

基本和第一个一样的流程
cuda环境安装教程
https://www.cnblogs.com/gooutlook/p/17677113.html
下载工程
git clone https://github.com/graphdeco-inria/reduced-3dgs --recursive
工程环境 安装指令
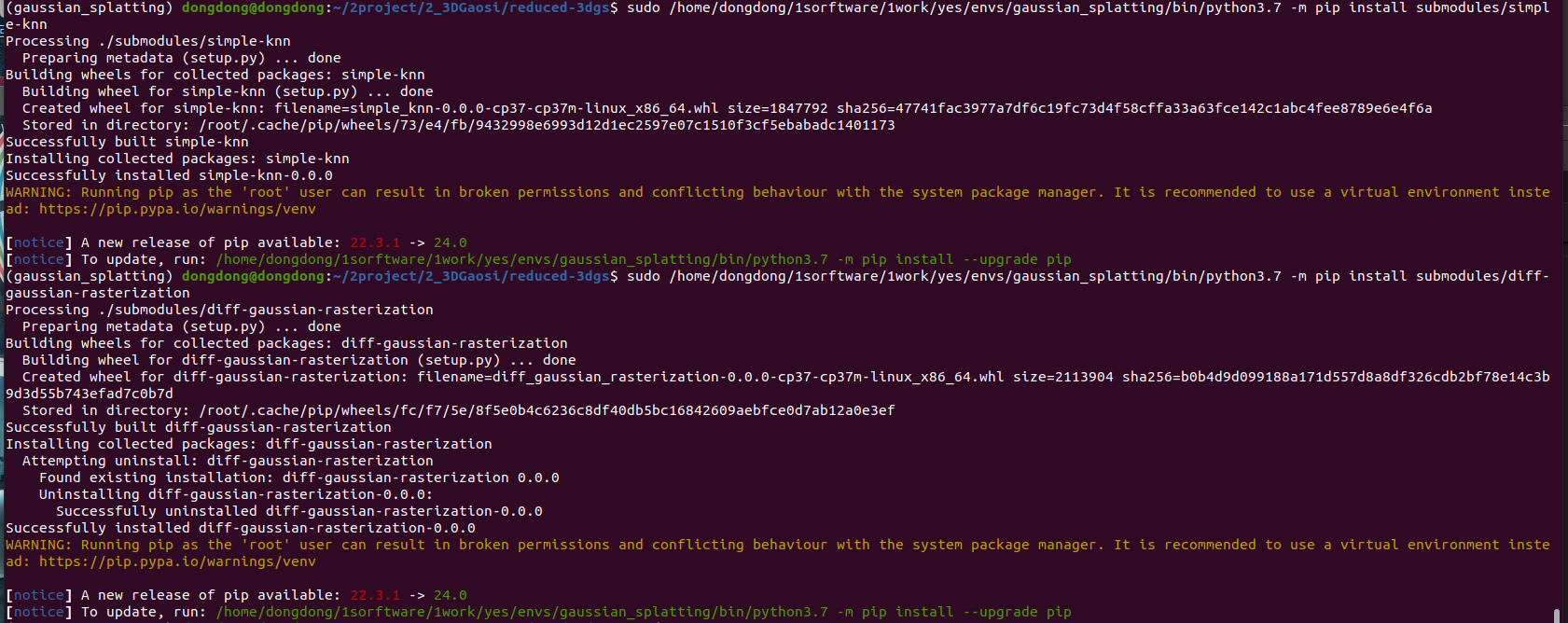
# 官网 https://github.com/graphdeco-inria/reduced-3dgs # ============= 1从文件创建环境 ============ 容易在submodules安装时候报错卡死 conda env create --file environment.yml # 删除环境指令(如果需要) conda env remove --name gaussian_splatting # ============= 2手动创建 =================== # 2-1 创建环境 conda create --name gaussian_splatting # 2-2 激活环境 conda activate gaussian_splatting # 2-3 安装在线库 pip install --upgrade setuptools wheel pip install --upgrade pip==22.3.1 pip install plyfile pip install tqdm pip install urllib3==2.2.1 pip install pandas pip install torch==1.12.1+cu116 torchaudio==0.12.1+cu116 torchvision==0.13.1+cu116 -f https://download.pytorch.org/whl/torch_stable.html # 2-4 安装离线库 代码文件夹自带的库 #pip install ./submodules/diff-gaussian-rasterization 无效 #pip install ./submodules/simple-knn 无效 # 需要用sudo 模式 指定目标环境的python去安装 sudo /home/dongdong/1sorftware/1work/yes/envs/gaussian_splatting/bin/python3.7 -m pip install submodules/simple-knn sudo /home/dongdong/1sorftware/1work/yes/envs/gaussian_splatting/bin/python3.7 -m pip install submodules/diff-gaussian-rasterization # 0查看内存情况====================== watch -n 1 nvidia-smi # 1激活环境========================== conda activate py37gaosi 老版本 conda activate gaussian_splatting 最新版本 # 2训练============================= 训练时候 其他占用显卡内存的软件需要关掉例如colmap 不然内存会爆满 # 2-1 最简单的训练指令 python ./train.py -s ../data/tandt/truck/ -m ../data/tandt/truck/train_out/ # 2-2 指定参数的训练指令 # --resolution / -r 1 参数 2 原来图像的1/2分辨率 。 参数 -1 如果超过1600分辨率, 默认强行缩放,除非指定参数为1才是原分辨率 # -s 数据文件夹 # --model-path / -m 训练结果存放位置 # --data_device cpu gpu 选择训练模式 # --sh_degree 0 所要使用的球谐函数的阶数(不大于 3)。3默认情况下。 给成0 减少内存 # 还可以尝试设置--test_iterations为-1以避免测试期间内存峰值 默认是7000和30000轮次测试一次 # --data_device cuda 或者 cpu // cuda默认使用。 如果使用 cpu 这将减少 VRAM 消耗,但会稍微减慢训练速度。 # --iterations 最大训练次数 默认30000 且 默认7000,30000次保存模型和测试模型 # --test_iterations 默认7000 30000测试数据 给-1 可以执行不测试,从而减少瞬间显卡内存峰值占用,以免显卡内存不够爆了 python ./train.py -s /home/dongdong/2project/0data/NWPU_cplmap/ -m /home/dongdong/2project/0data/NWPU_cplmap/train_out/ --resolution 1 --data_device cpu --sh_degree 3 --iterations 7100 # 3可视化============================== # 3-1 训练过程中查看 sudo ./SIBR_viewers/install/bin/SIBR_remoteGaussian_app # 3-2 代码渲染图 # --models baseline 使用标准的模型渲染(相对于降低一半精度的quantised_half) # -m <训练好的模型路径> # -iteration -1 <使用哪一轮训练的模型> 默认 -1 训练次数最大的模型 # --skip_train 0 跳过训练集的图像渲染 默认0 渲染 # python ./render.py -m /home/dongdong/2project/0data/NWPU_cplmap/train_out_v1_sh0_num30000/ --models baseline # 3-2 训练以后查看 # --模型路径 / -m # --iteration 使用哪一轮训练的模型 默认 -1 训练次数最大的模型 cd /home/dongdong/2project/2_3DGaosi/gaussian-splatting sudo ./SIBR_viewers/install/bin/SIBR_gaussianViewer_app -m /home/dongdong/2project/0data/NWPU_cplmap/train_out/
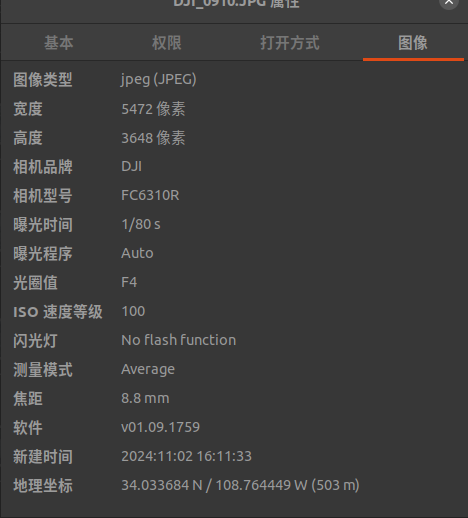
