

0 为什么会出现注意机制
97. 97 - 097 传统解决方案遇到的问题_哔哩哔哩_bilibili



缺点
1 后续的预测必须用上前面的中间态结果,不能算独立, 不能并行加速计算
2 网络能学习到不同的重点,而不是统一均匀都起到作用。
3 传统词向量训练好,词向量模型不能改变



1 注意力理解概念引入
self-Attention|自注意力机制 |位置编码 | 理论 + 代码_哔哩哔哩_bilibili

使用推荐算法讲解,因为很类似
查询和key匹配(最匹配的),然后乘上value(含金量 高分 畅销 好评),综合得分=最相似的的*含金量


2 自注意力-自然语言场景转化

计算公式

dk是每一个词的特征维度,除dk是否为了缩放归一化
第一轮计算
0初始化 w1 w2 w3 所有词a1 a2 a3 共用一套
1计算出各自对应的q k v
2 计算匹配度
3归一化匹配度 概率位1
4根据匹配度计算加权值 每一个计算结果按照匹配程度加权和
atention(q1,k1,v1)=q1*k1/根号d= w1*v1
atention(q2,k2,v2)=q2*k2/根号d= w2*v2
atention(q3,k3,v3)=q3*k3/根号d= w3*v2
b1=atention(q1,k1,v1) + atention(q2,k2,v2) + atention(q3,k3,v3)





第二个词语计算

代码

nn.Linear() 全连接层
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 | import torch.nn as nnimport torchimport matplotlib.pyplot as pltclass Self_Attention(nn.Module): def __init__(self, dim, dk, dv): super(Self_Attention, self).__init__() self.scale = dk ** -0.5 self.q = nn.Linear(dim, dk) self.k = nn.Linear(dim, dk) self.v = nn.Linear(dim, dv) def forward(self, x): q = self.q(x) k = self.k(x) v = self.v(x) attn = (q @ k.transpose(-2, -1)) * self.scale attn = attn.softmax(dim=-1) x = attn @ v return xatt = Self_Attention(dim=2, dk=2, dv=3)x = torch.rand((1, 4, 2))output = att(x)# class MultiHead_Attention(nn.Module):# def __init__(self, dim, num_heads):## super(MultiHead_Attention, self).__init__()# self.num_heads = num_heads # 2# head_dim = dim // num_heads # 2# self.scale = head_dim ** -0.5 # 1# self.qkv = nn.Linear(dim, dim * 3)# self.proj = nn.Linear(dim, dim)## def forward(self, x):# B, N, C = x.shape# qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)## q, k, v = qkv[0], qkv[1], qkv[2]## attn = (q @ k.transpose(-2, -1)) * self.scale# attn = attn.softmax(dim=-1)## x = (attn @ v).transpose(1, 2).reshape(B, N, C)# x = self.proj(x)# x = self.proj_drop(x)# return x## att = MultiHead_Attention(dim=768, num_heads=12)# x = torch.rand((1, 197, 768))# output = att(x) |
位置编码
102. 102 - 102 位置编码与多层堆叠_哔哩哔哩_bilibili




1位置编码直接加在输入里面
2 两种办法 方法2可以自己学习,论文作者用的是自学习的方式
3 pos代表第几个token词,

j个token词,每个词有i个维度。
可视化出来

位置越大,频率越小,sin曲线拉的越长
在二进制表示中,较高比特位的交替频率低于较低比特位, 与下面的热图所示相似,只是位置编码通过使用三角函数在编码维度上降低频率。 由于输出是浮点数,因此此类连续表示比二进制表示法更节省空间。
参考
10.6. 自注意力和位置编码 — 动手学深度学习 2.0.0 documentation (d2l.ai)
网络代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | #@saveclass PositionalEncoding(nn.Module): """位置编码""" def __init__(self, num_hiddens, dropout, max_len=1000): super(PositionalEncoding, self).__init__() self.dropout = nn.Dropout(dropout) # 创建一个足够长的P self.P = torch.zeros((1, max_len, num_hiddens)) X = torch.arange(max_len, dtype=torch.float32).reshape( -1, 1) / torch.pow(10000, torch.arange( 0, num_hiddens, 2, dtype=torch.float32) / num_hiddens) self.P[:, :, 0::2] = torch.sin(X) self.P[:, :, 1::2] = torch.cos(X) def forward(self, X):<br> #为了使用序列的顺序信息,可以通过在输入表示中添加位置编码,来注入绝对的或相对的位置信息。 X = X + self.P[:, :X.shape[1], :].to(X.device) return self.dropout(X) |
调用
1 2 3 4 5 6 7 | encoding_dim, num_steps = 32, 60pos_encoding = PositionalEncoding(encoding_dim, 0)pos_encoding.eval()X = pos_encoding(torch.zeros((1, num_steps, encoding_dim)))P = pos_encoding.P[:, :X.shape[1], :]d2l.plot(torch.arange(num_steps), P[0, :, 6:10].T, xlabel='Row (position)', figsize=(6, 2.5), legend=["Col %d" % d for d in torch.arange(6, 10)]) |
102. 102 - 102 位置编码与多层堆叠_哔哩哔哩_bilibili
https://jalammar.github.io/illustrated-transformer/

