

Elastic Stack部署
1、Elastic Stack简介
Elastic Stack早期名字叫ELK,是由三个开源软件组成得数据处理框架,后期由于有新的成员加入到ELK中,ELK更名为Elastic Stack以反映其组成成员得变化情况。
Elastic Stack主要组件如下:
Elasticsearch:用来数据检索和存储
Logstash:用来数据传输与清洗
Kibana:用于数据展示,数据可视化等领域
Beats:专门用于数据传送得轻量级组件,logstash是基于java语言开发,运行需要java环境,beats则不同,由go语言开发,更加轻量级,可以将网络、日志、指标、审计等各种数据从不同得数据源头发送到Logstash或者Elasticsearch
现在Elasticsearch、Logstash、Kibana、Beats作为一个整体,目的依然是要提供一套整体处理数据得解决方案,包括数据得收集、清洗、整理、传输、存储、检索、应用等各个方面
2、elasticsearch安装部署
2.1 安装准备
elasticsearch基于java语言开发,所以在安装elasticsearch之前,首先要安装jdk,elasticsearch7版本以上都要求jdk1.8以上版本,推荐版本为OracleJDK1.8.0_131,需要注意,elasticsearch默认是集群模式部署,会存在主分片和副本分片,且两个分片不会存在一个服务节点上,推荐部署elasticsearch部署两台以上的服务器
elk官方下载地址:https://www.elastic.co/cn/downloads/
2.2 创建普通用户及用户组
groupadd elasticsearch
useradd elasticsearch -g elasticsearch
2.3 修改系统参数
修改最大连接数,/etc/security/limits.conf中添加两行
* soft nofile 65536 * hard nofile 65536 * soft nproc 32000 * hard nproc 32000 * hard memlock unlimited * soft memlock unlimited
