

https://www.processon.com/diagraming/6538ba85599d0f3e3d5b11a7
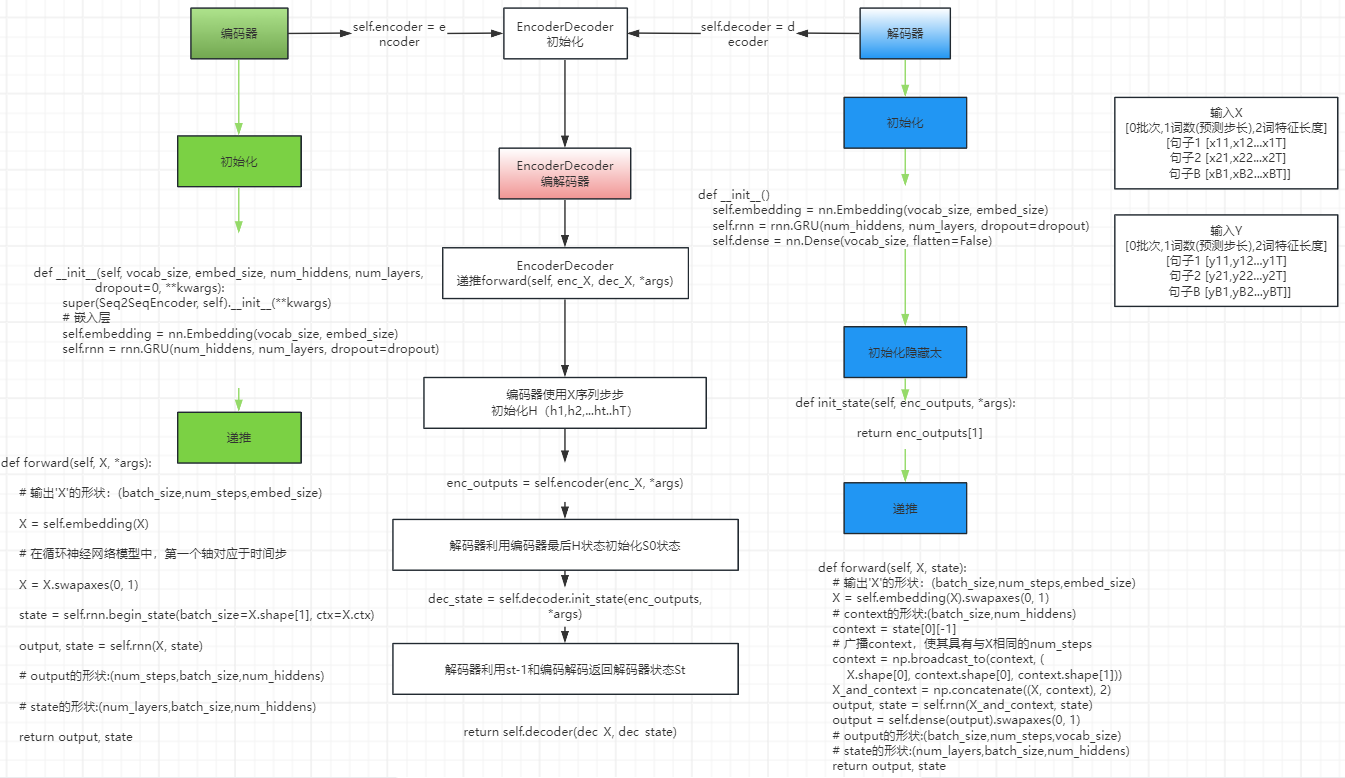
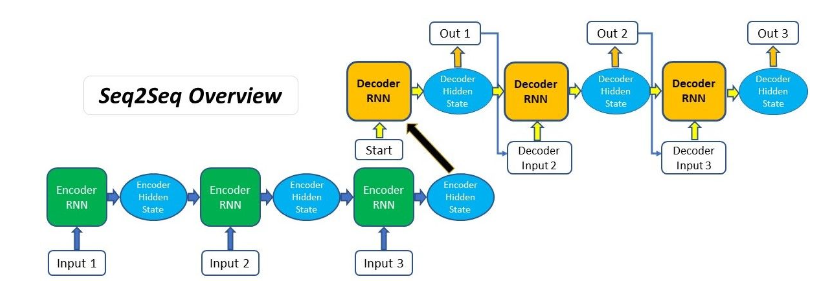
编解码器整体架构
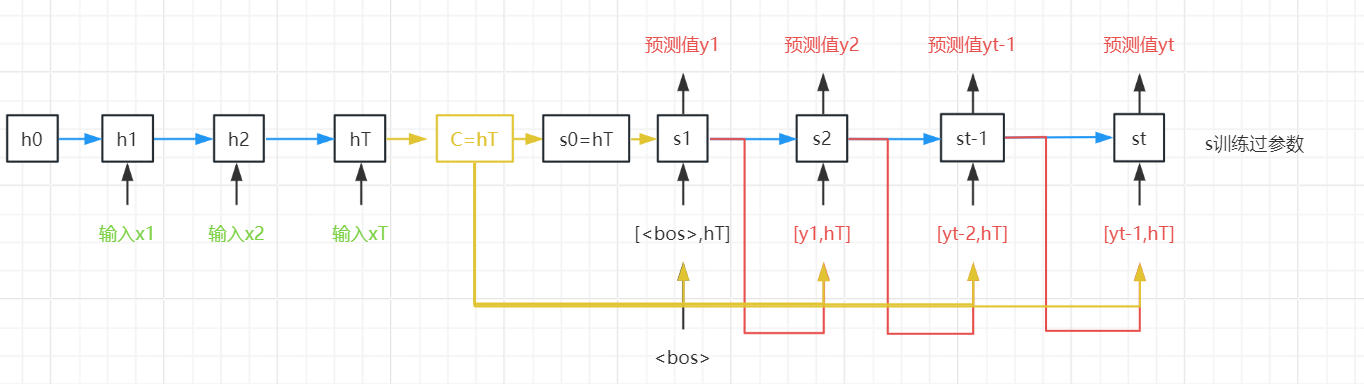
固定上下文
训练阶段
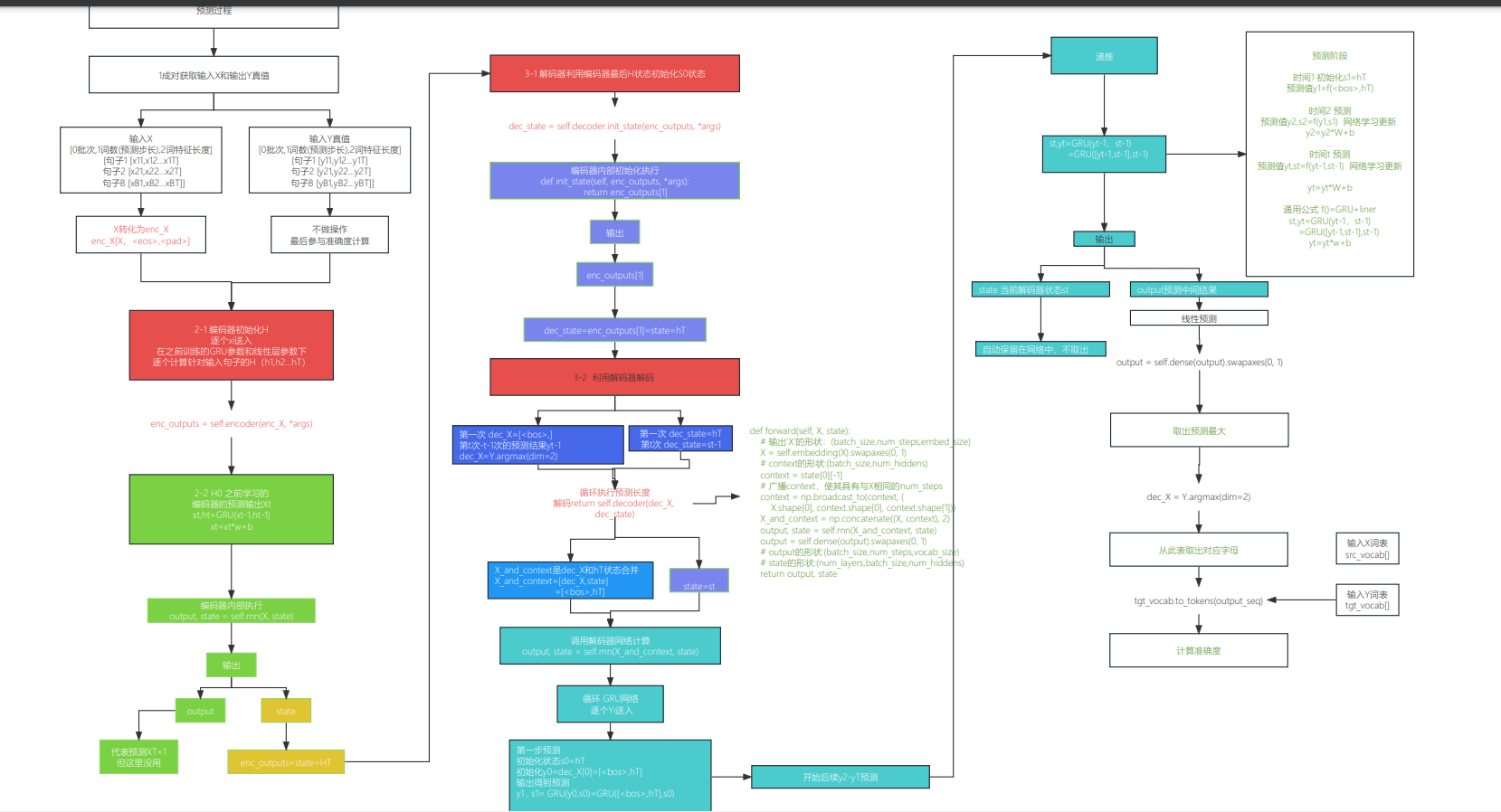
预测阶段
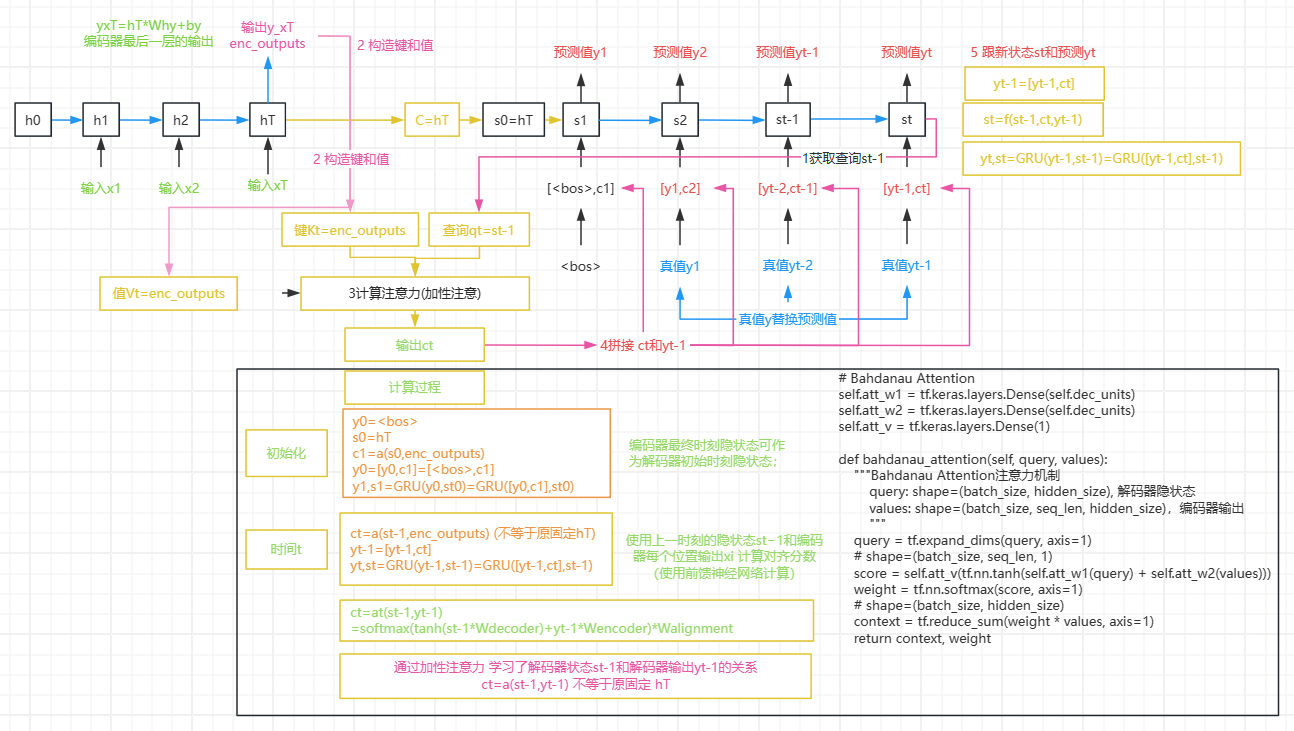
可变上下文


1早先的预测模型
让我们首先定义预测函数来生成prefix之后的新字符, 其中的prefix是一个用户提供的包含多个字符的字符串。
在循环遍历prefix中的开始字符时, 我们不断地将隐状态传递到下一个时间步,但是不生成任何输出。
这被称为预热(warm-up)期, 因为在此期间模型会自我更新(例如,更新隐状态), 但不会进行预测。
预热期结束后,隐状态的值通常比刚开始的初始值更适合预测, 从而预测字符并输出它们。
1-1模型定义
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 | #@saveclass RNNModel(nn.Module): """循环神经网络模型""" def __init__(self, rnn_layer, vocab_size, **kwargs): super(RNNModel, self).__init__(**kwargs) self.rnn = rnn_layer self.vocab_size = vocab_size self.num_hiddens = self.rnn.hidden_size # 如果RNN是双向的(之后将介绍),num_directions应该是2,否则应该是1 if not self.rnn.bidirectional: self.num_directions = 1 self.linear = nn.Linear(self.num_hiddens, self.vocab_size) else: self.num_directions = 2 self.linear = nn.Linear(self.num_hiddens * 2, self.vocab_size) def forward(self, inputs, state): X = F.one_hot(inputs.T.long(), self.vocab_size) X = X.to(torch.float32) Y, state = self.rnn(X, state) # 全连接层首先将Y的形状改为(时间步数*批量大小,隐藏单元数) # 它的输出形状是(时间步数*批量大小,词表大小)。 output = self.linear(Y.reshape((-1, Y.shape[-1]))) return output, state def begin_state(self, device, batch_size=1): if not isinstance(self.rnn, nn.LSTM): # nn.GRU以张量作为隐状态 return torch.zeros((self.num_directions * self.rnn.num_layers, batch_size, self.num_hiddens), device=device) else: # nn.LSTM以元组作为隐状态 return (torch.zeros(( self.num_directions * self.rnn.num_layers, batch_size, self.num_hiddens), device=device), torch.zeros(( self.num_directions * self.rnn.num_layers, batch_size, self.num_hiddens), device=device)) |
1-2预测阶段