https://zh.d2l.ai/chapter_attention-mechanisms/nadaraya-waston.html

https://zhuanlan.zhihu.com/p/265108616
Attention注意力机制与self-attention自注意力机制
Attention注意力机制与self-attention自注意力机制
1.为什么要因为注意力机制
在Attention诞生之前,已经有CNN和RNN及其变体模型了,那为什么还要引入attention机制?主要有两个方面的原因,如下:
(1)计算能力的限制:当要记住很多“信息“,模型就要变得更复杂,然而目前计算能力依然是限制神经网络发展的瓶颈。
(2)优化算法的限制:LSTM只能在一定程度上缓解RNN中的长距离依赖问题,且信息“记忆”能力并不高。
注意力机制的优缺点
attention的优点
1.参数少:相比于 CNN、RNN ,其复杂度更小,参数也更少。所以对算力的要求也就更小。
2.速度快:Attention 解决了 RNN及其变体模型 不能并行计算的问题。Attention机制每一步计算不依赖于上一步的计算结果,因此可以和CNN一样并行处理。
3.效果好:在Attention 机制引入之前,有一个问题大家一直很苦恼:长距离的信息会被弱化,就好像记忆能力弱的人,记不住过去的事情是一样的。
attention的缺点
缺点:自注意力机制的信息抓取能力其实不如RNN和CNN,在小数据集的表现不如后两者,只有在数据量上来了之后才能发挥出实力。实际应用中数据集较小时建议还是用CNN和RNN
缺点有啊,需要的数据量大。因为注意力机制是抓重点信息,忽略不重要的信息,所以数据少的时候,注意力机制效果不如bilstm,现在我们企业都用注意力机制,因为企业数据都是十万百万级的数据量,用注意力机制就很好。还有传统的lstm,bilstm序列短的时候效果也比注意力机制好。所以注意力机制诞生的原因就是面向现在大数据的时代,企业里面动不动就是百万数据,超长序列,用传统的递归神经网络计算费时还不能并行计算,人工智能很多企业比如极视角现在全换注意力机制了
2.什么是注意力机制
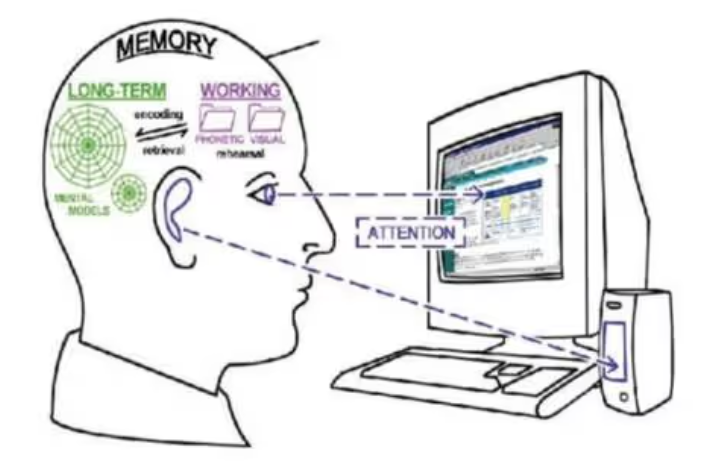
在介绍什么是注意力机制之前,先让大家看一张图片。当大家看到下面图片,会首先看到什么内容?当过载信息映入眼帘时,我们的大脑会把注意力放在主要的信息上,这就是大脑的注意力机制。