2.4 调整虚拟内存vm.max_map_count大小
修改/etc/sysctl.conf文件,添加下面一行内容,使其生效
vm.max_map_count=262144
sysctl -p
tar xf elasticsearch-7.12.1-linux-x86_64.tar.gz -C /app mv elasticsearch-7.12.1 elasticsearch chown -R elasticsearch.elasticsearch elasticsearch
2.6 切换用户修改elasticsearch.yml文件,具体配置如下:

cluster.name: my-application #配置es得集群名称,默认是elasticsearch,es会自动发现同一网段下得es,如果在同一网段下有多个集群,就可以用这个属性来区分不同得集群 node.name: node-1 #节点名称,默认随机指定一个name列表中得名字 node.attr.rack: r1 #节点部落属性 node.master: true #指定该节点是都有资格被选举为node,默认伟true,es是默认集群中得第一台机器为master,如果这个太机器挂了就会重新选举master node.data: true #指定该节点是否存储索引数据,默认为true,可以选择false,将数据和路由节点区分开 node.attr.box_type: hot #节点做冷热分离 node.attr.gateway: true bootstrap.memory_lock: false #机制使用内存交换功能,防止性能瓶颈 path.data: /app/elasticsearch/data #数据存储路径 path.logs: /app/elasticsearch/logs #日志存储路径 network.host: 0.0.0.0 #设置节点绑定地址(IPv4 或者 IPv6) http.port: 9200 #设置http访问端口 http.cors.enabled: true http.cors.allow-credentials: true http.cors.allow-origin: "*" #以上三个配置在使用head等插件监控集群信息,需要打开 