python ./train.py -s /home/dongdong/2project/0data/RTK/300_400 -m /home/dongdong/2project/0data/RTK/300_400/gs_out --resolution 3 --data_device cpu --sh_degree 0 --iterations 30010

编译可视化软件
参考教程
https://www.cnblogs.com/gooutlook/p/17677113.html
1编译前注销conda环境,不然会干扰库的查找。
# Dependencies sudo apt install -y libglew-dev libassimp-dev libboost-all-dev libgtk-3-dev libopencv-dev libglfw3-dev libavdevice-dev libavcodec-dev libeigen3-dev libxxf86vm-dev libembree-dev # Project setup cd SIBR_viewers cmake -Bbuild . -DCMAKE_BUILD_TYPE=Release # add -G Ninja to build faster cmake --build build -j24 --target install
修稿后的编译指令
下载 embree-3.13.5.x86_64 指定路径
cmake -Bbuild . -D embree_DIR=/home/dongdong/2project/2_3DGaosi/reduced-3dgs/SIBR_viewers/embree-3.13.5.x86_64.linux/lib/cmake/embree-3.13.5/ -DCMAKE_BUILD_TYPE=Release
编译前注销conda环境
ctrl+h 显示隐藏文件
问题1
如果opencv不是安装在默认系统环境,手动指定
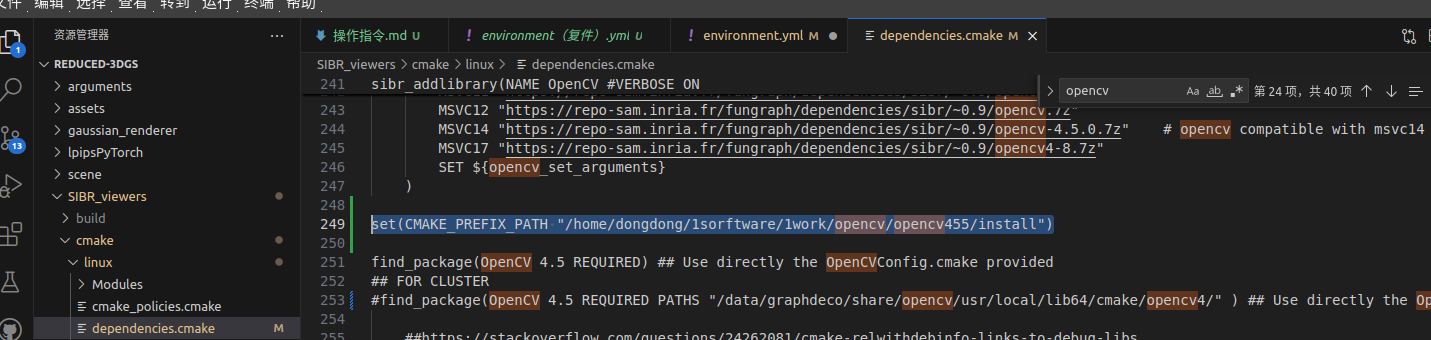
set(CMAKE_PREFIX_PATH "/home/dongdong/1sorftware/1work/opencv/opencv455/install")
opencv 安装路径
问题2 如果找不到eigen3
eigen3默认装在
include_directories("/usr/local/include/eigen3")
问题3 MeshData::setTransformation 报错
error: cannot bind non-const lvalue reference of type ‘sibr::Matrix4f&’ {aka ‘Eigen::Matrix<float, 4, 4, 2>&’} to an rvalue of type ‘sibr::Matrix4f’ {aka ‘Eigen::Matrix<float, 4, 4, 2>’}
这个错误表明你尝试将一个右值绑定到一个非const的左值引用上。在C++中,非const的左值引用不能绑定到右值。你可以尝试以下几种方法解决这个问题:
-
将引用改为const左值引用:如果你只需读取对象,可以使用const左值引用。
修改MeshData::setTransformation 函数 添加const修饰符号
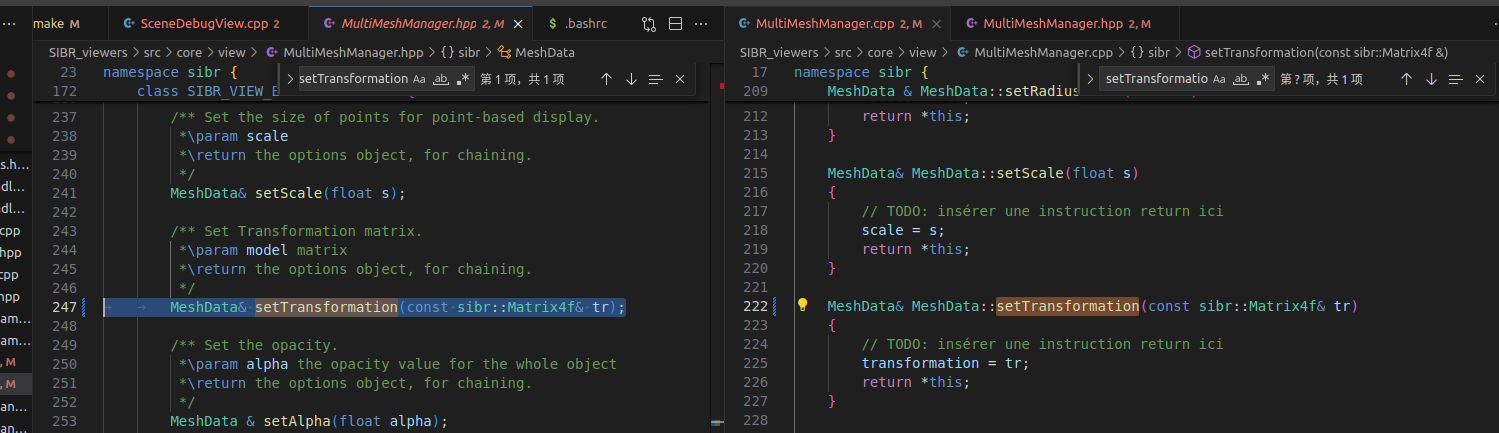
MeshData& MeshData::setTransformation(const sibr::Matrix4f& tr)
{
// TODO: insérer une instruction return ici
transformation = tr;
return *this;
}
编译成功
但是运行报错
但是可以直接查看第一个版本生成的模型
第二个版本的模型,貌似带球鞋系数=3的才能查看

python ./render.py -m /home/dongdong/2project/0data/RTK/300_400/gs_out --iteration 30000 --models baseline
自己写的简易版本查看器
训练好的模型路径
要使用的迭代次数
要使用的模型质量
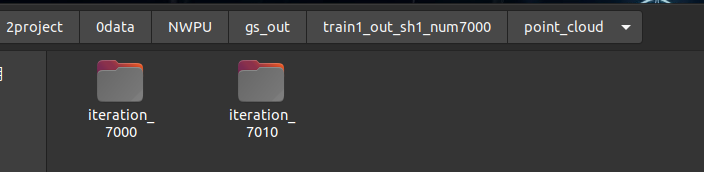
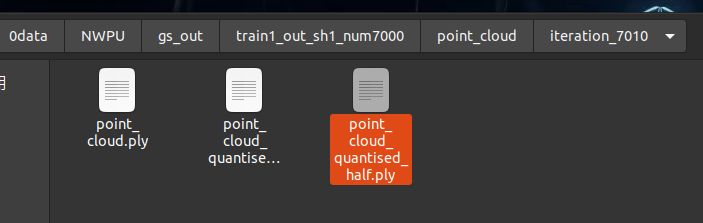
# 773.5 MB - 2.33G -5.48G 峰值 4.6G python ./render.py -m /home/dongdong/2project/0data/NWPU/gs_out/train1_out_sh1_num7000/ --iteration 7010 --models baseline # 269.1 MB - 2.454G -5.48G 峰值 4.6G python ./render.py -m /home/dongdong/2project/0data/NWPU/gs_out/train1_out_sh1_num7000/ --iteration 7010 --models quantised # 218.6 MB - 2.454G -5.48G 峰值 4.6G python ./render.py -m /home/dongdong/2project/0data/NWPU/gs_out/train1_out_sh1_num7000/ --iteration 7010 --models quantised_half
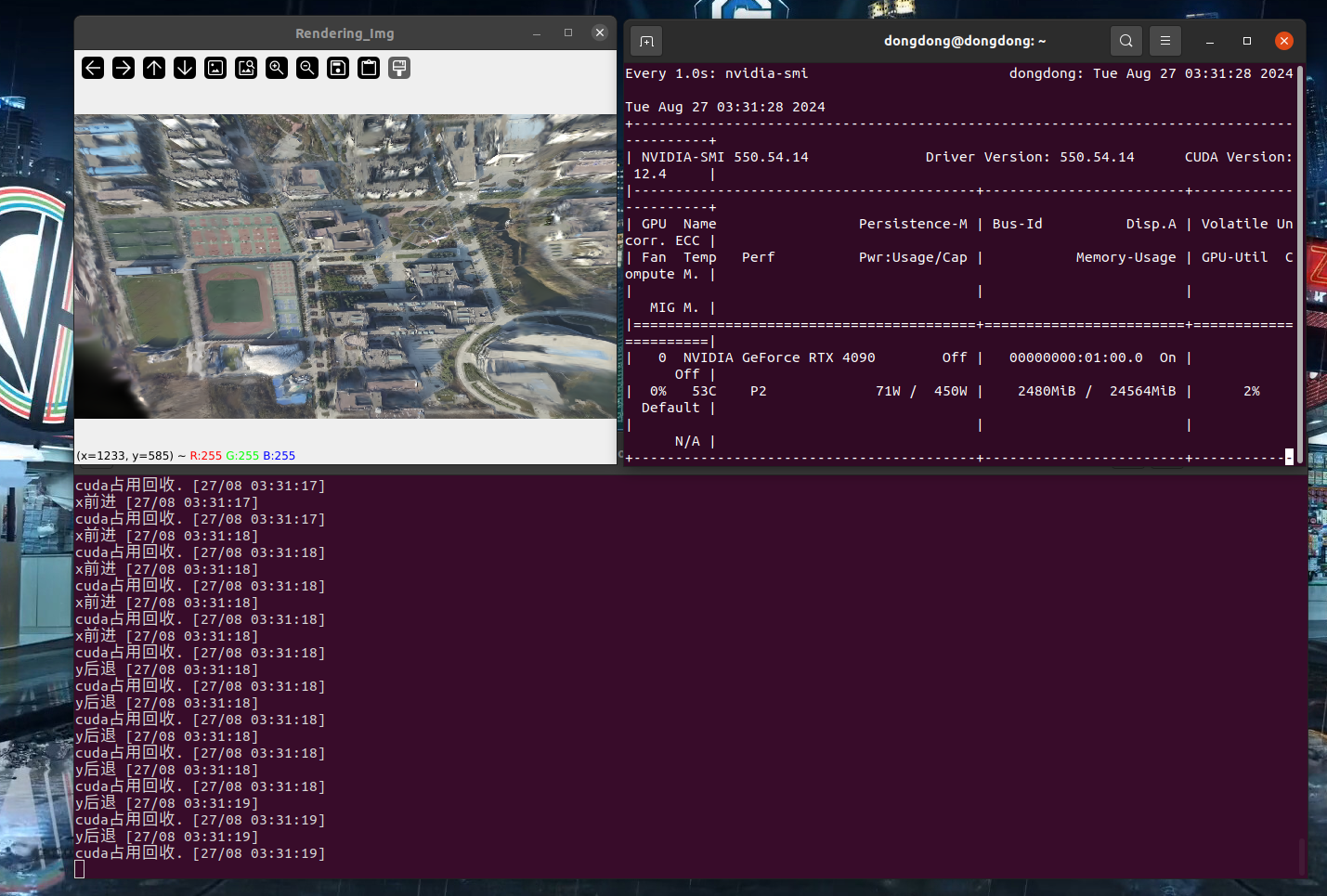
手动调整位置