1 2 3 4 5 6 7 8 9 10 11 12 | def predict_ch8(prefix, num_preds, net, vocab, device): #@save """在prefix后面生成新字符""" state = net.begin_state(batch_size=1, device=device) outputs = [vocab[prefix[0]]] get_input = lambda: torch.tensor([outputs[-1]], device=device).reshape((1, 1)) for y in prefix[1:]: # 预热期 _, state = net(get_input(), state) outputs.append(vocab[y]) for _ in range(num_preds): # 预测num_preds步 y, state = net(get_input(), state) outputs.append(int(y.argmax(dim=1).reshape(1))) return ''.join([vocab.idx_to_token[i] for i in outputs]) |
1-3训练阶段
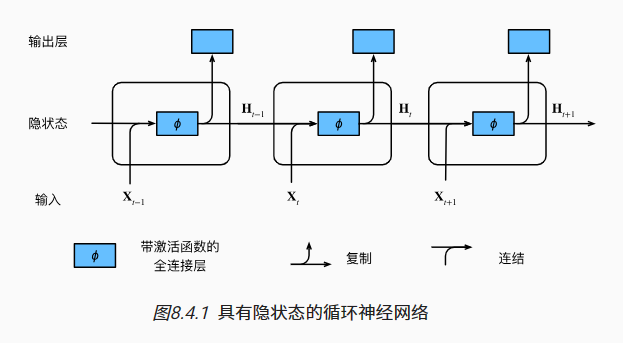
当使用顺序分区时, 我们只在每个迭代周期的开始位置初始化隐状态。
由于下一个小批量数据中的第�个子序列样本 与当前第<span class="math notranslate nohighlight">�个子序列样本相邻, 因此当前小批量数据最后一个样本的隐状态, 将用于初始化下一个小批量数据第一个样本的隐状态。
这样,存储在隐状态中的序列的历史信息 可以在一个迭代周期内流经相邻的子序列。
当使用随机抽样时,因为每个样本都是在一个随机位置抽样的, 因此需要为每个迭代周期重新初始化隐状态。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | #@savedef train_epoch_ch8(net, train_iter, loss, updater, device, use_random_iter): """训练网络一个迭代周期(定义见第8章)""" state, timer = None, d2l.Timer() metric = d2l.Accumulator(2) # 训练损失之和,词元数量 for X, Y in train_iter: if state is None or use_random_iter: # 在第一次迭代或使用随机抽样时初始化state state = net.begin_state(batch_size=X.shape[0], device=device) else: if isinstance(net, nn.Module) and not isinstance(state, tuple): # state对于nn.GRU是个张量 state.detach_() else: # state对于nn.LSTM或对于我们从零开始实现的模型是个张量 for s in state: s.detach_() y = Y.T.reshape(-1) X, y = X.to(device), y.to(device) y_hat, state = net(X, state) l = loss(y_hat, y.long()).mean() if isinstance(updater, torch.optim.Optimizer): updater.zero_grad() l.backward() grad_clipping(net, 1) updater.step() else: l.backward() grad_clipping(net, 1) # 因为已经调用了mean函数 updater(batch_size=1) metric.add(l * y.numel(), y.numel()) return math.exp(metric[0] / metric[1]), metric[1] / timer.stop() |
