prometheus matil 日志监控错误信息,实现日志报错监控及告警
1、部署Prometheus
2、Mtail 日志监控
简介
mtail日志处理器是由Google的SRE人员编写的,其采用Apache 2.0许可证,并且使用Go语言。mtail日志处理器专门用于从应用程序日志中提取要导出到时间序列数据库中的指标
Mtail的工作原理基于用户定义的正则表达式。用户可以编写自定义的规则,根据这些规则,mtail从日志文件中提取关键信息,并生成指标。这些指标可以实时反映系统的状态和性能,帮助管理员和开发人员更好地理解和优化系统。 Mtail的使用非常灵活,它支持多种配置选项,包括指定监控的日志文件列表、自定义监控指标以及设置监听端口等。启动后,mtail会自动监听一个端口,并在该端口的/metrics接口暴露符合Prometheus协议的监控数据。这样,其他工具如Prometheus就可以从这个接口提取监控数据,进行进一步的分析和告警。
此外,由于mtail轻量级的特性,它特别适合用于资源有限的环境,如云环境或边缘计算场景。在这些环境中,mtail可以有效地提取和分析日志数据,帮助用户实时了解系统的运行状况,确保系统的稳定性和可靠性。
总的来说,Mtail是一个功能强大且灵活的日志监控工具,它可以帮助用户从海量的日志数据中提取有价值的信息,为系统的优化和运维提供有力的支持。
部署 mtail
wget https://github.com/google/mtail/releases/download/v3.0.0-rc54/mtail_3.0.0-rc54_linux_amd64.tar.gz mkdir mtail tar xf mtail_3.0.0-rc54_linux_amd64.tar.gz -C mtail/
创建采集prog文件
vim error_count.mtail
counter error_count /ERROR|error|Failed|failed/ { error_count++ }
说明:error_count变量值统计了包含/ERROR|error|Failed|failed/字串的行
启动mtail
./mtail -logtostderr --progs error_count.mtail --logs /data/app/logs/*.log
--progs 指定progs程序
--logs 指定解析的日志文件
--logtostderr 直接输出标准错误信息
查看mtail的相关信息
http://192.168.53.124:3903/
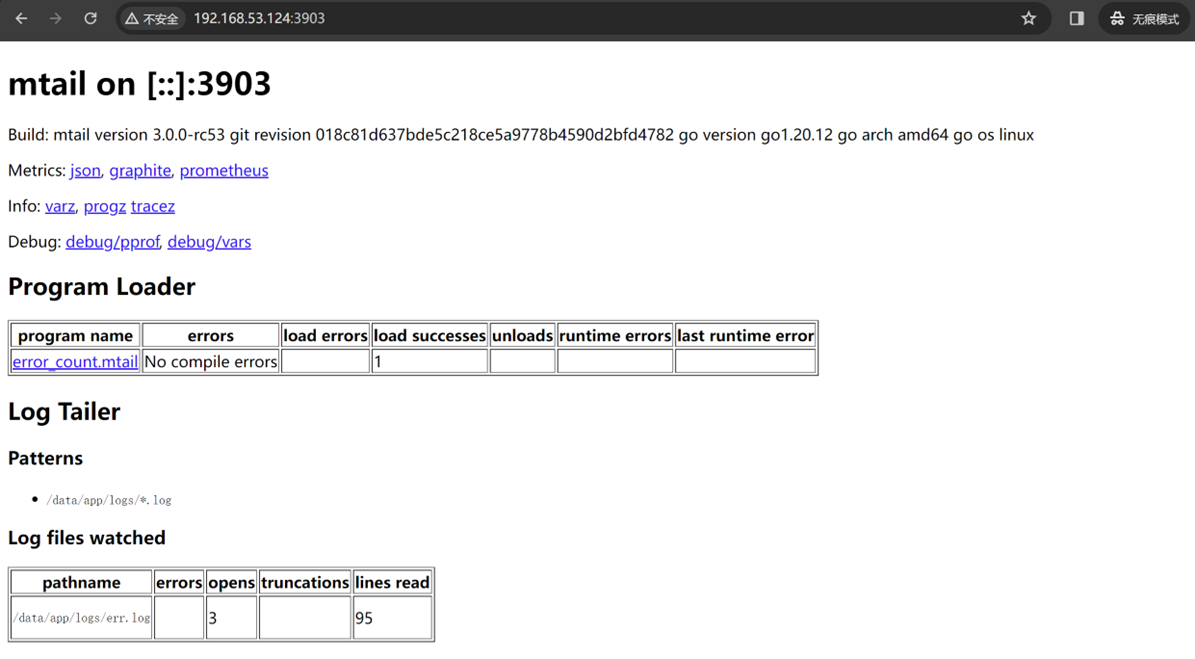
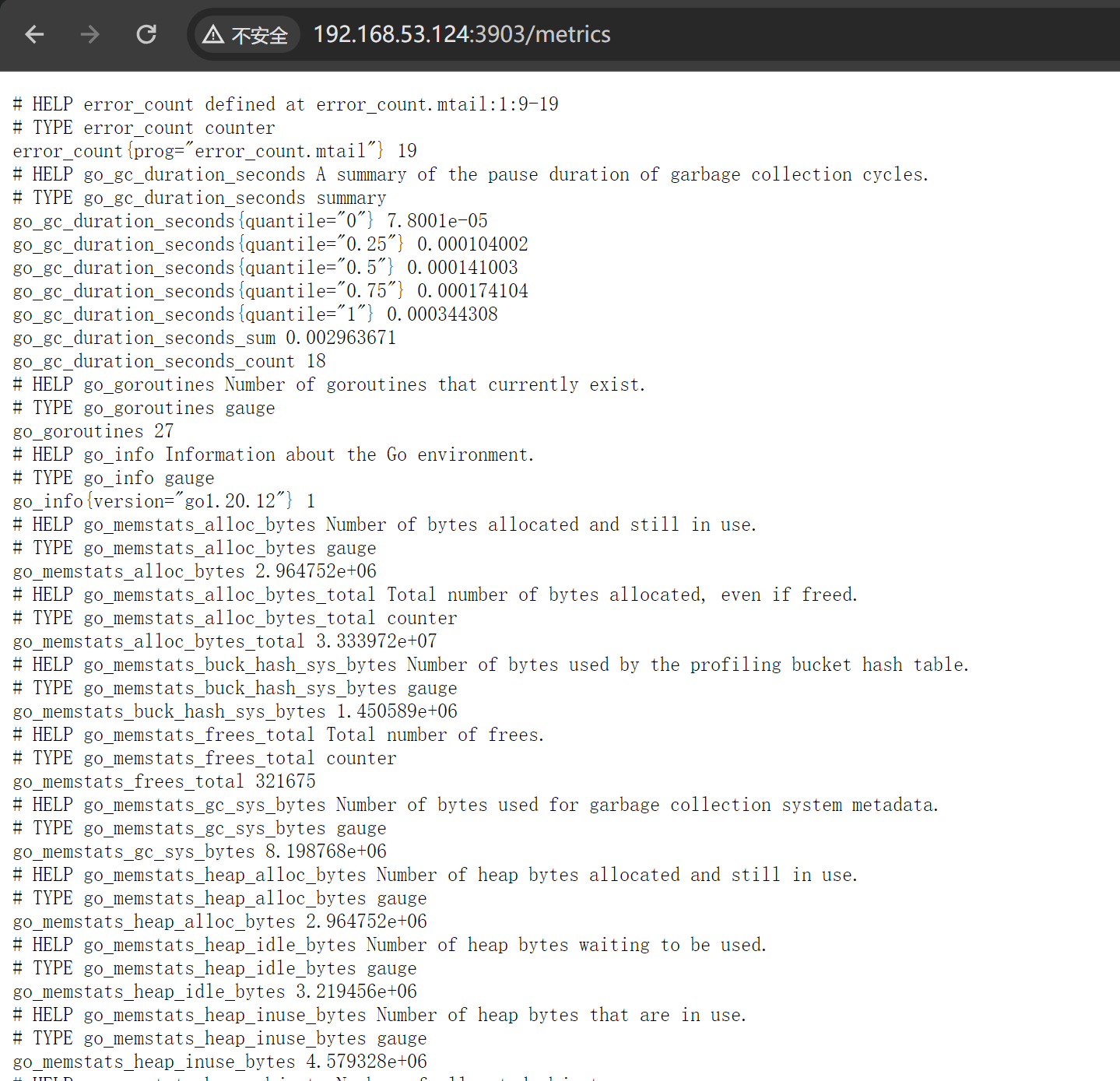
查看mtail输出得metrics