#
# Copyright (C) 2023, Inria
# GRAPHDECO research group, https://team.inria.fr/graphdeco
# All rights reserved.
#
# This software is free for non-commercial, research and evaluation use
# under the terms of the LICENSE.md file.
#
# For inquiries contact george.drettakis@inria.fr
#
import cv2
import numpy as np
import torch
from scene import Scene
import os
from tqdm import tqdm
from os import makedirs
from gaussian_renderer import render
import torchvision
from utils.general_utils import safe_state
from argparse import ArgumentParser
from arguments import ModelParams, PipelineParams, get_combined_args
from gaussian_renderer import GaussianModel
import pandas as pd
import torch
from torch import nn
import numpy as np
from utils.graphics_utils import getWorld2View2, getProjectionMatrix
class Camera_view(nn.Module):
def __init__(self, img_id, R, FoVx, FoVy, image_width,image_height,
t=np.array([0.0, 0.0, 0.0]), scale=1.0
):
super(Camera_view, self).__init__()
self.img_id = img_id
# 这里默认是 相机到世界 也就是相机在世界坐标系下的位姿
self.R = R
self.t = t
self.scale = scale # 尺度 展示没有
self.FoVx = FoVx
self.FoVy = FoVy
self.image_width = image_width
self.image_height = image_height
self.zfar = 100.0
self.znear = 0.01
# 相机在世界坐标系下的位姿 相机到世界的变换矩阵
sRt_c2w = np.zeros((4, 4)) #标准的矩阵转置
sRt_c2w[:3, :3] = self.R
sRt_c2w[:3, 3] = self.scale*self.t
sRt_c2w[3, 3] = 1.0
# 3D高斯渲染 需要的是 一个3D高斯球(x,y,z) 投影到相机像素画面 ,也就是世界到相机的变换矩阵, 所以需要对相机到世界矩阵sRt转置取逆
#3D世界到3D相机坐标系 变换矩阵
#self.world_view_transform = torch.tensor(np.float32(sRt_c2w)).transpose(0, 1).cuda() #
self.world_view_transform = torch.tensor(np.float32(sRt_c2w)).transpose(0, 1).cuda() #
'''
#将3D相机坐标投影到2D相机像素平面的投影矩阵
# 真实相机成像模型中 该矩阵是由 fx fy cx cy构造的
# 虚拟渲染相机模型中 该矩阵是由 znear 默认0.01 近平面 zfar 默认100 远平面 视场角FoVx FoVy构造的。计算视场角FoVx=fx/(W/2),FoVy=fy/(H/2)
# 两者关系:
# 虚拟渲染相机用fx和fy表示的话 ,最后都是变为统一的形式。
(相机前方为z正轴的坐标系)
u=fx*x/z-W/2
v=fy*y/z-H/2
w=-zfar*n/z (像素坐标不关心投影后的z值,无用舍去,所以最终znear和zfar对像素坐标u,v没有影响。)
# 真实采集相机参数 fx fy cx=实际物理值 cy=实际物理值 成像分辨率 W*H
# 渲染虚拟相机参数 fx fy cx=W/2 cy=H/2 成像分辨率 W*H
'''
self.projection_matrix = getProjectionMatrix(znear=self.znear, zfar=self.zfar, fovX=self.FoVx, fovY=self.FoVy).transpose(0, 1).cuda()
# 3D世界点投影到2D相机像素坐标 变换矩阵
self.full_proj_transform = (self.world_view_transform.unsqueeze(0).bmm(self.projection_matrix.unsqueeze(0))).squeeze(0)
self.inverse_full_proj_transform = self.full_proj_transform.inverse()# 后面貌似没用到
self.camera_center = self.world_view_transform[3, :3] #相机中心的世界坐标
def __del__(self):
# 如果几个数据使用.cuda() 创建的,会自动存到显卡内存,多次渲染积累造成内存爆满,每次用完需要指定回收释放。否则不会随着程序(cpu)关闭而销毁。
# 删除张量并释放 GPU 内存
del self.world_view_transform
del self.full_proj_transform
del self.inverse_full_proj_transform
del self.camera_center
torch.cuda.empty_cache()
print("cuda占用回收.")