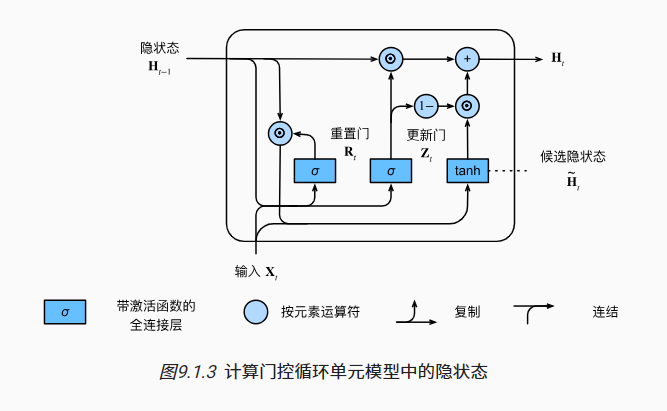
1-4 升级到门控单元
门控循环单元与普通的循环神经网络之间的关键区别在于: 前者支持隐状态的门控。
这意味着模型有专门的机制来确定应该何时更新隐状态, 以及应该何时重置隐状态。
这些机制是可学习的,并且能够解决了上面列出的问题。
例如,如果第一个词元非常重要, 模型将学会在第一次观测之后不更新隐状态。
同样,模型也可以学会跳过不相关的临时观测。 最后,模型还将学会在需要的时候重置隐状态。 下面我们将详细讨论各类门控。
2 长期记忆网络模型转化编码器和解码器架构
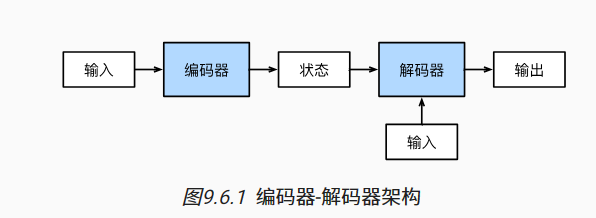
第一个组件是一个编码器(encoder): 它接受一个长度可变的序列作为输入, 并将其转换为具有固定形状的编码状态。
第二个组件是解码器(decoder): 它将固定形状的编码状态映射到长度可变的序列。
给定一个英文的输入序列:“They”“are”“watching”“.”。
首先,这种“编码器-解码器”架构将长度可变的输入序列编码成一个“状态”,
然后对该状态进行解码, 一个词元接着一个词元地生成翻译后的序列作为输出: “Ils”“regordent”“.”。
编解码
1 2 3 4 5 6 7 8 9 10 11 | class EncoderDecoder(nn.Module): """编码器-解码器架构的基类""" def __init__(self, encoder, decoder, **kwargs): super(EncoderDecoder, self).__init__(**kwargs) self.encoder = encoder self.decoder = decoder def forward(self, enc_X, dec_X, *args): enc_outputs = self.encoder(enc_X, *args) dec_state = self.decoder.init_state(enc_outputs, *args) return self.decoder(dec_X, dec_state) |
编码器将长度可变的序列作为输入,并将其转换为具有固定形状的编码状态。
解码器将具有固定形状的编码状态映射为长度可变的序列
3序列到序列学习(seq2seq)
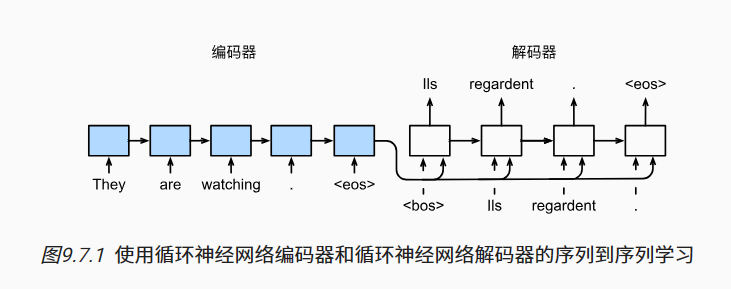
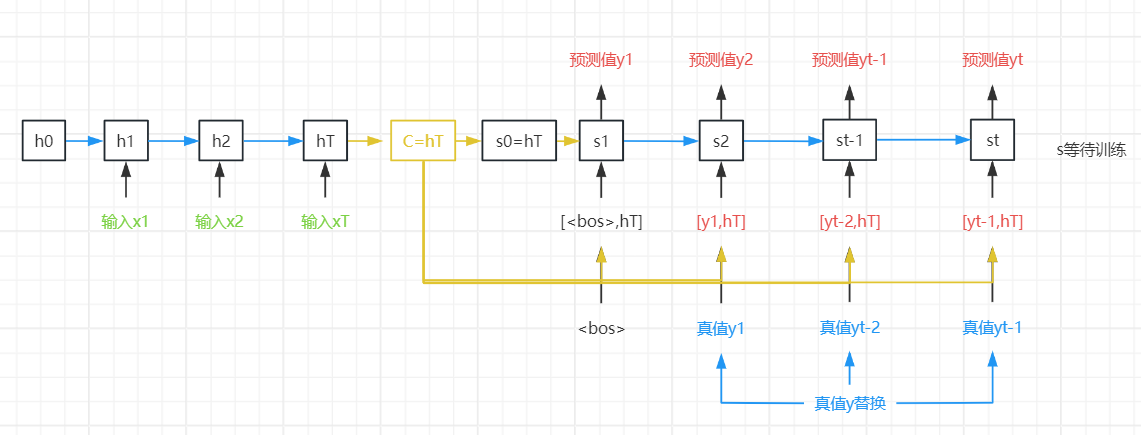
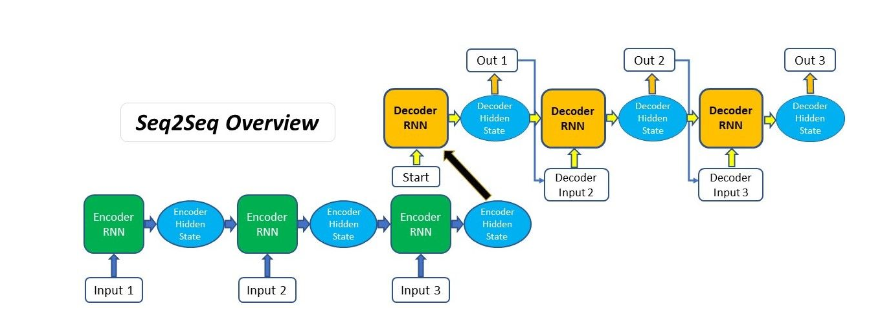
首先,特定的“<bos>”表示序列开始词元,它是解码器的输入序列的第一个词元。
其次,使用循环神经网络编码器最终的隐状态来初始化解码器的隐状态。
编码器最终的隐状态在每一个时间步都作为解码器的输入序列的一部分。
3-2 编码器
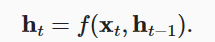
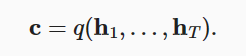
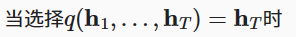 上下文变量仅仅是输入序列在最后时间步的隐状态
上下文变量仅仅是输入序列在最后时间步的隐状态
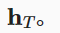
单向循环神经网络来设计编码器, 其中隐状态只依赖于输入子序列, 这个子序列是由输入序列的开始位置到隐状态所在的时间步的位置 (包括隐状态所在的时间步)组成。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | #@saveclass Seq2SeqEncoder(d2l.Encoder): """用于序列到序列学习的循环神经网络编码器""" def __init__(self, vocab_size, embed_size, num_hiddens, num_layers, dropout=0, **kwargs): super(Seq2SeqEncoder, self).