

http://www.liuxiao.org/2019/02/%E8%AE%BA%E6%96%87%E7%AC%94%E8%AE%B0%EF%BC%9Anetvlad-cnn-architecture-for-weakly-supervised-place-recognition/
https://zhuanlan.zhihu.com/p/237602816
传统方法来讲,这里讲最经典最经典的几个方法:
- [VLAD] - https://github.com/jorjasso/VLAD
- [DBoW2] - https://github.com/dorian3d/DBoW2
- [libhaloc]- https://github.com/srv/libhaloc
- [HBST] - https://gitlab.com/srrg-software/srrg_hbst
- [iBow] - https://github.com/emiliofidalgo/ibow-lcd
- ...
无论以何种方式实现,其输入是一张图,输出是database中的query对象。
当然以神经网络对图像的强大表达能力,近些年深度学习的方法比较流行,核心思路应该理解为对图像提取特征,这种特征能够描述这个场景,相似场景特征之间的距离要近,不同场景对应的特征向量的距离应该尽量远,这样才有区分度,这里也列举近些年一些基于深度学习的算法。
- [NetVLAD] - https://github.com/Relja/netvlad
- [DIR] - https://github.com/almazan/deep-image-retrieval
- [GeM,DAME] - https://github.com/scape-research/DAME-WEB
- [DELF] - https://github.com/tensorflow/models/tree/master/research/delf
- [HF-NET] - https://github.com/ethz-asl/hfnet
- [UR2KID] - https://arxiv.org/abs/2001.07252
- ...
上述DL的方法基本上输入是图像,输出是一个N(1024/2048/4096...)维度的向量,即描述子。如果两张图很接近,那么其描述子之间的距离会比较接近,反之则比较距离较远,另外近年也有与语义信息结合的工作,但目前(2020.09)还没有看到比较好的开源工作。
这里推荐一个CVPR2017的一个Tutorial,:
Tutorial : Large-Scale Visual Place Recognition and Image-Based Localization Part 1
Tutorial : Large-Scale Visual Place Recognition and Image-Based Localization Part 2
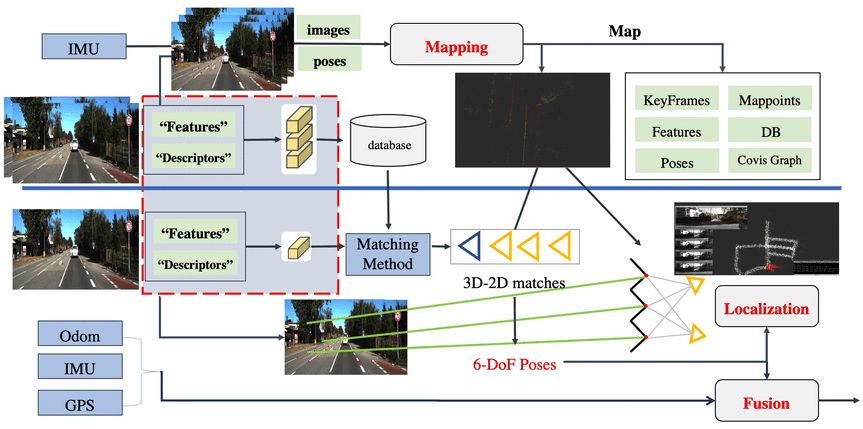
如果说像把上面的工作集成到自己的SLAM系统或者框架中,一般还需要考虑实时性以及是否需要模型加速或者说转换成C++的问题,可以从NetVLAD入手,譬如大佬们把它修改成了tensorflow版本的
NetVLAD: CNN architecture for weakly supervised place recognition
论文笔记:NetVLAD: CNN architecture for weakly supervised place recognition
文章目录
NetVLAD1是一个较早的使用 CNN 来进行图像检索或者视频检索的工作,后续在此工作的基础上陆续出了很多例如 NetRVLAD、NetFV、NetDBoW 等等的论文,思想都是大同小异。
一、图像检索
VLAD 和 BoW、Fisher Vector 等都是图像检索领域的经典方法,这里仅简介下图像检索和 VLAD 的基本思想。
图像检索(实例搜索)是这样的一个经典问题:
1、我们有一个图像数据库 I_iIi 通过函数可以得到每一个图像的特征 f(I_i)f(Ii);
2、我们有一个待查询图像 qq 通过函数得到它的特征 f(q)f(q);
3、则我们获得的欧氏距离 d(q, I) = \parallel f(q) - f(I)\paralleld(q,I)=∥ f(q)−f(I)∥ 应该满足越相近的图像 d(q, I)d(q,I) 越小。
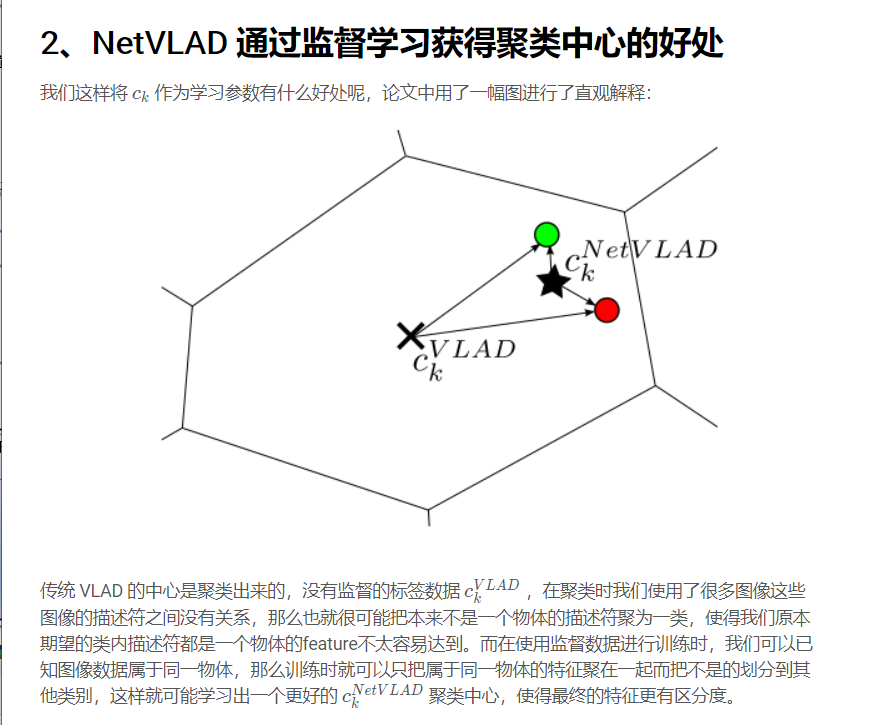
二、VLAD (Vector of Locally Aggregated Descriptors)

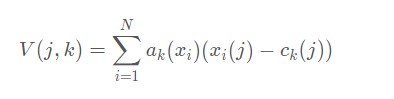

NetVLAD
经典 VLAD 公式的可微化




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
2020-11-24 Cesium学习笔记2-4:更多官方示例