http://192.168.53.124:3903/metrics
Prometheus 集成 mtail
编辑prometheus配置文件
prometheus.yml
- job_name: "mtail" scrape_interval: 60s static_configs: - targets: ['192.168.53.124:3903'] labels: project: mtail
重启prometheus
nohup ./prometheus --config.file=prometheus.yml --web.listen-address=:9001 --storage.tsdb.path="/data/prometheus/prom_data" --storage.tsdb.retention.time=15d &
Prometheus Web 指标查询
error_count{prog="error_count.mtail"} - error_count{prog="error_count.mtail"} offset 3m

Prometheus mtail Rule 文件
groups: - name: 日志监控 rules: - alert: ErrorlogStatus expr: error_count{prog="error_count.mtail"} - error_count{prog="error_count.mtail"} offset 3m >= 2 for: 10s labels: severity: "critical" annotations: description: "{{ $labels.instance }} file [/data/app/logs/err.log] error >=2 current value: {{ $value }}" summary: "{{ $labels.instance }} file [/data/app/logs/err.log] error >=2 current value: {{ $value }}"
"error_count offset 3m >=2" 当前指标减去3分钟之前指标大于等于2触发告警,告警触发后自动恢复
触发告警查看Prometheus 告警

查看告警邮件

mtail官方示例
https://github.com/google/mtail/tree/master/examples
补充:
mtail设置多个变量,统计不同字符串到相关得变量中
示例:
counter http_error_count counter app_error_count /.*ERROR.*|.*error.*|.*Failed.*|.*failed.*/ { http_error_count++ } /.*NULL.*|.*null.*/ { app_error_count++ }