#训练中间只会保存 原始模型 。 训练结束最后一次会保存原始模型baseline 精度减半模型quantised 精度减半减半模型 quantised_half,三种不同模型供测试。
# 要测试的模型类型。标准的、基准的模型 “baseline”和将模型的权重或激活值量化为半精度(16-bit)格式“quantised_half”之间的选择
#功能:量化可以显著降低计算量和内存消耗,但可能会引入一些精度损失。具体来说,“quantised_half”可能指的是将模型参数或中间激活值量化为16-bit浮点数(half precision),从而减少存储需求并提高计算效率。
#半浮点量化 如果采用半浮点量化,则码本条目以及位置参数将以半精度存储。这意味着使用 16 位而不是 32 位,因此存储的是 float16 而不是 float32。
# #但是,由于格式.ply不允许 float16 类型的数字,因此参数将指针转换为 int16 并以此形式存储。
models_configuration = {
'baseline': {
'quantised': False,
'half_float': False,
'name': 'point_cloud.ply'
},
'quantised': {
'quantised': True,
'half_float': False,
'name': 'point_cloud_quantised.ply'
},
'quantised_half': {
'quantised': True,
'half_float': True,
'name': 'point_cloud_quantised_half.ply'
},
}
def measure_fps(iteration, views, gaussians, pipeline, background, pcd_name):
fps = 0
for _, view in enumerate(views):
render(view, gaussians, pipeline, background, measure_fps=False)
for _, view in enumerate(views):
fps += render(view, gaussians, pipeline, background, measure_fps=True)["FPS"]
fps *= 1000 / len(views)
return pd.Series([fps], index=["FPS"], name=f"{pcd_name}_{iteration}")
def render_img(view,
gaussians, # 模型
pipeline,
background,
):
#for idx, view in enumerate(tqdm(views, desc="Rendering progress")):
# view 拷贝 # gaussians 继承 pipeline 拷贝 background 继承
rendering = render(view, gaussians, pipeline, background)["render"]
#fps = render(view, gaussians, pipeline, background, measure_fps=True)["FPS"]
#gt = view.original_image[0:3, :, :]
# 将渲染图像转换为 NumPy 数组
rendering_np = rendering.cpu().numpy()
# 如果张量是 (C, H, W) 形式,需要调整为 (H, W, C)
if rendering_np.shape[0] == 3:
rendering_np = np.transpose(rendering_np, (1, 2, 0))
# 将 RGB 转换为 BGR
opencv_img = rendering_np[..., ::-1]
# 及时清空显卡数据缓存
del rendering
del rendering_np
torch.cuda.empty_cache()
# # 显示图像
# cv2.imshow('Rendering', opencv_img)
# cv2.waitKey(0) # 等待用户按键
return opencv_img
def render_sets(dataset : ModelParams,
iteration : int,
pipeline : PipelineParams,
):
with torch.no_grad():
print("dataset._model_path 训练渲染保存的模型总路径",dataset.model_path)
print("dataset._source_path 原始输入SFM数据路径",dataset.source_path)
print("dataset.sh_degree 球谐系数",dataset.sh_degree)
print("dataset.white_background 是否白色背景",dataset.sh_degree)
gaussians = GaussianModel(dataset.sh_degree)
bg_color = [1,1,1] if dataset.white_background else [0, 0, 0]
background = torch.tensor(bg_color, dtype=torch.float32, device="cuda")
# 加载什么精度模型
model = args.models
print("渲染实际加载的训练模型精度类型 (标准baseline 半精度quantised 半半精度half_float)",model)
name = models_configuration[model]['name']
quantised = models_configuration[model]['quantised']