同样,当我们读一句话时,大脑也会首先记住重要的词汇,这样就可以把注意力机制应用到自然语言处理任务中,于是人们就通过借助人脑处理信息过载的方式,提出了Attention机制
3.注意力机制模型
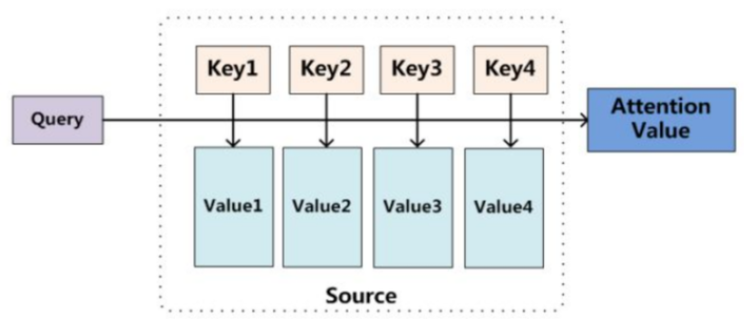

从本质上理解,Attention是从大量信息中有筛选出少量重要信息,并聚焦到这些重要信息上,忽略大多不重要的信息。权重越大越聚焦于其对应的Value值上,即权重代表了信息的重要性,而Value是其对应的信息。
至于Attention机制的具体计算过程,如果对目前大多数方法进行抽象的话,可以将其归纳为两个过程:
第一个过程是根据Query和Key计算权重系数,
而第一个过程又可以细分为两个阶段:
第一个阶段根据Query和Key计算两者的相似性或者相关性;
第二个阶段对第一阶段的原始分值进行归一化处理;
第二个过程根据权重系数对Value进行加权求和。
这样,可以将Attention的计算过程抽象为如图展示的三个阶段。

第一个阶段
在第一个阶段,可以引入不同的函数和计算机制,根据Query和某个 Keyi ,计算两者的相似性或者相关性,最常见的方法包括:求两者的向量点积、求两者的向量Cosine相似性或者通过再引入额外的神经网络来求值,即如下方式:

第一阶段产生的分值根据具体产生的方法不同其数值取值范围也不一样,第二阶段引入类似SoftMax的计算方式对第一阶段的得分进行数值转换,一方面可以进行归一化,将原始计算分值整理成所有元素权重之和为1的概率分布;另一方面也可以通过SoftMax的内在机制更加突出重要元素的权重。即一般采用如下公式计算:

1过程对位置加权

2通用公式

3要求它们是非负的,并且总和为1,引入一个高斯核(Gaussian kernel)

4 联合a和K
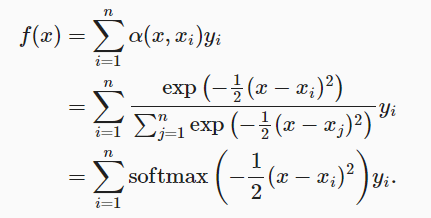
如果一个键xi越是接近给定的查询x&amp;amp;amp;amp;amp;amp;lt;span class="math notranslate nohighlight"&amp;amp;amp;amp;amp;amp;gt;, 那么分配给这个键对应值yi&amp;amp;amp;amp;amp;amp;lt;span class="math notranslate nohighlight"&amp;amp;amp;amp;amp;amp;gt;的注意力权重就会越大, 也就&amp;amp;amp;amp;amp;amp;amp;ldquo;获得了更多的注意力&amp;amp;amp;amp;amp;amp;amp;rdquo;。
如图

因此由观察可知“查询-键”对越接近, 注意力汇聚的注意力权重就越高。
第二阶段
第二阶段的计算结果 ai 即为 Valuei 对应的权重系数,然后进行加权求和即可得到Attention数值:

通过如上三个阶段的计算,即可求出针对Query的Attention数值,目前绝大多数具体的注意力机制计算方法都符合上述的三阶段抽象计算过程。
4.Self-attention自注意力机制
自注意力机制是注意力机制的变体,其减少了对外部信息的依赖,更擅长捕捉数据或特征的内部相关性。
自注意力机制在文本中的应用,主要是通过计算单词间的互相影响,来解决长距离依赖问题。
自注意力机制的计算过程:
1.将输入单词转化成嵌入向量;
2.根据嵌入向量得到q,k,v三个向量;
3.为每个向量计算一个score:score =q . k ;
4.为了梯度的稳定,Transformer使用了score归一化,即除以
5.对score施以softmax激活函数;
6.softmax点乘Value值v,得到加权的每个输入向量的评分v;
7.相加之后得到最终的输出结果z :z=



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律
2019-10-16 Kinect for Windows V2开发教程
2019-10-16 12 图像拼接 -Stitching模块讲解
2018-10-16 微信接入arduino
2017-10-16 很认真的聊一聊程序员的自我修养
2017-10-16 谷歌镜像