__init__(**kwargs) # 嵌入层 self.embedding = nn.Embedding(vocab_size, embed_size) self.rnn = nn.GRU(embed_size, num_hiddens, num_layers, dropout=dropout) def forward(self, X, *args): # 输出'X'的形状:(batch_size,num_steps,embed_size) X = self.embedding(X) # 在循环神经网络模型中,第一个轴对应于时间步 X = X.permute(1, 0, 2) # 如果未提及状态,则默认为0 output, state = self.rnn(X) # output的形状:(num_steps,batch_size,num_hiddens) # state的形状:(num_layers,batch_size,num_hiddens) return output, state |
如果使用长短期记忆网络,state中还将包含记忆单元信息。
3-3 解码器
传统seq2seq模型中encoder将输入序列编码成一个context向量,decoder将context向量作为初始隐状态,生成目标序列。随着输入序列长度的增加,编码器难以将所有输入信息编码为单一context向量,编码信息缺失,难以完成高质量的解码。
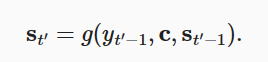
对于解码器,为啥st状态不是和本次输入yt有关而是和yt-1有关??
第一个输入数据是 起始标签<bos>,第一个输出y1 是 X1-XT的整体预测输出的,得到编码器的第一个状态s1
第二个输入数据是上一步预测出的y1,
在上一步输出y1的基础上,
在c的基础上(c=q(H)=q(h1,h2...,hT)=可选HT编码器的最后一个输出状态),其中c是形状固定的,不管输入多长,H的构形固定了,导致c也是固定的。
在上一步状态s1基础上,
共同得到本次输出 y2
不管你多少输入,最终的H是固定的
当实现解码器时, 我们直接使用编码器最后一个时间步的隐状态来初始化解码器的隐状态。
为了进一步包含经过编码的输入序列的信息, 上下文变量在所有的时间步与解码器的输入进行拼接(concatenate)。
1 | context =HT (假设一个句子有T个词去预测下一个,HT记录了输入T个词语的最终隐藏态) |
1 | X [0] 批次每次送入的样本数 可认为句子输目 [1] 词的个数 [2] 词特征的维度 |
1 | context = state[-1].repeat(X.shape[0], 1, 1) <br>HT变为 [0 扩展为和X一样的批次 ,1保持原样,2保持原样] |
1 | X_and_context = torch.cat((X, context), 2) 按照第2维度拼接(词语的维度)拼接<br>作为编码输入解码器 |
为了预测输出词元的概率分布, 在循环神经网络解码器的最后一层使用全连接层来变换隐状态。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | class Seq2SeqDecoder(d2l.Decoder): """用于序列到序列学习的循环神经网络解码器""" def __init__(self, vocab_size, embed_size, num_hiddens, num_layers, dropout=0, **kwargs): super(Seq2SeqDecoder, self).