half_float = models_configuration[model]['half_float']
try:
# 选择什么训练次数模型
model_path = dataset.model_path+"/point_cloud/iteration_"+str(iteration)+"/"
model_path=os.path.join(model_path,name)
print("渲染实际加载的训练模型",model_path)
gaussians.load_ply(model_path, quantised=quantised, half_float=half_float)
except:
raise RuntimeError(f"Configuration {model} with name {name} not found!")
height, width = 1080, 1920
img_opencv = np.ones((height, width, 3), dtype=np.uint8) * 255
cv2.namedWindow('Rendering_Img', cv2.WINDOW_NORMAL)
x=0
y=0
z=0
i=0
step_=0.1
while True:
new_img=0
cv2.imshow('Rendering_Img', img_opencv)
key = cv2.waitKey(1) & 0xFF
if key == 27: # 按下 'q' 键
print("退出")
break
elif key == ord('w'): # 按下 's' 键
print("x前进")
x=x+step_
i=i+1
new_img=1
elif key == ord('s'): # 按下 's' 键
print("x后退")
x=x-step_
i=i+1
new_img=1
elif key == ord('a'): # 按下 's' 键
print("y前进")
y=y+step_
i=i+1
new_img=1
elif key == ord('d'): # 按下 's' 键
print("y后退")
y=y-step_
i=i+1
new_img=1
elif key == ord('q'): # 按下 's' 键
print("z前进")
z=z+step_
i=i+1
new_img=1
elif key == ord('e'): # 按下 's' 键
print("z后退")
z=z-step_
i=i+1
new_img=1
if new_img==1:
# 相机到世界的旋转矩阵
R_c2w = np.array([
[1.0, 0.0, 0.0],
[0.0, 1.0, 0.0],
[0.0, 0.0, 1.0]
])
# 相机到世界的平移矩阵 也就是相机在世界坐标系下的位置
t_c2w=np.array([x, y, z])
scale_c2w=1
view = Camera_view(img_id=i,
R=R_c2w,
t=t_c2w,
scale=scale_c2w,
FoVx=90,
FoVy=90,
image_width=width,
image_height=height)
#df = pd.DataFrame()
img_opencv = render_img( view, gaussians, pipeline, background)
#cv2.imwrite('random_white_image.jpg', white_image)
if __name__ == "__main__":
# Set up command line argument parser
parser = ArgumentParser(description="渲染测试脚本")
model = ModelParams(parser, sentinel=True)
pipeline = PipelineParams(parser)
parser.add_argument("--iteration", default=30000, type=int)
parser.add_argument("--models", default='baseline',type=str) #'baseline','quantised' 'quantised_half'
parser.add_argument("--quiet", action="store_true") #标记以省略写入标准输出管道的任何文本。
args = get_combined_args(parser) # 从cfg_args加载路径
safe_state(args.quiet)
render_sets(model.extract(args), args.iteration, pipeline.extract(args))
训练速度
训练指令
python ./train.py -s /home/dongdong/2project/0data/NWPU_cplmap/ -m /home/dongdong/2project/0data/NWPU_cplmap/train_out/ --resolution 1 --data_device cpu --sh_degree 0
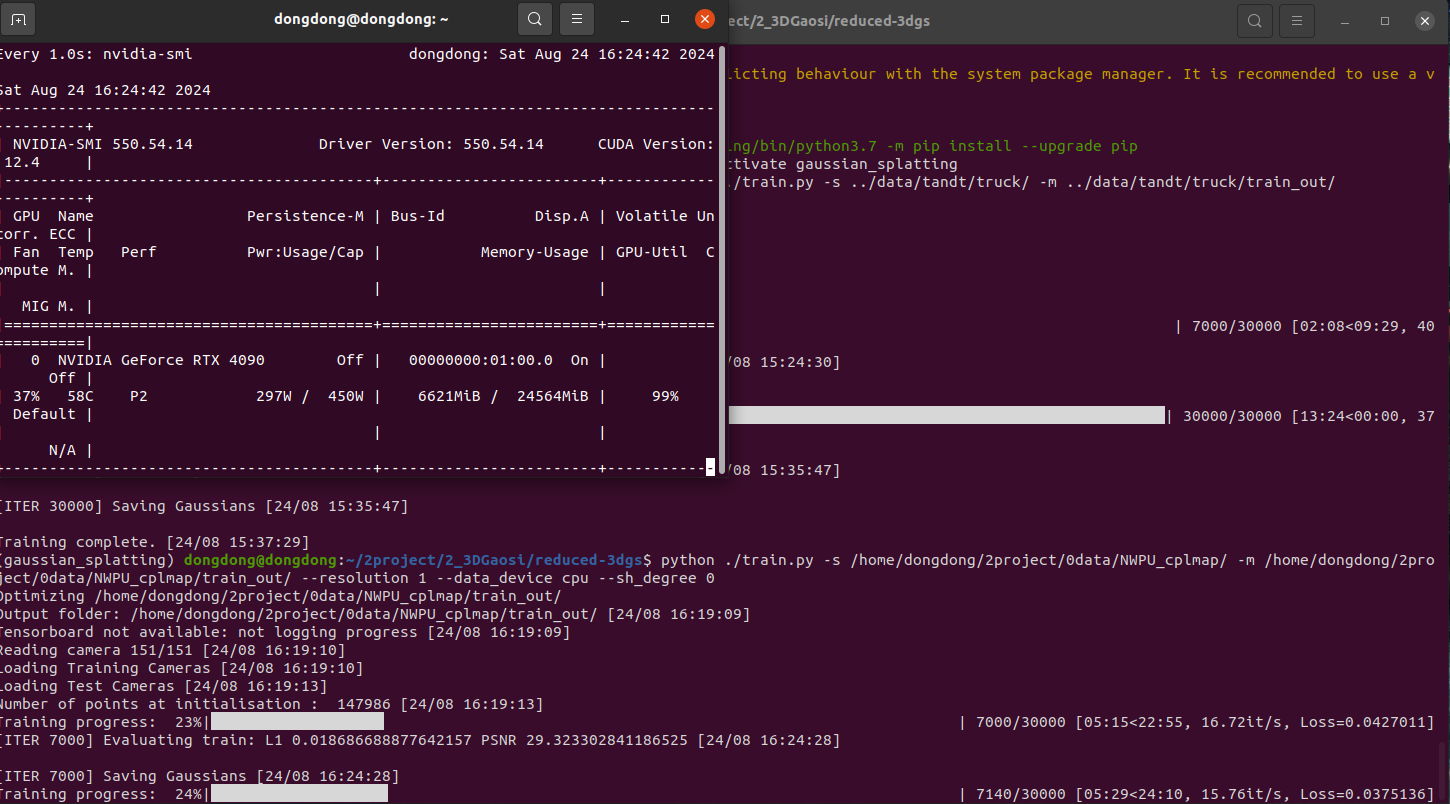
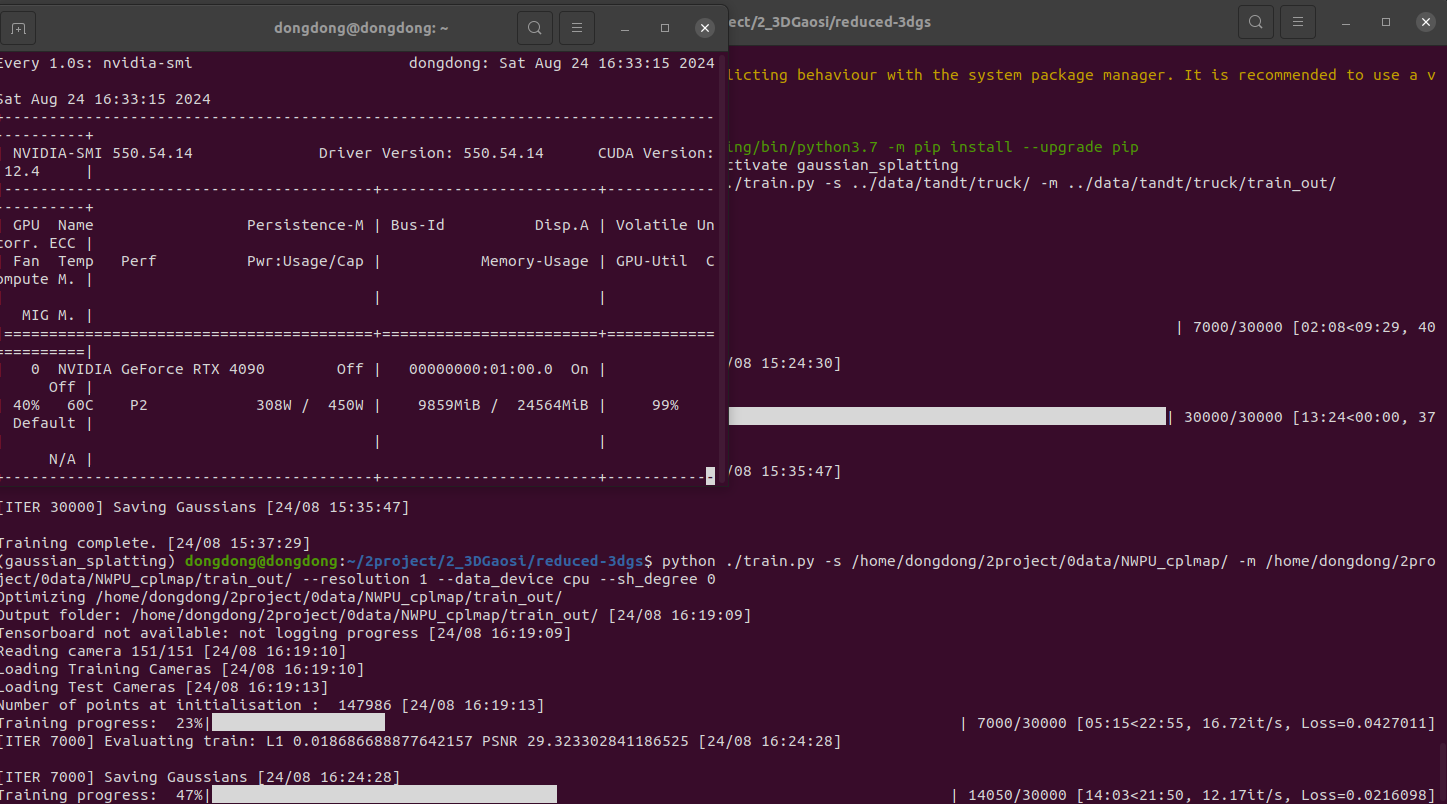
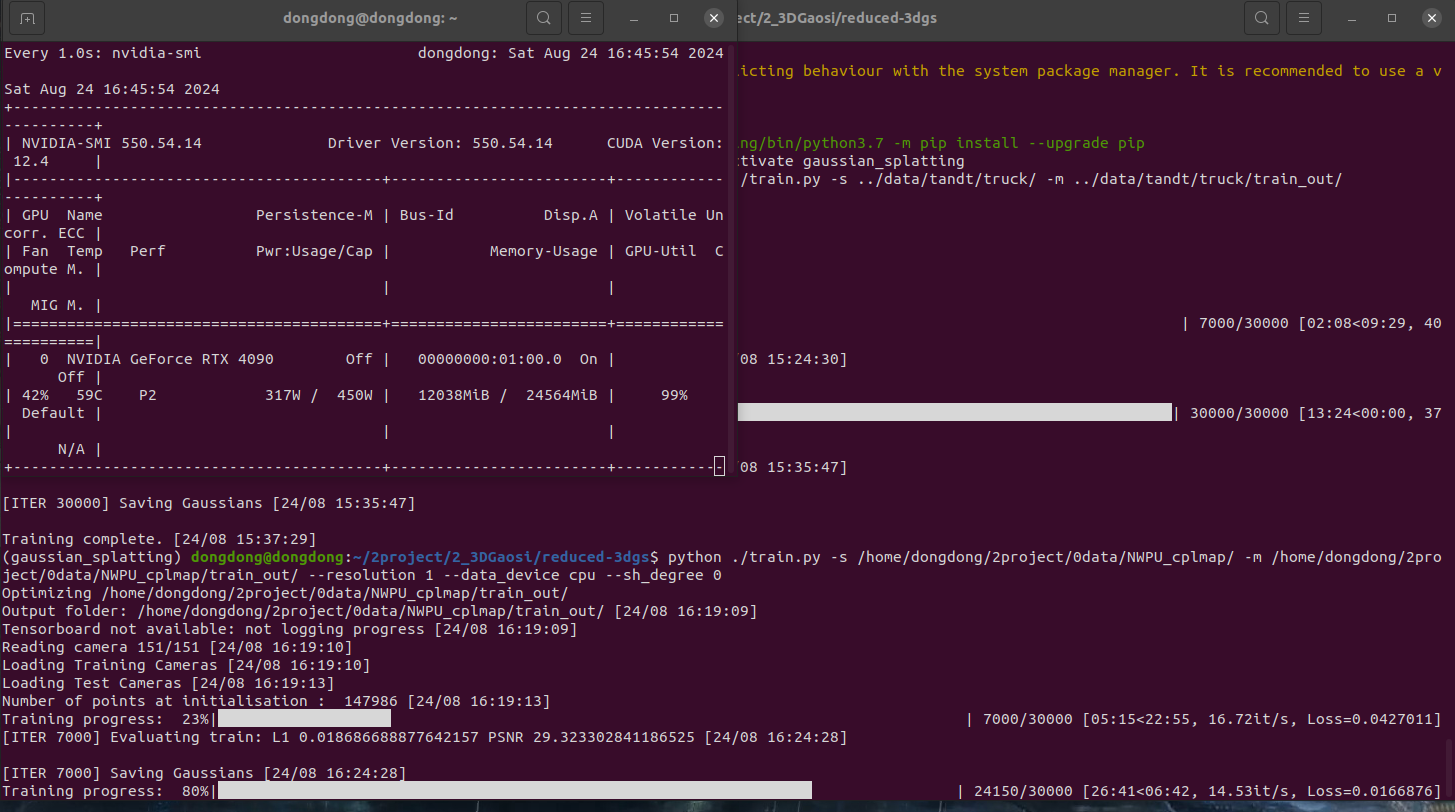
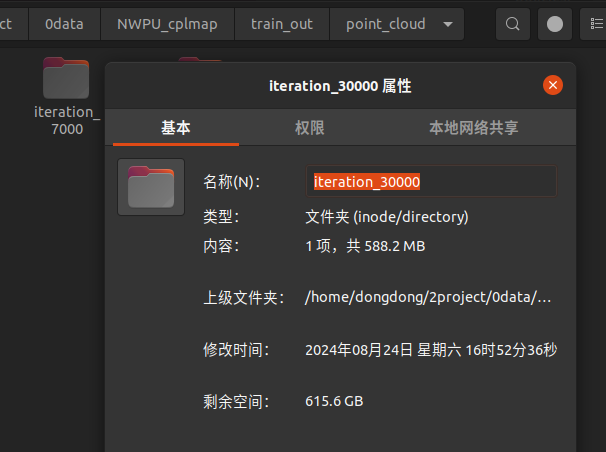
老版本
训练大约 10g运行内存
3D 高斯渲染图像 opencv刷图
#
# Copyright (C) 2023, Inria
# GRAPHDECO research group, https://team.inria.fr/graphdeco
# All rights reserved.
#
# This software is free for non-commercial, research and evaluation use
# under the terms of the LICENSE.md file.
#
# For inquiries contact george.drettakis@inria.fr
#
import cv2