transport.port: 9300 #数据传输、节点连接端口 discovery.seed_hosts: ["192.168.53.20:9300", "192.168.53.21:9300"] #集群发现 cluster.initial_master_nodes: ["node-1","node-2"] #手动指定可以成为master得所有节点得name或者IP,这些配置将会在第一次选举中进行计算
其他节点参考以上配置,仅需修改node.name与network.host两个配置参数
2.7 服务启动
su - elasticsearch cd /app/elasticsearch/bin ./elasticsearch ./elasticsearch -d #后台启动
2.8 服务验证
浏览器访问IP+端口
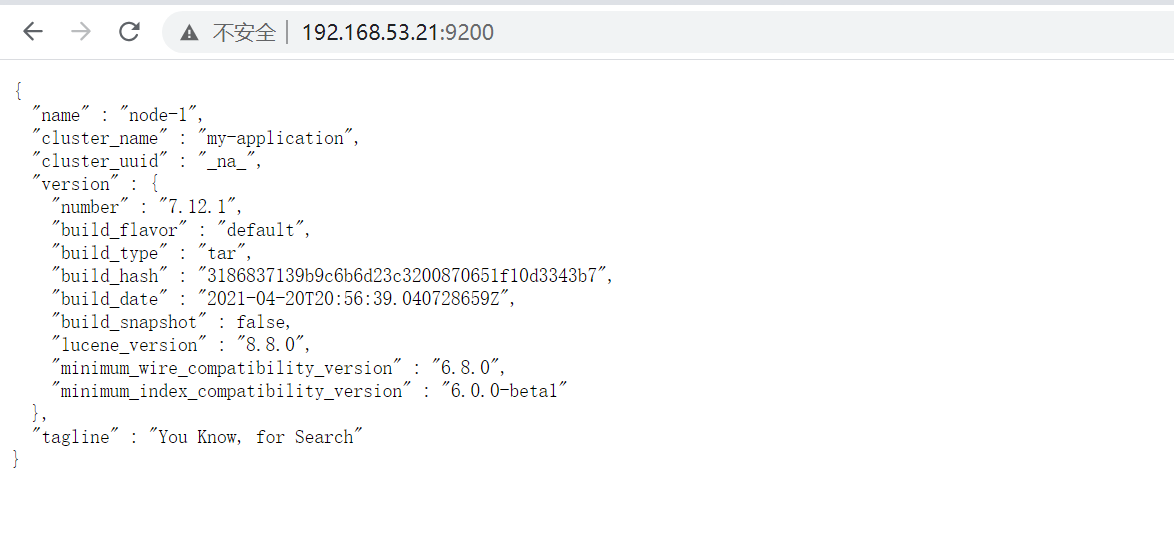
3、elasticsearch-head安装
3.1 elasticsearch-head简介
github地址:https://github.com/mobz/elasticsearch-head
elasticsearch只是后端提供各种api,无法直观使用它,elasticsearch-head将是一款专门针对于elasticsearch的客户端工具,它是一个基于node.js的前端工程,故在部署直线首先要安装node.js
3.2 安装node.js(Linux环境)
#安装包下载 wget https://nodejs.org/dist/v8.11.1/node-v8.11.1-linux-x64.tar.xz #解压 xz node-v8.11.1-linux-x64.tar.xz tar -xvf node-v8.11.1-linux-x64.tar -C /app/ #环境变量配置 vim /etc/profile #添加以下两行 export NODE_HOME=/app/node-v8.11.1-linux-x64 export PATH=$PATH:$NODE_HOME/bin source /etc/profile
3.3 npm安装
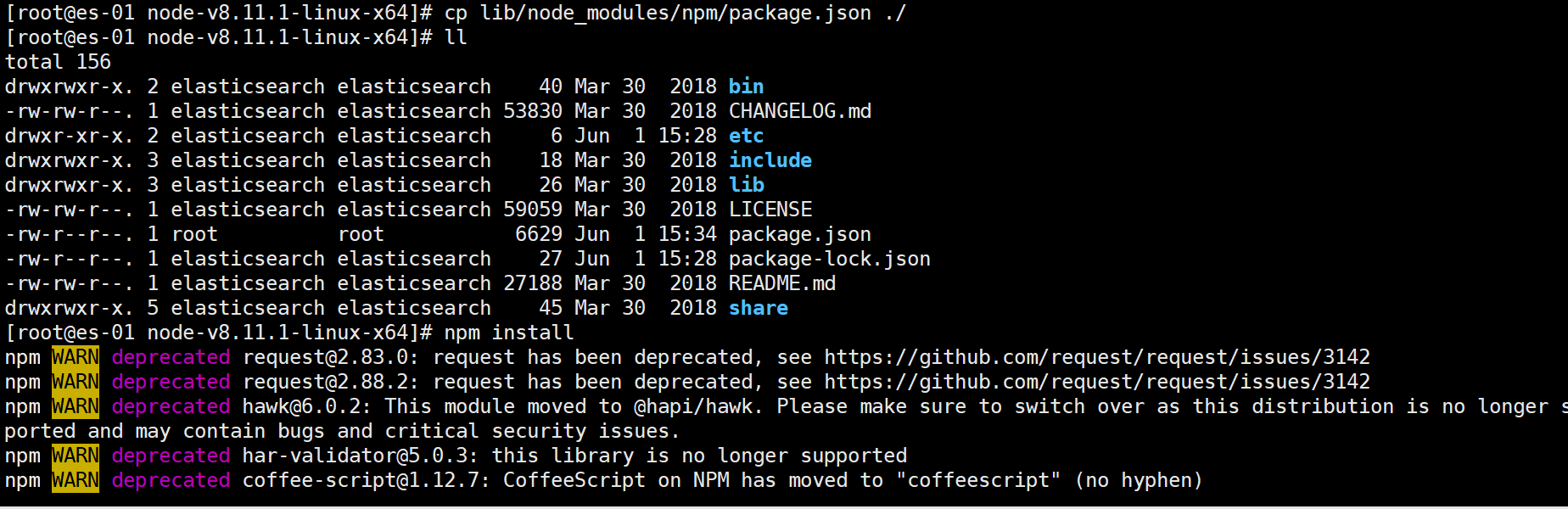