__init__(**kwargs) self.embedding = nn.Embedding(vocab_size, embed_size) self.rnn = nn.GRU(embed_size + num_hiddens, num_hiddens, num_layers, dropout=dropout) self.dense = nn.Linear(num_hiddens, vocab_size) def init_state(self, enc_outputs, *args): return enc_outputs[1] # 编码器最后输出的状态HT def forward(self, X, state): # 输出'X'的形状:(batch_size,num_steps,embed_size) X = self.embedding(X).permute(1, 0, 2) # 广播context,使其具有与X相同的num_steps context = state[-1].repeat(X.shape[0], 1, 1) X_and_context = torch.cat((X, context), 2) output, state = self.rnn(X_and_context, state) output = self.dense(output).permute(1, 0, 2) # output的形状:(batch_size,num_steps,vocab_size) # state的形状:(num_layers,batch_size,num_hiddens) return output, state |
3-4 编解码器
定义
1 2 3 4 5 6 7 8 9 10 11 | class EncoderDecoder(nn.Module): """编码器-解码器架构的基类""" def __init__(self, encoder, decoder, **kwargs): super(EncoderDecoder, self).__init__(**kwargs) self.encoder = encoder self.decoder = decoder def forward(self, enc_X, dec_X, *args): enc_outputs = self.encoder(enc_X, *args) dec_state = self.decoder.init_state(enc_outputs, *args) return self.decoder(dec_X, dec_state) |
初始化
1 2 3 4 5 6 7 8 9 10 11 | embed_size, num_hiddens, num_layers, dropout = 32, 32, 2, 0.1batch_size, num_steps = 64, 10lr, num_epochs, device = 0.005, 300, d2l.try_gpu()train_iter, src_vocab, tgt_vocab = d2l.load_data_nmt(batch_size, num_steps)encoder = Seq2SeqEncoder(len(src_vocab), embed_size, num_hiddens, num_layers, dropout)decoder = Seq2SeqDecoder(len(tgt_vocab), embed_size, num_hiddens, num_layers, dropout)net = d2l.EncoderDecoder(encoder, decoder)train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device) |
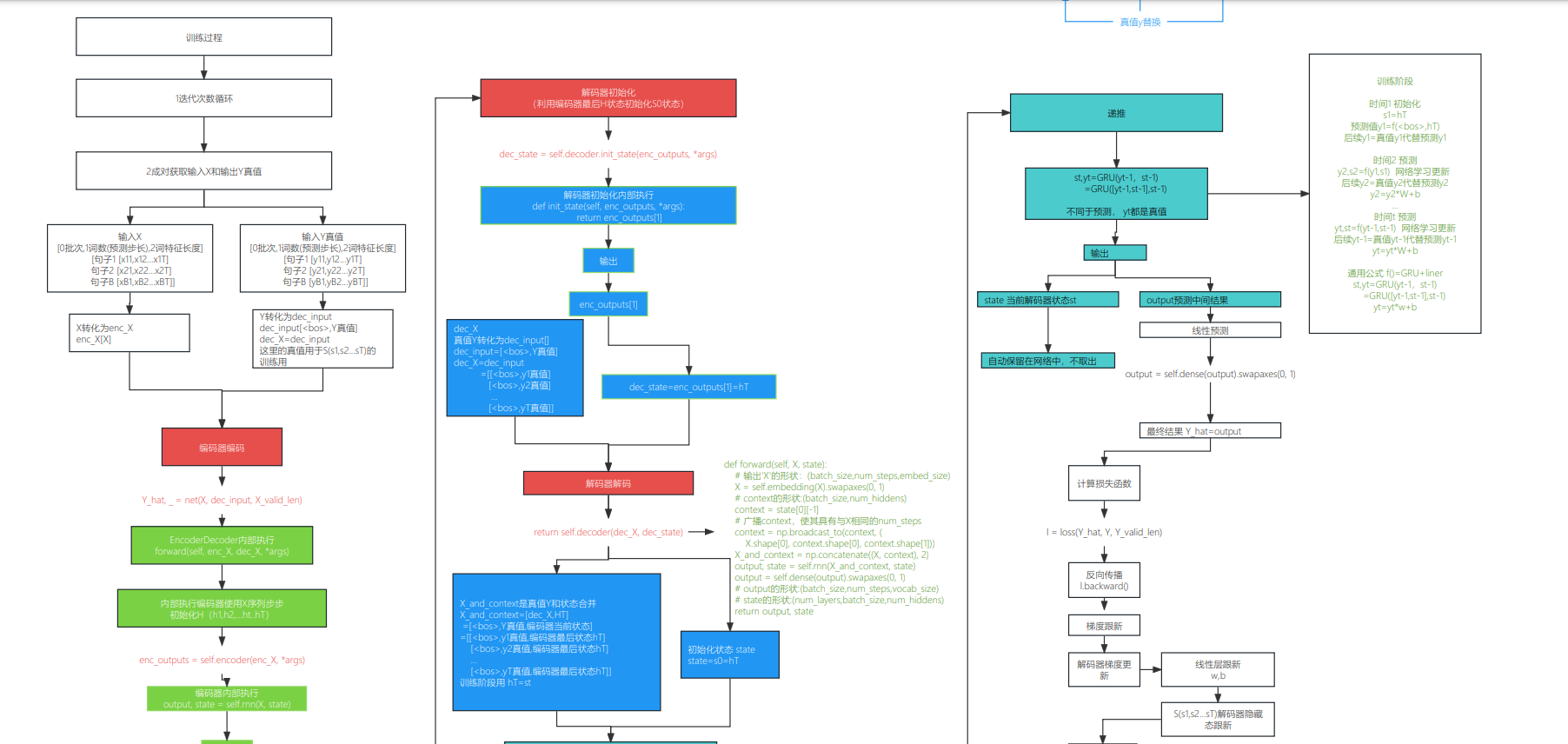
3-5 训练
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | for epoch in range(num_epochs): timer = d2l.Timer() metric = d2l.Accumulator(2) # 训练损失总和,词元数量 for batch in data_iter: optimizer.zero_grad() X, X_valid_len, Y, Y_valid_len = [x.to(device) for x in batch] bos = torch.tensor([tgt_vocab['<bos>']] * Y.shape[0], device=device).reshape(-1, 1) dec_input = torch.cat([bos, Y[:, :-1]], 1) # 强制教学 Y_hat, _ = net(X, dec_input, X_valid_len) l = loss(Y_hat, Y, Y_valid_len) l.sum().backward() # 损失函数的标量进行“反向传播” d2l.grad_clipping(net, 1) num_tokens = Y_valid_len.sum() optimizer.step() with torch.no_grad(): metric.add(l.sum(), num_tokens) if (epoch + 1) % 10 == 0: animator.add(epoch + 1, (metric[0] / metric[1],)) print(f'loss {metric[0] / metric[1]:.3f}, {metric[1] / timer.stop():.1f} ' f'tokens/sec on {str(device)}') |

1 |
(1) Y标签数据加入<bos> 起始位,标签数据作为解码器的每一步输入(x1,x2...),得到对应的真实状态s1,s2,,作为真值对比
1 2 3 | bos = torch.tensor([tgt_vocab['<bos>']] * Y.shape[0], device=device).reshape(-1, 1)dec_input = torch.cat([bos, Y[:, :-1]], 1) # 强制教学 |
1 | (2)送入编-解码器 |
1 | Y_hat, _ = net(X, dec_input, X_valid_len) |
具体执行
1 2 3 4 | def forward(self, enc_X, dec_X, *args): enc_outputs = self.encoder(enc_X, *args) dec_state = self.decoder.init_state(enc_outputs, *args) return self.decoder(dec_X, dec_state) |
1 | <br><br>逐步解析 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 | enc_outputs = self.encoder(enc_X, *args) # net 编码器 def forward(self, enc_X, dec_X, *args): 1对输入的X整体递推状态得到HT enc_outputs = self.encoder(enc_X, *args) 编码器输出 output, state = self.rnn(X) # output的形状:(num_steps,batch_size,num_hiddens) # state的形状:(num_layers,batch_size,num_hiddens) return output, state2解码器使用编码器的最后状态HT,作为输入初始化dec_state = self.decoder.init_state(enc_outputs, *args) # net 解码器初始化 def init_state(self, enc_outputs, *args): H=state=enc_outputs[1] return enc_outputs[1] # 编码器最后输出的状态HT dec_state = 编码器最后的状态HT3 使用【<bos>,y】真值标签计算return self.decoder(dec_X, dec_state) 解码器具体做的事情 输入参数 X =[<bos>,Y真值] state= 编码器最后的状态HT def forward(self, X, state): # 输出'X'的形状:(batch_size,num_steps,embed_size) X = self.embedding(X).permute(1, 0, 2) # 广播context,使其具有与X相同的num_steps context = state[-1].repeat(X.shape[0], 1, 