import numpy as np
import torch
from scene import Scene
import os
from tqdm import tqdm
from os import makedirs
from gaussian_renderer import render
import torchvision
from utils.general_utils import safe_state
from argparse import ArgumentParser
from arguments import ModelParams, PipelineParams, get_combined_args
from gaussian_renderer import GaussianModel
import pandas as pd
import torch
from torch import nn
import numpy as np
from utils.graphics_utils import getWorld2View2, getProjectionMatrix
from scene.colmap_loader import *
from scene.dataset_readers import *
# 要选的视角
class Camera_view(nn.Module):
def __init__(self, img_id, R, FoVx, FoVy, image_width,image_height,
t=np.array([0.0, 0.0, 0.0]), scale=1.0
):
super(Camera_view, self).__init__()
self.img_id = img_id
# 这里默认是 相机到世界 也就是相机在世界坐标系下的位姿
self.R = R
self.t = t
self.scale = scale # 尺度 展示没有
self.FoVx = FoVx
self.FoVy = FoVy
self.image_width = image_width
self.image_height = image_height
self.zfar = 100.0
self.znear = 0.01
# 相机在世界坐标系下的位姿 相机到世界的变换矩阵
sRt_c2w = np.zeros((4, 4)) #标准的矩阵转置
sRt_c2w[:3, :3] = self.R
sRt_c2w[:3, 3] = self.scale*self.t
sRt_c2w[3, 3] = 1.0
# 3D高斯渲染 需要的是 一个3D高斯球(x,y,z) 投影到相机像素画面 ,也就是世界到相机的变换矩阵, 所以需要对相机到世界矩阵sRt转置取逆
#3D世界到3D相机坐标系 变换矩阵
#self.world_view_transform = torch.tensor(np.float32(sRt_c2w)).transpose(0, 1).cuda() #
self.world_view_transform = torch.tensor(np.float32(sRt_c2w)).transpose(0, 1).cuda() #
'''
#将3D相机坐标投影到2D相机像素平面的投影矩阵
# 真实相机成像模型中 该矩阵是由 fx fy cx cy构造的
# 虚拟渲染相机模型中 该矩阵是由 znear 默认0.01 近平面 zfar 默认100 远平面 视场角FoVx FoVy构造的。计算视场角FoVx=fx/(W/2),FoVy=fy/(H/2)
# 两者关系:
# 虚拟渲染相机用fx和fy表示的话 ,最后都是变为统一的形式。
(相机前方为z正轴的坐标系)
u=fx*x/z-W/2
v=fy*y/z-H/2
w=-zfar*n/z (像素坐标不关心投影后的z值,无用舍去,所以最终znear和zfar对像素坐标u,v没有影响。)
# 真实采集相机参数 fx fy cx=实际物理值 cy=实际物理值 成像分辨率 W*H
# 渲染虚拟相机参数 fx fy cx=W/2 cy=H/2 成像分辨率 W*H
'''
self.projection_matrix = getProjectionMatrix(znear=self.znear, zfar=self.zfar, fovX=self.FoVx, fovY=self.FoVy).transpose(0, 1).cuda()
# 3D世界点投影到2D相机像素坐标 变换矩阵
self.full_proj_transform = (self.world_view_transform.unsqueeze(0).bmm(self.projection_matrix.unsqueeze(0))).squeeze(0)
self.inverse_full_proj_transform = self.full_proj_transform.inverse()# 后面貌似没用到
self.camera_center = self.world_view_transform[3, :3] #相机中心的世界坐标
def __del__(self):
# 如果几个数据使用.cuda() 创建的,会自动存到显卡内存,多次渲染积累造成内存爆满,每次用完需要指定回收释放。否则不会随着程序(cpu)关闭而销毁。
# 删除张量并释放 GPU 内存
del self.world_view_transform
del self.full_proj_transform
del self.inverse_full_proj_transform
del self.camera_center
torch.cuda.empty_cache()
#print("cuda占用回收.")
