
官方
https://jalammar.github.io/illustrated-transformer/
知乎解读
https://zhuanlan.zhihu.com/p/266069794
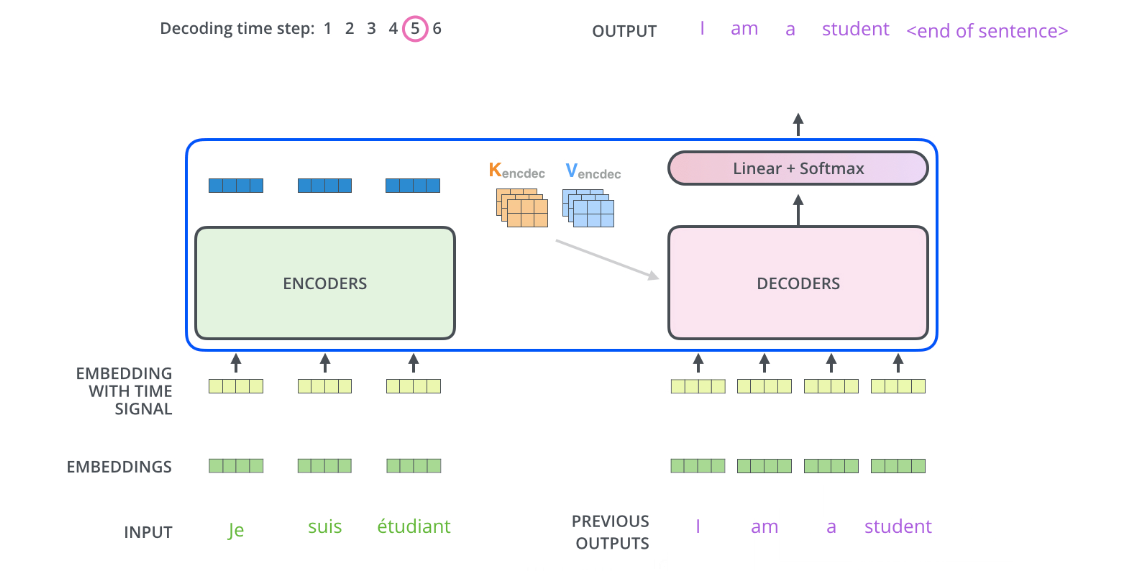
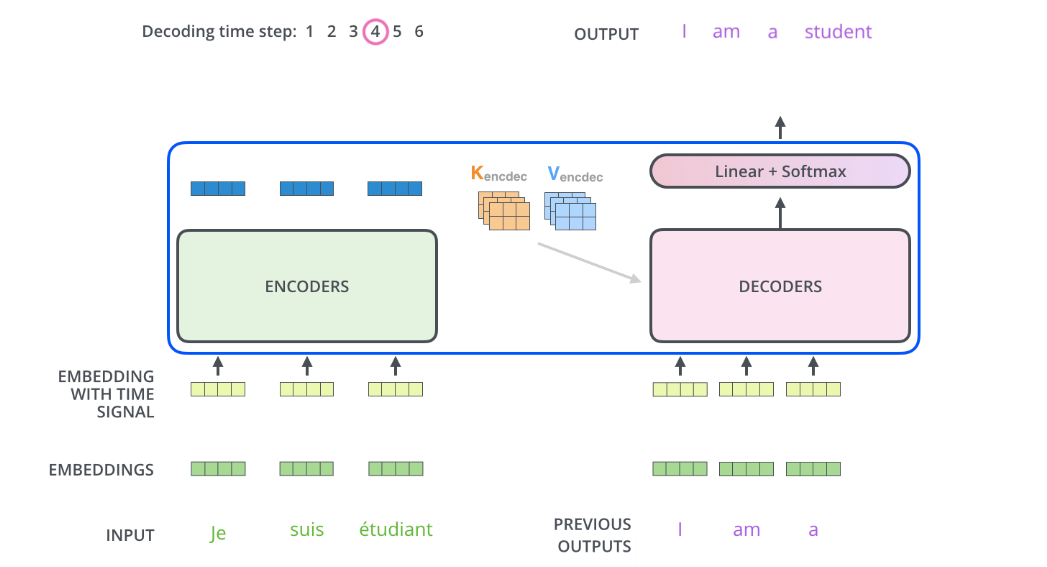
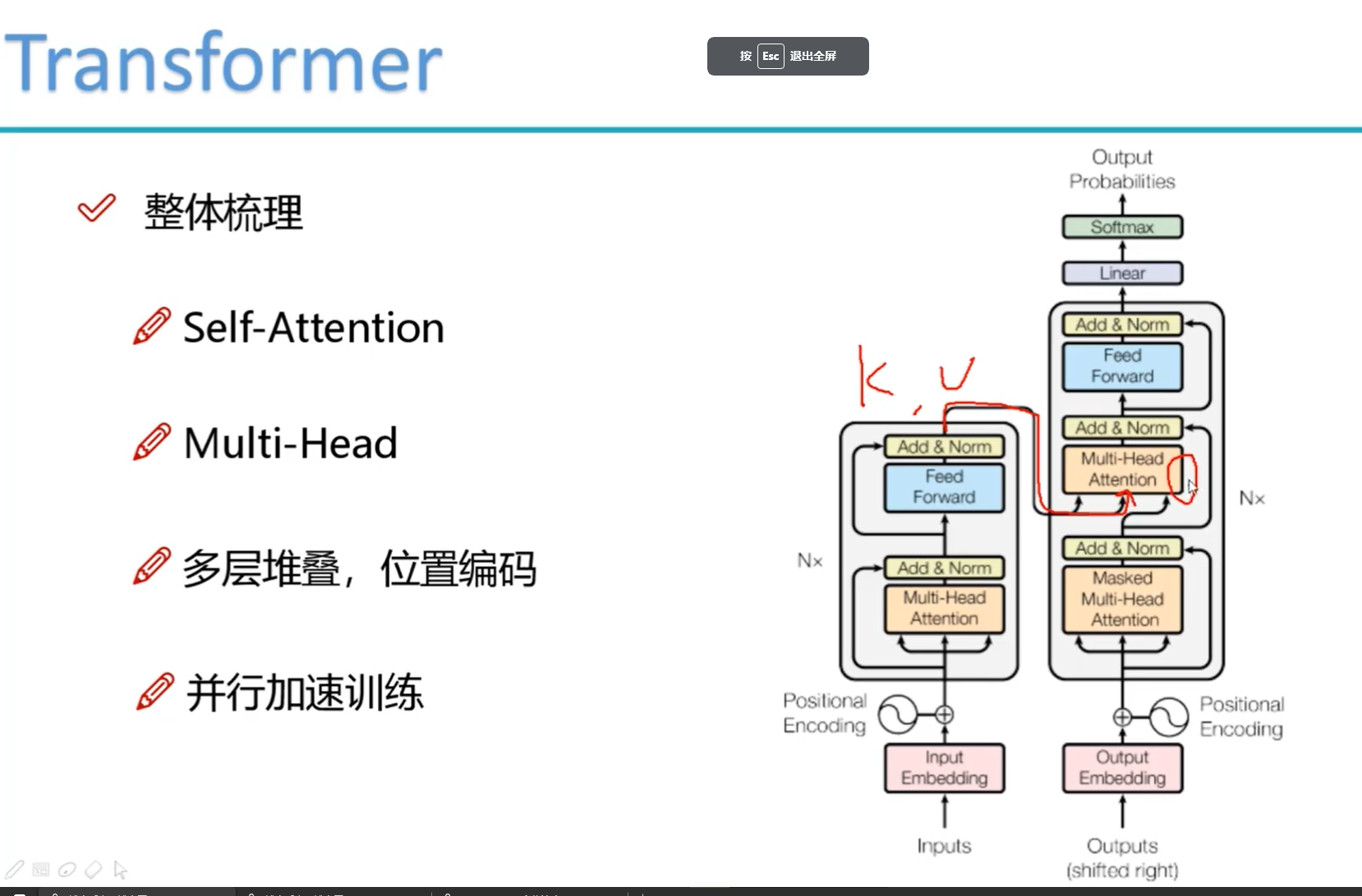
解码器中的自关注层的运行方式与编码器中的运行方式略有不同:
在解码器中,自注意力层只允许关注输出序列中较早的位置。-inf这是通过在自注意力计算中的 softmax 步骤之前屏蔽未来位置(将它们设置为 )来完成的。
“编码器-解码器注意力”层的工作方式与多头自注意力类似,只不过它从其下面的层创建查询矩阵,并从编码器堆栈的输出中获取键和值矩阵。
多层堆叠
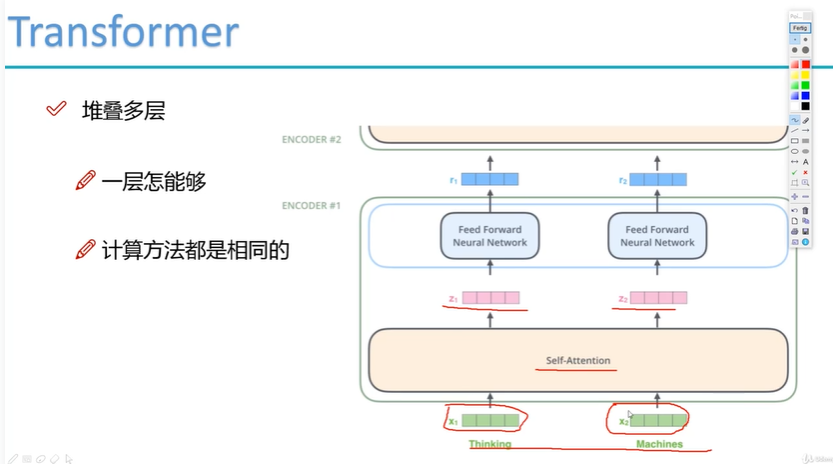
多头得到到多个结果 z1 z2
z1 z2经过 feed forward neural network (全连接层)得到向量r1 r2.
既然是向量,就可以重复输入网络了
然后就可以重复堆积层了。
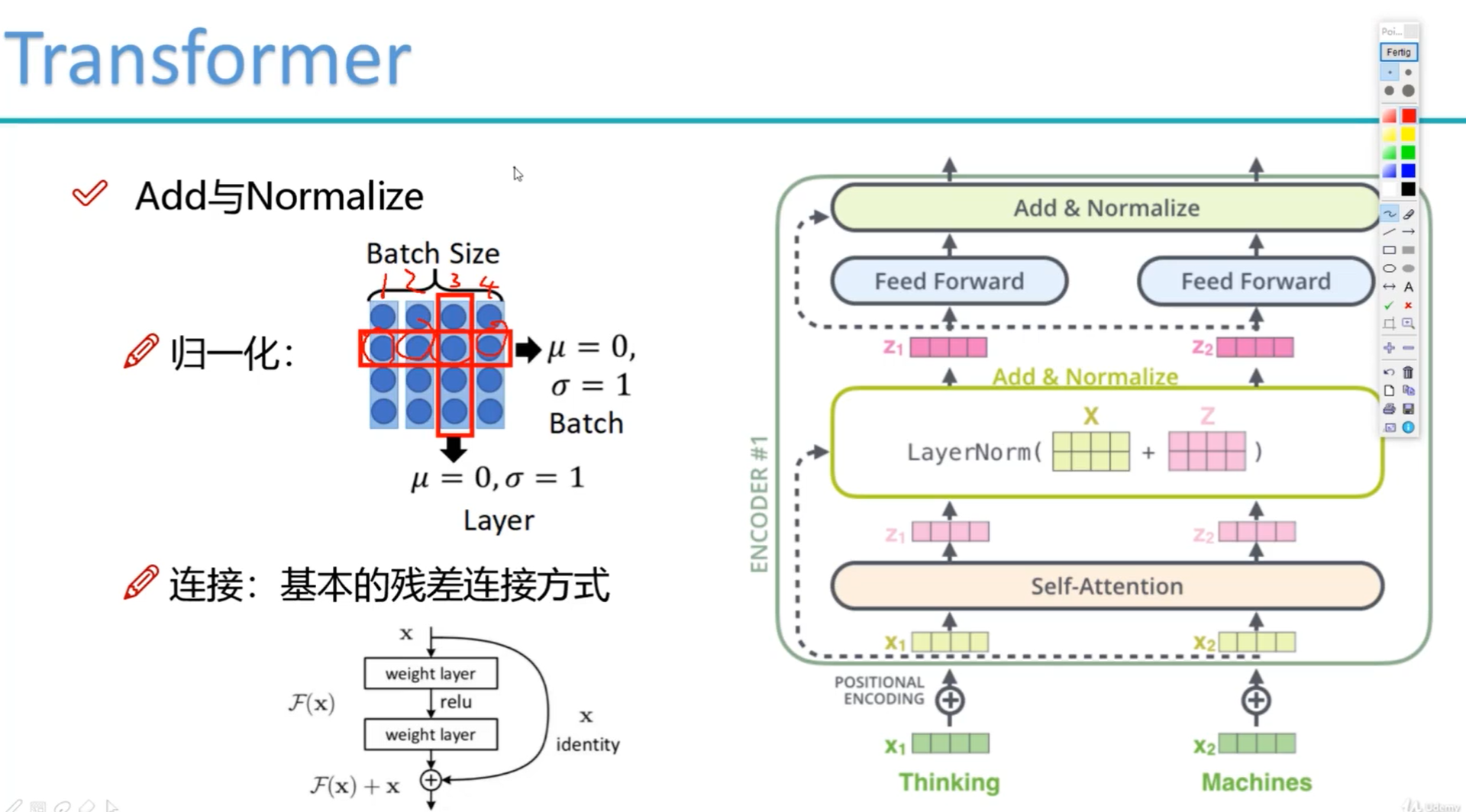