1) # 将HT和X拼接在一起 X=[X,H] = [<bos>,y真值,HT] X_and_context = torch.cat((X, context), 2) #用Y真值【y1,y2..yn】和C=ht 去跟新解码器的状态 s[s1,s2,..sn] #这里nn是一个GNU门控网络,输出预测yt 和 状态 st+1 output, state = self.rnn(X_and_context, state) # dense=nn.Linear(num_hiddens, vocab_size) 最后先行曾预测输出 y1 y2 y3 ... output = self.dense(output).permute(1, 0, 2) # output的形状:(batch_size,num_steps,vocab_size) # state的形状:(num_layers,batch_size,num_hiddens) return output, state |
(3)计算loss
1 | l = loss(Y_hat, Y, Y_valid_len)) |
(4)反向传播计算参数
1 | l.sum().backward() # 损失函数的标量进行“反向传播” |
1 | (5)更新梯度 |
1 | optimizer.step() |
5-1-1更新解码器线性层
5-1-2更新解码GNU网络参数(更新编码器状态s1,s2,..st)
5-2-1更新编码器线性层
5-2-2更新编码GNU网络参数(更新编码器状态s1,s2,..st)
1 | <br><br> |
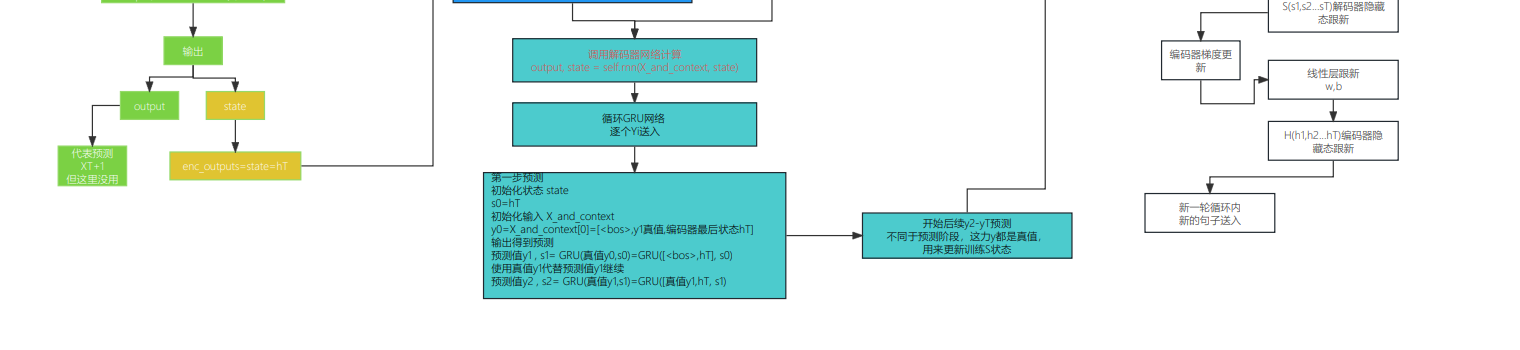
3-6 预测
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | #@savedef predict_seq2seq(net, src_sentence, src_vocab, tgt_vocab, num_steps, device, save_attention_weights=False): """序列到序列模型的预测""" # 在预测时将net设置为评估模式 net.eval() src_tokens = src_vocab[src_sentence.lower().split(' ')] + [ src_vocab['<eos>']] enc_valid_len = torch.tensor([len(src_tokens)], device=device) src_tokens = d2l.truncate_pad(src_tokens, num_steps, src_vocab['<pad>']) # 添加批量轴 enc_X = torch.unsqueeze( torch.tensor(src_tokens, dtype=torch.long, device=device), dim=0) enc_outputs = net.encoder(enc_X, enc_valid_len) dec_state = net.decoder.init_state(enc_outputs, enc_valid_len) # 添加批量轴 dec_X = torch.unsqueeze(torch.tensor( [tgt_vocab['<bos>']], dtype=torch.long, device=device), dim=0) output_seq, attention_weight_seq = [], [] for _ in range(num_steps): Y, dec_state = net.decoder(dec_X, dec_state) # 我们使用具有预测最高可能性的词元,作为解码器在下一时间步的输入 dec_X = Y.argmax(dim=2) pred = dec_X.squeeze(dim=0).type(torch.int32).item() # 保存注意力权重(稍后讨论) if save_attention_weights: attention_weight_seq.append(net.decoder.attention_weights) # 一旦序列结束词元被预测,输出序列的生成就完成了 if pred == tgt_vocab['<eos>']: break output_seq.append(pred) return ' '.join(tgt_vocab.to_tokens(output_seq)), attention_weight_seq |