启动mtail
nohup ./mtail -logtostderr --progs error_count.mtail --logs /data/app/logs/*.log &
指定多个日志使用多个 --logs,例如:
./mtail -logtostderr \
--progs error_count.mtail \
--logs /data/app/logs/err.log \
--logs /data/ruoyi/logs/application.log \
修改Prometheus告警规则:mtail_err.yml
groups: - name: http_err rules: - alert: ErrorlogStatus expr: http_error_count{prog="error_count.mtail"} - http_error_count{prog="error_count.mtail"} offset 3m >= 1 for: 10s labels: severity: "critical" annotations: summary: "{{ $labels.instance }} file [/data/app/logs/err.log] error >=2 current value: {{ $value }}" description: "{{ $labels.instance }} file [/data/app/logs/err.log] error >=2 current value: {{ $value }}" - name: app_err rules: - alert: AppErrorCountIncrease expr: app_error_count{prog="error_count.mtail"} - app_error_count{prog="error_count.mtail"} offset 3m >= 1 for: 30s labels: severity: "critical" annotations: summary: App error count has not decreased in the last 3 minutes description: "The app_error_count metric has not shown a decrease over the past 3 minutes. Current value is higher than or equal to the value 3 minutes ago."
重新加载 pormetheus 配置
kill -HUP PID


 浙公网安备 33010602011771号
浙公网安备 33010602011771号