形式存储的,使用这种模式无需考虑文本文件的字符编码、图片文件的jgp格式、视频文件的avi格式) 7 rb 8 wb 9 ab 10 注:以b方式打开时,读取到的内容是字节类型,写入时也需要提供字节类型,不能指定编码 11 12 #3. 了解部分 13 "+" 表示可以同时读写某个文件 14 r+, 读写【可读,可写】 15 w+,写读【可读,可写】 16 a+, 写读【可读,可写】 17 18 19 x, 只写模式【不可读;不存在则创建,存在则报错】 20 x+ ,写读【可读,可写】 21 xb
了解u模式和换行符
# U模式 'U' mode is deprecated and will raise an exception in future versions of Python. It has no effect in Python 3. Use newline to control universal newlines mode. # 总结: 在python3中使用默认的newline=None即可,换行符无论何种平台统一用\n即可
三 操作文件的方法
1 #要记住哦 2 f.read() #读取所有内容,光标移动到文件末尾 3 f.readline() #读取一行内容,光标移动到第二行首部 4 f.readlines() #读取每一行内容,存放于列表中 5 6 f.write('1111\n222\n') #针对文本模式的写,需要自己写换行符 7 f.write('1111\n222\n'.encode('utf-8')) #针对b模式的写,需要自己写换行符 8 f.writelines(['333\n','444\n']) #文件模式 9 f.writelines([bytes('333\n',encoding='utf-8'),'444\n'.encode('utf-8')]) #b模式 10 11 #了解 12 f.readable() #文件是否可读 13 f.writable() #文件是否可读 14 f.closed #文件是否关闭 15 f.encoding #如果文件打开模式为b,则没有该属性 16 f.flush() #立刻将文件内容从内存刷到硬盘 17 f.name
四 文件内光标移动
一: read(3):
1. 文件打开方式为文本模式时,代表读取3个字符
2. 文件打开方式为b模式时,代表读取3个字节
二: 其余的文件内光标移动都是以字节为单位如seek,tell,truncate
注意:
1. seek有三种移动方式0,1,2,其中1和2必须在b模式下进行,但无论哪种模式,都是以bytes为单位移动的
2. truncate是截断文件,所以文件的打开方式必须可写,但是不能用w或w+等方式打开,因为那样直接清空文件了,所以truncate要在r+或a或a+等模式下测试效果
五 文件的修改
文件的数据是存放于硬盘上的,因而只存在覆盖、不存在修改这么一说,我们平时看到的修改文件,都是模拟出来的效果,具体的说有两种实现方式:
方式一:将硬盘存放的该文件的内容全部加载到内存,在内存中是可以修改的,修改完毕后,再由内存覆盖到硬盘(word,vim,nodpad++等编辑器)
1 import os 2 3 with open('a.txt') as read_f,open('.a.txt.swap','w') as write_f: 4 data=read_f.read() #全部读入内存,如果文件很大,会很卡 5 data=data.replace('alex','SB') #在内存中完成修改 6 7 write_f.write(data) #一次性写入新文件 8 9 os.remove('a.txt') 10 os.rename('.a.txt.swap','a.txt') 11 复制代码
方式二:将硬盘存放的该文件的内容一行一行地读入内存,修改完毕就写入新文件,最后用新文件覆盖源文件
1 import os 2 3 with open('a.txt') as read_f,open('.a.txt.swap','w') as write_f: 4 for line in read_f: 5 line=line.replace('alex','SB') 6 write_f.write(line) 7 8 os.remove('a.txt') 9 os.rename('.a.txt.swap','a.txt')