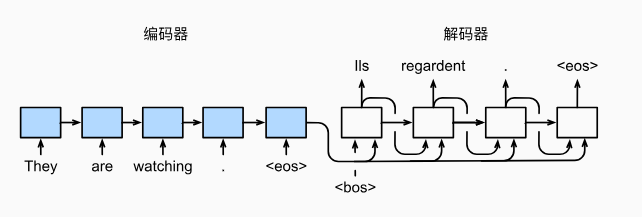
特定的“<eos>”表示序列结束词元。 一旦输出序列生成此词元,模型就会停止预测。
定的“<bos>”表示序列开始词元,它是解码器的输入序列的第一个词元。
这里我们将出现次数少于2次的低频率词元 视为相同的未知(“<unk>”)词元。
在小批量时用于将序列填充到相同长度的填充词元(“<pad>”)
解析
1输入预测的句子
X=[x1,x2..xN]=src_sentence[] 包含num_steps个词
2输入预测的句子处理
添加结束词,添加填充词
1 | enc_X=[]=src_sentence[] 【x,<eos>,<pad>】 |
3 编码器将所有输入词 编码得到状态上午下文变量enc_outputs=C =q(h1,h2,...,hT)=HT 这里取最后一个
1 | enc_outputs = net.encoder(enc_X, enc_valid_len) |
4 使用编码器最后的状态初始化解码器
1 | dec_state = net.decoder.init_state(enc_outputs, enc_valid_len) |
1 | dec_state =enc_outputs=C =q(h1,h2,...,hT)=HT 编码器最后一个状态 |
5 需要预测的句子 再次变换位解码器要输入的词
dec_X =[<BOS>,X]
6 循环每一个词,预测
1 2 | for _ in range(num_steps): Y, dec_state = net.decoder(dec_X, dec_state) |
6-1 输入在次加入上下文C=HT
1 | dec_X=【dec_X,dec_state】 =[<BOS>,X,HT]6-2 使用gnu网络计算结果,最后使用线性层得到输出,并取最大。 |
# 我们使用具有预测最高可能性的词元,作为解码器在下一时间步的输入
dec_X = Y.argmax(axis=2)
1 | 6-3根据结果从目标词表取出对应的字母 |
tgt_vocab.to_tokens(output_seq)
1 | |
最后对比结果
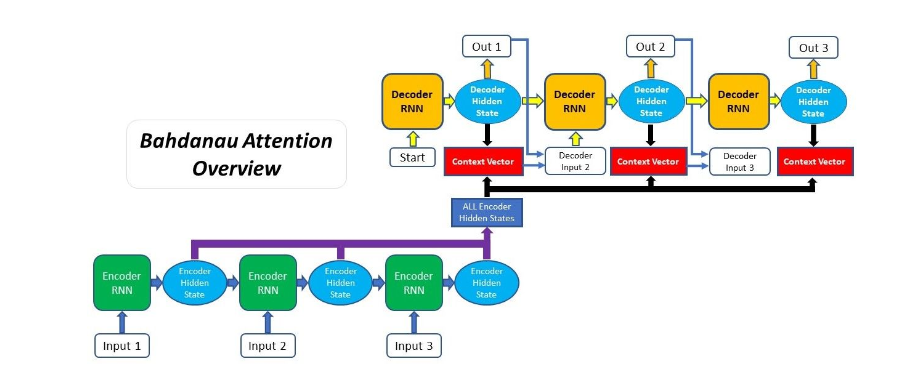
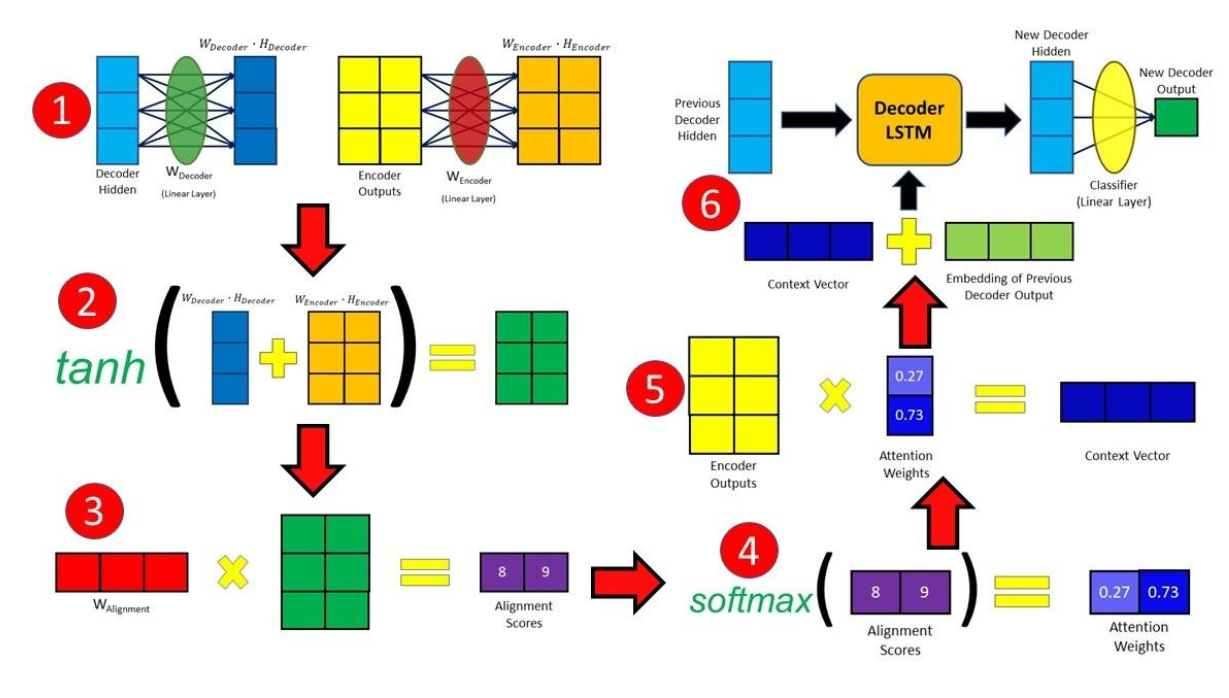
4 可变上下文
传统seq2seq模型中encoder将输入序列编码成一个context向量,decoder将context向量作为初始隐状态,生成目标序列。随着输入序列长度的增加,编码器难以将所有输入信息编码为单一context向量,编码信息缺失,难以完成高质量的解码。
注意力机制是在每个时刻解码时,基于当前时刻解码器的隐状态、输入或输出等信息,计算其对输入序列各位置隐状态的注意力(分数)并加权生成context向量用于当前时刻解码。引入注意力机制,使得不同时刻的解码能够关注不同位置的输入信息,提高预测准确性。




【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek “源神”启动!「GitHub 热点速览」
· 我与微信审核的“相爱相杀”看个人小程序副业
· 微软正式发布.NET 10 Preview 1:开启下一代开发框架新篇章
· 如何使用 Uni-app 实现视频聊天(源码,支持安卓、iOS)
· C# 集成 DeepSeek 模型实现 AI 私有化(本地部署与 API 调用教程)
2022-10-24 英雄连2作弊码
2020-10-24 修改etc/sudoers,导致系统出现sudo错误
2020-10-24 python和sudo python的区别
2019-10-24 openpose开发(1)官方1.5版本源码编译