cd /app/node-v8.11.1-linux-x64 npm install
如果出现以下错误:

解决方法如下
find ./ -name package.json cp lib/node_modules/npm/package.json ./
再重新执行npm install即可
grunt工具包安装
[root@es-01 node-v8.11.1-linux-x64]# npm install -g grunt-cli /app/node-v8.11.1-linux-x64/bin/grunt -> /app/node-v8.11.1-linux-x64/lib/node_modules/grunt-cli/bin/grunt + grunt-cli@1.4.3 added 58 packages in 36.27s
检查当前目录npm安装情况
npm list --depth=0
3.4 安装elasticsearch-head
unzip -d elasticsearch-head-master.zip
cd elasticsearch-head/ npm run start
3.6 浏览器验证
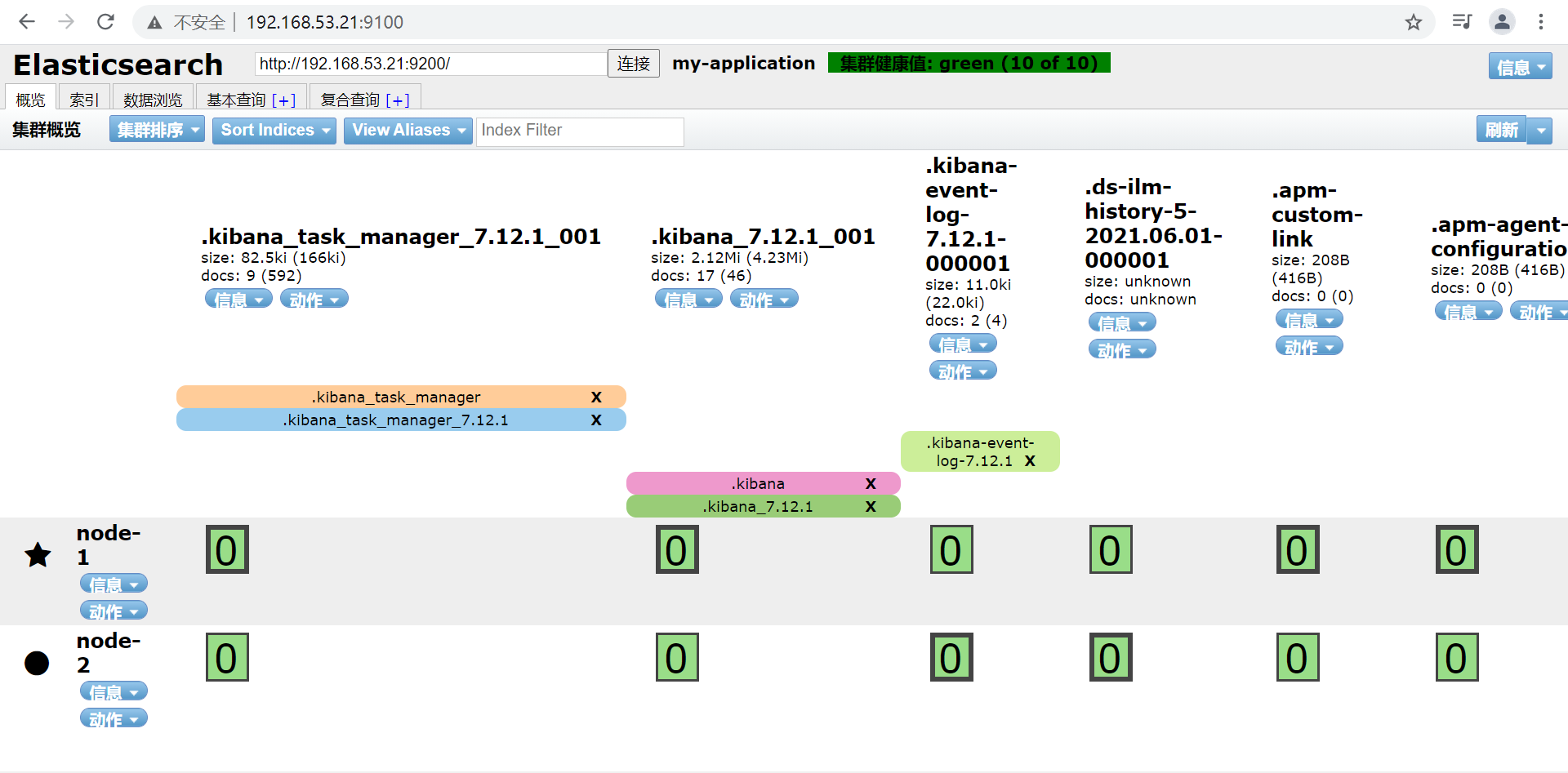
3.7 注意
elasticsearch-head在连接es集群时候,es集群需要添加一下参数配置:
http.cors.enabled: true http.cors.allow-origin: "*"
4、Kibana安装部署
kibana在整个Elastic Stack中起到了数据可视化的作用,也就是通过图、表、统计等方式将复杂的数据以更加直观的形式展示出来,由于kibana运行于Elasticsearch基础之上,所以将kibana视为elasticsearch的用户图形界面
安装前需要先安装jdk(略)
4.3 创建安装用户
groupadd kibana
useradd -g kibana kibana
4.4 安装与配置
安装目录/app
tar xf kibana-7.12.1-linux-x86_64.tar.gz -C /app/ mv kibana-7.12.1-linux-x86_64 kibana