#训练中间只会保存 原始模型 。 训练结束最后一次会保存原始模型baseline 精度减半模型quantised 精度减半减半模型 quantised_half,三种不同模型供测试。
# 要测试的模型类型。标准的、基准的模型 “baseline”和将模型的权重或激活值量化为半精度(16-bit)格式“quantised_half”之间的选择
#功能:量化可以显著降低计算量和内存消耗,但可能会引入一些精度损失。具体来说,“quantised_half”可能指的是将模型参数或中间激活值量化为16-bit浮点数(half precision),从而减少存储需求并提高计算效率。
#半浮点量化 如果采用半浮点量化,则码本条目以及位置参数将以半精度存储。这意味着使用 16 位而不是 32 位,因此存储的是 float16 而不是 float32。
# #但是,由于格式.ply不允许 float16 类型的数字,因此参数将指针转换为 int16 并以此形式存储。
models_configuration = {
'baseline': {
'quantised': False,
'half_float': False,
'name': 'point_cloud.ply'
},
'quantised': {
'quantised': True,
'half_float': False,
'name': 'point_cloud_quantised.ply'
},
'quantised_half': {
'quantised': True,
'half_float': True,
'name': 'point_cloud_quantised_half.ply'
},
}
def measure_fps(iteration, views, gaussians, pipeline, background, pcd_name):
fps = 0
for _, view in enumerate(views):
render(view, gaussians, pipeline, background, measure_fps=False)
for _, view in enumerate(views):
fps += render(view, gaussians, pipeline, background, measure_fps=True)["FPS"]
fps *= 1000 / len(views)
return pd.Series([fps], index=["FPS"], name=f"{pcd_name}_{iteration}")
def rotation_matrix_x(theta_x):
""" 创建绕x轴旋转的旋转矩阵 """
c, s = np.cos(theta_x), np.sin(theta_x)
return np.array([
[1, 0, 0],
[0, c, -s],
[0, s, c]
])
def rotation_matrix_y(theta_y):
""" 创建绕y轴旋转的旋转矩阵 """
c, s = np.cos(theta_y), np.sin(theta_y)
return np.array([
[c, 0, s],
[0, 1, 0],
[-s, 0, c]
])
def rotation_matrix_z(theta_z):
""" 创建绕z轴旋转的旋转矩阵 """
c, s = np.cos(theta_z), np.sin(theta_z)
return np.array([
[c, -s, 0],
[s, c, 0],
[0, 0, 1]
])
def combined_rotation_matrix(theta_x, theta_y, theta_z):
""" 通过绕x、y、z轴的旋转角度创建组合旋转矩阵 """
Rx = rotation_matrix_x(theta_x)
Ry = rotation_matrix_y(theta_y)
Rz = rotation_matrix_z(theta_z)
# 旋转矩阵的组合顺序:绕z轴 -> 绕y轴 -> 绕x轴
R = Rz @ Ry @ Rx
return R
# # 示例角度(以弧度为单位)
# theta_x = np.radians(30) # 30度
# theta_y = np.radians(45) # 45度
# theta_z = np.radians(60) # 60度
# # 计算旋转矩阵
# R = combined_rotation_matrix(theta_x, theta_y, theta_z)
# print("旋转矩阵 R:")
# print(R)
# 渲染单个视角图像并转化opencv图像
def render_img(view,
gaussians, # 模型
pipeline,
background,
):
#for idx, view in enumerate(tqdm(views, desc="Rendering progress")):
# view 拷贝 # gaussians 继承 pipeline 拷贝 background 继承
rendering = render(view, gaussians, pipeline, background)["render"]
#fps = render(view, gaussians, pipeline, background, measure_fps=True)["FPS"]
#gt = view.original_image[0:3, :, :]
# 将渲染图像转换为 NumPy 数组
rendering_np = rendering.cpu().numpy()
# 如果张量是 (C, H, W) 形式,需要调整为 (H, W, C)
if rendering_np.shape[0] == 3:
rendering_np = np.transpose(rendering_np, (1, 2, 0))
# 将 RGB 转换为 BGR
opencv_img = rendering_np[..., ::-1]
# 及时清空显卡数据缓存
del rendering
del rendering_np
torch.cuda.empty_cache()
# # 显示图像
# cv2.imshow('Rendering', opencv_img)
# cv2.waitKey(0) # 等待用户按键
return opencv_img
# 从slam读取相机参数
def Read_caminfo_from_orbslam(path):
# wait to do
pass
# 从colmap读取相机参数
def Read_caminfo_from_colmap(path):
cam_intrinsics={}
cam_extrinsics={}
# 自带的代码
'''
from scene.colmap_loader import *
from scene.dataset_readers import *
'''
try:
cameras_extrinsic_file = os.path.join(path, "sparse/0", "images.bin")
cameras_intrinsic_file = os.path.join(path, "sparse/0", "cameras.bin")
cam_extrinsics = read_extrinsics_binary(cameras_extrinsic_file)
cam_intrinsics = read_intrinsics_binary(cameras_intrinsic_file)
except:
cameras_extrinsic_file = os.path.join(path, "sparse/0", "images.txt")
cameras_intrinsic_file = os.path.join(path, "sparse/0", "cameras.txt")
cam_extrinsics = read_extrinsics_text(cameras_extrinsic_file)
cam_intrinsics = read_intrinsics_text(cameras_intrinsic_file)
'''
加载相机内参 read_intrinsics_text()
# Camera list with one line of data per camera:
# CAMERA_ID, MODEL, WIDTH, HEIGHT, PARAMS[]
# Number of cameras: 1
1 PINHOLE 1920 1080 1114.0581411159471 1108.508409747483 960 540
'''
cam_id=1 # 从1开始。以一个相机模型 这里默认colmap一般只有一个相机. 但是可能存在GNSS照片和视频抽离的帧,2个相机模型参数
cam_parameters=cam_intrinsics[cam_id]
print("相机id",cam_parameters.id)
print("相机模型",cam_parameters.model)
print("图像宽度",cam_parameters.width)
print("图像高度",cam_parameters.height)
print("相机内参 fx ",cam_parameters.params[0])
print("相机内参 fy ",cam_parameters.params[1])
FovY=0
FovX=0
if cam_parameters.model=="SIMPLE_PINHOLE":
focal_length_x = cam_parameters.params[0]
FovY = focal2fov(focal_length_x, cam_parameters.height)
FovX = focal2fov(focal_length_x, cam_parameters.width)
elif cam_parameters.model=="PINHOLE":
focal_length_x = cam_parameters.params[0]
focal_length_y = cam_parameters.params[1]
FovY = focal2fov(focal_length_y, cam_parameters.height)
FovX = focal2fov(focal_length_x, cam_parameters.width)
else:
assert False, "Colmap camera model not handled: only undistorted datasets (PINHOLE or SIMPLE_PINHOLE cameras) supported!"