layernorm 应用了残差网络思想(确保加的层不会导致比原来系统差)
1 加操作:输出+输入,增加了输入有利于解决梯度消失
2 归一化:保证方差,均值稳定,减缓梯度爆炸
Transformer
10.7. Transformer — 动手学深度学习 2.0.0 documentation (d2l.ai)


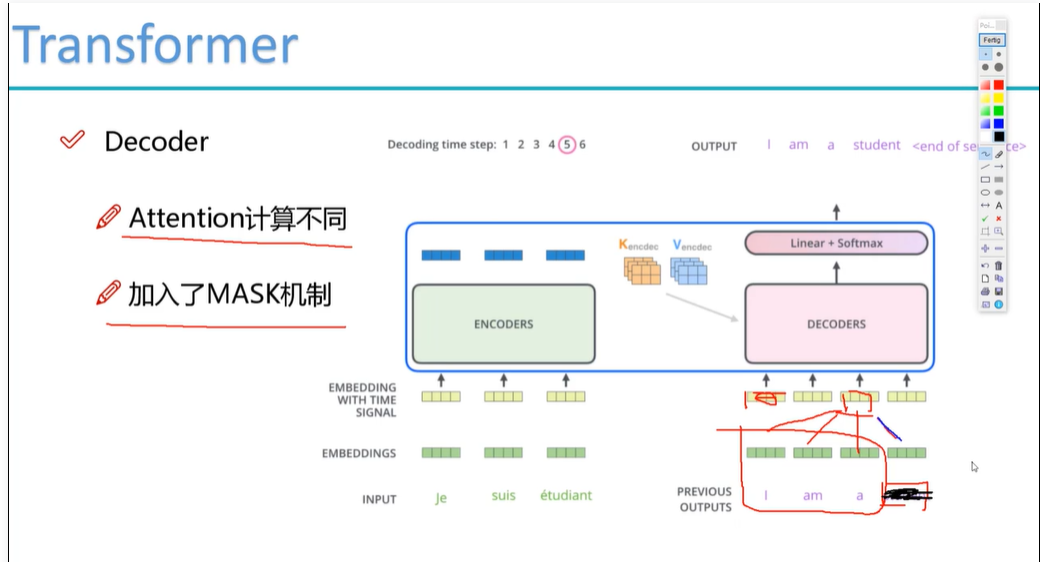
掩蔽(masked)注意力
但是,解码器中的每个位置只能考虑该位置之前的所有位置。这种掩蔽(masked)注意力保留了自回归(auto-regressive)属性,确保预测仅依赖于已生成的输出词元。
103. 103 - 103 transformer整体架构梳理_哔哩哔哩_bilibili
掩蔽(masked)注意力
但是,解码器中的每个位置只能考虑该位置之前的所有位置。这种掩蔽(masked)注意力保留了自回归(auto-regressive)属性,确保预测仅依赖于已生成的输出词元。

编码时候知道全文 例如中文 我 爱 你
但是预测时候,不知道全文,只知道目前已经翻译出来的。 I LOVE (YOU等待预测) s所以掩码遮蔽.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号