

python-任务26
python操作数据库读书笔记
使用
1、导入python SQLITE数据库模块
import sqlite3
2、打开数据库
在调用connect函数的时候,指定库名称,如果指定的数据库存在就直接打开这个数据库,如果不存在就新创建一个再打开。
cx=sqlite3.connect("E:/test.db")
3.数据库连接对象
打开数据库时返回的对象cx就是一个数据库连接对象,它可以有以下操作:
① commit()--事务提交
② rollback()--事务回滚
③ close()--关闭一个数据库连接
④ cursor()--创建一个游标
② rollback()--事务回滚
③ close()--关闭一个数据库连接
④ cursor()--创建一个游标
关于commit(),如果isolation_level隔离级别默认,那么每次对数据库的操作,都需要使用该命令,你也可以设置isolation_level=None,这样就变为自动提交模式。
4.使用游标查询数据库
我们需要使用游标对象SQL语句查询数据库,获得查询对象。 通过以下方法来定义一个游标。
cu=cx.cursor()
游标对象有以下的操作:
① execute()--执行sql语句
② executemany--执行多条sql语句
③ close()--关闭游标
④ fetchone()--从结果中取一条记录,并将游标指向下一条记录
⑤ fetchmany()--从结果中取多条记录
⑥ fetchall()--从结果中取出所有记录
⑦ scroll()--游标滚动
② executemany--执行多条sql语句
③ close()--关闭游标
④ fetchone()--从结果中取一条记录,并将游标指向下一条记录
⑤ fetchmany()--从结果中取多条记录
⑥ fetchall()--从结果中取出所有记录
⑦ scroll()--游标滚动
查找广东最好大学排名
import requests from bs4 import BeautifulSoup allUniv=[] def getHTMLText(url): try: r=requests.get(url,timeout=30) r.raise_for_status() r.encoding = 'utf-8' return r.text except: return "" def fillUnivList(soup): data = soup.find_all('tr') for tr in data: ltd = tr.find_all('td') if len(ltd)==0: continue singleUniv = [] for td in ltd: singleUniv.append(td.string) allUniv.append(singleUniv) def printUnivList(num): a="广东" print("{1:^2}{2:{0}^10}{3:{0}^6}{4:{0}^4}{5:{0}^10}".format(chr(12288),"排名","学校名称","省市","总分","科研质量")) for i in range(num): u=allUniv[i] #print(u[1]) if a in u: print("{1:^2}{2:{0}^10}{3:{0}^6}{4:{0}^8.1f}{5:{0}^10}".format(chr(12288),i+1,u[1],u[2],eval(u[3]),u[7])) def main(): url='http://www.zuihaodaxue.cn/zuihaodaxuepaiming2018.html' html = getHTMLText(url) soup = BeautifulSoup(html,"html.parser") fillUnivList(soup) num=len(allUniv) printUnivList(num) main()
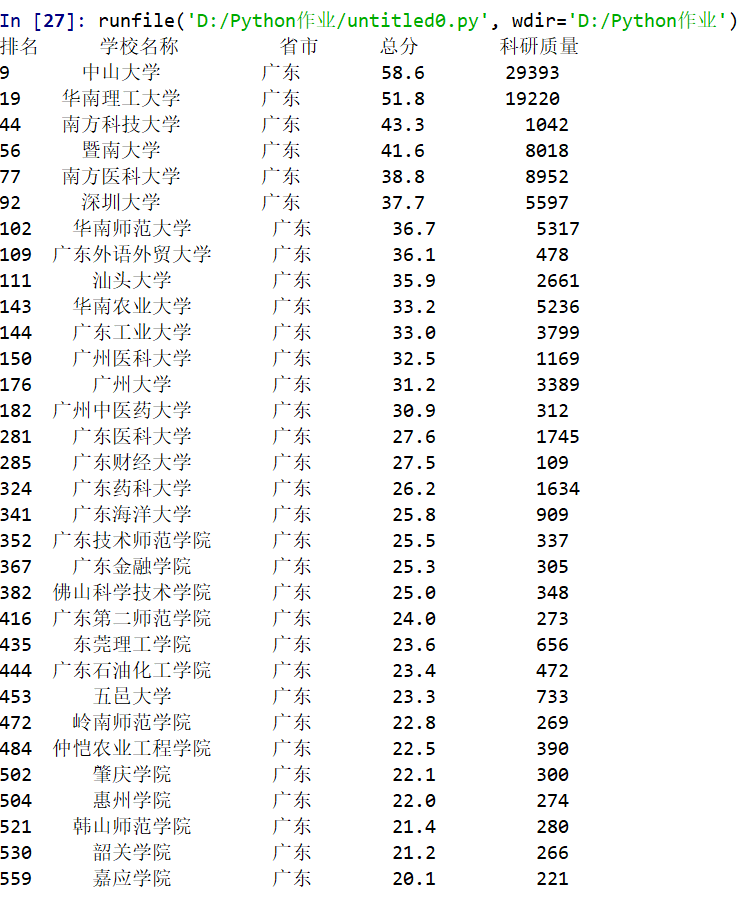
广东技术师范大学的科研质量
import requests from bs4 import BeautifulSoup allUniv=[] def getHTMLText(url): try: r=requests.get(url,timeout=30) r.raise_for_status() r.encoding = 'utf-8' return r.text except: return "" def fillUnivList(soup): data = soup.find_all('tr') for tr in data: ltd = tr.find_all('td') if len(ltd)==0: continue singleUniv = [] for td in ltd: singleUniv.append(td.string) allUniv.append(singleUniv) def printUnivList(num): a="广东技术师范学院" print("{1:^2}{2:{0}^10}{3:{0}^6}{4:{0}^4}{5:{0}^10}".format(chr(12288),"排名","学校名称","省市","总分","科研质量")) for i in range(num): u=allUniv[i] #print(u[1]) if a in u: print("{1:^2}{2:{0}^10}{3:{0}^6}{4:{0}^8.1f}{5:{0}^10}".format(chr(12288),i+1,u[1],u[2],eval(u[3]),u[7])) def main(): url='http://www.zuihaodaxue.cn/zuihaodaxuepaiming2018.html' html = getHTMLText(url) soup = BeautifulSoup(html,"html.parser") fillUnivList(soup) num=len(allUniv) printUnivList(num) main()