cam_info = {
"width": cam_parameters.width,
"height": cam_parameters.height,
"fx": cam_parameters.params[0],
"fy": cam_parameters.params[1],
"FovX": FovX,
"FovY": FovY
}
return cam_info
def render_sets_handMode(dataset : ModelParams,
iteration : int,
pipeline : PipelineParams,
):
with torch.no_grad():
print("dataset._model_path 训练渲染保存的模型总路径",dataset.model_path)
print("dataset._source_path 原始输入SFM数据路径",dataset.source_path)
print("dataset.sh_degree 球谐系数",dataset.sh_degree)
print("dataset.white_background 是否白色背景",dataset.sh_degree)
cam_info = Read_caminfo_from_colmap(dataset.source_path)
height, width = cam_info["height"], cam_info["width"]
Fovx,Fovy = cam_info["FovX"], cam_info["FovY"]
img_opencv = np.ones((height, width, 3), dtype=np.uint8) * 0
cv2.namedWindow('Rendering_Img', cv2.WINDOW_NORMAL)
i=0 # 渲染的图像计数 id
x=0 # 位置
y=0
z=0
step_=0.1
theta_x=0 # 旋转角度
theta_y=0
theta_z=0
step_theta=1
# 加载渲染器
gaussians = GaussianModel(dataset.sh_degree)
bg_color = [1,1,1] if dataset.white_background else [0, 0, 0]
background = torch.tensor(bg_color, dtype=torch.float32, device="cuda")
# 加载什么精度模型
model = args.models
print("渲染实际加载的训练模型精度类型 (标准baseline 半精度quantised 半半精度half_float)",model)
name = models_configuration[model]['name']
quantised = models_configuration[model]['quantised']
half_float = models_configuration[model]['half_float']
try:
# 选择什么训练次数模型
model_path = dataset.model_path+"/point_cloud/iteration_"+str(iteration)+"/"
model_path=os.path.join(model_path,name)
print("渲染实际加载的训练模型",model_path)
gaussians.load_ply(model_path, quantised=quantised, half_float=half_float)
except:
raise RuntimeError(f"Configuration {model} with name {name} not found!")
while True:
new_img=0
image = cv2.UMat(img_opencv) # 原始渲染图不能被污染 要发送slam回去,新创建图可视化 cv2.UMat转换后才可以 cv2.putText
# 设置文字的参数
font_scale = 2 # 大小
thickness = 2 # 粗细
text1 ="position_xyz: " + str(round(x, 2))+" , "+str(round(y, 2)) +" , "+ str(round(z, 2))
position1 = (10, 60) # 文字的位置
cv2.putText(image, text1, position1, cv2.FONT_HERSHEY_SIMPLEX, font_scale, (255, 0, 0), thickness)
text2 = "theta_xyz: " + str(round(theta_x, 2))+" , "+str(round(theta_y, 2)) +" , "+ str(round(theta_z, 2))
position2 = (10, 120) # 文字的位置
cv2.putText(image, text2, position2, cv2.FONT_HERSHEY_SIMPLEX, font_scale, (0, 0, 255), thickness)
cv2.imshow('Rendering_Img', image)
#cv2.imshow('Rendering_Img', img_opencv)# imshow 不需要额外 cv2.UMat转换
key = cv2.waitKey(1) & 0xFF
if key == 27: # 按下 'q' 键
print("退出")
break
elif key == ord('w'): # 按下 's' 键
print("x前进")
x=x+step_
i=i+1
new_img=1
elif key == ord('s'): # 按下 's' 键
print("x后退")
x=x-step_
i=i+1
new_img=1
elif key == ord('a'): # 按下 's' 键
print("y前进")
y=y+step_
i=i+1
new_img=1
elif key == ord('d'): # 按下 's' 键
print("y后退")
y=y-step_
i=i+1
new_img=1
elif key == ord('q'): # 按下 's' 键
print("z前进")
z=z+step_
i=i+1
new_img=1
elif key == ord('e'): # 按下 's' 键
print("z后退")
z=z-step_
i=i+1
new_img=1
elif key == ord('i'): # 按下 's' 键
print("x旋转+")
theta_x=theta_x+step_theta
if(theta_x>360 or theta_x<-360): theta_x=0
i=i+1
new_img=1
elif key == ord('k'): # 按下 's' 键
print("x旋转-")
theta_x=theta_x-step_theta
if(theta_x>360 or theta_x<-360): theta_x=0
i=i+1
new_img=1
elif key == ord('j'): # 按下 's' 键
print("y旋转+")
theta_y=theta_y+step_theta
if(theta_y>360 or theta_y<-360): theta_y=0
i=i+1
new_img=1
elif key == ord('l'): # 按下 's' 键
print("y旋转-")
theta_y=theta_y-step_theta
if(theta_y>360 or theta_y<-360): theta_y=0
i=i+1
new_img=1
elif key == ord('u'): # 按下 's' 键
print("z旋转+")
theta_z=theta_z+step_theta
if(theta_z>360 or theta_z<-360): theta_z=0
i=i+1
new_img=1
elif key == ord('o'): # 按下 's' 键
print("z旋转-")
theta_z=theta_z-step_theta
if(theta_z>360 or theta_z<-360): theta_z=0
i=i+1
new_img=1
if new_img==1:
# # 示例角度(以弧度为单位)
theta_x_pi = np.radians(theta_x) # 30度
theta_y_pi = np.radians(theta_y) # 45度
theta_z_pi = np.radians(theta_z) # 60度
# # 计算旋转矩阵
R_c2w = combined_rotation_matrix(theta_x_pi, theta_y_pi, theta_z_pi)
# 相机到世界的旋转矩阵
# R_c2w = np.array([
# [1.0, 0.0, 0.0],
# [0.0, 1.0, 0.0],
# [0.0, 0.0, 1.0]
# ])
# print("旋转矩阵 R:")
# print(R)
# 相机到世界的平移矩阵 也就是相机在世界坐标系下的位置
t_c2w=np.array([x, y, z])
scale_c2w=1
view = Camera_view(img_id=i,
R=R_c2w,
t=t_c2w,
scale=scale_c2w,
FoVx=Fovx,
FoVy=Fovy,
image_width=width,
image_height=height)
#df = pd.DataFrame()
img_opencv = render_img( view, gaussians, pipeline, background)
# python ./render.py -m /home/dongdong/2project/0data/NWPU/gs_out/train1_out_sh1_num7000 --iteration 7010
if __name__ == "__main__":
# Set up command line argument parser
parser = ArgumentParser(description="渲染测试脚本")
model = ModelParams(parser, sentinel=True)
pipeline = PipelineParams(parser)
parser.add_argument("--iteration", default=30000, type=int)
parser.add_argument("--models", default='baseline',type=str) #'baseline','quantised' 'quantised_half'
parser.add_argument("--quiet", action="store_true") #标记以省略写入标准输出管道的任何文本。
args = get_combined_args(parser) # 从cfg_args加载路径
safe_state(args.quiet)
render_sets_handMode(model.extract(args), args.iteration, pipeline.extract(args))