修改文件所属用户用户组
chown -R kibana.kibana kibana
切换至kibana用户修改kibana.yml
su - kibana cd /app/kibana/config vim kibana.yml
具体配置如下:
server.port: 5601 #kibana运行的端口 server.host: "0.0.0.0" #kibana运行对外释放的服务IP elasticsearch.hosts: ["http://192.168.53.21:9200"] #kibana连接ES集群的地址,选择其中一个节点即可 kibana.index: ".kibana" #kibana在ES集群存储数据的索引 i18n.locale: "zh-CN" #kibana的界面汉化
4.5 服务启动
cd /app/kibana/bin
./kibana
4.6 服务验证
5、filebeat安装部署
5.1 filebeat概述
filebeat一般安装于宿主机,用于收集文本型日志数据
5.2 安装filebeat
解压安装包
tar xf filebeat-7.12.1-linux-x86_64.tar.gz mv filebeat-7.12.1-linux-x86_64 filebeat
修改配置文件filebeat.yml
filebeat.inputs: - type: log enabled: true paths: - /var/log/nginx/*.log #- /data/nginx/logs/{{now "yyyy-MM"}}*.log - type: filestream enabled: false paths: - /var/log/*.log filebeat.config.modules: path: ${path.config}/modules.d/*.yml reload.enabled: false setup.template.settings: index.number_of_shards: 1 setup.kibana: host: "192.168.53.23:5601" output.elasticsearch: hosts: ["192.168.53.21:9200"] processors: - add_host_metadata: when.not.contains.tags: forwarded - add_cloud_metadata: ~ - add_docker_metadata: ~ - add_kubernetes_metadata: ~
需要修改的位置不多,这里没有注释或删掉原本没有注释得内容,修改需要收集得日志路径,kibana得地址以及es得地址,也可以先传送到logstash后再由logstash传送给elasticsearch
5.3 服务启动
cd /app/filebeat
./filebeat -e -c filebeat.yml
后台启动filebeat,如果是离线安装得话需要手动编辑/usr/lib/systemd/system/filebeat.service文件,内容如下:
[Unit] Description=filebeat server daemon Documentation=/app/filebeat/filebeat -help Wants=network-online.target After=network-online.target [Service] User=root Group=root Environment="BEAT_CONFIG_OPTS=-c /app/filebeat/filebeat.yml" ExecStart=/app/filebeat/filebeat $BEAT_CONFIG_OPTS Restart=always [Install] WantedBy=multi-user.target
systemctl start filebeat.service
5.4 浏览器验证
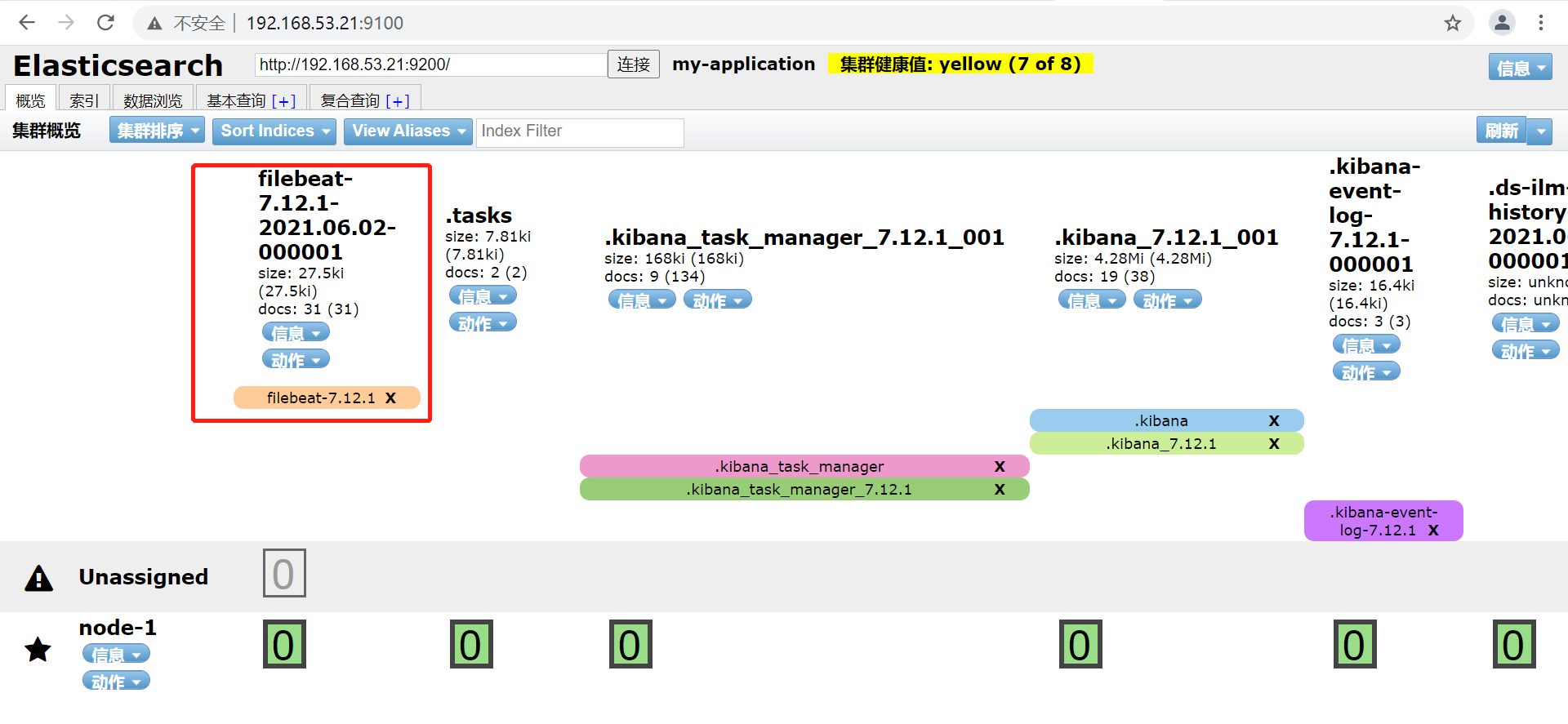
在kibana中添加索引进行展示
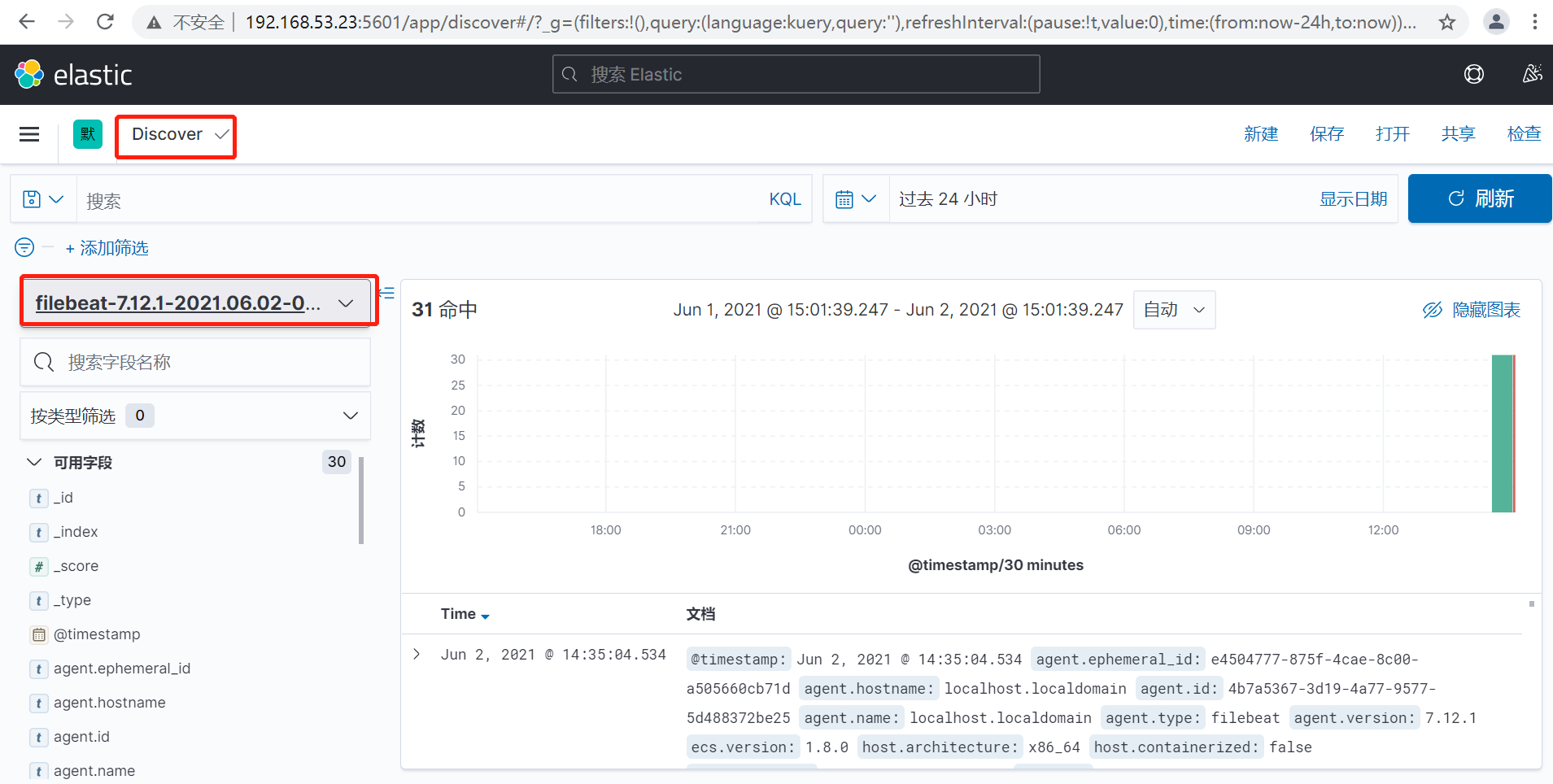
6、Nginx日志收集
6.1 收集nginx日志并且自定义索引名称
修改filebeat.yml文件如下:
filebeat.inputs: - type: log enabled: true paths: - /var/log/nginx/*.log - type: filestream enabled: false paths: - /var/log/*.log filebeat.config.modules: path: ${path.config}/modules.d/*.yml reload.enabled: false setup.template.settings: index.number_of_shards: 1 setup.kibana: host: "192.168.53.23:5601" output.elasticsearch: hosts: ["192.168.53.21:9200"] index: "nginx-%{[agent.version]}-%{+yyyy.MM}" setup.ilm.enabled: false setup.template.eanbled: false setup.template.name: "index" setup.template.pattern: "index-*" logging.level: info logging.to_files: true logging.file: path: /app/filebeat/logs/filebeat name: filebeat keepfiles: 7 permissions: 0644
重新启动filebeat
6.2 浏览器验证
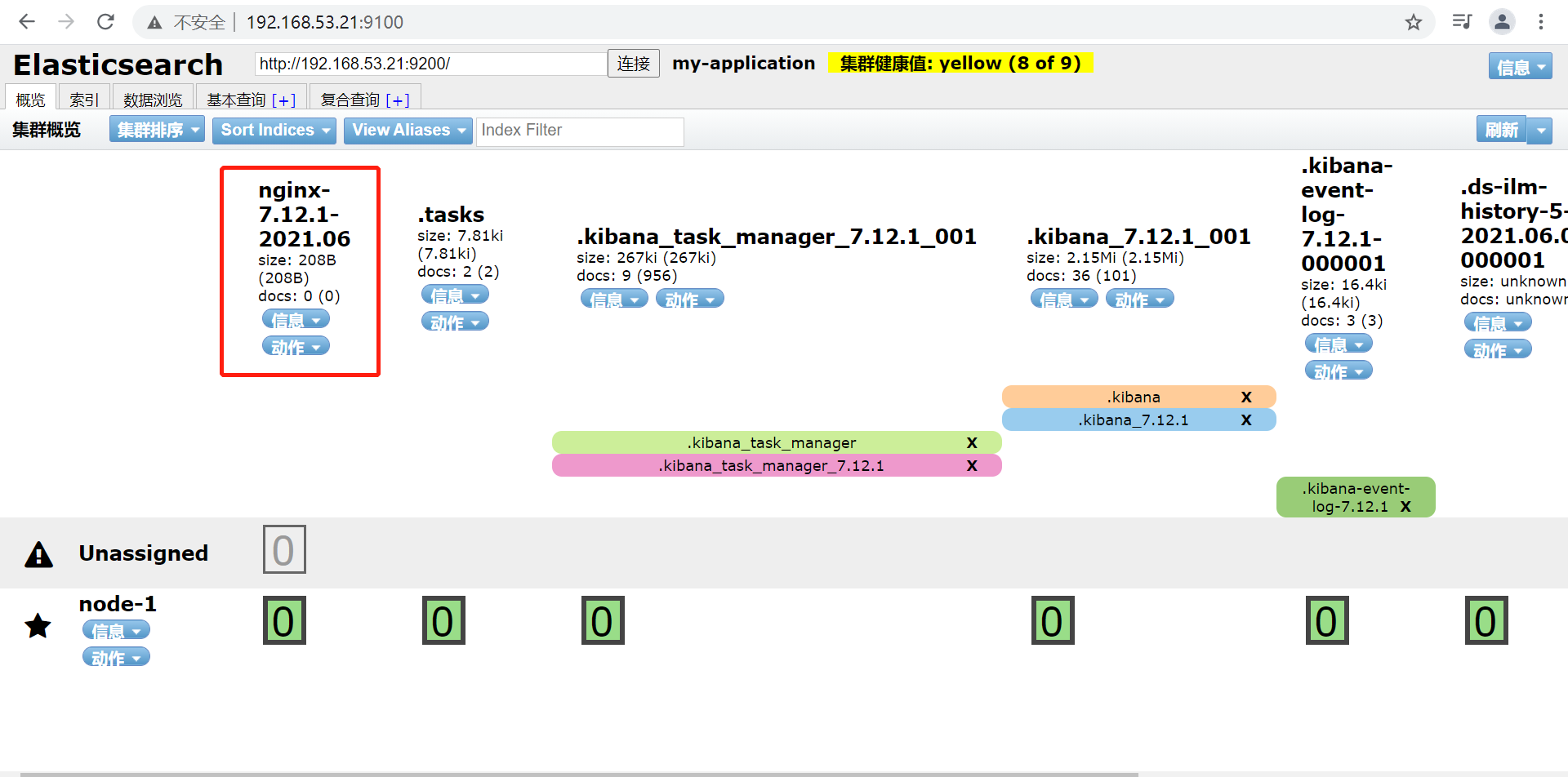
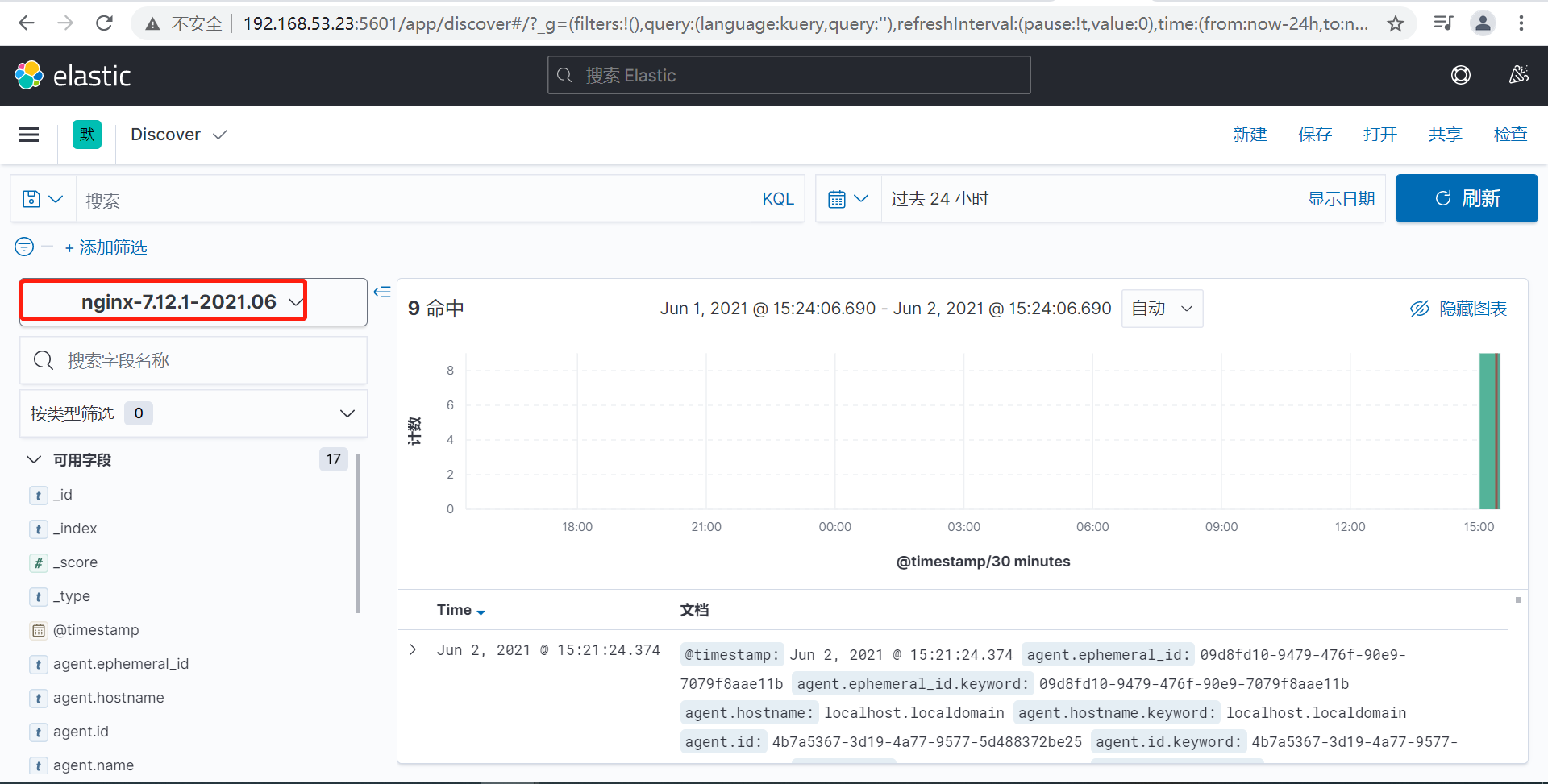
自定义索引名称完成,nginx日志也可定义成json格式进行收集,具体配置如下:
vim nginx.conf
log_format json '{ "time_local": "$time_local", ' '"remote_addr": "$remote_addr", ' '"remote_user": "$remote_user", ' '"referer": "$http_referer", ' '"request": "$request", ' '"status": $status, ' '"bytes": $body_bytes_sent, ' '"agent": "$http_user_agent", ' '"x_forwarded": "$http_x_forwarded_for", ' '"up_addr": "$upstream_addr", ' '"up_host": "$upstream_http_host", ' '"upstream_time": "$upstream_response_time", ' '"request_time": "$request_time"'
'}'; access_log /var/log/nginx/access.log json;
json.keys_under_root: true json.overwite_keys: true
filebeat.inputs: - type: log enabled: true paths: - /var/log/nginx/access.log json.keys_under_root: true json.overwite_keys: true ##......
重新启动nginx和filebeat服务即可
添加可视化,仪表盘
6.3 收集java日志
filebeat.inputs: - type: log enabled: true paths: - /var/log/elasticsearch/elasticsearch.log multiline.pattern: '^\s' ##正则表达式,匹配行 multiline.negate: true multiline.match: after output.elasticsearch: hosts: ["192.168.53.21:9200"] index: "es-%{[agent.version]}-%{+yyyy.MM}" setup.ilm.enabled: false setup.template.enabled: false


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端
· AI Agent开发,如何调用三方的API Function,是通过提示词来发起调用的吗